- The paper introduces Scalable-Softmax (SSMax) to mitigate attention fading in Transformers, enhancing length generalization over extended contexts.
- It demonstrates mathematically and experimentally that SSMax reduces training loss and improves key token retrieval in long sequences.
- SSMax integrates with Transformer architectures through minimal modifications, offering efficiency gains and better performance in extended-context scenarios.
Scalable-Softmax Is Superior for Attention
Introduction
The paper "Scalable-Softmax Is Superior for Attention" (2501.19399) investigates an important challenge in Transformer-based LLMs known as length generalization, which is the ability to handle context sizes longer than those used during training. Traditional attention mechanisms utilize Softmax to compute attention scores, which leads to the flattening of attention distributions as context size grows, potentially limiting length generalization. The proposed solution, Scalable-Softmax (SSMax), addresses this problem by offering a scalable alternative to Softmax specifically designed to maintain effective attention focus across variable input vector sizes, thereby enhancing length generalization capabilities in Transformer architectures.
The significance of the problem is underscored by the quadratically growing computational and memory requirements for Transformer training, which impose practical limitations on context sizes. Current approaches to length generalization include improving positional encoding methods, adopting sparse attention mechanisms, further training on longer contexts after modifying positional encodings, and enhancing attention mechanisms. The focus here is on enhancing attention mechanisms by introducing SSMax.
Scalable-Softmax (SSMax) Design
SSMax modifies the Softmax probability distribution transformation to prevent attention fading in growing input vector sizes. The Softmax function interprets vector elements as a probability distribution whose elements sum to one. However, due to vector size dependence, the result can become increasingly flat, leading to attention fading. SSMax addresses this by adjusting the exponential base in its formulation to integrate the input vector size, thereby maintaining focus on key tokens even as input size grows.
The SSMax function is mathematically defined as:
zi↦∑j=1nnszjnszi,
where s is a scalar scaling parameter. This formulation is distinct from Softmax in its adaptability to varying input vector sizes, preserving effective attention allocation regardless of these sizes.
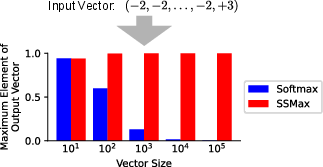
Figure 1: Comparison of Softmax and SSMax, illustrating the issue of attention fading and the effectiveness of SSMax in preventing it.
Experimental Evidence and Analysis
To validate the SSMax design, experiments analyzed how attention scores ideally depend on input vector size. It was found that attention mechanisms benefit from the SSMax formulation, confirming a logarithmic relationship between input size and attention distribution focus.
Theoretical analysis highlights the extent of attention fading under Softmax and clarifies how SSMax manages to maintain attention on significant tokens by ensuring that, with zmax−z2nd>s1, the attention remains focused. This property allows dynamic adjustment of attention allocation based on input values.
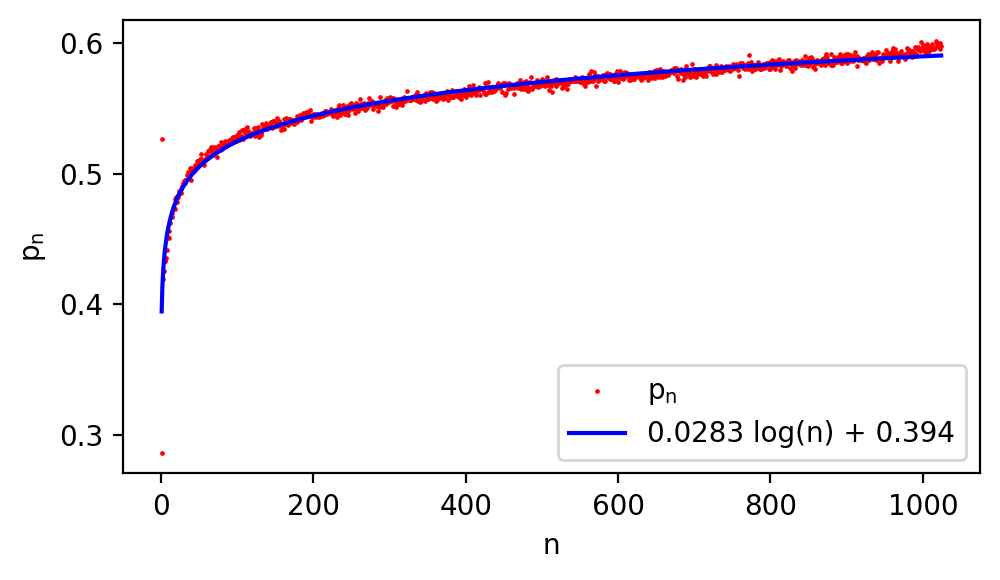
Figure 2: Relationship between pn and the input vector size $n.
Implementation and Evaluation
SSMax implementation integrates seamlessly into existing Transformer architectures with minimal changes required, enhancing efficiency without affecting compatibility.
Evaluations indicate SSMax's effectiveness in lowering training loss consistently across multiple model variants compared to standard Transformers. Furthermore, it improves long-context generalization and key information retrieval performance significantly, as demonstrated by per-position test loss assessments on sequences much longer than those seen during training.
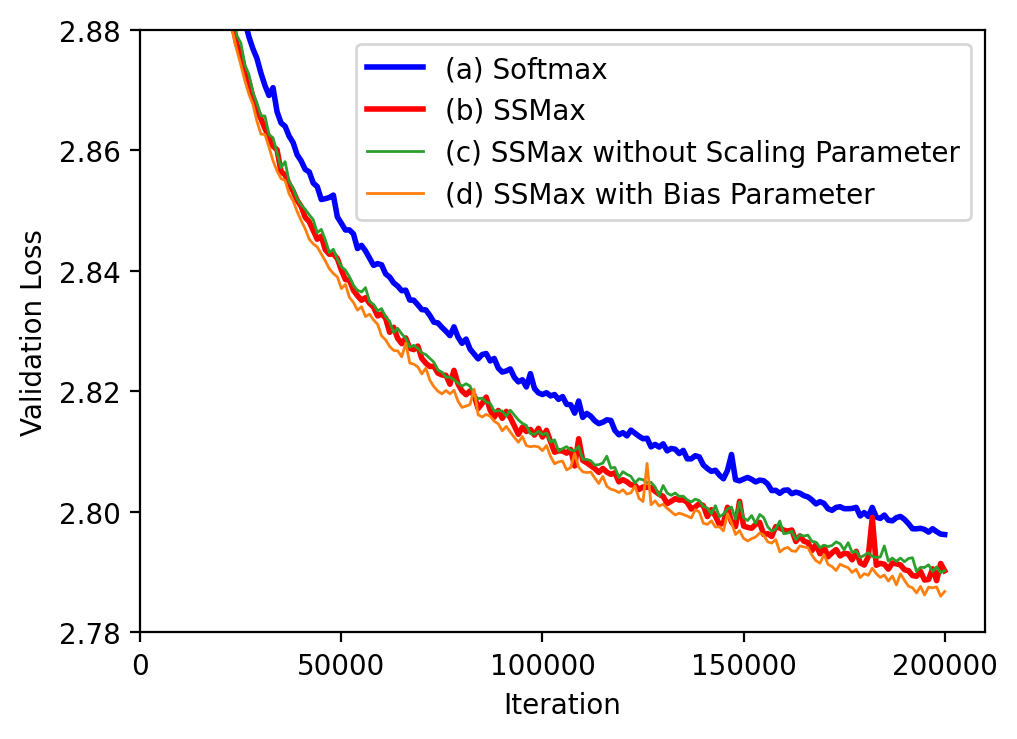
Figure 3: Learning curves comparing the standard Transformer and SSMax variants.
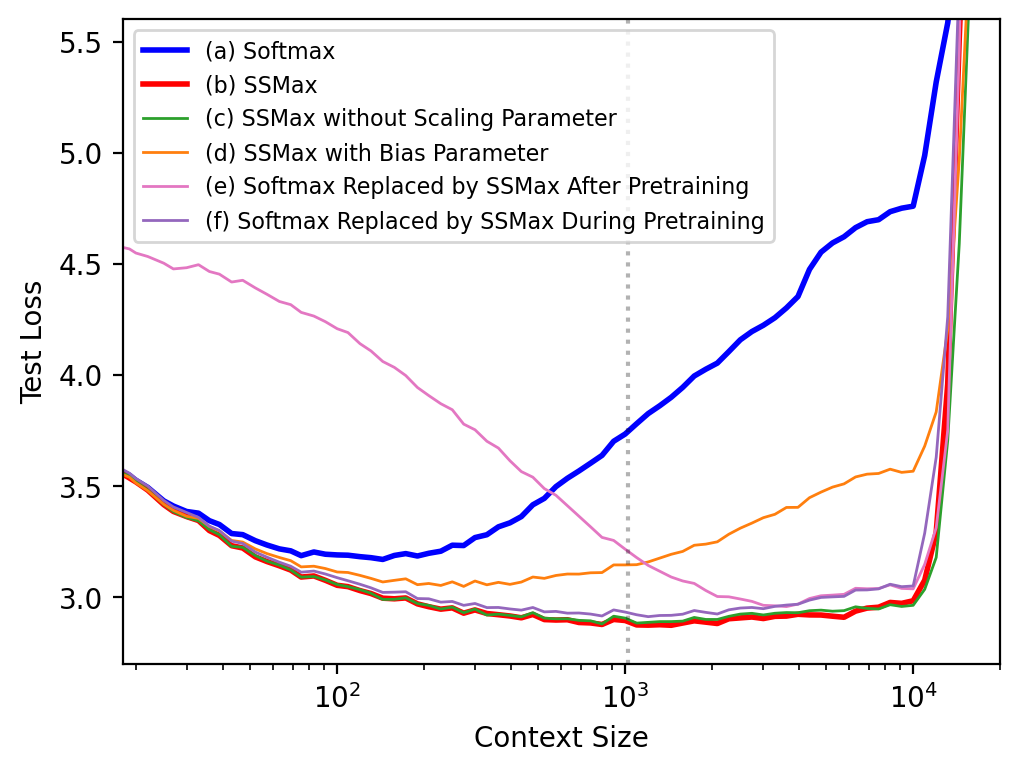
Figure 4: Per-position test loss across context sizes up to 20,000.
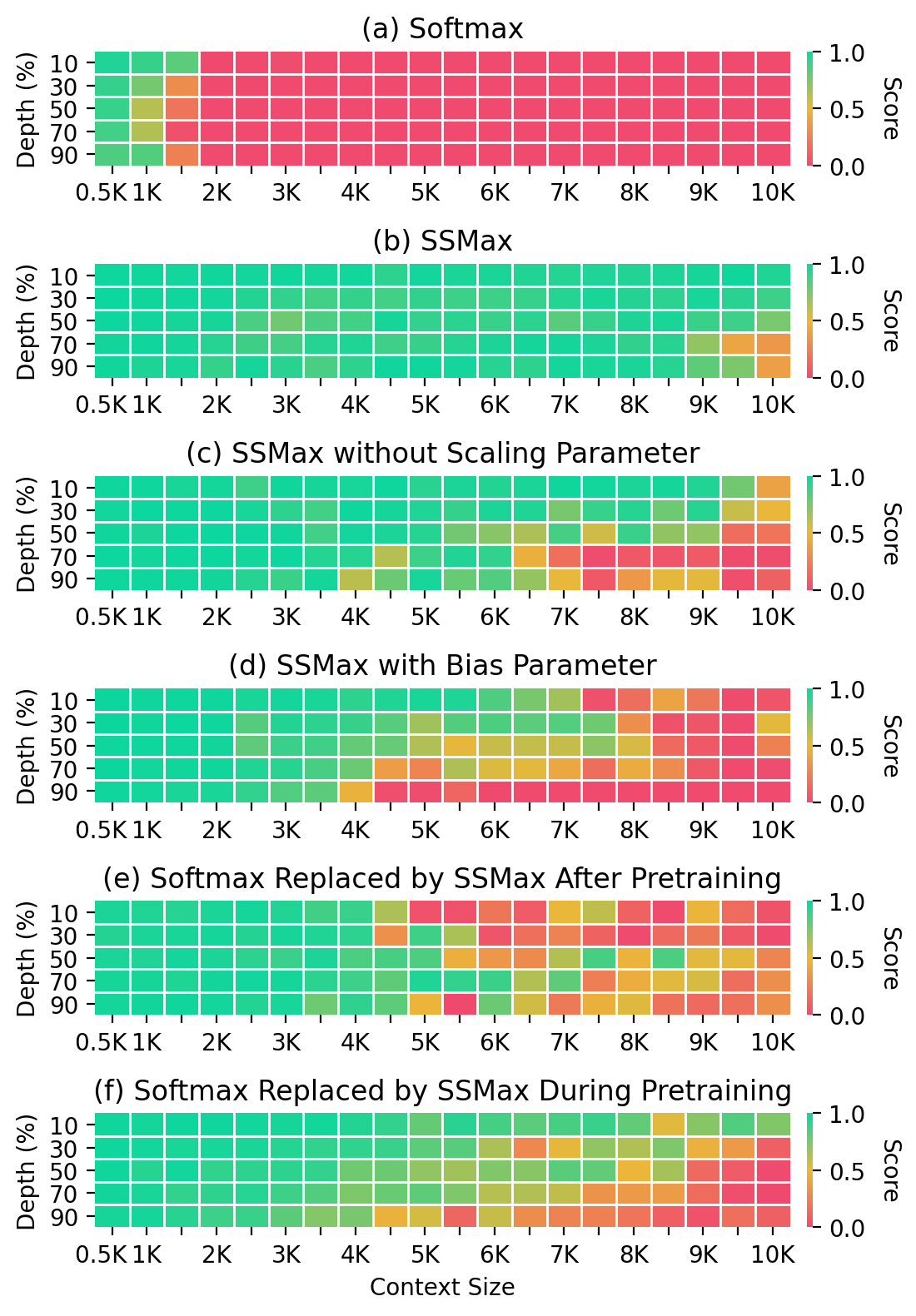
Figure 5: Needle-In-A-Haystack test results showcasing retrieval accuracy.
Attention score analysis further consolidates SSMax's advantage in focusing attention effectively on key tokens, particularly in extended contexts, fostering improved key information retrieval.
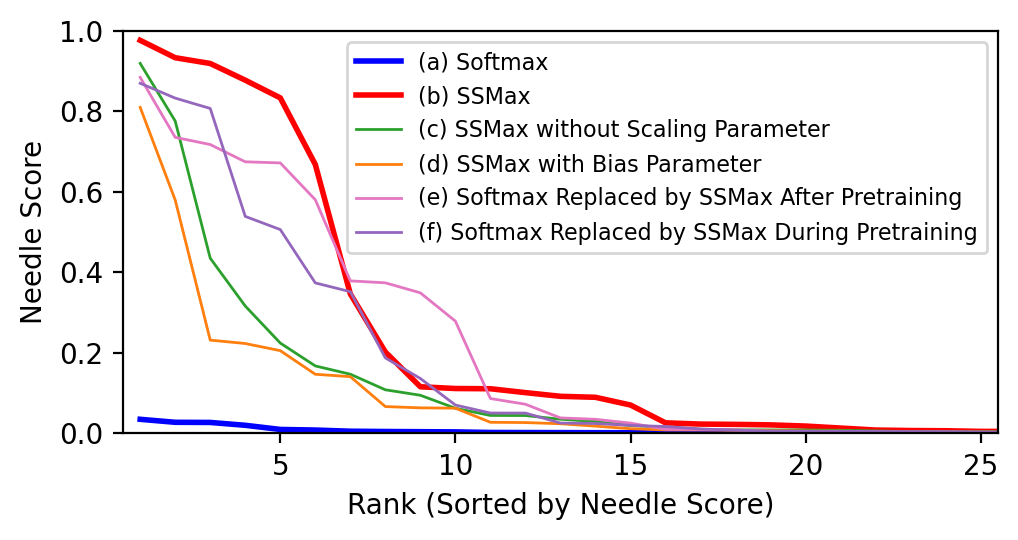
Figure 6: Needle score distribution across attention layers and heads.
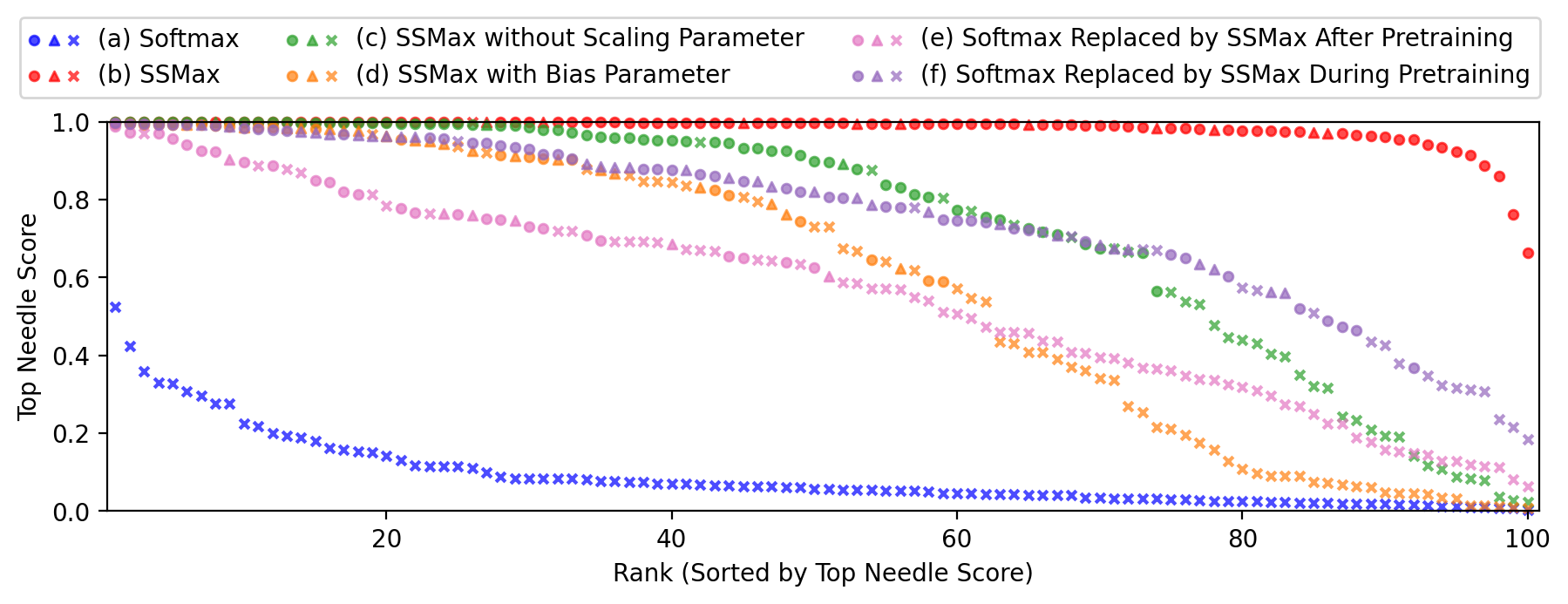
Figure 7: Top needle score distribution across models.
Conclusion
SSMax presents a formidable alternative to Softmax within Transformer attention layers, addressing the limitation of attention fading and enhancing length generalization. Through rigorous experimentation, SSMax is shown to improve training efficiency, maintain lower test loss across extended contexts, and excel in key information retrieval tasks within long contexts. While benefits accrue most substantially when SSMax is incorporated from the beginning of training, switching from Softmax to SSMax during or after pretraining also yields noticeable improvements. Its potential to adapt and enhance Transformer-based LLMs positions SSMax as an attractive candidate for broader adoption. Future work may focus on extending SSMax's application across diverse Transformer architectures and exploring its integration into existing pretrained models.
