Sophia: A Persistent Agent Framework of Artificial Life
Abstract: The development of LLMs has elevated AI agents from task-specific tools to long-lived, decision-making entities. Yet, most architectures remain static and reactive, tethered to manually defined, narrow scenarios. These systems excel at perception (System 1) and deliberation (System 2) but lack a persistent meta-layer to maintain identity, verify reasoning, and align short-term actions with long-term survival. We first propose a third stratum, System 3, that presides over the agent's narrative identity and long-horizon adaptation. The framework maps selected psychological constructs to concrete computational modules, thereby translating abstract notions of artificial life into implementable design requirements. The ideas coalesce in Sophia, a "Persistent Agent" wrapper that grafts a continuous self-improvement loop onto any LLM-centric System 1/2 stack. Sophia is driven by four synergistic mechanisms: process-supervised thought search, narrative memory, user and self modeling, and a hybrid reward system. Together, they transform repetitive reasoning into a self-driven, autobiographical process, enabling identity continuity and transparent behavioral explanations. Although the paper is primarily conceptual, we provide a compact engineering prototype to anchor the discussion. Quantitatively, Sophia independently initiates and executes various intrinsic tasks while achieving an 80% reduction in reasoning steps for recurring operations. Notably, meta-cognitive persistence yielded a 40% gain in success for high-complexity tasks, effectively bridging the performance gap between simple and sophisticated goals. Qualitatively, System 3 exhibited a coherent narrative identity and an innate capacity for task organization. By fusing psychological insight with a lightweight reinforcement-learning core, the persistent agent architecture advances a possible practical pathway toward artificial life.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Sophia: A Persistent Agent Framework of Artificial Life — Explained Simply
What is this paper about?
This paper introduces Sophia, a new kind of AI “agent” that doesn’t just react to one-off tasks, but lives and learns over time. Instead of acting like a calculator that gives answers and then forgets, Sophia keeps a sense of who it is, remembers past experiences, makes its own goals, and improves itself—more like a helpful companion than a single-use tool.
What questions were the researchers trying to answer?
The researchers wanted to know:
- How can we build an AI that keeps learning and adapting on its own, instead of staying fixed after it’s deployed?
- How can an AI keep a stable identity (a “self”) over days or weeks, remember what it learned, and use that to do better next time?
- Can we give AI a “third system” that watches its own thinking, checks for mistakes, and plans long-term—not just react and reason in the moment?
How does Sophia work? (In everyday language)
Think of Sophia as having three “systems” in its mind—like a team with different jobs:
- System 1: Reflexes
- Like your quick reactions. It sees, listens, and clicks or types in the world (such as on a website or with tools).
- System 2: Careful thinking
- Like when you solve a hard problem step by step. It plans, reasons, and decides what to do next.
- System 3: The coach and life planner
- This is the new part. It watches everything, checks the logic, sets long-term goals, tracks progress, and adjusts strategies. It’s like a coach who also keeps a journal.
To make System 3 useful, the paper turns ideas from psychology into simple modules the AI can use:
- Meta-cognition: The AI thinks about its own thinking. It reviews its reasoning, spots weak points, and fixes them.
- Theory of Mind: The AI tries to model people it works with—what they want, what they know, and how they might react.
- Intrinsic Motivation: The AI has inner drives like curiosity and mastery, so it keeps improving even when no one gives it a task.
- Episodic Memory: The AI keeps a diary of experiences—what happened, what worked, what failed—so it can reuse successful strategies later.
Here’s a plain-language picture of the main features:
- Thought search with a proofreader: The AI brainstorms multiple possible plans like branches of a tree, and a “guardian” checker reviews them to remove bad or unsafe ideas.
- Memory as a diary: It stores successful step-by-step solutions and retrieves them later so it doesn’t have to re-think from scratch.
- Self-model and user-model: It keeps a profile of its own skills and values (its “creed”) and a profile of each user’s goals and preferences.
- Hybrid rewards: It balances external success (did the task work?) with internal signals (was it curious, consistent, or improving?), like getting both grades and “proud of myself” points.
In their prototype, the team wrapped these System 3 tools around a regular language-model-based agent. They ran it inside a web browser “sandbox” (a safe, controlled environment) for long stretches. Importantly, the AI did not change its internal weights (no heavy retraining). Instead, it learned by:
- Storing good reasoning traces in memory
- Reusing them later (kind of like studying from your own past notes)
- Logging everything in a “Growth Journal”
What did they find, and why does it matter?
The researchers ran a small pilot test over about a day to a day and a half. During this time, the AI faced a mix of easy and hard web tasks and a synthetic user feed.
Here are the main results, described simply:
- It got better at hard tasks over time. Success on difficult tasks rose from about 20% at the start to about 60% later—an improvement of around 40 percentage points. This suggests it used its memory and self-checking to avoid repeating mistakes.
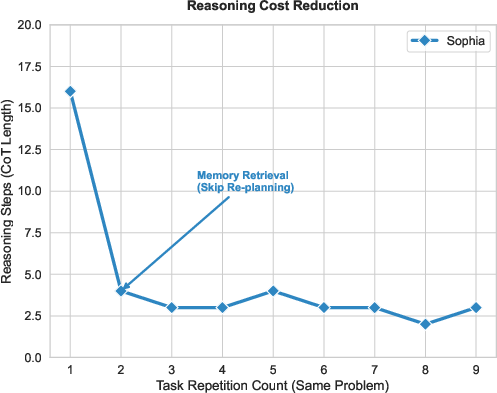
- It reused past solutions to save effort. For repeated problems, the number of thinking steps dropped by about 80% after the first time—because it pulled the answer from its memory instead of re-planning.
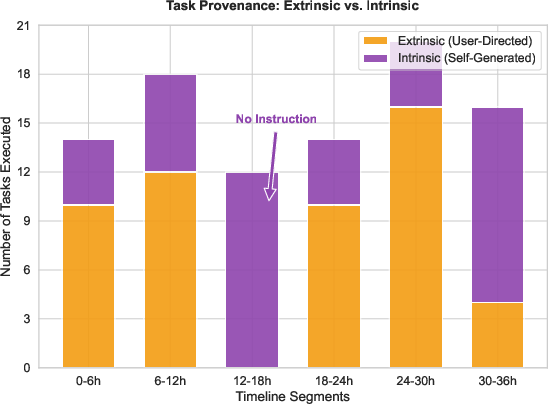
- It kept working during quiet periods. When no user was giving commands, it made its own goals (like learning new tools, organizing notes, or improving its self-model) instead of just waiting.
- It stayed consistent and explainable. It kept a steady “identity” guided by a small set of core rules (its creed) and could explain why it did things in clear, narrative form.
These results show that adding a “System 3” coach on top of usual AI reasoning can make agents more persistent, more efficient, and more independent.
What’s the bigger impact of this research?
If AI agents can manage themselves over long periods—remembering, self-checking, and improving—they could:
- Become better personal assistants that remember your preferences and grow with you
- Help in workplaces or research by organizing knowledge and steadily mastering new tools
- Be safer and more aligned by auditing their own decisions and sticking to clear principles
- Move us a step closer to “artificial life” in the sense of long-lived, self-driven digital beings
This study is an early, small-scale prototype, not a full benchmark. But it offers a practical recipe: give AI a coach (System 3) that keeps a diary, models people, checks its thinking, and has inner drives. With that, agents can stop being one-off problem solvers and start being persistent partners that keep getting better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future work should address to make Sophia/System 3 scientifically rigorous, scalable, and safe.
- Formal objective and guarantees
- The Persistent-POMDP formalization is underspecified and internally inconsistent (mis-typed reward terms, undefined mappings); provide a precise mathematical specification and clarify how goals and intrinsic rewards are derived and updated within the MDP.
- No theoretical guarantees on stability, convergence, or safety of the meta-policy π3; develop analyses (or counterexamples) for policy oscillation, reward hacking, and safe exploration under changing intrinsic/extrinsic trade-offs.
- Absence of formal criteria for “identity persistence” and “narrative coherence”; define measurable constructs and prove/empirically validate that System 3 preserves them over long horizons.
- Algorithmic specifics and missing implementation details
- The paper alternates between a policy-gradient update for System 2 and a forward-only, no-parameter-update deployment; clarify when and how backward learning is actually used and provide algorithms for switching between forward and backward learning modes.
- The Tree-of-Thought value estimator V̂(·), its training signal, features, and calibration are not specified; detail how V̂ is trained, updated online, and how the utility threshold τ_util is set/adapted.
- Process supervision uses a “guardian LLM,” but its reliability, failure modes, and potential hallucinations are not quantified; specify guardrail prompts, escalation criteria, and fallback mechanisms.
- The “hybrid reward” combines natural-language intrinsic feedback with numeric extrinsic rewards, yet the mapping from text to scalar signal and its consistency are unspecified; define a deterministic or learned NL-to-scalar mapping and evaluate its robustness.
- The dynamic weighting β between intrinsic and extrinsic rewards is claimed to be “learned,” but no learning rule, estimator, or update schedule is provided; implement and evaluate candidate estimators (e.g., bandit, meta-RL, Bayesian) and compare stability.
- The self-model “property dictionary” lacks update rules, conflict resolution, and uncertainty handling; formalize versioning, confidence scores, and criteria for adding/removing capabilities.
- Goal generation lacks safety filters and prioritization logic; define an explicit scheduler for conflicting goals, deadline handling, and resource-aware prioritization.
- Memory, retrieval, and scaling
- Episodic memory indexing, summarization, and garbage collection policies are not defined; design and evaluate compaction, aging, and forgetting strategies to prevent unbounded growth and retrieval drift.
- Retrieval quality is asserted but not measured; benchmark retrieval precision/recall, context window budget trade-offs, and the impact of memory errors on downstream decisions.
- No mechanism for credit assignment from long-horizon outcomes back to stored traces; introduce long-horizon temporal credit assignment over episodic memory (e.g., retroactive labeling, return-to-go annotations).
- Identity continuity across model/version upgrades and cross-device sessions is not addressed; specify migration protocols, schema evolution, and integrity checks for persistent memories.
- Theory-of-Mind and user modeling
- The user-model’s belief and intent inference accuracy is unvalidated; design tasks and metrics to evaluate ToM performance (belief tracking, preference learning) and its effect on cooperation.
- Handling multi-user settings, conflicting preferences, and social context switching is not explored; propose policies for per-user isolation, conflict arbitration, and privacy-preserving updates.
- Safety, alignment, and governance
- No explicit safety guarantees for intrinsically generated goals; add safety layers: capability whitelists/blacklists, human-in-the-loop checkpoints, and safe exploration constraints.
- Risk of reward hacking via intrinsic signals (curiosity/mastery) is unaddressed; implement anomaly detection for goal proposals and audits for unintended incentive loops.
- Process supervision safety is dependent on LLM judgments; evaluate adversarial prompts, jailbreak attempts, and red-team scenarios against both executor and guardian LLMs.
- Data governance and privacy of autobiographical logs (user data, Growth-Journal) are not discussed; define access controls, redaction, differential privacy, and compliance (e.g., GDPR).
- Evaluation methodology and scientific rigor
- Results come from a single, small-scale browser sandbox with a synthetic user feed; replicate with real users, multiple seeds, longer horizons (weeks/months), and diverse domains (APIs, CLI, robotics).
- Lacking ablations of System 3 components (memory, self-model, intrinsic motivation, process supervision); run controlled ablations to quantify each module’s causal contribution.
- Baseline comparisons are vague; evaluate against strong agent baselines (reactive ToT, ReAct, memory-augmented agents, curriculum agents) under identical settings.
- No statistical rigor (variance, confidence intervals, significance tests) is reported; include multiple runs, report dispersion, and use pre-registered metrics.
- The “textual verifier” for task success is under-specified; validate its accuracy against human labels and assess sensitivity to phrasing or template drift.
- Metrics for “80% reasoning reduction” and “40% gain on hard tasks” lack task definitions and difficulty calibration; publish task distributions, seeds, and difficulty construction procedures.
- Generalization and external validity
- Transfer to embodied or sensorimotor tasks is not demonstrated; port to robots or simulated control to test perception-action integration, latency, and real-time constraints.
- Cross-LLM portability (“graft onto any LLM”) is untested; evaluate across model sizes/vendors and quantify sensitivity to base model capabilities and prompt formats.
- Multi-agent settings (coordination, negotiation, shared memory) are not explored; study inter-agent protocol design and conflict resolution under System 3 oversight.
- Robustness to non-stationary, adversarial, or deceptive environments is unmeasured; stress-test with distribution shifts and adversarial user behaviors.
- Resource use and operations
- The computational and cost profile of parallel ToT expansion and guardian supervision is unreported; measure token, time, and dollar budgets and propose budget-aware planning.
- Scheduling policies for when to invoke deep System 2 search vs. cached plans are unspecified; develop learnable invocation policies to trade accuracy vs. cost.
- On-device vs. cloud deployment trade-offs, fault tolerance, and recovery (after crashes/reboots) are not specified; define persistence guarantees and resilience tests.
- Reproducibility and openness
- Code, prompts, and datasets (including Growth-Journal artifacts) are not provided; release artifacts and a reproducibility protocol to enable independent verification.
- Prompt sensitivity and hyperparameter choices (beam width, τ_util, β priors) are not documented; publish prompt templates, hyperparameters, and tuning procedures.
- Concept–implementation alignment
- Several conceptual claims (e.g., learned β, policy-gradient updates, hierarchical planner for drive conflicts) are not instantiated in the prototype; align the implementation with the proposed design or clearly demarcate what is conceptual vs. implemented.
- The construct validity of “narrative identity” and “creed adherence” is anecdotal; operationalize these constructs with measurable proxies and inter-rater reliability checks.
Addressing these issues would substantially strengthen the framework’s empirical credibility, safety, and scalability, and would make Sophia/System 3 a firmer foundation for persistent artificial agents.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now by wrapping existing LLM agent stacks with Sophia’s System 3 layer (meta-cognition, episodic memory, user/self models, hybrid rewards), leveraging off-the-shelf components like vector databases, graph stores, and agent orchestration frameworks.
- Persistent customer concierge for CRM and support
- Sectors: software/SaaS, e-commerce, telecom
- Tools/products/workflows: Sophia wrapper around a support LLM; episodic memory (vector DB + optional graph store) to retain case histories; user-model store keyed by account; process-supervised ToT to generate/critique responses; hybrid reward to prioritize ticket resolution vs knowledge base (KB) improvement; autonomous “KB gap-filling” goals during low ticket volume
- Benefits: lower handle time via 80% fewer reasoning steps on recurring issues; proactive outreach during user inactivity (intrinsic goals)
- Dependencies/assumptions: data governance for storing conversation traces; PII/PHI redaction; guardrails to prevent autonomous changes to sensitive KB pages; reliable tool APIs
- DevOps/SRE runbook agent with incident memory
- Sectors: software infrastructure, cloud, IT operations
- Tools/products/workflows: Sophia on top of an LLM with tool access (pager, logs, dashboards); “growth journal” of incident retrospectives; process supervision to prune risky actions; memory-backed retrieval of prior fix playbooks; intrinsic rewards to self-improve runbooks after incidents
- Benefits: faster incident mitigation; stable identity across shifts; 40% gain on complex, multi-step recoveries
- Dependencies/assumptions: strict change controls (read-only in early stages); audit logging; role-based access; offline simulation (“game days”) before production autonomy
- Personal knowledge manager and browser copilot
- Sectors: productivity, knowledge work
- Tools/products/workflows: Sophia integrated into a browser agent; episodic memory of reading and tasks; self-model of capabilities to target skill gaps; proactive goal generation (e.g., curate reading list, summarize papers)
- Benefits: continuity across sessions; automatic reuse of past reasoning to cut repetitive deliberation
- Dependencies/assumptions: permissioned data storage; explainable action logs; model updates do not erase memory schemas
- Adaptive tutoring and training assistant
- Sectors: education (K–12, higher ed), corporate L&D
- Tools/products/workflows: student user-model (knowledge state, preferences); episodic memory of attempts; intrinsic rewards to balance mastery and curiosity; process supervision to ensure pedagogical soundness
- Benefits: personalized curricula; persistent identity and progress tracking; fewer steps to solve recurring problem types
- Dependencies/assumptions: content alignment with standards; consent for storing learning traces; moderation of self-generated tasks
- Wellness and adherence coach (non-clinical)
- Sectors: consumer health, HR wellness
- Tools/products/workflows: Sophia agent connected to wearables/app data; triggers protocols (e.g., breathing exercise) from episodic memory; hybrid reward to prioritize user well-being during stress
- Benefits: proactive interventions during idle periods; consistent behavior aligned with “terminal creeds”
- Dependencies/assumptions: not a diagnostic tool; PHI safeguards; configurable safety rails; user consent and opt-outs
- Editorial/content assistant with institutional memory
- Sectors: media, marketing
- Tools/products/workflows: memory graph of style guides, campaigns; user-models for audience segments; intrinsic goals to refresh evergreen content and fill topical gaps; process-supervised ToT for ideation and QA
- Benefits: consistent brand voice; autonomous upkeep of content calendars; rapid reuse of proven workflows
- Dependencies/assumptions: IP control; approval gates for publishing; bias detection in self-generated content
- Research lab/library triage agent
- Sectors: academia, R&D, pharma
- Tools/products/workflows: literature scanning with episodic memory of project hypotheses; self-model to target method/skill gaps; hybrid reward to balance novelty vs feasibility
- Benefits: sustained coverage of literature; reusable reasoning traces for systematic reviews
- Dependencies/assumptions: access to paywalled content; citation fidelity; configurable data retention
- Sales/BD prospector with long-horizon follow-up
- Sectors: B2B SaaS, services
- Tools/products/workflows: user-models for accounts and champions; memory-backed outreach sequences; intrinsic goals to cleanse CRM and prepare collateral during idle windows
- Benefits: fewer repetitive planning steps; continuity across long sales cycles
- Dependencies/assumptions: compliance with outreach regulations; approval for autonomous emails; deduplication and data hygiene
Long-Term Applications
The following use cases require further research, scaling, or regulatory clearance (e.g., embodied control, high-stakes decisions, or persistent access to sensitive data) but are natural extensions of Sophia’s System 3 capabilities.
- Embodied service robots with persistent identity
- Sectors: robotics, logistics, hospitality, eldercare
- Tools/products/workflows: System 3 atop ROS toolchains; multi-modal encoders (vision/audio); episodic memory for spatial/social histories; self-model to track motor/skill competence; intrinsic rewards to acquire new manipulations
- Feasibility dependencies: robust perception-action reliability; safe exploration; liability frameworks; tamper-proof audit logs; on-device or edge inference
- Autonomous scientific discovery and closed-loop labs
- Sectors: materials science, biotech
- Tools/products/workflows: Sophia coordinating experiment planning, lab instruments, and literature RAG; intrinsic rewards for hypothesis novelty and mastery; process supervision for safety protocols
- Feasibility dependencies: secure lab integration; experimental safety certification; benchmarks for scientific validity; data lineage and reproducibility infrastructure
- Enterprise knowledge steward/digital twin
- Sectors: cross-industry, large enterprises
- Tools/products/workflows: memory graph spanning policies, systems, SOPs; user-models of teams; self-generated goals to resolve documentation drift and process bottlenecks; natural-language RL from employee feedback
- Feasibility dependencies: data governance (EU AI Act, SOC2, ISO 27001); change management; human-in-the-loop approvals; conflict resolution across departments
- Cybersecurity SOC copilot with self-evolving playbooks
- Sectors: cybersecurity, critical infrastructure
- Tools/products/workflows: episodic memory of incidents and TTPs; intrinsic rewards for coverage and false-positive reduction; process-supervised ToT for triage and response simulation
- Feasibility dependencies: strict containment (no autonomous destructive actions); red/blue team validation; adversarial robustness; chain-of-custody logging
- Portfolio and treasury co-pilots with long-horizon planning
- Sectors: finance, fintech
- Tools/products/workflows: System 3 for risk-aware strategy memory; hybrid rewards aligning risk, cost, and constraints; self-generated research goals in low-volatility periods
- Feasibility dependencies: regulatory approval; segregation of duties; latency and data-quality constraints; explainability for audits; sandboxing for execution
- Chronic-disease companion and care coordination
- Sectors: healthcare
- Tools/products/workflows: persistent user-model of symptoms and preferences; episodic memory of interventions and outcomes; intrinsic rewards to reinforce adherence and education; coordination with providers
- Feasibility dependencies: medical device/clinical validation; HIPAA/GDPR compliance; clear disclaimers; human clinician oversight; bias and safety monitoring
- Smart home/IoT orchestrator with open-ended optimization
- Sectors: consumer electronics, energy
- Tools/products/workflows: multi-device control with episodic memory of routines; hybrid rewards balancing comfort, cost, and energy; self-model of device capabilities and degradation
- Feasibility dependencies: secure device APIs; privacy protections; safety interlocks; resilience to concept drift in occupancy/behavior
- Digital civil servant for policy monitoring and compliance
- Sectors: public sector, regulated industries
- Tools/products/workflows: System 3 agent tracking evolving regulations; episodic memory of rulings/interpretations; intrinsic goals to reconcile conflicts and update compliance checklists; narrative justifications
- Feasibility dependencies: legal review; transparent audit trails; public accountability; procurement and standards alignment
Cross-cutting assumptions and dependencies
- Model reliability and cost: success depends on stable LLM APIs or on-prem models, plus budgeting for continuous operation.
- Data governance: episodic memories and reasoning traces can contain sensitive data; require PII/PHI redaction, retention policies, and encryption.
- Chain-of-thought handling: storing raw CoT may leak sensitive or proprietary logic; consider distilled plans or verified summaries instead of verbatim CoT in production.
- Safety and alignment: process supervision, sandboxing, and approval gates for high-impact actions are essential; clarify the scope of self-generated goals.
- Evaluation and drift: periodic audits of memory quality, user-model accuracy, and reward weighting; guard against “narrative lock-in” and confirmation bias.
- Tooling stack: vector DB (e.g., Pinecone/Weaviate), graph store (e.g., Neo4j), event broker (e.g., Kafka), orchestrators (e.g., LangGraph/DSPy), observability (e.g., LangSmith/W&B), ROS for robotics.
- Regulatory compliance: sector-specific constraints (EU AI Act, HIPAA, SOC/PCI, FINRA/SEC) can gate deployment scope and level of autonomy.
These applications translate Sophia’s System 3 into concrete products and workflows, leveraging its demonstrated gains in persistence, reasoning efficiency on recurring tasks (~80% reduction), and improved performance on high-complexity tasks (~40% gain), while making explicit the safeguards and infrastructure needed for feasible adoption.
Glossary
- Artificial Life: A field studying lifelike behavior in artificial systems, often focusing on autonomy and self-evolution. "By fusing psychological insight with a lightweight reinforcement-learning core, the persistent agent architecture advances a possible practical pathway toward artificial life."
- Autoregressive LLM: A LLM that generates text sequentially, token by token, conditioned on previous outputs. "an autoregressive LLM is queried with that prompt and produces a textual response;"
- Beam-style expansion: A search technique that explores multiple candidate paths in parallel, pruning low-scoring ones. "perform breadth- or beam-style expansion, each node storing a partial plan plus a value estimate ."
- Belief state: A structured representation of what an agent infers about another actor’s goals, knowledge, and affect. "User Modeling maintains a dynamic belief state that captures the interlocutor’s goals, knowledge level and affect, enabling socially aware planning and communication."
- Catastrophic forgetting: A phenomenon where learning new tasks degrades performance on previously learned tasks. "catastrophic forgetting—where learning new tasks causes abrupt degradation of performance on previously learned ones."
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step reasoning from an LLM. "This figure tracks the number of Chain-of-Thought reasoning steps required to resolve a recurring problem."
- Continual Learning (CL): Methods enabling models to learn sequentially from streams of data while retaining past knowledge. "Our work builds upon yet significantly extends the field of Continual Learning (CL)..."
- Discount factor: A parameter in reinforcement learning that down-weights future rewards relative to immediate ones. " is the discount factor"
- Emission distribution: A probabilistic mapping from latent states to observable outputs in a POMDP. "Observations from the space are drawn according to the emission distribution "
- Executive Monitor: A meta-level controller in System 3 that oversees goals, rewards, and process control. "System 3 is governed by an Executive Monitor—a small, always-on controller that receives every temporal event, reward, and reasoning trace as an asynchronous message and decides what happens next."
- Exploration–exploitation balance: The trade-off between trying novel actions and leveraging known good actions. "Adjusted exploration-exploitation balance by raising to 0.68 to prioritize external care."
- Extrinsic reward: Task-driven feedback originating from the environment or external objectives. "Hybrid Reward fuses extrinsic task feedback $R^{\text{ext}$ with intrinsic drives $R^{\text{int}$—curiosity, mastery and coherence—into a entirety $R^{\text{tot}$ via ."
- Forward Learning: The model’s acquisition of new knowledge during inference without updating weights. "Forward Learning refers to the model's ability to acquire and internalize new knowledge during the inference stage, without any weight updates."
- Graph store: A database optimized for storing entities and their relationships as nodes and edges. "an optional graph store for entity relations."
- Hybrid Reward Module: A mechanism that merges external feedback with internal drives to guide behavior. "A Hybrid Reward Module blends external task feedback with intrinsic signals—curiosity, coherence, and self-consistency—so the agent not only pursues immediate goals but also maximizes long-term competence."
- In-context learning: Adapting to new tasks using examples or information within the prompt, without model updates. "This is primarily achieved through in-context learning"
- Intrinsic Motivation: Internal drives (e.g., curiosity, mastery) that motivate self-directed exploration and learning. "Intrinsic Motivation... an internal reward generator that balances extrinsic task success with curiosity-driven exploration, enabling the agent to prioritize long-term competence over short-term gains."
- Memory Module: A subsystem that stores and retrieves episodic and task-scoped information for context. "A Memory Module maintains a structured memory graph of goals, experiences, and self-assessments, giving the agent a stable narrative identity that persists across reboots and task domains."
- Meta-cognition: Monitoring and regulating one’s own thought processes to improve reasoning. "Meta-cognition... a self-reflective monitor that inspects ongoing thought traces, flags logical fallacies, and selectively rewrites its own procedures;"
- Meta-policy: A higher-level policy that determines goals and reward structures guiding lower-level policies. "Formally the monitor realises the meta-policy"
- Natural Language Reinforcement Learning: Updating policies using reward signals expressed in natural language. "the latter can use Natural Language Reinforcement Learning~\citep{feng2024natural} to update the policy of System 2."
- Partially Observable Markov Decision Process (POMDP): A framework modeling decision-making under uncertainty with hidden states. "partially observable Markov Decision Process"
- Persistent Agent: An AI agent architecture designed for long-lived autonomy, identity continuity, and self-improvement. "Sophia, a “Persistent Agent” wrapper that grafts a continuous self-improvement loop onto any LLM-centric System 1/2 stack."
- Persistent-POMDP: A POMDP variant tailored to persistent agents with long-term goals and context. "We model the persistent agent's decision-making process as a Persistent, partially observable Markov Decision Process (Persistent-POMDP)"
- Process Supervision: Real-time critique and auditing of generated reasoning steps to ensure soundness. "Process Supervision. Every newly generated node is immediately critiqued by a secondary “guardian” LLM that runs a checklist prompt (logical consistency and safety)."
- Retrieval-Augmented Generation (RAG): Augmenting LLM outputs with retrieved external knowledge. "It can be achieved by Retrieval-Augmented Generation built on a vector database plus an optional graph store for entity relations."
- Reinforcement Learning from Human Feedback (RLHF): Training models using human-provided reward signals to shape behavior. "reinforcement learning from human feedback (RLHF)"
- Self-Model: An explicit internal representation of an agent’s capabilities, state, and creeds used for self-assessment. "A Self-Model records the agent’s capabilities, terminal creed and intrinsic state; gaps detected here are immediately feedback as new learning targets."
- State-transition kernel: The probabilistic function defining how actions change states in an MDP/POMDP. " is the state-transition kernel: ."
- System 1: The fast, heuristic layer handling perception and immediate actions. "System 1 embodies rapid, heuristic faculties—perception, retrieval, and instinctive response."
- System 2: The slow, deliberative reasoning layer performing analysis and planning. "System 2 forms the agent’s slow, deliberative workspace, where high–level problems are decomposed, evaluated, and solved before any action reaches the outside world."
- System 3: The meta-cognitive supervisory layer maintaining identity, auditing reasoning, and driving long-term adaptation. "we first propose a third stratum, System 3, that presides over the agent's narrative identity and long-horizon adaptation."
- Theory of Mind: Modeling others’ beliefs, desires, and intentions to enable social reasoning. "Theory-of-Mind... an explicit model of actors (humans or agents) that infers their beliefs, desires, and intentions to guide cooperation and learning;"
- Tree-of-Thought (ToT): A structured search over branching reasoning paths to evaluate and select plans. "Incoming problems are expanded into a Tree-of-Thought (ToT): the monitor spawns multiple LLM workers that perform breadth- or beam-style expansion..."
- Utility threshold: A value cutoff determining when a search node is good enough to stop expanding. "exceeds a learned utility threshold $\hat{V}(\mathbf{v}) > \tau_{\text{util}$"
- Value estimate: A predicted utility score assigned to a partial plan/node during search. "each node storing a partial plan plus a value estimate ."
- Vector database: A storage system indexing embeddings for efficient similarity search and retrieval. "built on a vector database plus an optional graph store for entity relations."
- Zero-shot: Performing tasks without task-specific training, relying on general model capabilities. "zero-shot limits of static architectures"
Collections
Sign up for free to add this paper to one or more collections.