IC-Effect: Precise and Efficient Video Effects Editing via In-Context Learning
Abstract: We propose \textbf{IC-Effect}, an instruction-guided, DiT-based framework for few-shot video VFX editing that synthesizes complex effects (\eg flames, particles and cartoon characters) while strictly preserving spatial and temporal consistency. Video VFX editing is highly challenging because injected effects must blend seamlessly with the background, the background must remain entirely unchanged, and effect patterns must be learned efficiently from limited paired data. However, existing video editing models fail to satisfy these requirements. IC-Effect leverages the source video as clean contextual conditions, exploiting the contextual learning capability of DiT models to achieve precise background preservation and natural effect injection. A two-stage training strategy, consisting of general editing adaptation followed by effect-specific learning via Effect-LoRA, ensures strong instruction following and robust effect modeling. To further improve efficiency, we introduce spatiotemporal sparse tokenization, enabling high fidelity with substantially reduced computation. We also release a paired VFX editing dataset spanning $15$ high-quality visual styles. Extensive experiments show that IC-Effect delivers high-quality, controllable, and temporally consistent VFX editing, opening new possibilities for video creation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces IC-Effect, a smart tool that edits videos by adding visual effects—like flames, sparkles, or cartoon characters—based on simple text instructions (for example, “make sparks trail behind the skateboard”). The main goal is to add these effects cleanly and realistically while keeping the original video’s background and motion unchanged.
The Big Questions
The researchers focused on three clear challenges:
- How can we add effects that look natural without changing the original video’s background or colors?
- How can we follow text instructions exactly (like where and when an effect should appear)?
- How can we learn different effect styles (like fire vs. particles) from only a few example pairs of “before and after” videos?
How IC-Effect Works
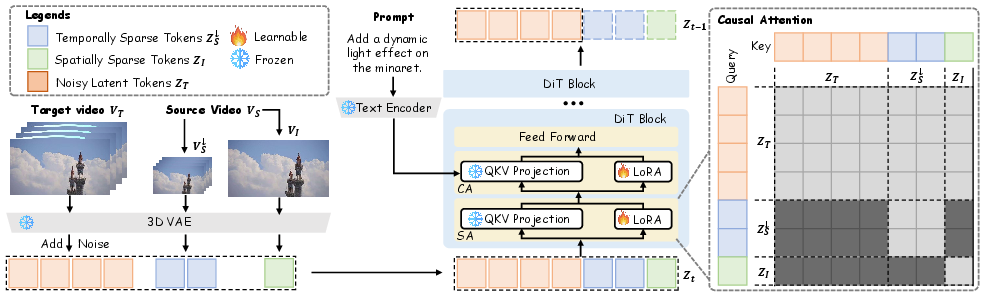
IC-Effect is built on top of a Diffusion Transformer (“DiT”), a type of AI that is great at making and editing videos. Think of it like a careful artist who refines a noisy sketch into a polished clip, step by step, while paying attention to both space (where things are) and time (how things move).
Using the Original Video as a Guide (In-Context Conditioning)
- Idea: Treat the original video like a “clean blueprint” the model can constantly refer to.
- Analogy: You’re tracing over a transparent sheet laid on top of the original video. The AI copies what should stay the same (background, motion) and only draws new effects where the text says.
- How: The model places “clean tokens” from the source video next to “noisy tokens” it’s editing. Attention (the model’s way of focusing) lets the edited part look at the original so it doesn’t drift or flicker.
Keeping Clean and Noisy Parts Separate (Causal Attention)
- Problem: If the clean guide and the noisy editable part mix too much, the result gets messy.
- Solution: A rule called “causal attention” lets the editable part look at the clean guide, but not the other way around.
- Analogy: The student can look at the answer key, but the answer key doesn’t get scribbled on.
Two-Stage Training with Effect-LoRA
- Step 1: Train a general “Video-Editor” to understand text instructions well across many kinds of edits.
- Step 2: Add small, lightweight “adapters” (LoRA modules) that specialize the model for a specific effect style (like flames or particles) using just a few paired examples.
- Analogy: First you learn how to follow directions in art class; then you clip on a small “style lens” to master a particular technique. LoRA is like a tiny add-on knob that tweaks the model without retraining everything.
Spatiotemporal Sparse Tokenization (Saving Compute)
- Problem: Long, high-resolution videos take a lot of memory and time to process.
- Solution: IC-Effect picks smart “summaries” of the source video:
- Downsampled (smaller) video tokens to capture motion over time.
- High-quality tokens from the first frame to capture fine details (textures, colors).
- Analogy: Instead of reading every page, the model reads a summary plus a detailed cover image.
- Position Correction: A small fix ensures these summaries line up with the right places in the edited video, avoiding misalignment or wobbly edges.
What Did They Build and Test?
- A new paired dataset for video effects editing with 15 different effect styles (like flames, anime clones, light particles, and bouncing elements).
- Each sample includes:
- The original video,
- The edited video with the effect,
- A text description explaining what the effect is and where/when it appears.
- They compared IC-Effect against several well-known video editing tools and tested both:
- General editing tasks (change style, adjust colors, etc.),
- Special effects editing (add dynamic VFX precisely).
What Did They Find?
IC-Effect performed strongly in several areas:
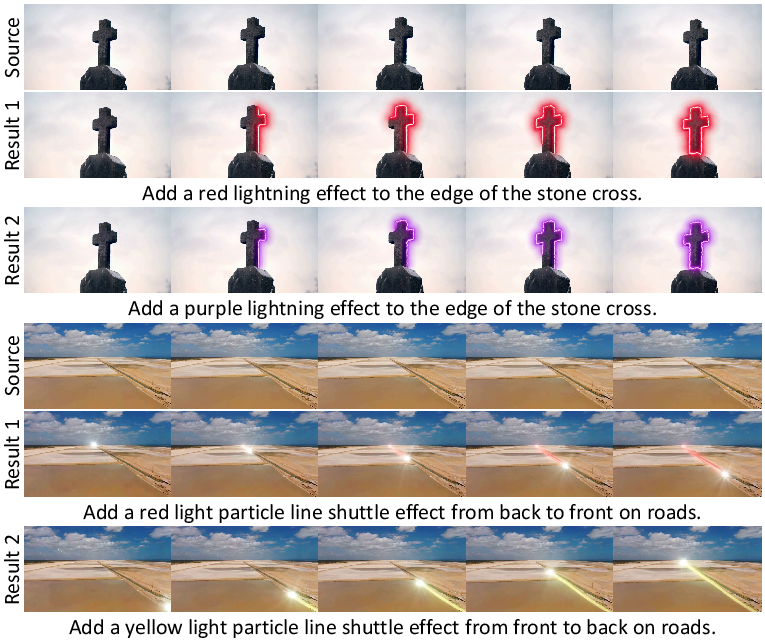
- High quality: The added effects look natural and sharp.
- Excellent background preservation: The original scenery and colors stay stable, without flicker or drift.
- Better instruction following: Edits match the text prompts closely (where and when the effects should happen).
- Time consistency: Motion is smooth across frames.
- Efficiency: Thanks to sparse tokenization, it uses less compute while keeping high fidelity.
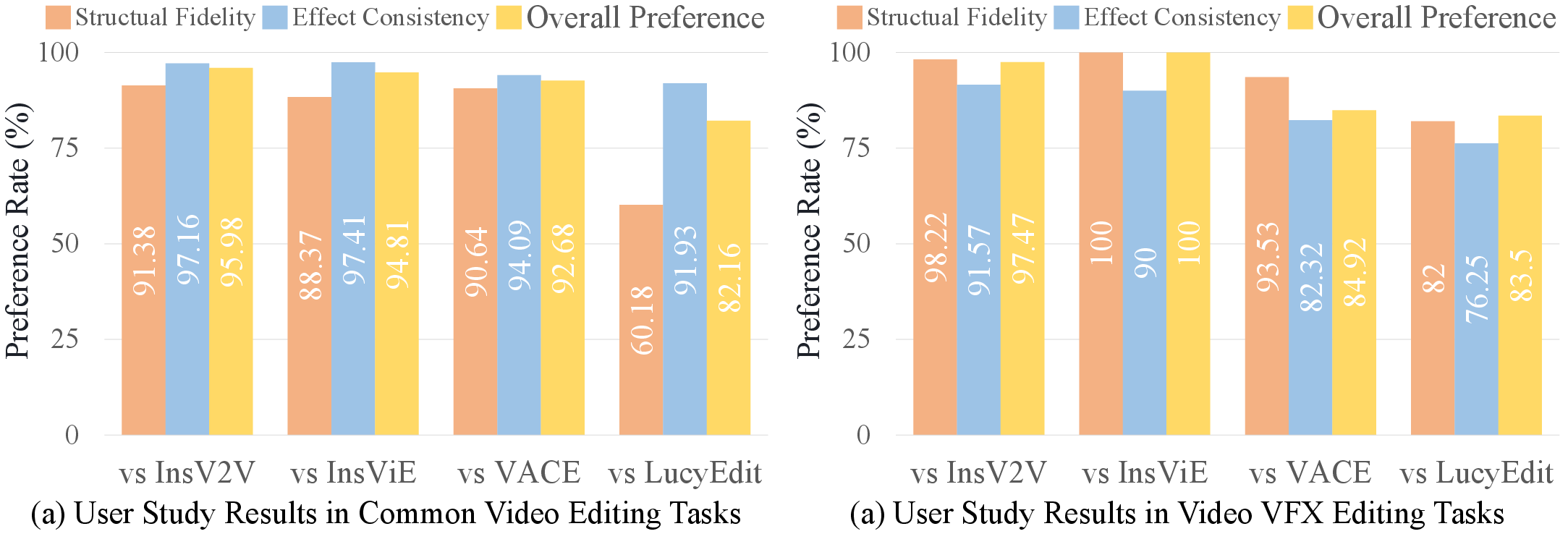
- User studies: People preferred IC-Effect’s results over other methods for both accuracy and overall look.
- Ablation tests (turning off parts of the system): Each piece (in-context conditioning, Effect-LoRA, sparse tokens) clearly contributes; removing any of them harms quality, consistency, or control.
Why This Matters
- For creators: Filmmakers, YouTubers, gamers, and students can add complex effects quickly without expensive tools or manual masking.
- Lower cost, faster turnaround: Less time spent on tedious editing and compositing.
- Personalized and precise: You can describe exactly what you want, and the model does it while keeping your original video intact.
- A foundation for future tools: The dataset and approach help the community build better, more controllable video editors and effects generators.
In short, IC-Effect shows how to add cool, dynamic visual effects to videos accurately and efficiently, guided by simple text instructions, while protecting the original look and motion of the scene.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper; each point specifies a concrete direction for future work.
- Dataset scale and diversity: The VFX dataset is small (15 effect types; “over 20” curated videos vs. a later 50-video benchmark) and its exact size, composition, licenses, and release status are inconsistent. Build a larger, publicly available benchmark with diverse scenes (fast camera motion, occlusions, lighting changes, complex backgrounds), longer durations, and higher resolutions.
- Pretraining data transparency: The “self-constructed video editing dataset” used to pretrain the Video-Editor is not described (size, domains, licenses, curation). Provide full details and a reproducible recipe to enable fair comparisons and replication.
- Text instruction representation: The text encoder and the format/semantics of “spatiotemporal annotations” are unspecified. Formalize a schema (e.g., referring expressions, coordinates, temporal segments), document the encoder, and evaluate how different instruction formats affect localization and effect placement.
- Precise localization without masks: The method claims automated placement of effects from text alone, but does not quantify localization accuracy or failure modes. Integrate and evaluate lightweight localization aids (referring-expression grounding, bounding boxes, segmentation/tracking) and measure placement error against ground-truth regions.
- Background preservation measurement: The paper asserts “entirely unchanged” backgrounds but lacks pixel-level preservation metrics. Report PSNR/SSIM/LPIPS between source and edited video on non-effect regions, and provide difference maps to quantify unintended drift.
- Robustness to motion and occlusion: The dataset is curated to be “carefully aligned in viewpoint”; robustness under fast motion, strong parallax, occlusions, motion blur, and sudden scene changes remains unclear. Design stress tests and report performance across these challenging regimes.
- Physical and photometric consistency: The approach does not model lighting, shadows, depth, or occlusion reasoning for effects interacting with the scene. Explore multimodal conditioning (depth, normals, optical flow, scene lighting estimates) or physically inspired constraints and evaluate improvements in realism.
- STST design choices: Spatiotemporal sparse tokenization is proposed, but the selection strategy (which frames, downsampling factor n, spatial sampling pattern) and its sensitivity are not characterized. Systematically ablate temporal sampling rates, spatial sparsity layouts, and adaptive/keyframe selection policies.
- Position correction clarity: The spatiotemporal position correction formulation is underspecified (broken equation, undefined parameters), and its impact lacks rigorous analysis. Precisely define the mapping, provide implementation details, and compare alternative alignment strategies.
- Causal attention analysis: The mask-based causal attention is introduced without theoretical or empirical study of gradients, information flow, or alternatives (e.g., gated fusion, cross-attention). Analyze its effects and compare with other conditioning isolation mechanisms.
- Efficiency and scalability: Despite STST, inference remains heavy (≈2790s and 64 GB for 81 frames at 480×832). Investigate streaming generation, token-pruning, low-rank/quantization, distillation, and long-context attention to reach practical throughput and memory for longer, higher-resolution videos.
- Long-duration and high-resolution generalization: Training and evaluation focus on 81-frame clips and sub-HD resolutions. Validate performance on multi-minute videos and 1080p/4K outputs, and study scaling behavior and failure modes.
- Effect-LoRA scalability: Each effect category requires its own LoRA; composition of multiple effects, simultaneous multi-effect editing, conflict resolution, and LoRA merging/mixing strategies are not explored. Develop methods for multi-effect control and evaluate interference/catastrophic forgetting.
- Few-shot/zero-shot effect generalization: The approach fine-tunes per effect with paired data but does not assess zero-shot or cross-style transfer. Measure how performance degrades with fewer samples and explore meta-learning/in-context strategies for rapid customization.
- Control strength and edit scope: There is no explicit mechanism to trade off effect intensity vs. background preservation or to confine edits spatially/temporally. Introduce tunable controls (e.g., guidance scales, regional masks, temporal windows) and quantify their effects.
- Evaluation metrics adequacy: Reliance on CLIP/ViCLIP, VBench sub-metrics, and GPT-4o scores may not capture VFX-specific fidelity (e.g., visual blending, temporal anchoring). Develop and adopt effect-specific metrics (background change IoU, temporal anchoring error, visual blending quality) and larger, blinded user studies.
- Baseline fairness and breadth: Baselines were adapted by fine-tuning attention layers on the same small VFX dataset; stronger baselines (mask-guided, control-net–augmented, depth/flow-conditioned DiTs) and commercial-grade tools are absent. Expand the comparative suite and report sensitivity to fine-tuning protocols.
- Failure case analysis: The paper lacks systematic characterization of typical failures (misplacement, color drift, temporal flicker, over-editing). Provide a taxonomy of errors, quantitative rates, and diagnostics to guide method improvements.
- Reproducibility details: Key training choices (loss weighting for rectified flow, noise schedule, positional embeddings specifics, LoRA insertion points) are incomplete. Release code, configs, and seeds to enable reproducible training and evaluation.
- Ethical and legal considerations: Dataset sources are “from the Internet,” with no discussion of licensing, consent, bias, or misuse risks in video manipulation. Document data provenance, licenses, and ethical safeguards, and explore watermarking or edit provenance tracking.
Practical Applications
Practical Applications of IC-Effect
Below are actionable, real-world applications derived from the paper’s findings and methods. Each item notes sector(s), potential tools/workflows, and feasibility assumptions or dependencies.
Immediate Applications
These can be deployed now, primarily in offline/cloud workflows with high-end GPUs.
- Precise, instruction-guided VFX augmentation for post-production (Media/Entertainment)
- What: Insert flames, particles, cartoons, and stylized overlays into existing footage while strictly preserving background geometry and motion, reducing manual rotoscoping/compositing.
- Tools/workflows: NLE/DAW plug-ins (Premiere/After Effects/Resolve), Python SDK/REST API for batch jobs; Effect-LoRA “effect packs” per show or franchise; previsualization pipeline to iterate effects quickly.
- Assumptions/dependencies: Offline/cloud inference; high compute (reported ~64 GB GPU and tens of minutes per 81-frame 480×832 clip); licensing for base T2V model (e.g., Wan 2.2); LoRA fine-tuning for new effect families; stable input (benefits from stabilization).
- Creative variant generation for advertising and e-commerce (Advertising/Marketing/Retail)
- What: Produce branded particle trails, glows, and highlight effects across product videos with minimal background drift for A/B testing and personalization.
- Tools/workflows: “Brand LoRA” libraries with locked palettes/shapes; DAM integration; templated prompts for batch processing; QC using CLIP/ViCLIP/VBench metrics.
- Assumptions/dependencies: Brand governance approvals; watermarking/disclosure policies; reliable prompt templates; cloud GPU budget.
- Trailer/cinematics enhancement and previz (Gaming/Virtual Production)
- What: Rapidly explore stylized cues consistent with camera motion; iterate effects that match scene timing and blocking without breaking continuity.
- Tools/workflows: Unreal/Unity toolchain bridge; ingest of editorial timelines and camera tracks; per-sequence Effect-LoRA.
- Assumptions/dependencies: Scene metadata ingestion; compute availability; effect-specific paired examples for best fidelity.
- Creator tools for precise overlays without background drift (UGC/Social/Creator Economy)
- What: Cloud-based editors that add dynamic effects via text prompts while keeping the scene intact (e.g., emphasizing action, adding subtle particles).
- Tools/workflows: Web app with Effect-LoRA marketplace; preset prompts; auto-QA and content moderation filters; queue-based batch service.
- Assumptions/dependencies: Not real-time on consumer devices; platform safety policies; cost control via STST and caching.
- Instructional and corporate video augmentation (Education/Enterprise Communications)
- What: Overlay attention-guiding effects (trails, highlight glows, schematic particles) to illustrate processes or draw focus, without unintended scene changes.
- Tools/workflows: PowerPoint/Keynote export -> batch effect insertion -> replace shots; prompt templates for training content; governance review.
- Assumptions/dependencies: Offline latency acceptable; style packs aligned to corporate branding.
- Newsroom/compliance overlays with provenance (Media/Journalism)
- What: Add emphasis graphics or censoring masks while preserving the unedited background for auditability; integrate provenance trails.
- Tools/workflows: NLE plug-in with C2PA signing at export; structured prompt templates; audit logs tracking effect prompts and LoRA IDs.
- Assumptions/dependencies: Organizational standards for disclosure; watermarking/provenance infrastructure.
- Academic benchmarking and reproducible research (Academia)
- What: Use the paired VFX dataset (15 effect types; source-edited-text triplets) as a benchmark for VFX editing and controllable generation.
- Tools/workflows: Standardized evaluation with CLIP/ViCLIP/VBench and GPT-based ratings; ablation on causal attention, STST, and Effect-LoRA ranks.
- Assumptions/dependencies: Dataset licensing and availability; fair-use of base models; community baselines.
- Efficient conditioning patterns for DiT models (Software/ML Systems)
- What: Reuse spatiotemporal sparse tokenization and causal attention masking to cut quadratic attention cost in token-conditioned video tasks.
- Tools/workflows: Reference implementation integrated into DiT backbones; profile-and-trim pipelines for long or high-res clips.
- Assumptions/dependencies: Access to DiT architectures; careful position correction to avoid misalignment.
Long-Term Applications
These require further research, optimization, or ecosystem development (e.g., real-time performance, broader effect coverage, standardization).
- Near-real-time VFX for live streaming and AR (Media/Streaming/AR)
- What: On-the-fly insertion of dynamic effects on live video with strict background preservation for streamers and AR glasses.
- Tools/workflows: Distilled/quantized DiT; sparse attention kernels; hardware accelerators; low-latency prompting UI.
- Assumptions/dependencies: Aggressive model compression and caching; specialized GPUs/NPUs; robust latency SLAs.
- On-device mobile video effects editors (Consumer Software/Handsets)
- What: Smartphone apps enabling high-fidelity effects without cloud roundtrips.
- Tools/workflows: Edge-optimized models (int8/FP8), tiled inference, first-frame caching, LoRA switching on-device.
- Assumptions/dependencies: NPU support; memory- and energy-aware inference; simplified effect taxonomy vs cloud.
- Unified, multimodal controllable video editing (Software/Creative Suites)
- What: Extend in-context conditioning to support depth, flow, camera trajectory, and sketches, unifying VFX, relighting, object insertion, and style edits in one editor.
- Tools/workflows: Multimodal token concatenation with improved sparse routing; editor nodes for condition sources; layered Effect-LoRA stacks.
- Assumptions/dependencies: Larger, diverse training corpora; token-sparsity schedulers; robust position correction across modalities.
- Interactive direction in virtual production (Film/TV/VP)
- What: Directors issue natural-language “notes” during shoots to preview plausible effects on LED volumes or monitors.
- Tools/workflows: Tight integration with stage tracking and camera metadata; predictive caching; human-in-the-loop approval.
- Assumptions/dependencies: Sub-minute turnaround per shot; stable tracking; safety rails to avoid hallucinations.
- Dynamic creative optimization at scale (Advertising/AdTech)
- What: Auto-generate thousands of effect variants aligned to audience segments, contexts, and brand rules; optimize in-market.
- Tools/workflows: Programmatic API; effect policy engine (colors/motifs/placements); online learning feedback loops.
- Assumptions/dependencies: Cost containment; brand safety; A/B measurement infrastructure.
- Provenance, watermarking, and disclosure standards (Policy/Trust & Safety)
- What: Embed robust provenance (e.g., C2PA) and watermarks at generation time; standardize disclosures for edited vs. synthetic VFX.
- Tools/workflows: Mandatory metadata, cryptographic signing, and verification APIs; newsroom and platform policies.
- Assumptions/dependencies: Industry adoption; resilient watermarking vs compression/crops; regulator alignment.
- Data-centric tooling for VFX LoRA creation (Tools/Platforms)
- What: Turn small, paired effect samples into reliable Effect-LoRA packs with QA gates and safety filters.
- Tools/workflows: Semi-automatic triplet collection/cleaning; misalignment diagnostics; CC licensing checks; human review UI.
- Assumptions/dependencies: Access to curated paired data; IP clearance; repeatable evaluation suites.
- Assistive editing for accessibility and learning (Education/Accessibility)
- What: Effects that highlight motion, speakers, or procedures for low-vision users or learners; synchronized with captions.
- Tools/workflows: Semantic prompts tied to transcripts; motion-triggered overlays; educator-facing presets.
- Assumptions/dependencies: Accurate ASR/diarization; alignment with accessibility guidelines; latency acceptable for classroom use.
- Synthetic data generation for video understanding (Academia/AI Training)
- What: Create controlled effect overlays to stress-test motion, tracking, and segmentation models under visual clutter.
- Tools/workflows: Parametric prompt sweeps; labels for effect regions and timings; public benchmarks of robustness.
- Assumptions/dependencies: Proper labeling pipelines; domain gap analyses; licensing for redistribution.
- Compliance-friendly editorial tooling (Media/Regulated Industries)
- What: Precision edits that guarantee non-target regions are unchanged for audit; “diff” certificates proving background integrity.
- Tools/workflows: Region-diff validators; structural preservation scores; compliance reports attached to assets.
- Assumptions/dependencies: Reliable metrics to satisfy auditors; storage of source/edited pairs; cryptographic hashing.
Notes on feasibility across applications
- Compute and latency: Current reported setup suggests offline cloud use with large GPUs; STST halves cost but is not yet real-time.
- Effect coverage: Out-of-the-box effects limited to the 15 dataset styles; new effects need small paired data and Effect-LoRA fine-tuning.
- Model dependencies: Access to a DiT-based T2V backbone (e.g., Wan 2.2) and a compatible VAE; licensing and redistribution terms apply.
- Input quality: Best performance on stable, well-exposed footage; shaky or low-light videos may require stabilization/preprocessing.
- Safety/IP: Risk of misleading edits; adopt watermarking/provenance and brand/content policies; ensure rights for source footage and effect assets.
Glossary
- 3D full attention: Transformer attention operating jointly over spatial and temporal dimensions of video tokens to capture cross-frame dependencies. "employ 3D full attention to capture complex dependencies"
- 3D rotary positional embeddings: Rotational positional encoding extended to three dimensions to encode spatiotemporal positions in token sequences. "Both representations share the same 3D rotary positional embeddings,"
- 3D VAE: A variational autoencoder that encodes and decodes video volumes into latent representations across space and time. "Specifically, we encode the source and edited video into latent representations and through a 3D VAE."
- Attention mask: A matrix used in self-attention to restrict which tokens can attend to others, enforcing constraints like causality. "We realize this causal attention using a specifically designed attention mask:"
- Bidirectional attention: An attention setup where tokens can attend to all other tokens in both forward and backward directions. "Within the bidirectional attention of DiT, interactions between latent noise and conditional tokens can cause clean conditional tokens to be fused with noisy representations, thereby degrading the quality of the generated results."
- Camera trajectories: Representations of camera motion over time used as conditioning signals for controllable generation. "FullDiT~\cite{ju2025fulldit} achieves highly controllable text-to-video generation by integrating multimodal conditions like depth maps and camera trajectories."
- Causal attention: An attention mechanism that restricts certain tokens (e.g., condition tokens) from attending to noisy or future tokens to prevent degradation. "To prevent this, we introduce a causal attention mechanism."
- CLIP Image Similarity (CLIP-I): A metric using the CLIP image encoder to measure frame-to-frame similarity for temporal consistency. "We employ CLIP~\cite{radford2021learning} Image Similarity (CLIP-I) to measure temporal consistency by computing the cosine similarity between consecutive frames of the edited videos using the CLIP image encoder."
- Depth maps: Per-pixel estimates of scene depth used as conditioning signals for video generation or editing. "FullDiT~\cite{ju2025fulldit} achieves highly controllable text-to-video generation by integrating multimodal conditions like depth maps and camera trajectories."
- DiT (Diffusion Transformer): A transformer-based architecture for diffusion models that models videos as token sequences and replaces U-Nets. "The T2V model built upon the DiT~\cite{peebles2023scalable} architecture mainly relies on attention mechanisms,"
- Effect-LoRA: A low-rank adaptation module fine-tuned to capture and apply a specific visual effect’s editing style. "Effect-LoRA adopts a low-rank LoRA specifically designed to capture the editing style of a single video effect."
- Flow matching loss: A training objective from rectified flow models that guides denoising by matching learned vector fields to target data. "During training, we apply the flow matching loss~\cite{esser2024scaling} only to the latent tokens to guide the model in learning high-quality and structurally consistent video VFX editing."
- In-context learning (ICL): The ability of a model to adapt its behavior to new tasks using provided examples or conditions without changing weights. "In-context learning (ICL) enables models to rapidly adapt to new tasks with only a few examples and is widely adopted in LLMs"
- Latent tokens: Tokenized representations in a compressed latent space used by the model for generation and editing. " denotes the noisy latent tokens and represents clean conditional tokens."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects trainable low-rank matrices while freezing base weights. "LoRA~\cite{hulora} enables efficient fine-tuning of large-scale pre-trained models by introducing trainable low-rank matrices while keeping the original weights frozen."
- Mask-based editing: Approaches that use user-provided masks to constrain edits to selected regions of frames. "Mask-based editing methods~\cite{bian2025videopainter, gao2025lora} can preserve the unmasked regions, but they rely on pixel-accurate masks,"
- Optical flow: A dense motion field estimating pixel displacement between consecutive frames. "encode structural priorsâsuch as depth or optical flowâvia auxiliary modules."
- Patchified tokens: Tokens obtained by splitting latent feature maps into fixed-size patches for transformer processing. " and are patchified and concatenated into a unified token sequence,"
- Spatiotemporal position correction: A technique to align sparse condition tokens with corresponding spatial and temporal positions in the generation space. "we propose a spatiotemporal position correction technique."
- Spatiotemporal sparse tokenization (STST): A strategy that sparsifies condition tokens across space and time to reduce computation while preserving key guidance. "we introduce a spatiotemporal sparse tokenization (STST) strategy that converts the source video into a set of spatiotemporally sparse tokens, effectively reducing the number of conditional tokens processed by the T2V model and improving inference efficiency."
- Text-to-video (T2V): Generative modeling that produces video content conditioned on textual descriptions. "Recent advances in text-to-video (T2V) generation~\cite{wan2025wan, yang2025cogvideox, kong2024hunyuanvideo} open new possibilities for automated VFX creation"
- U-Net backbone: A convolutional encoder–decoder architecture commonly used in diffusion models, here noted as limited for long-term dynamics. "However, the U-Net backbone struggles with long-term dynamics."
- VBench: A standardized benchmarking toolkit for evaluating video generation/editing quality across multiple sub-metrics. "We adopt multiple sub-metrics from the VBench~\cite{huang2024vbench} toolkit, including Smoothness, Dynamic Degree, and Aesthetic Quality,"
- ViCLIP: A video-level CLIP encoder used to measure semantic alignment between videos and text. "we use both the CLIP~\cite{radford2021learning} encoder and the ViCLIP~\cite{wang2024internvid} encoder to calculate frame-level and video-level similarities"
- Visual Effects (VFX): Artificial visual elements composited into video to create phenomena like flames or particles. "Visual Effects (VFX) aim to create videos or edit existing ones by incorporating visually compelling elements such as flames, cartoon characters, or particle effects."
Collections
Sign up for free to add this paper to one or more collections.

