- The paper introduces a unified framework for self-evolving agents, presenting four evolvable pillars that guide their progression toward Artificial Super Intelligence.
- It details adaptive mechanisms including real-time and retrospective learning, memory evolution, and dynamic tool creation for continual improvement.
- The survey emphasizes rigorous evaluation metrics and outlines open challenges in safety, scalability, and multi-agent coordination for evolving AI systems.
A Comprehensive Survey of Self-Evolving Agents: Foundations, Mechanisms, and the Path Toward Artificial Super Intelligence
Introduction and Motivation
The static nature of LLMs has become a critical bottleneck as these models are increasingly deployed in open-ended, interactive environments. The inability to adapt internal parameters or external behaviors in response to novel tasks, evolving knowledge, or dynamic contexts limits their utility in real-world applications. The surveyed work provides a systematic and comprehensive review of self-evolving agents—autonomous systems capable of continual learning and adaptation—framing them as a necessary step toward Artificial Super Intelligence (ASI). The survey organizes the field along the axes of what to evolve, when to evolve, and how to evolve, and establishes a unified theoretical and practical framework for the design, evaluation, and deployment of self-evolving agentic systems.
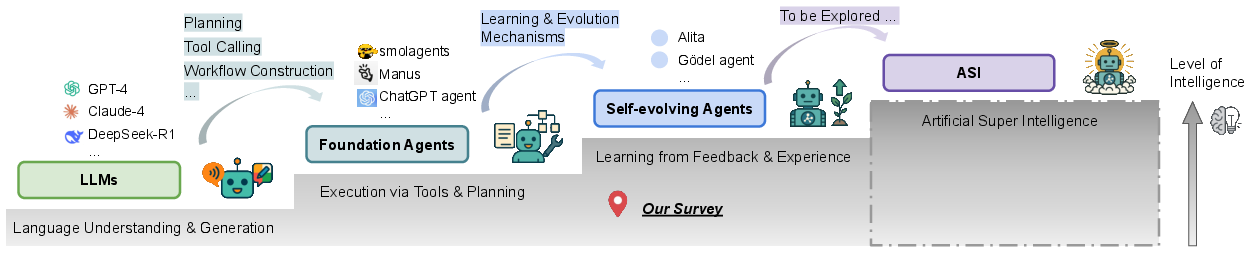
Figure 1: A conceptual trajectory from LLMs to foundation agents, self-evolving agents, and ultimately toward hypothetical ASI, with increasing intelligence and adaptivity.
Taxonomy and Evolutionary Landscape
The survey introduces a multi-dimensional taxonomy for self-evolving agents, decomposing the agent system into four evolvable pillars: model, context, tool, and architecture. Each pillar encapsulates distinct evolutionary mechanisms:
- Model: Parameter adaptation, policy refinement, and experience-driven learning.
- Context: Memory evolution and prompt optimization.
- Tool: Autonomous tool creation, mastery, and scalable management.
- Architecture: Optimization of single-agent and multi-agent system topologies.
This taxonomy is complemented by temporal (when to evolve) and methodological (how to evolve) dimensions, as well as the application domain (where to evolve).
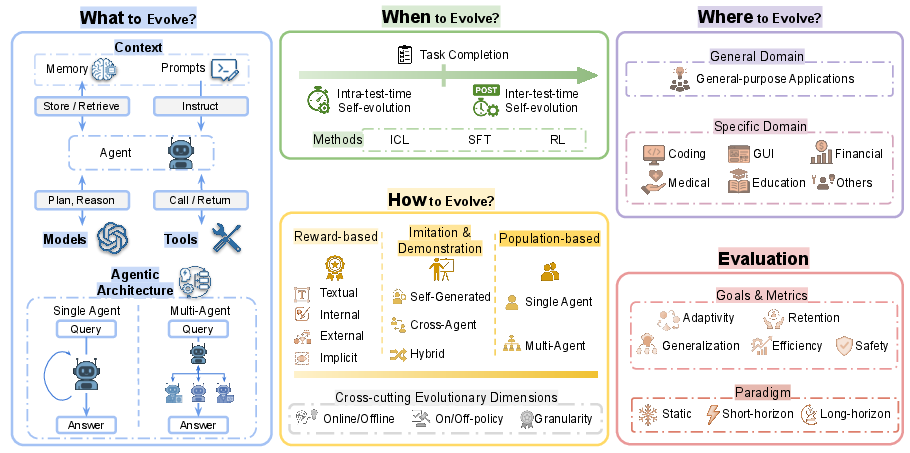
Figure 2: Overview of self-evolving agents across the dimensions of what, when, how, and where to evolve, and evaluation paradigms.
The evolutionary landscape is further contextualized by a chronological mapping of major research milestones, highlighting the rapid progression from static LLMs to increasingly autonomous, self-improving agentic systems.
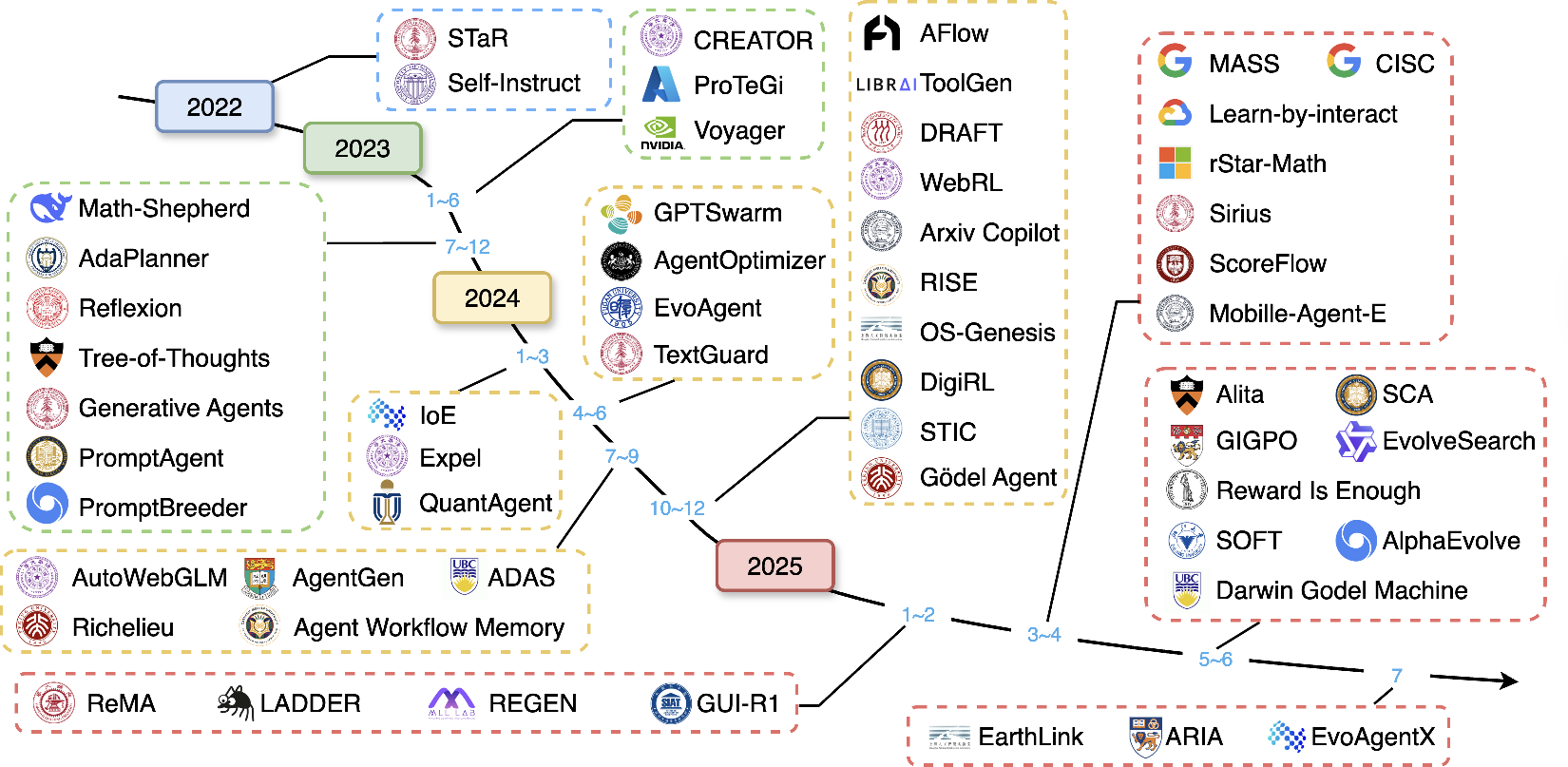
Figure 3: Evolutionary landscape of self-evolving agent frameworks from 2022 to 2025, showing advances in planning, tool use, and continual self-improvement.
The survey formalizes the agent-environment interaction as a POMDP, with the agent system defined as a tuple encompassing architecture, models, context, and toolset. The self-evolving strategy is a transformation function that updates the agent system based on observed trajectories and feedback, with the objective of maximizing cumulative utility across a sequence of tasks.
Self-evolving agents are distinguished from curriculum learning, lifelong learning, model editing, and unlearning by their ability to update both parametric and non-parametric components, perform active exploration, modify their own topology, and engage in self-reflection and self-evaluation. This expanded scope enables more flexible and robust adaptation in sequential and dynamic task settings.
What to Evolve: Components and Mechanisms
Model Evolution
Model evolution encompasses both policy refinement and experience-driven learning. Recent approaches enable agents to autonomously generate training data, perform self-supervised fine-tuning, and leverage interaction feedback for continual policy improvement. Notably, frameworks such as SCA and Self-Rewarding Self-Improving demonstrate significant gains in complex reasoning tasks by alternating between problem generation, solution, and self-assessment.
Context Evolution
Memory evolution and prompt optimization are critical for enabling agents to accumulate, retrieve, and generalize from past experiences. Advanced memory systems (e.g., SAGE, Mem0) implement dynamic indexing, semantic augmentation, and rule-based updates to maintain coherent and actionable long-term memory. Prompt optimization is treated as a search or optimization problem, with evolutionary and differentiable approaches enabling agents to autonomously refine instructions and workflow prompts.
The transition from tool use to tool creation is a defining feature of self-evolving agents. Systems such as Voyager and Alita autonomously expand their skill libraries through exploration and retrieval-augmented generation, while frameworks like CREATOR and SkillWeaver formalize tool synthesis and mastery. ToolGen reframes tool retrieval as a generative problem, leveraging the model's vocabulary for efficient selection and composition.
Architecture Evolution
Self-optimization of agentic architectures is realized through both node-level and system-level search. TextGrad and EvoFlow enable local and global workflow optimization, while AgentSquare and Darwin Godel Machine support modular design space exploration and recursive codebase modification. Multi-agent systems leverage workflow search (e.g., AFlow, ADAS) and multi-agent reinforcement learning (e.g., ReMA, GiGPO) for emergent coordination and meta-reasoning.
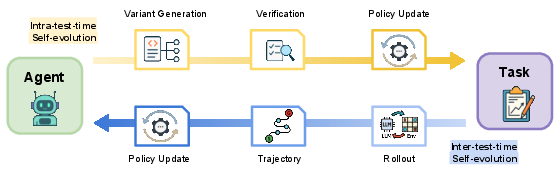
When to Evolve: Temporal Taxonomy
The temporal aspect of self-evolution is categorized into intra-test-time and inter-test-time adaptation:
How to Evolve: Learning Paradigms and Cross-Cutting Dimensions
Reward-Based Self-Evolution
Reward design is central to self-evolution, with feedback signals ranging from natural language critiques (Reflexion, AdaPlanner) to internal confidence metrics and external environment rewards. Implicit reward frameworks demonstrate that LLMs can perform in-context RL using scalar signals embedded in the context window, revealing an inherent capacity for self-improvement without explicit supervision.

Figure 5: Reward-based self-evolution strategies, categorized by feedback type and source.
Imitation and Demonstration Learning
Imitation learning leverages self-generated or cross-agent demonstrations for bootstrapping reasoning and multimodal capabilities. Adaptive data sampling, verifier-guided self-training, and confidence-based demonstration selection are employed to ensure high-quality exemplars and robust learning.
Population-Based and Evolutionary Methods
Population-based methods maintain multiple agent variants, enabling parallel exploration and the emergence of novel strategies through selection, mutation, and competition. Single-agent evolution (e.g., DGM, GENOME) and multi-agent evolution (e.g., EvoMAC, Puppeteer) support both code-level and architectural adaptation, as well as knowledge-based evolution via shared memory and case-based learning.
Cross-Cutting Dimensions
The survey systematically analyzes self-evolution methods along axes such as online/offline learning, on/off-policy consistency, and reward granularity (process-based, outcome-based, hybrid). These dimensions inform trade-offs in sample efficiency, stability, and scalability.
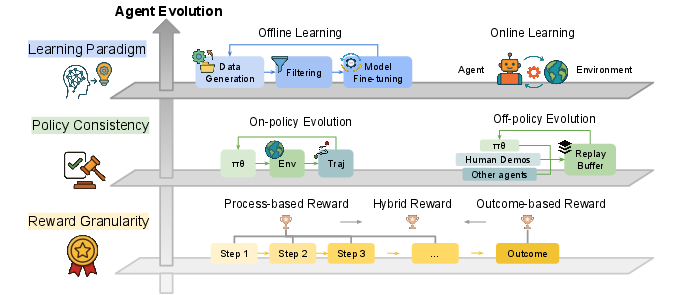
Figure 6: Cross-cutting evolutionary dimensions: learning paradigm, policy consistency, and reward granularity.
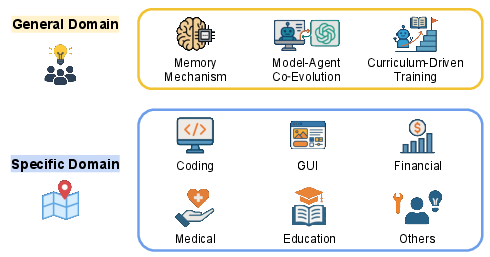
Where to Evolve: Application Domains
Self-evolving agents are applied in both general-purpose and specialized domains:
Evaluation: Metrics and Paradigms
Evaluating self-evolving agents requires metrics that capture adaptivity, retention, generalization, efficiency, and safety. The survey distinguishes between static assessment, short-horizon adaptation, and long-horizon lifelong learning evaluation, emphasizing the need for longitudinal and dynamic benchmarks to assess continual learning, catastrophic forgetting, and knowledge transfer.
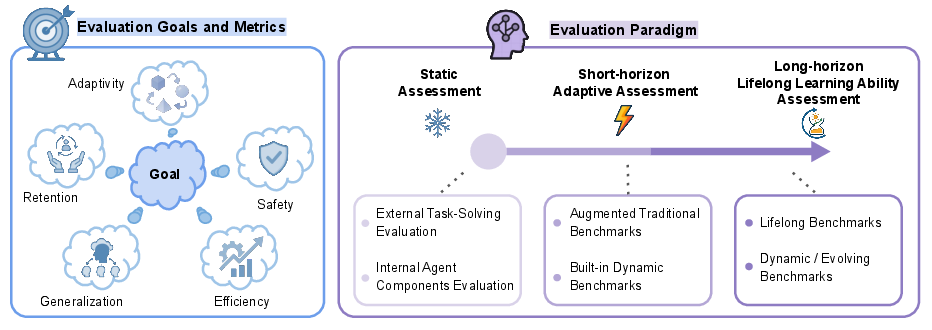
Figure 8: Evaluation angles for self-evolving agents, spanning adaptivity, retention, generalization, safety, efficiency, and evaluation paradigms.
Open Challenges and Future Directions
The survey identifies several open challenges and research directions:
- Personalization: Addressing the cold-start problem, long-term user modeling, and bias mitigation in personalized self-evolving agents.
- Generalization: Designing scalable architectures, enabling cross-domain adaptation, mitigating catastrophic forgetting, and improving knowledge transferability.
- Safety and Control: Ensuring safe, controllable evolution in the presence of ambiguous instructions, malicious environments, and privacy risks.
- Multi-Agent Ecosystems: Balancing individual and collective reasoning, developing efficient collaboration frameworks, and establishing dynamic evaluation protocols for multi-agent systems.
Conclusion
Self-evolving agents represent a paradigm shift toward dynamic, adaptive, and robust AI systems. The surveyed work provides a comprehensive framework for understanding, designing, and evaluating self-evolving agents, highlighting the interplay between model, context, tool, and architecture evolution, as well as the temporal and methodological dimensions of adaptation. Realizing the full potential of self-evolving agents will require advances in continual learning, safe autonomous evolution, and co-evolution of agents and environments, ultimately paving the way toward Artificial Super Intelligence.