- The paper proposes N-simplicial attention, extending traditional pairwise interactions to model complex higher-order dependencies using sparse tensor selection and multi-axis softmax.
- It demonstrates that while this approach enhances model expressiveness in low-data regimes, it also risks over-smoothing and rank-collapse under certain parameter configurations.
- The study provides a Lipschitz upper-bound analysis and suggests future research directions including dynamic token selection and non-linear aggregation to further mitigate smoothing effects.
How Smoothing is N-simplicial Attention?
Introduction
The evolution from Multilayer Perceptrons (MLPs) to graph message-passing frameworks, particularly through Graph Attention Networks (GATs) and Transformer models, has marked a pivotal transition in deep learning. These architectures have proven vital in various domains, including language and vision processing. However, they predominantly focus on pairwise interactions between elements, limiting the scope of interaction modeling. This paper proposes an expansion in the attention mechanism through the introduction of N-simplicial attention, extending the pairwise to higher-order interactions and adapting it to utilize Rotary Position Embeddings (RoPE).
Figure 1: An illustration of higher-order message passing.
N-simplicial Attention
N-simplicial attention generalizes the traditional attention mechanisms to encompass any N-order interaction among tokens. This is a significant leap from previous models which dealt primarily with pairwise (1-simplicial) or limited higher-order (e.g., 2-simplicial) interactions. The proposed approach constructs an nN+1 tensor for attention logits, allowing for the modeling of complex dependencies between tokens in a computationally feasible manner by leveraging a sparse selection of interacting simplexes. This sparse selection strategy ensures computational efficiency while retaining the model's capability to process intricate interaction patterns.

Figure 2: A 0-simplex is a node/vertex, a 1-simplex is an edge, a 2-simplex is a triangle, etc.
The N-simplicial attention utilizes a multi-axis softmax operation to project attention scores from higher-order interactions back onto the input features, effectively capturing the complexity inherent in hierarchical token interaction networks.
Over-smoothing in N-simplicial Attention
While N-simplicial attention improves the expressiveness of models by considering higher-order interactions, it remains susceptible to over-smoothing. This phenomenon, akin to that observed in GNNs and attention layers, results in the convergence of token representations to a homogeneous state, potentially leading to loss of distinctive feature information. The research demonstrates that despite these additional interaction dimensions, over-smoothing can result in rank-collapse under specific parameter constraints.
The derived Lipschitz upper-bound provides insights into how the transition from attention to higher-order N-simplicial attention influences the continuity of token transformations, helping understand the smoothing behavior concerning proximate inputs.
Practical Implications and Future Directions
The practical implications of N-simplicial attention are considerable. By enhancing the adaptability and precision of attention mechanisms, this approach opens new avenues for robust AI systems capable of deeper contextual understanding in complex datasets. The proposed model offers potential advantages in scenarios where limited data availability necessitates maximal leverage of input features through efficient compute distribution.
Future research could further explore the role of simplicial architectures in mitigating over-smoothing effects and improving efficiency in high-dimensional input spaces. Additionally, the adaptation of simplicity-based attention to dynamic environments via real-time token selection and the exploration of non-linear aggregation functions could provide new pathways for research endeavors.
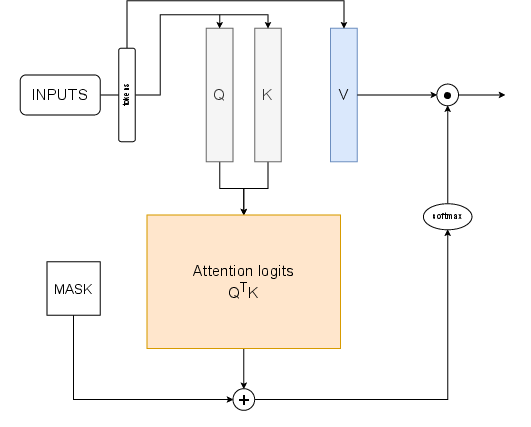
Figure 3: An illustration of masked dot product attention.
Conclusion
This paper presents N-simplicial attention, extending the capabilities of transformer-like architectures to model higher-order interactions efficiently. Through its innovative sparse selection system, the method balances complexity and computational load while maintaining sensitivity to critical interactions. Despite its potential, the susceptibility to over-smoothing necessitates strategic architectural considerations, emphasizing the need for further study in practical deployments and theoretical refinements.
By integrating these new dimensions of interaction into attention mechanisms, the work advances the state of AI models, promoting a deeper, more nuanced comprehension of token interdependencies in various data structures and application domains.