EditVerse: Unifying Image and Video Editing and Generation with In-Context Learning
Abstract: Recent advances in foundation models highlight a clear trend toward unification and scaling, showing emergent capabilities across diverse domains. While image generation and editing have rapidly transitioned from task-specific to unified frameworks, video generation and editing remain fragmented due to architectural limitations and data scarcity. In this work, we introduce EditVerse, a unified framework for image and video generation and editing within a single model. By representing all modalities, i.e., text, image, and video, as a unified token sequence, EditVerse leverages self-attention to achieve robust in-context learning, natural cross-modal knowledge transfer, and flexible handling of inputs and outputs with arbitrary resolutions and durations. To address the lack of video editing training data, we design a scalable data pipeline that curates 232K video editing samples and combines them with large-scale image and video datasets for joint training. Furthermore, we present EditVerseBench, the first benchmark for instruction-based video editing covering diverse tasks and resolutions. Extensive experiments and user studies demonstrate that EditVerse achieves state-of-the-art performance, surpassing existing open-source and commercial models, while exhibiting emergent editing and generation abilities across modalities.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces EditVerse, a single powerful AI model that can both edit and create images and videos. Instead of building lots of separate tools for different tasks (like “add a hat,” “change the background,” “make a video in Minecraft style”), EditVerse aims to be one unified “editor” that understands text instructions and can work with pictures and videos of many shapes, sizes, and lengths.
What questions was the paper trying to answer?
The researchers focused on three simple questions:
- Can one model handle many kinds of image and video editing and generation, all in the same system?
- How can we make the model flexible enough to accept different inputs (text, images, videos) and produce different outputs (edited images or videos) without special settings each time?
- Since high‑quality video editing examples are hard to get, can the model learn good video editing by “borrowing” knowledge from the much larger world of image editing?
How did they do it?
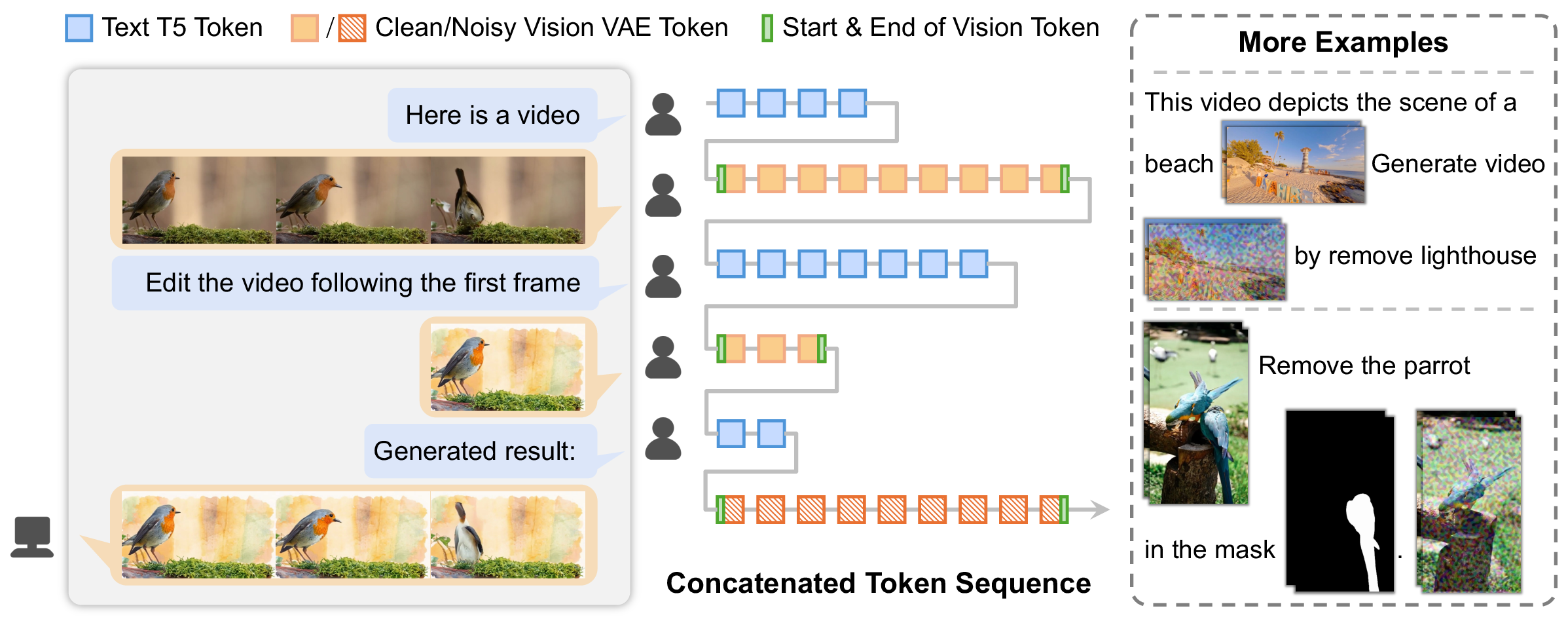
Think of EditVerse like a smart multimedia tutor that reads a mixed “story” made of text, image pieces, and video clips, all lined up together:
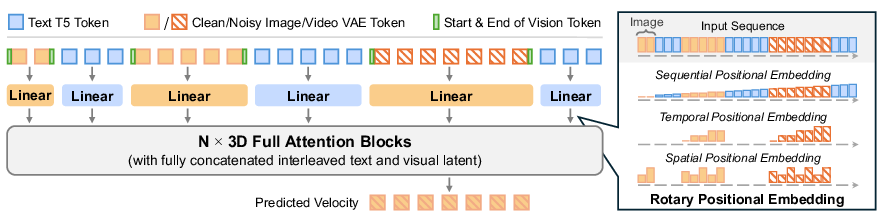
- Unified tokens: The model turns text, images, and videos into small chunks called “tokens,” like breaking a big Lego build into many bricks. These tokens are placed in a single long line (interleaved), so the model sees everything in the exact order you provide.
- Self‑attention: Imagine a study group where every token can “look at” every other token to understand context (who’s talking to whom, what goes where). This helps the model learn from examples inside the prompt (called in‑context learning).
- Position “GPS” for tokens: They give each token a sense of “where and when” it is using a special four‑part positional label:
- Height and width (where in the image frame)
- Sequence order (where it appears in the overall input)
- Time (which frame in the video)
- This is like adding coordinates so the model knows the exact spot and moment for each piece.
- Compressing images/videos: A tool called a VAE acts like a zip file for visuals—shrinking images/videos into a compact form the model can process and later reconstruct.
- Training with “flow matching”: Picture starting from a noisy, messy version of an image/video and steadily cleaning it up. The model learns the best “direction to move” from noise to a sharp result step by step.
- Building better video training data: Because good video editing examples are rare, they created their own pipeline:
- Remove or add objects (using object masks)
- Change objects (like turning a car’s color or shape)
- Style transfer (turn a clip into “Minecraft style,” comic, etc.)
- Camera moves (zoom, pan, tilt)
- Mask detection and edit propagation (find what to edit and carry the change across frames)
- They generated many examples and used another AI (a vision‑LLM) to filter out low‑quality ones, keeping only the best.
- New benchmark: They built EditVerseBench—100 videos (50 horizontal and 50 vertical), with 20 types of editing tasks—to fairly test instruction‑based video editing.
What did they find, and why is it important?
Big takeaways:
- Strong performance: EditVerse beat other open‑source research models on their benchmark and did very well even compared to commercial tools. In user studies, people preferred EditVerse’s edits because they followed instructions well and kept the unedited parts intact.
- Emergent abilities: Even when the model wasn’t directly trained on certain video edits, it learned to do them anyway. Why? Because it transferred editing “skills” from images to videos and from generation tasks to editing tasks. This is like learning to play piano helping you learn keyboard—skills carry over.
- Flexible and simple: Because everything (text, images, videos) goes into one combined sequence, EditVerse can handle different input types and sizes without special settings or extra branches (like masks you must provide).
- Design matters: When they removed either the interleaved input format or the special “sequence” position info, performance dropped—especially on understanding the text instructions. That shows the architecture itself is key.
- Data matters too: Mixing large image editing and video generation datasets helped the model’s video editing quality, making videos smoother, more consistent over time, and better aligned with the requested edits.
What could this mean for the future?
If tools like EditVerse become common:
- Creators (students, artists, YouTubers, game modders) could describe an edit in plain language (“Make the sky purple, remove the car, add glowing lights”) and get a high‑quality result in images or videos—no complicated steps.
- One general model could replace many niche tools, making workflows faster and simpler.
- Better cross‑training (from images to videos) can reduce the need for huge, expensive video datasets, speeding up progress.
- It opens doors for smarter multimedia assistants that understand and edit content interactively in real time.
In short, EditVerse shows that unifying images and videos under one model—with carefully designed inputs, positions, and training—can unlock surprising abilities and make instruction‑based editing more powerful and accessible.
Knowledge Gaps
Below is a single, concrete list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could directly address.
- Limited video-editing data diversity and scale: the curated 288K samples are concentrated on a few task families (object addition/removal/change, style transfer, camera change, mask detection, propagation); broader edits (e.g., global lighting/weather/material changes, complex multi-object interactions, scene rearrangement, compositing, text insertion/removal, background replacement with occlusions/parallax) remain underrepresented and should be systematically collected and benchmarked.
- Heavy reliance on model-generated “ground-truth” edits (VACE, DiffuEraser, ReCamMaster): potential quality/bias transfer from upstream models is unquantified; a human-annotated or professionally curated video-edit dataset is needed to assess and reduce synthetic bias and error compounding.
- Benchmark scope and scale: EditVerseBench (100 source videos, 200 edit pairs, 20 task categories) is too small to characterize generalization, robustness, and fairness; a larger, publicly available, diverse benchmark with multi-domain content, long-form videos, and more edit taxonomies (including failure cases) is needed.
- High-resolution and long-duration performance is unknown: the base training at 360p and resizing to areas between 256×256 and 512×512 leaves open how EditVerse scales to 1080p/4K and multi-minute sequences; research on progressive upsampling, spatiotemporal tiling, streaming/online generation, and memory-efficient attention for long sequences is needed.
- Positional encoding design choices are heuristic: the 4D RoPE dimension splits (H/W/S/T = 56/56/12/4) lack theoretical justification and broad ablation; alternative designs (learned relative/absolute PE, disentangled spatiotemporal encodings, hierarchical segment-level PE, content-aware PE) should be evaluated across resolutions/aspect ratios/durations.
- Sequence length and attention scalability: full self-attention over interleaved text–image–video tokens can be memory-prohibitive for long videos or multi-asset instructions; block-sparse attention, windowed/streaming attention, or cross-token routing should be studied with quantitative trade-offs (quality vs. speed vs. memory).
- Ambiguity in target selection for multi-asset inputs: training randomly picks a generation target segment, but inference behavior for instructions involving multiple images/videos is unspecified; explicit “target-pointer” tokens, segment-level routing, or instruction grounding mechanisms should be introduced and tested.
- Guidance strategy is limited: classifier-free guidance is applied only to text; the effect of guidance on visual/control tokens (first frame, depth, pose, sketch, masks) is unexplored; learned guidance, per-modality guidance scales, and adaptive guidance schedules could improve edit fidelity and stability.
- Multilingual instruction following is unassessed: the Flan-T5-XXL text encoder and training data appear predominantly English; multilingual understanding (instructions and captions) and cross-lingual alignment should be measured and supported with appropriate data and fine-tuning.
- Safety, misuse, and ethics are unaddressed: there is no analysis of identity manipulation, deepfake risks, watermarking, provenance tracking, or safety guardrails; an alignment layer, policy filters, watermarking, and misuse detection should be integrated and evaluated.
- Robustness to underspecified, contradictory, or adversarial instructions is unknown: stress tests with ambiguous prompts, conflicting edits, and adversarial inputs should be created to benchmark instruction grounding and failure modes.
- Training objective coverage: flow matching is chosen without comparative studies; side-by-side evaluations against diffusion (DDPM/EDM), consistency models, rectified flow, and hybrid objectives could reveal better edit fidelity/temporal coherence or speed.
- Solver/time-step trade-offs: the ODE solver with 50 steps is fixed; systematic exploration of solver families and step budgets (including learned schedulers) is needed to balance speed, temporal stability, and edit faithfulness.
- Control modality unification is under-specified: while depth/pose/sketch/masks are used in data pipelines, the paper does not detail how non-RGB control signals are represented in the unified tokenization and whether modality-specific encoders help; explicit multi-control tokenization and fusion strategies should be ablated.
- Temporal consistency metrics are limited: frame-wise CLIP/DINO and PickScore do not directly capture flicker, motion coherence, or causal consistency; new edit-aware video metrics (e.g., FVD variants conditioned on unedited regions, motion smoothness scores, edit-localized temporal metrics) should be designed and validated.
- Mask detection dataset/evaluation is incomplete: the paper constructs mask detection data via prompts but does not report segmentation quality metrics (IoU, boundary accuracy) or how mask prediction is integrated into the model; a measurable mask detection benchmark and training objective are needed.
- Emergent abilities are anecdotal: claims that the model performs edits outside the training distribution lack controlled measurement; formal emergence studies with scaling laws, data-mixture ablations, and task transfer analysis (from image to video) should be conducted.
- Data-mixing strategy is opaque: sampling ratios, curriculum, and task weighting across image/video generation/editing and video editing are not specified; rigorous studies of mixture schedules, curricula, and adaptive sampling policies are needed to optimize edit quality and minimize forgetting.
- Reproducibility constraints: reliance on internal datasets and proprietary pipelines (and a closed-source base model) limits reproducibility; releasing code, model weights, data recipes, and filtering criteria is essential for independent verification.
- Fine-grained region-level edit control via text is not quantified: how well the model localizes edits from text alone (without masks) and preserves unedited content needs targeted benchmarks and metrics (e.g., edit-localized LPIPS/SSIM/PSNR, bounding-box IoU for textual referring edits).
- Interactive/multi-turn editing is asserted but not demonstrated: the interleaved design suggests interactive workflows; experiments on multi-step instruction sequences, stateful editing sessions, and latency/quality under user-in-the-loop constraints are needed.
- Aspect ratio generalization gaps: although horizontal/vertical are included and TGVE+ is square, evaluation across extreme aspect ratios (e.g., cinematic 2.39:1, ultra-tall) and mixed-resolution multi-asset contexts is missing; stress tests and PE/adaptation mechanisms should be studied.
- Inference efficiency and resource footprint are unreported: end-to-end latency, memory usage, throughput per video length/resolution, and hardware requirements should be measured and optimized for practical deployment.
- Delimiter token design is minimal: only “start/end of vision” tokens are used; richer segment-level metadata (modality tags, role tags, timestamps) and hierarchical delimiters could improve instruction grounding and asset routing—this warrants ablation.
- Latent compression quality constraints: the VAE compression and 1×2×2 patchification may introduce artifacts; comparative studies of different latent codecs/patchification schemes (e.g., learned video codecs, 3D patching) on edit fidelity and temporal consistency are needed.
- Reference-based generation/editing is under-evaluated: while customization data is included, quantitative metrics for identity/style preservation and controlled reference-based edits are missing; dedicated benchmarks (face/body/brand/style references) should be added.
- Architectural comparison gap: claims about advantages over cross-attention/MMDiT are not supported by controlled experiments; direct, apples-to-apples comparisons on unified editing/generation tasks are needed to validate the self-attention interleaving design.
- Audio is excluded: audiovisual editing/generation (sound effects, speech alignment to visual edits) and audio-visual consistency are not addressed; extending the unified sequence to audio tokens and designing audio-aware PE/attention is an open direction.
- 3D/geometry awareness is absent: depth/pose are used as controls, but 3D-consistent editing across viewpoints and camera trajectories is not studied; integrating scene geometry (NeRF/GS, monocular reconstruction) and evaluating cross-view edit consistency is an open problem.
- Real-world robustness is unknown: performance under motion blur, low light, sensor noise, compression artifacts, and handheld camera shake is untested; robustness datasets and augmentation strategies should be introduced.
- Failure mode taxonomy is missing: the paper lacks a systematic analysis of typical failures (over/under-editing, semantic drift, identity leakage, temporal flicker, artifact accumulation); documenting and quantifying these modes would guide targeted model/data improvements.
- Legal/privacy considerations: dataset licensing, privacy (faces/brands), and compliance aspects are not discussed; establishing data governance and consent-aware pipelines is essential for responsible scaling.
Practical Applications
Below are practical, real-world applications that follow directly from the paper’s findings, methods, and innovations (unified interleaved token representation of text/image/video, full self-attention for in-context learning, 4D RoPE for spatial–temporal–sequential positioning, scalable video-editing data pipeline, and the EditVerseBench evaluation suite).
Immediate Applications
- Instruction-based video editor for creative production (plugin/SaaS)
- Sector: software, media/entertainment, VFX
- Use cases: text-prompted object removal/addition/replacement; style transfer (incl. “first-frame-to-video”); mask detection; inpainting; depth/pose/sketch-guided edits; virtual camera moves
- Tools/products/workflows: “Prompt-to-edit” panel in Premiere/After Effects/Resolve; batch propagation from a first frame; control-to-video panels (depth/pose/sketch)
- Assumptions/dependencies: base model currently strongest at 360p–512p tokenized areas; GPU inference; content rights and safety guardrails; prompt quality; integration with NLE APIs
- Creative A/B generation and localization for marketing
- Sector: advertising/marketing
- Use cases: rapid variant generation across locales (swap product, color, logo, language in overlays), aspect ratio retargeting (horizontal/vertical), micro-edits for A/B tests
- Tools/products/workflows: “Auto-localization engine” that reads brand guidelines plus a base cut, then produces compliant variants
- Assumptions/dependencies: brand asset ingestion; approval workflows; watermarking/provenance for synthetic edits; legal compliance checks
- Compliance scrubber and content redaction
- Sector: policy, media compliance, news, enterprise
- Use cases: blur/remove faces, logos, sensitive objects; mask detection to localize regions requiring edits per instruction (“Detect the region that needs to be edited” prompt)
- Tools/products/workflows: automated review pipeline that flags and edits content before distribution; audit report with masks and edit logs
- Assumptions/dependencies: reliable detection for regulated categories; human oversight; record-keeping for audit; risk management for deepfake misuse
- Social content assistant for creators
- Sector: consumer apps, social media
- Use cases: one-click object cleanup, trend style transfer (e.g., Minecraft-style), virtual camera moves and reframing for vertical platforms
- Tools/products/workflows: mobile app with text prompts, first-frame editing, and automatic propagation across clips
- Assumptions/dependencies: on-device or cloud GPU; latency constraints; content safety and platform policies
- E-commerce product video personalization
- Sector: retail/e-commerce
- Use cases: dynamic color/material updates, background replacement, quick customization using reference images; batch retargeting for catalog videos
- Tools/products/workflows: CMS-integrated “Product Video Editor” that takes SKU metadata and produces updated clips
- Assumptions/dependencies: accurate material recoloring; product accuracy requirements; brand consistency checks
- Rapid previsualization and rough-in VFX
- Sector: film/TV/VFX
- Use cases: plate cleanup, set extension via inpainting, previsualization from control signals (depth/pose/sketch), quick stylized concept clips from reference frames
- Tools/products/workflows: previs pipeline that accepts storyboard panels or first frames and generates motion-consistent sequences
- Assumptions/dependencies: handoff to traditional pipelines for final, high-res compositing; temporal consistency validated by human reviews
- Robotics and CV data augmentation from real videos
- Sector: robotics, autonomous systems, industrial vision
- Use cases: domain randomization (style/weather/material changes), object insertion/removal to create rare scenarios; depth/pose-conditioned edits for training perception
- Tools/products/workflows: “Scenario Generator” that augments training corpora from existing video data
- Assumptions/dependencies: annotation pipelines for ground truth after edits; ensuring physical plausibility; governance around synthetic data usage
- Unified multimodal editing API for MLLM orchestration
- Sector: software/platforms
- Use cases: interleaved token API that lets LLM agents reason across text, images, and videos; chain-of-thought edits (describe → select region → edit → verify)
- Tools/products/workflows: server-side service exposing interleaved sequence interfaces and 4D RoPE-compatible SDK
- Assumptions/dependencies: standardized schemas for multimodal tokens; robust prompt interpretation; rate limits and compute budgets
- Academic benchmarking and dataset curation
- Sector: academia/research
- Use cases: adopt EditVerseBench for instruction-based video editing evaluation across 20 categories and mixed orientations; replicate the paper’s video-editing data pipeline to curate new training sets
- Tools/products/workflows: comparative studies on cross-modal transfer (image→video), ablation of 4D RoPE and interleaving; using VLM scoring filters for dataset quality control
- Assumptions/dependencies: access to evaluation data and metrics; reproducibility of filtering criteria; ethical review of synthetic dataset generation
- Everyday privacy and cleanup of personal videos
- Sector: daily life
- Use cases: remove bystanders, license plates, or unwanted objects; stylize family videos for sharing; reframe to fit platform aspect ratios
- Tools/products/workflows: consumer desktop/mobile app with instruction-based editing
- Assumptions/dependencies: easy UX for non-experts; default safety/watermarking settings; mobile-friendly inference or cloud offload
Long-Term Applications
- Studio-grade, high-resolution (4K/8K) production pipelines
- Sector: media/entertainment
- Use cases: end-to-end instruction-based editing at broadcast/film quality; multi-shot consistency; high frame rates
- Tools/products/workflows: “EditVerse Pro” with shot tracking, asset management, and render farm integration
- Assumptions/dependencies: scaling model capacity and training data to high-res; robust temporal coherence across long durations; cost-effective inference
- Real-time/on-device video editing
- Sector: mobile/edge, live streaming
- Use cases: low-latency instruction-based effects and redactions during capture; interactive creative edits in live video
- Tools/products/workflows: hardware-optimized inference (ONNX/TensorRT/Apple Neural Engine); streaming-aware schedulers
- Assumptions/dependencies: model distillation/quantization; efficient VAE and flow-matching solvers; thermal and battery constraints
- Synthetic data factories for safety-critical training
- Sector: robotics, autonomous driving, smart cities, energy
- Use cases: programmatic generation of edge-case videos (weather, materials, object behaviors) for model robustness; pose/depth-conditioned sequences
- Tools/products/workflows: data generation orchestration with scenario libraries and quality gates; provenance-aware pipelines
- Assumptions/dependencies: validation against real-world distributions; regulatory acceptance of synthetic training data; governance and documentation
- Brand-aware creative copilot with memory and references
- Sector: marketing/enterprise
- Use cases: persistent brand style/application across campaigns; reference-based generation/insertion; automated compliance checks
- Tools/products/workflows: embeddings for brand assets, fine-tuned adapters, LLM planning over interleaved sequences
- Assumptions/dependencies: enterprise-grade identity and asset management; policy guardrails; scalable fine-tuning and retrieval
- Multimodal standards for provenance, watermarking, and audit
- Sector: policy/regulation, standards bodies
- Use cases: standardized audit logs for instruction-based edits (masks, prompts, regions); embedded watermarks in edited videos; reproducible edit specifications
- Tools/products/workflows: “Edit Ledger” and “Provenance SDK” that records interleaved sequences and edit velocity fields for compliance
- Assumptions/dependencies: cross-industry agreement on formats; integration with platforms; balance between privacy and transparency
- Education and workforce upskilling in multimodal AI
- Sector: education
- Use cases: curricula around unified token sequences, 4D RoPE, in-context learning; practical assignments using EditVerseBench
- Tools/products/workflows: lab kits and course modules; competitions in instruction-based video editing
- Assumptions/dependencies: accessible tooling and datasets; institutional support; ethical guidelines for synthetic media
- Healthcare video anonymization and patient education content
- Sector: healthcare
- Use cases: automatic removal of PHI in clinical videos; generation of instructive patient education clips from references
- Tools/products/workflows: HIPAA-compliant edit pipelines with mask detection and audit trails
- Assumptions/dependencies: very high reliability and human review; liability and regulatory approvals; domain-specific fine-tuning
- Game and metaverse content pipelines
- Sector: gaming, XR/metaverse
- Use cases: rapid stylization of live-action captures to game aesthetics; first-frame-to-video generation for cutscenes; pose/depth-driven animation previews
- Tools/products/workflows: content authoring tools that bridge recorded footage and in-engine assets
- Assumptions/dependencies: IP licensing; engine integration; temporal quality at high frame rates
- Generalized multimodal foundation models beyond video
- Sector: AI research and platforms
- Use cases: extend interleaved tokens and 4D RoPE to include audio and interaction streams; unified editing/generation across text–image–video–audio
- Tools/products/workflows: unified model APIs, cross-modal co-reasoning, interactive generation with agent loops
- Assumptions/dependencies: additional modalities (audio) encoded consistently; larger-scale training data; safety models for multi-sensory synthesis
- Enterprise digital asset management (DAM) with edit intelligence
- Sector: enterprise software
- Use cases: content versioning across regions and platforms; automated retargeting and compliance checks; searchable edit histories
- Tools/products/workflows: DAM-integrated “Edit Intelligence” layer that ingests interleaved sequences and produces compliant variants
- Assumptions/dependencies: integration with existing DAM/ERP/CRM; policy engines; compute budgets and SLAs
Notes on feasibility across applications:
- The model’s unified interleaved sequence and full self-attention enable immediate cross-modal knowledge transfer (image→video), which underpins many editing tasks now. Scaling to long, high-res videos will require more compute, data, and model optimization.
- EditVerseBench provides a ready evaluation scaffold for industry and academia to quantify edit faithfulness, text alignment, video quality, and temporal consistency.
- The data pipeline (object removal/addition/change, style transfer, camera moves, mask detection, propagation) is immediately replicable, but quality depends on upstream detectors (e.g., Grounded-SAM-2) and VLM-based filtering thresholds.
- Responsible deployment needs provenance, watermarking, and human-in-the-loop review to mitigate misuse and ensure regulatory compliance.
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient update to improve training stability. "We use AdamW optimizer~\citep{adamw} with hyper-parameters set to , a peak learning rate of , and weight decay of $0.01$."
- Canny Edge Detection: A classic image processing method for detecting edges using gradients and non-maximum suppression. "sketch is annotated with OpenCV Canny Edge Detection~\citep{opencv}."
- Classifier-free guidance: A technique in diffusion models to amplify conditioning signals (e.g., text) without an explicit classifier. "During inference, we use a classifier-free guidance scale of $5.0$, applying it only to text conditions."
- Cosine decay learning schedule: A learning rate schedule that smoothly decreases the rate following a cosine curve. "We use a warm-up of $2K$ steps and a cosine decay learning schedule, decreasing the learning rate to the minimum of ."
- Cross-attention: An attention mechanism where one modality (e.g., text) attends to another (e.g., image/video) to condition generation. "Existing video generation models, mostly based on cross-attention~\citep{moviegen,wanx} or MMDiT~\citep{cogvideox,hunyuanvideo} architecture, are typically designed for specific tasks such as text-to-video generation."
- Cross-modal knowledge transfer: Leveraging learned capabilities in one modality (e.g., images) to improve performance in another (e.g., videos). "EditVerse leverages self-attention to achieve robust in-context learning, natural cross-modal knowledge transfer, and flexible handling of inputs and outputs with arbitrary resolutions and durations."
- Denoising procedure: The iterative process in diffusion models that transforms noise into clean data (images/videos). "EditVerse predicts the visual velocity that guides the generation of images or videos through a denoising procedure (Section~\ref{sec:training_and_inference_paradigm})."
- Depth Anything v2: A model for estimating depth maps from images/videos. "the depth map is annotated with Depth Anything v2~\citep{depthanythingv2}."
- DiffuEraser: A diffusion-based method for object removal by inpainting masked regions. "We use DiffuEraser~\citep{diffueraser} to remove the masked objects."
- DINO: A self-supervised vision representation method often used for consistency metrics across frames. "temporal consistency (frame-wise CLIP~\citep{clip} and DINO~\citep{dino} consistency)."
- First-frame-to-video: A task setup where the first edited frame is propagated or used to guide the generation of the full video. "we also include annotations for first-frame-to-video generation data and video inpainting data annotated with Grounded-SAM-2~\citep{sam2,groundedsam}."
- Flow Matching: A training objective for diffusion-like models that directly predicts velocity fields guiding data generation. "we randomly select one image or video as the generation target, optimizing with the Flow Matching~\citep{flowmatching} training objective."
- Full self-attention: Applying self-attention across all tokens (text, image, video) to enable unified modeling. "we introduce EditVerse, a unified framework that enables image and video editing and generation within a single model, leveraging full self-attention to enable robust in-context learning and effective knowledge transfer between images and videos."
- Grounded-SAM-2: A segmentation-and-detection system combining grounding with SAM for object masks in video. "We first use Grounded-SAM-2~\citep{sam2,groundedsam} to extract object masks from the video."
- In-context learning: The ability of a model to perform tasks by conditioning on examples or inputs provided in the same sequence without explicit fine-tuning. "This design enables the use of full self-attention with strong in-context learning capabilities~\citep{fulldit} to jointly model and align different modalities."
- Inpainting: Filling in or editing regions of an image/video specified by a mask to match context or prompts. "Moreover, we also include annotations for first-frame-to-video generation data and video inpainting data annotated with Grounded-SAM-2~\citep{sam2,groundedsam}."
- Interleaved sequence: A unified token sequence where text, image, and video tokens are concatenated in the order they appear. "we unify all modalities into a single interleaved sequence representation (shown in Figure~\ref{fig:interleave})."
- KnapFormer packing strategy: A batching technique for variable-length sequences to improve training efficiency. "Since the training data consist of token sequences with variable lengths, making it difficult to form batches, we adopt the packing strategy introduced in KnapFormer~\citep{knapformer}."
- MMDiT: A multimodal diffusion transformer architecture used in text-to-video generation. "Existing video generation models, mostly based on cross-attention~\citep{moviegen,wanx} or MMDiT~\citep{cogvideox,hunyuanvideo} architecture, are typically designed for specific tasks such as text-to-video generation."
- Multimodal LLMs (MLLM): Large transformer models that process and generate across multiple modalities (text, vision, etc.). "We use an interleaved design for text, image, and video, inspired by the native generation architecture of multimodal LLMs (MLLM), which are well-suited for supporting diverse tasks and interactive generation."
- NTK-aware interpolation: A positional encoding scaling method that preserves neural tangent kernel properties for longer contexts. "To better support variable-length input, we use the NTK-aware interpolation~\citep{ntk} in RoPE calculation for context window extension."
- ODE solver: A numerical solver that integrates ordinary differential equations, used here to simulate diffusion trajectories. "During inference, the diffusion model first samples , then uses an ODE solver with a discrete set of timesteps to generate from ."
- Patchified token sequence: Converting spatial (and temporal) latent features into fixed-size patches that become tokens. "Then, the vision features are patchified into a long token sequence with a kernel to get $X_{vision} \in \mathbb{R}^{L_{vision}\times C_{vision}$..."
- Pick Score: A metric (often VLM-based) assessing aesthetic and quality attributes of generated frames. "video quality (frame-wise Pick Score~\citep{pickscore})"
- Propagation: Extending edits from an initial frame through subsequent frames to maintain consistency. "We build the propagation dataset by extracting the first edited frame from style transfer, object removal, object addition, and object change data."
- ReCamMaster: A method/system to synthesize camera motion changes in videos. "We select $10$ camera movements and use ReCamMaster~\citep{recammaster} to generate camera change data."
- Rotary Positional Embedding (RoPE): A positional encoding that rotates query/key vectors to encode positions; here extended to 4D (height, width, sequential, temporal). "we design a four-dimensional Rotary Positional Embedding (RoPE) that incorporates sequential, temporal, height, and width dimensions."
- RTMPose: A human pose estimation model used to annotate skeletal keypoints. "human pose is annotated with RTMPose~\citep{rtmpoose}"
- VACE: A video editing/inpainting framework used to modify masked regions according to prompts. "We then use VACE~\citep{vace} to inpaint the masked region based on the VLM's output."
- Variational Autoencoder (VAE): A generative model that encodes data into a latent distribution and reconstructs it; used to compress images/videos. "we encode the RGB pixel-space videos and images into a learned spatio-temporally compressed latent space by training a convolutional Variational Autoencoder (VAE) capable of both feature extraction and reconstruction."
- ViCLIP: A video-text contrastive model used for alignment metrics such as direction and output similarity. "text alignment (CLIP~\citep{clip} text-image and ViCLIP~\citep{internvid} text-video alignment)"
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs for tasks like scoring or editing guidance. "We used a VLM~\citep{Qwen2VL} to filter the dataset by scoring both editing and video quality."
- Visual velocity: The velocity field in latent space that guides the denoising trajectory in flow matching-based generation. "EditVerse predicts the visual velocity~\citep{sd3,flowmatching} that guides the generation of images or videos through a denoising procedure"
Collections
Sign up for free to add this paper to one or more collections.