Unified Video Editing with Temporal Reasoner
Abstract: Existing video editing methods face a critical trade-off: expert models offer precision but rely on task-specific priors like masks, hindering unification; conversely, unified temporal in-context learning models are mask-free but lack explicit spatial cues, leading to weak instruction-to-region mapping and imprecise localization. To resolve this conflict, we propose VideoCoF, a novel Chain-of-Frames approach inspired by Chain-of-Thought reasoning. VideoCoF enforces a ``see, reason, then edit" procedure by compelling the video diffusion model to first predict reasoning tokens (edit-region latents) before generating the target video tokens. This explicit reasoning step removes the need for user-provided masks while achieving precise instruction-to-region alignment and fine-grained video editing. Furthermore, we introduce a RoPE alignment strategy that leverages these reasoning tokens to ensure motion alignment and enable length extrapolation beyond the training duration. We demonstrate that with a minimal data cost of only 50k video pairs, VideoCoF achieves state-of-the-art performance on VideoCoF-Bench, validating the efficiency and effectiveness of our approach. Our code, weight, data are available at https://github.com/knightyxp/VideoCoF.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
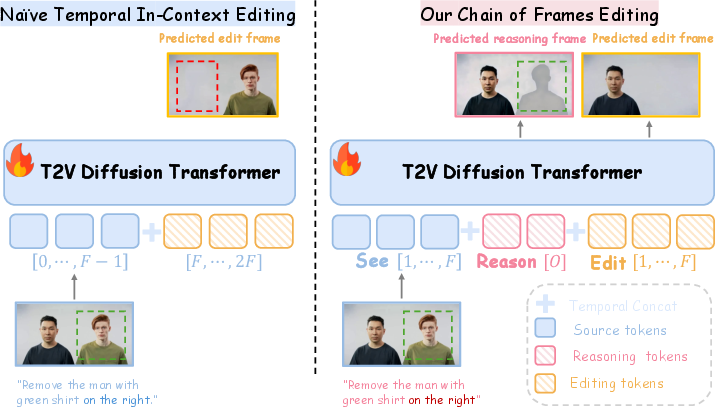
This paper introduces VideoCoF, a new way for computers to edit videos more smartly. The main idea is simple: before changing anything in a video, the model first looks carefully, then thinks about exactly where to make the change, and only then does the edit. The authors call this “see → reason → edit,” like a student who first reads a question, figures out what part of the text is relevant, and then writes the answer.
What problems are the researchers trying to solve?
In video editing, there’s a trade-off:
- Some methods are very precise but need extra tools like masks (you have to draw exactly where to edit). That makes them less flexible and harder to use.
- Other methods don’t require masks and can do many kinds of edits, but they often change the wrong parts or don’t follow instructions closely, especially when multiple objects are in the scene.
The big question: Can we get both accuracy and flexibility without asking the user to provide masks?
How does VideoCoF work?
Think of VideoCoF as a careful editor with a simple three-step plan:
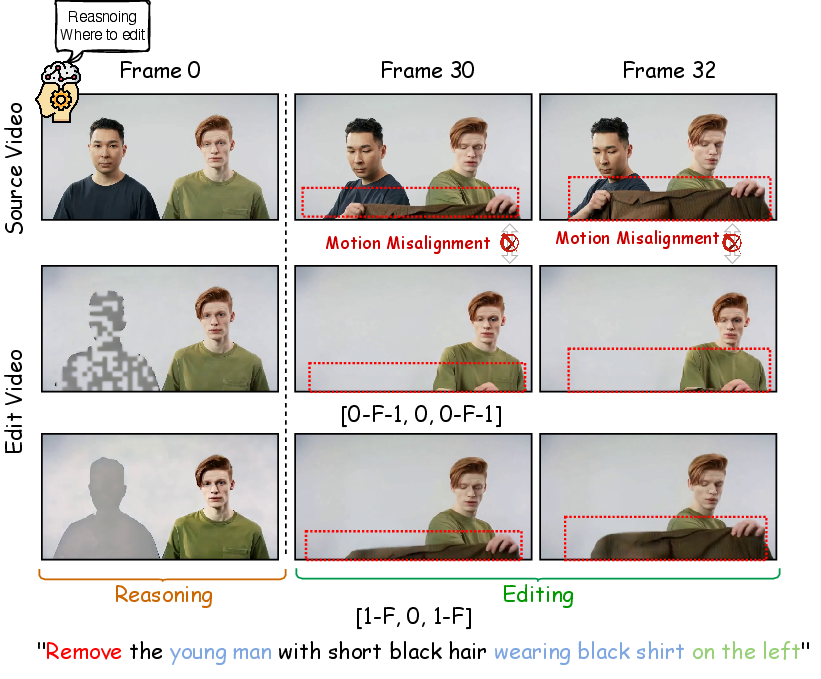
- See: It looks at the original video.
- Reason: It predicts a “reasoning frame” — a soft, gray highlight showing where the edit should happen (like lightly shading the area to be changed). This replaces the need for a user-supplied mask.
- Edit: It performs the actual edit in the highlighted region.
Under the hood, it uses a kind of “diffusion model,” which is a technique that learns to turn noisy, blurry inputs back into sharp, clean outputs. Here’s what that means in everyday terms:
- Imagine starting with a messy, static-filled version of a video and gradually “un-blurring” it step by step until it looks right. The model learns how to do that un-blurring so that the final video matches your instructions.
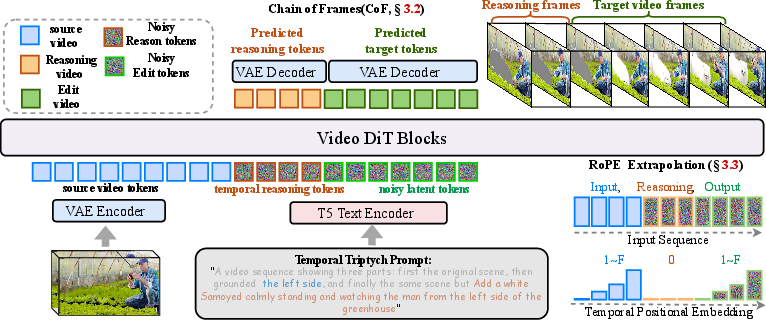
- The model first “un-blurs” the reasoning frames (where to edit) and then “un-blurs” the edited frames (what the edit looks like), while keeping the original source frames clean.
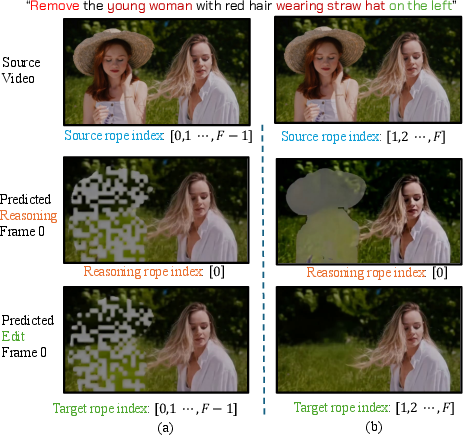
To keep motion smooth and to support longer videos than the ones seen during training, they use a trick called RoPE (rotary position embeddings). You can think of RoPE like time stamps that tell the model the order of frames. If two different parts share the same time stamp, it gets confused (like scheduling two events for the same time and place). The authors carefully set these time stamps so the reasoning frame has a unique index, and both the source and edited frames have their own consistent sequence. This avoids “collisions” and lets the model handle videos up to 4× longer than it was trained on.
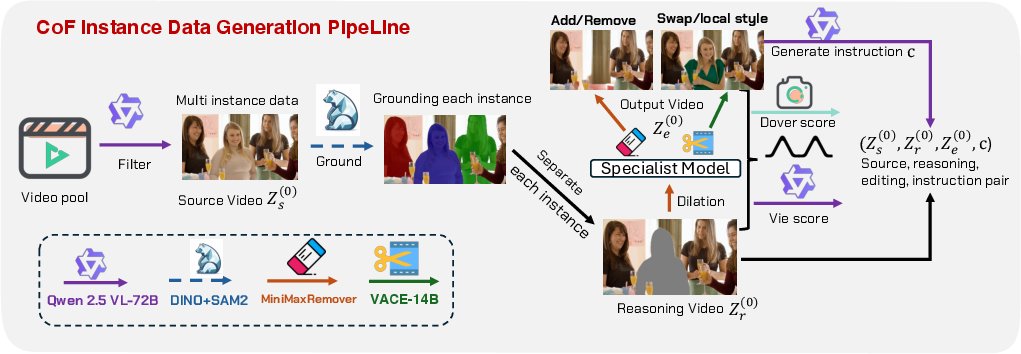
Finally, they built a training dataset with video triplets: original video, reasoning frames (gray highlights over edit regions), and the edited video. They used tools to find multiple objects in scenes, cut masks for each object, and generate realistic edits (adding, removing, swapping, or styling objects). Then they filtered out low-quality results so the model learned from good examples.
What did they find, and why is it important?
- Precision without masks: VideoCoF learns to identify exactly where to edit from the instruction itself, so users don’t have to draw masks. This improves instruction-following and reduces mistakes.
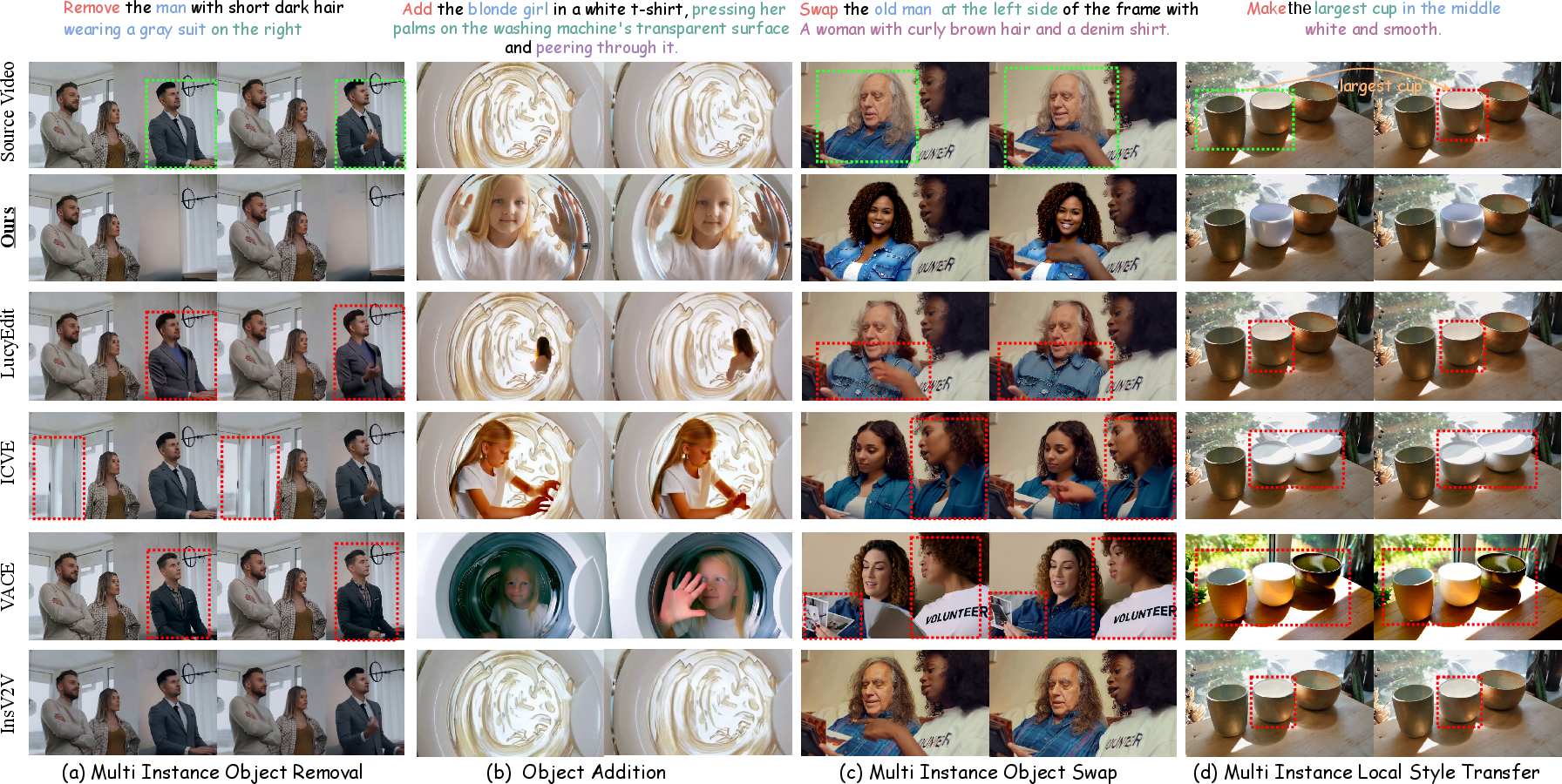
- Strong on multi-object scenes: It does well when there are several similar objects (for example, editing the “largest cup” or the “person on the right”) — situations where many models get confused.
- Works on longer videos: Even though it was trained on short clips (33 frames) and only 50,000 examples, it can edit videos 4× longer at test time while keeping motion aligned.
- State-of-the-art results: On their benchmark (VideoCoF-Bench), VideoCoF beat other strong systems in how well it followed instructions and in overall success rate, despite using much less training data. In simple terms: better edits with fewer training videos.
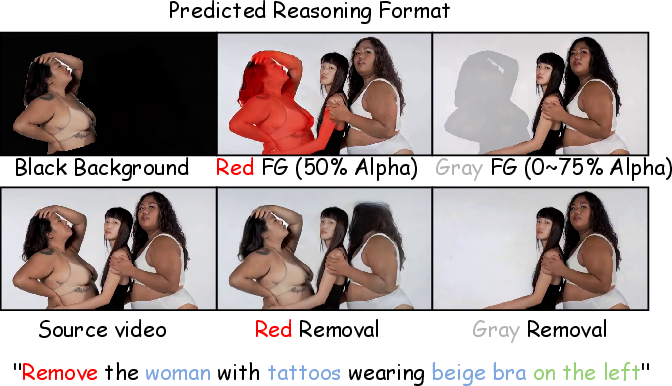
They also ran tests to figure out the best way to show the “reasoning” region. A gradually highlighted gray area was the most effective — better than black masks or red highlights — because it gives clear, gentle guidance without confusing the model.
Here are examples of tasks VideoCoF can handle:
- Object removal: Take out one specific person or item from a crowded scene.
- Object addition: Add a new object in the right spot (e.g., place a toy inside a box, not floating in the air).
- Object swap: Replace a person’s face or clothing while leaving others untouched.
- Local style change: Change the color or style of just one chosen object among many look-alikes.
What’s the potential impact?
- Easier, smarter video editing: Users can give natural instructions (“remove the person on the right,” “make the biggest cup blue”) without drawing masks, and the system figures out where to edit.
- More reliable results: Edits are cleaner and better aligned with motion, which matters for professional video work and creative projects.
- Efficient training: Getting strong performance from a relatively small dataset (50k videos) means this approach could be practical and widely available.
- A step toward “reasoning” in generative video: The “see → reason → edit” idea shows that teaching models to think about “where” before “how” can improve complex tasks.
In short, VideoCoF makes video editing more precise, more flexible, and easier to use, especially in scenes with many objects and longer video lengths. This could help creators, filmmakers, educators, and developers build better tools for storytelling and visual communication.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is framed to be actionable for future research.
- The RoPE reset scheme is only fully specified for a single reasoning frame; when L>1 (the default uses 4 reasoning frames), the temporal indexing strategy for multiple reasoning tokens is not described, leaving potential index collisions and unclear motion alignment behavior.
- No theoretical analysis is provided for why the [1..F, 0, 1..F] RoPE reset enables length extrapolation, nor its failure modes; a formal treatment of aliasing, attention bias across repeated indices, and sensitivity to sequence length is missing.
- Length generalization is shown up to ~141 frames (≈4× training length), but the approach’s robustness at much longer horizons (minutes-scale videos), varying frame rates, and mismatched source/target lengths is untested.
- The method’s computational footprint (memory, latency) scales with concatenating source+reasoning+target frames; there is no report of inference speed, resource requirements, or optimization strategies for real-time or edge devices.
- Evaluation relies heavily on GPT-4o-as-a-judge; reproducibility, evaluator bias, prompt sensitivity, and agreement with human raters are not measured, and no region-level quantitative metric (e.g., IoU of predicted edit region vs. ground truth) is reported.
- No explicit evaluation of reasoning-token accuracy is provided; the model’s predicted edit-region masks are not benchmarked against ground-truth segmentations, making instruction-to-region mapping quality uncertain.
- The dataset (50k curated triplets) is sourced largely from Pexels and filtered via automated scores, but domain diversity, biases (faces, demographics, scenery), and generalization to professional or synthetic domains (e.g., animation, sports, medical) are unquantified.
- The curation pipeline depends on Qwen-VL 72B for multi-instance detection and Grounded-SAM2 for segmentation; error rates, failure propagation to training targets, and robustness to noisy masks are not analyzed.
- Gray mask “reasoning format” is chosen via limited ablations; alternative reasoning modalities (e.g., keypoints, bounding boxes, depth, optical flow hints, text rationales, relational graphs, per-instance tags) are not explored.
- The progressive transparency schedule for reasoning frames is heuristically set; the optimal number of reasoning frames, opacity ramp schedule, and task-adaptive formats remain unexplored.
- Instruction disambiguation in multi-instance scenes (e.g., “the taller man,” “the cup nearest the camera,” “second occurrence”) lacks a formal evaluation; complex relational and temporal reasoning remains under-examined.
- Preservation of unedited regions is evaluated with global perceptual metrics (CLIP-F, DINO), but localized preservation (boundary integrity, texture carryover, lighting/shadow consistency) is not quantified.
- Occlusion- and interaction-heavy scenarios (e.g., overlapping instances, hands covering objects, fast motion with motion blur) are not specifically benchmarked, leaving robustness in challenging dynamics unclear.
- Global edits (style over the entire video), camera motion manipulation, background replacement, environmental lighting changes, and physics-aware edits are not covered by VideoCoF-Bench and remain untested.
- Identity preservation in face-related edits (swap, localized changes) is not rigorously measured (e.g., face recognition/verification scores), and temporally consistent identity retention is not assessed.
- The approach is reported on WAN-14B; its portability to smaller backbones, non-transformer VDMs, or open-source mid-scale models (for cost-sensitive labs) is not demonstrated.
- The training objective supervises reasoning frames via diffusion targets but does not include explicit losses for spatial alignment (e.g., segmentation/reconstruction losses); whether auxiliary supervision improves localization is untested.
- Boundary artifacts and seams between clean source frames and edited frames are qualitatively mentioned but not systematically evaluated; methods to mitigate such artifacts (e.g., temporal blending, boundary-aware losses) are not studied.
- The ODE solver details (solver type, step schedule, stability, error control) are omitted; sensitivity to solver choices and their impact on motion alignment and length extrapolation remains unknown.
- User control beyond text (e.g., optional hints like clicks, scribbles, bounding boxes) is not supported; how to integrate interactive constraints while remaining “mask-free” is an open design space.
- Multi-turn editing scenarios (iterative edits, undo/redo, chained instructions) and how the reasoning tokens evolve across sessions are not addressed.
- Safety and ethics (face swaps, identity manipulation, deepfake potential) are not discussed; guardrails, watermarking, and consent mechanisms for editing human subjects are absent.
- Robustness to ambiguous, contradictory, or low-quality instructions is not evaluated; mechanisms for uncertainty estimation, self-correction, or asking for clarification are not proposed.
- Fairness of comparisons: baselines differ in training scale and assumptions (e.g., mask requirements); matched-data, matched-budget evaluations against expert models are missing.
- Cross-dataset generalization (e.g., to TGVE, V2VBench, FIVE-Bench) and transfer across benchmarks (without fine-tuning) are not reported.
- Failure case analysis is limited; a taxonomy of typical errors (mislocalization, unintended edits, identity drift, temporal flicker) and targeted mitigation strategies is not provided.
- The claim of “theoretically infinite extrapolation” via RoPE reset lacks empirical stress testing and formal guarantees; degradation patterns at extreme lengths (drift, accumulated artifacts) are uncharacterized.
- Audio is ignored; impacts on audio-visual synchronization, sound continuity after visual edits, and co-editing audio tracks are unexplored.
- No explicit mechanisms to preserve scene geometry (depth, parallax) or to enforce physical plausibility during edits (e.g., shadows, contact points); integrating 3D priors or geometry-aware conditioning is unaddressed.
Practical Applications
Immediate Applications
Based on the paper’s “see → reason → edit” Chain-of-Frames (CoF) design and the RoPE alignment for motion/length generalization, the following applications can be deployed with today’s tooling and compute.
- Instance-aware, text-guided video editing without manual masks
- Sectors: media/entertainment, advertising/marketing, creator economy, software
- What: Precisely edit specific instances via natural language (e.g., “remove the person on the right,” “change the largest cup to blue”) using the model’s predicted gray reasoning overlays as soft masks.
- Tools/products/workflows:
- Plugins for After Effects/DaVinci Resolve/Premiere/CapCut that display the predicted “reasoning overlay” for user confirmation, then apply the edit.
- Batch A/B variant generation for ads and trailers (different objects, styles, brand placements).
- Cloud API exposing “text→region→edit” endpoints for developer integration.
- Assumptions/dependencies:
- Access to VideoCoF weights and a compatible VideoDiT/Video VAE stack; adequate GPU inference.
- Best performance on domains similar to training data (consumer videos); niche domains may require finetuning.
- Clear, disambiguated text prompts; multilingual support may vary.
- Compliance and privacy redaction with spatial disambiguation
- Sectors: broadcasting, public sector, enterprise IT, finance (CCTV/meeting recordings)
- What: Automatically blur or remove faces, logos, screens, or minors with instance-level precision using instructions like “blur only the leftmost bystander.”
- Tools/products/workflows:
- Redaction pipelines that preview the reasoning overlay for audit, then apply blur/inpaint.
- Integration with MAM/DAM systems to mass-process archives.
- Assumptions/dependencies:
- High-accuracy region grounding depends on video quality; low light or occlusions may need specialized finetuning.
- Human-in-the-loop recommended for compliance-critical use; add provenance/metadata logs.
- E-commerce product video tailoring
- Sectors: retail/e-commerce, D2C brands
- What: Swap product colors, logos, or accessories; add/remove props per market or campaign.
- Tools/products/workflows:
- Shopify/BigCommerce apps for automatic brand variant videos.
- Bulk generation workflows for seasonal/geo-targeted variants.
- Assumptions/dependencies:
- Brand guidelines and QC needed; model may require product-domain finetuning for consistent material/texture fidelity.
- Creator and mobile apps for local edits
- Sectors: consumer apps, social media
- What: One-tap object removal or localized style filters in short videos (e.g., “remove trash on the sidewalk,” “make only the backpack neon”).
- Tools/products/workflows:
- Server-backed mobile app with “preview reasoning map → confirm → apply edit” UX.
- Assumptions/dependencies:
- On-device inference is likely infeasible for large models today; cloud latency and cost must be managed.
- Long-shot edit stability via RoPE index reset
- Sectors: media/entertainment, software
- What: Apply consistent edits across longer clips than training length without motion drift/artifacts by reindexing temporal RoPE ([1–F, 0, 1–F]).
- Tools/products/workflows:
- “Temporal alignment fix” module for DiT-based editors to preserve motion alignment in long takes.
- Assumptions/dependencies:
- Effective within single continuous shots; multi-shot consistency (identity across cuts) still a challenge.
- Synthetic, instance-level video data generation for CV training
- Sectors: academia, robotics/perception, software
- What: Reuse the paper’s curation pipeline (Qwen-VL + Grounding-SAM2 + inpainting + filtering) to create structured datasets for segmentation, tracking, or VLM grounding.
- Tools/products/workflows:
- Data engines that programmatically create “before/reasoning/after” triplets with controlled perturbations.
- Assumptions/dependencies:
- Licenses for source videos and third-party models; verify data governance for synthetic labels.
- Benchmarking and evaluation
- Sectors: academia, R&D labs
- What: Use VideoCoF-Bench to evaluate instance- and part-level edit fidelity (instruction following, preservation, quality).
- Tools/products/workflows:
- Automated evaluation pipelines with GPT-4o-as-a-judge or open alternatives.
- Assumptions/dependencies:
- MLLM-as-a-Judge biases; consider multiple judges or human spot-checks for important comparisons.
- Developer APIs for “text→region→edit”
- Sectors: software, platforms
- What: Provide an API that returns both the reasoning mask and the edited video for downstream workflows.
- Tools/products/workflows:
- REST/gRPC services; SDKs for Python/JS; asynchronous batch endpoints for long videos.
- Assumptions/dependencies:
- GPU autoscaling and rate limiting; content safety filters to prevent misuse.
Long-Term Applications
These use cases will benefit from additional research, efficiency improvements, or ecosystem integration (e.g., model compression, provenance standards, domain finetuning).
- Real-time, interactive AR video editing with “reasoning” overlays
- Sectors: AR/VR, consumer electronics, education
- What: Live on-glasses preview of editable regions from text (e.g., “highlight only the right formula on the board,” “remove background clutter in real time”).
- Tools/products/workflows:
- On-device distillations/LoRA adapters; streaming inference with low-latency token updates.
- Assumptions/dependencies:
- Significant model compression and hardware acceleration; robust on-device vision-language parsing.
- Long-form (hours) consistent character/prop editing
- Sectors: film/TV, animation, sports broadcasting
- What: Maintain identity and style edits across scenes and episodes; apply team/kit updates in sports highlights.
- Tools/products/workflows:
- Memory-augmented DiTs, identity embeddings, scene boundary detection with per-shot RoPE control.
- Assumptions/dependencies:
- Persistent identity conditioning and cross-shot tracking; editorial oversight for continuity.
- Live broadcast compliance and regional localization at scale
- Sectors: media/broadcast, policy/compliance
- What: Automated, instruction-driven removal/blur/replacement of restricted content in live streams; instant regional variants (e.g., alcohol/brand restrictions).
- Tools/products/workflows:
- Low-latency inference clusters; pre-approved edit playbooks; real-time reasoning preview for operators.
- Assumptions/dependencies:
- Sub-200ms latency targets; fallback to rule-based detectors in edge cases; rigorous auditing.
- Provenance-aware editing with “reasoning map” audit trails
- Sectors: policy, standards, media integrity
- What: Embed predicted reasoning frames and edit metadata (time indices, prompts) into C2PA-like manifests for traceability.
- Tools/products/workflows:
- “CoF Audit” exporters; cryptographic signatures of overlays; viewer tools showing before/reasoning/after.
- Assumptions/dependencies:
- Industry adoption of provenance standards; UX for viewers and regulators.
- Training signal for grounded video-LLMs
- Sectors: academia, foundation model research
- What: Use model-predicted reasoning tokens as supervision for region-aware grounding, question answering, and instruction following in VLMs.
- Tools/products/workflows:
- Multi-task training where reasoning maps act as pseudo-masks; joint diffusion–language pretraining.
- Assumptions/dependencies:
- Robust alignment between language and predicted regions; curated, diverse triplets to avoid bias.
- Robotics and autonomy: controlled multi-object video synthesis for stress-testing perception
- Sectors: robotics, autonomous systems
- What: Generate targeted, multi-instance scenarios (occlusions, left/right ambiguity) to stress-test detectors and trackers.
- Tools/products/workflows:
- Scenario-spec prompt libraries; evaluation harnesses measuring perception failures under controlled edits.
- Assumptions/dependencies:
- Physics and kinematics plausibility; domain gaps between synthetic and real-world sensor data.
- Healthcare video de-identification and case curation
- Sectors: healthcare, telemedicine
- What: Precisely remove or anonymize patient-identifying features in surgical/clinic videos and curate examples for training.
- Tools/products/workflows:
- HIPAA/GDPR-compliant pipelines; human verification; provenance logs of reasoning overlays.
- Assumptions/dependencies:
- Clinical validation and bias assessment; specialized training on medical domains; strict governance.
- Collaborative, multi-agent editing assistants
- Sectors: software, creative tooling
- What: Orchestrate agents for reasoning (localization), editing (diffusion), and QA (MLLM judge) to reach target quality automatically.
- Tools/products/workflows:
- Agent frameworks with guardrails; RFC-like prompts; iterative overlay correction loops.
- Assumptions/dependencies:
- Cost/latency control; failure handling and human override interfaces.
- Domain-adaptive CoF for specialized verticals
- Sectors: manufacturing (inspection videos), security, sports analytics, education
- What: Vertical finetunes (e.g., “highlight defective weld on the left seam,” “remove number overlays except score bug”).
- Tools/products/workflows:
- Small curated triplets per vertical; task-conditioned adapters.
- Assumptions/dependencies:
- Access to representative domain data; evaluation metrics aligned with vertical KPIs.
Cross-cutting Assumptions and Dependencies
- Compute and latency: WAN-scale VideoDiT models require GPUs; real-time and on-device use cases need compression/distillation.
- Data domains: The paper’s strong results are on general consumer videos; specialized domains (e.g., medical, low-light surveillance) may need additional finetuning.
- Prompting quality and language support: Disambiguation (“left/right,” “largest,” “closest”) is crucial; multilingual performance may vary without additional training.
- Third-party components: The data curation pipeline uses Qwen-VL, GPT-4o, Grounding-SAM2, and filtering metrics (Dover, VIE); productionizing may require open or licensed alternatives.
- Safety, ethics, and policy: Powerful localized editing raises misinformation risks; adopt watermarking, provenance (e.g., C2PA), and human-in-the-loop QA for sensitive contexts.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient updates for stable training. "optimizing with AdamW \citep{adamw} and a base learning rate of ."
- adapter-based modules: Plug-in conditioning components used to inject external signals (e.g., masks) into generative models. "which use adapter-based modules to feed external masks into the video generation model"
- Chain-of-Frames (CoF): A reasoning-then-editing procedure that predicts edit regions before generating the edited video. "we propose VideoCoF, a novel Chain-of-Frames approach inspired by Chain-of-Thought reasoning."
- Chain-of-Thought (CoT): A prompting strategy that elicits multi-step reasoning in models. "Inspired by Chain-of-Thought (CoT) multi-step reasoning~\citep{wei2022chain}"
- CLIP-F: A metric assessing temporal consistency between frames in edited videos. "CLIP-F for temporal consistency,"
- CLIP-T: A metric evaluating image–text alignment for edited content. "CLIP-T for imageâtext alignment,"
- cross-attention: An attention mechanism where visual tokens attend to text conditions to guide generation. "and language control via cross-attention."
- denoising step: An iteration in diffusion where noise is progressively removed from latents. "At each denoising step, only the reasoning and target frames are denoised, and the source video latents are kept clean."
- DINO: A self-supervised representation metric used to gauge structural consistency. "and DINO for structural consistency."
- Dover Score: An aesthetic quality metric used to filter generated video pairs. "We use the Dover Score \cite{dover} to assess aesthetic quality"
- edit-region latents: Latent variables encoding the spatial area to be edited, predicted before target tokens. "predict reasoning tokens (edit-region latents) before generating the target video tokens."
- Gaussian noise: Random noise sampled from a normal distribution for training diffusion models. "Given timestep and Gaussian noise "
- GPT-4o: A multimodal LLM used both to judge edits and to generate creative prompts. "we prompt the GPT-4o to provide a binary Success Ratio (Yes/No) to judge the overall success of the edit."
- Grounding-SAM2: A segmentation system used for precise instance-level mask generation. "we use Grounding-SAM2 \cite{groundedsam} to perform precise segmentation"
- in-context learning (ICL): Training-free conditioning by concatenating inputs so the model learns from context. "Recently, in-context learning (ICL) has emerged as a promising paradigm for unified editing"
- index collisions: Overlaps in positional indices that cause interference and artifacts. "this naive reset leads to index collisions at temporal position 0, shared by the source, reasoning, and target frames."
- inpainting mode: A generation setup that fills content inside masks while preserving surrounding regions. "we leverage the VACE-14B \cite{vace} in its inpainting mode to fill the specified masked regions."
- instance-level: Editing or analysis at the granularity of individual object instances. "existing video editing datasets and methods predominantly focus on single-instance-level object manipulation."
- latent representations: Compressed feature tensors produced by encoders (e.g., VAEs) for efficient generation. "we first encode them into latent representations."
- length extrapolation: The ability to generalize to longer sequences than seen during training. "enable length extrapolation beyond the training duration."
- Minimaxremover: A tool used to erase specific instances from video content. "We utilize the Minimaxremover \citep{zi2025minimax} to erase a specific instance from the video."
- ODE solver: A numerical integrator used to evolve diffusion trajectories in latent space. "An ODE solver guided by our model evolves $\mathbf{z}_{\text{full}^{(t)}$ to $\mathbf{z}_{\text{full}^{(0)}$."
- optical flow: Motion estimation technique for tracking pixel displacements across frames. "or optical flow \citep{cong2024flatten}"
- positional encoding: A scheme that injects location information into transformer inputs. "we revisit the design of positional encoding."
- Qwen-VL 72B: A large vision–LLM used for multi-instance identification. "we employ the Qwen-VL 72B \citep{Qwen2VL} to perform multi-instance identification"
- reasoning tokens: Intermediate tokens that represent the predicted edit region to guide subsequent generation. "predict reasoning tokens (edit-region latents) before generating the target video tokens."
- resolution-bucketing strategy: Training across multiple aspect ratios by grouping resolutions into buckets. "We employ a resolution-bucketing strategy to support multiple aspect ratios,"
- RoPE alignment strategy: A design that aligns rotary position embeddings across segments to avoid collisions and enable generalization. "we introduce a RoPE alignment strategy that leverages these reasoning tokens to ensure motion alignment and enable length extrapolation beyond the training duration."
- rotary position embeddings: A positional encoding method that rotates token features to encode positions. "reset the temporal indices of the edited videoâs rotary position embeddings to match those of the source video"
- self-attention mechanism: Token-to-token attention within a sequence used for unified in-context processing. "and use self-attention mechanism to guide the edit."
- temporal concatenation: Concatenating source, reasoning, and target sequences along the time dimension. "Then, we perform temporal concatenation to get the unified representation:"
- temporal indices: Position labels assigned per frame to encode time ordering in transformers. "A naive in-context learning approach applies sequential temporal indices (e.g., $0$ to $2F-1$) across concatenated source and target videos."
- temporal RoPE: Rotary position embeddings applied along the temporal dimension for spatio-temporal encoding. "We adapt the temporal RoPE for source-to-target alignment"
- unified in-context learning: A single framework that handles diverse edits by conditioning on concatenated inputs. "performing unified in-context learning via self-attention"
- velocity field: The vector field predicted by the model that drives the diffusion trajectory. "The target velocity field is $\mathbf{v}=\boldsymbol{\varepsilon}-\mathbf{z}_{\text{full}^{(0)}$."
- VACE-14B: A large video creation/editing model used as an inpainting baseline. "we leverage the VACE-14B \cite{vace} in its inpainting mode"
- VIE Score: A metric for evaluating editing fidelity and coherence. "and the VIE Score \citep{viescore} to measure editing fidelity and coherence."
- VideoCoF-Bench: A benchmark suite for evaluating fine-grained, instance-level video edits. "state-of-the-art performance on VideoCoF-Bench"
- VideoDiT: A diffusion transformer backbone tailored for video generation/editing. "VideoCoF employs a VideoDiT \cite{wanx} for unified video editing."
- Video Diffusion Models (VDM): Generative models that produce videos via iterative denoising. "The development of Video Diffusion Models (VDM) ~\citep{tuneavideo, cogvideox, hunyuanvideo, wanx} has enabled high-fidelity video generation across a wide range of concepts."
- Video VAE: A variational autoencoder that encodes/decodes video frames into/from latents. "are encoded separately by a Video VAE and then concatenated temporally."
- WAN-14B: A large-scale video generative model used as the training backbone. "VideoCoF is trained on WAN-14B \citep{wanx}."
- visual grounding: Linking textual instructions to specific spatial regions in visual content. "we leverage visual grounding, which is naturally suited to simulating reasoning about the edit region."
Collections
Sign up for free to add this paper to one or more collections.