Beyond Real: Imaginary Extension of Rotary Position Embeddings for Long-Context LLMs
Abstract: Rotary Position Embeddings (RoPE) have become a standard for encoding sequence order in LLMs by applying rotations to query and key vectors in the complex plane. Standard implementations, however, utilize only the real component of the complex-valued dot product for attention score calculation. This simplification discards the imaginary component, which contains valuable phase information, leading to a potential loss of relational details crucial for modeling long-context dependencies. In this paper, we propose an extension that re-incorporates this discarded imaginary component. Our method leverages the full complex-valued representation to create a dual-component attention score. We theoretically and empirically demonstrate that this approach enhances the modeling of long-context dependencies by preserving more positional information. Furthermore, evaluations on a suite of long-context language modeling benchmarks show that our method consistently improves performance over the standard RoPE, with the benefits becoming more significant as context length increases. The code is available at https://github.com/OpenMOSS/rope_pp.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Beyond Real: Imaginary Extension of Rotary Position Embeddings for Long-Context LLMs — Explained Simply
What is this paper about?
This paper improves how LLMs understand very long texts. It focuses on a technique called Rotary Position Embedding (RoPE), which helps LLMs know the order of words. The authors noticed that standard RoPE uses only part of the information it could, and they show how to use the “imaginary” part as well. Their enhanced version, called RoPE++, helps models handle longer documents better and can even reduce memory use.
What questions were the researchers asking?
- Can LLMs do a better job with long documents by using more of the math behind RoPE?
- Does the “imaginary” part (not just the “real” part) of the calculation carry useful signals about word positions?
- Can we add this extra information without slowing the model or using a lot more memory?
- Will this make models more accurate on tasks that require remembering information far back in the text?
How did they approach the problem?
Quick background: How LLMs remember order (RoPE)
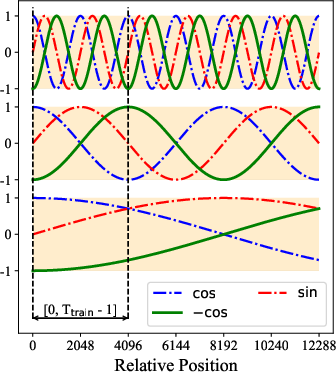
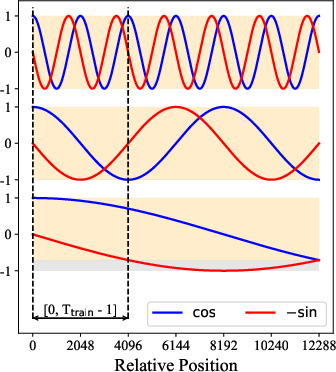
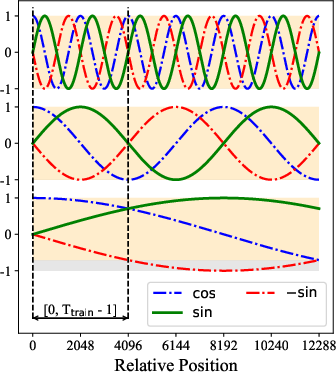
- Think of each word as an arrow on a circle. RoPE “rotates” these arrows based on where the word appears in the sentence. When the model compares two words, the amount of rotation reveals how far apart they are.
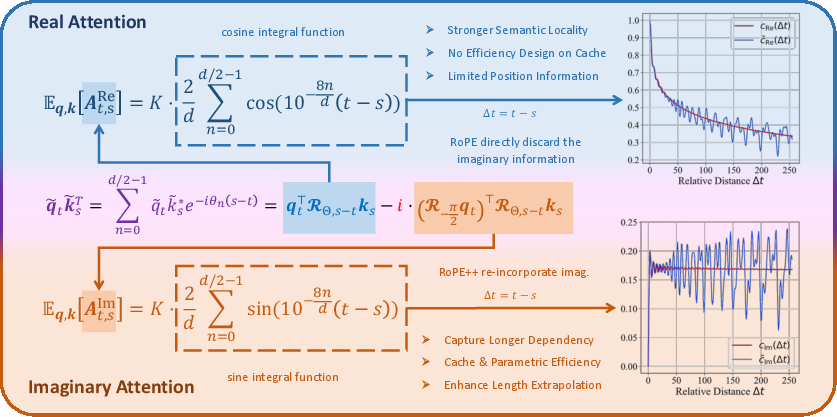
- Mathematically, this rotation lives in the complex plane (which has two parts: real and imaginary). Standard RoPE keeps only the real part when it computes attention scores (how much one word should pay attention to another) and throws away the imaginary part.
The new idea: use the imaginary part too (RoPE++)
- The authors bring back the imaginary part and compute attention using both real and imaginary components. You can imagine this like looking at both the horizontal and vertical directions of a rotated arrow instead of just one.
- Practical trick: you can get the imaginary attention by rotating the “query” vector an extra quarter turn (−90°) first, then doing the same operations you’d do for the real part. This lets the model use the full positional signal without changing the overall attention formula.
Two ways to use it
- RoPE++ EC (Equal Cache): Keeps the same memory for stored past information (KV cache) but doubles the number of attention heads (small teams of “spotlights” that focus on different parts of the text). This adds imaginary heads alongside the real ones.
- RoPE++ EH (Equal Heads): Keeps the same number of attention heads, but halves certain parameters and KV cache size. This saves memory while still adding imaginary attention inside each head pair.
In both setups, the real and imaginary heads share parameters, so this is efficient and easy to plug into existing models.
Why this might help with long texts
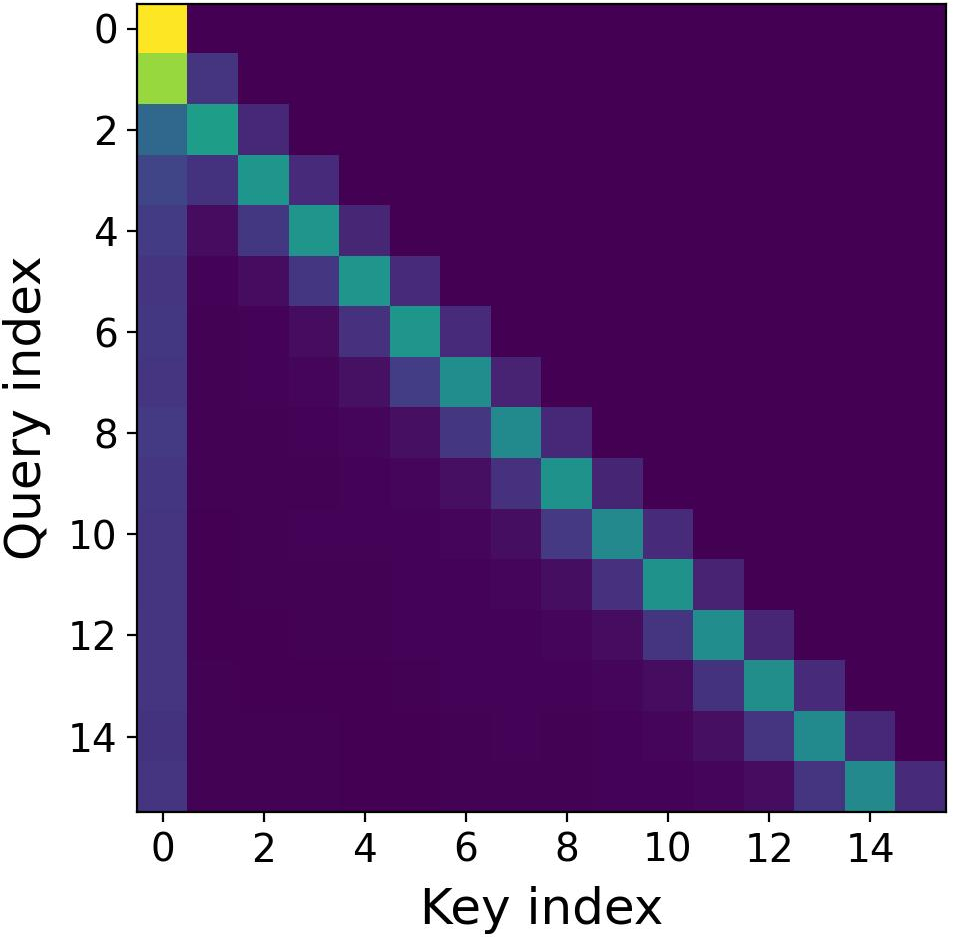
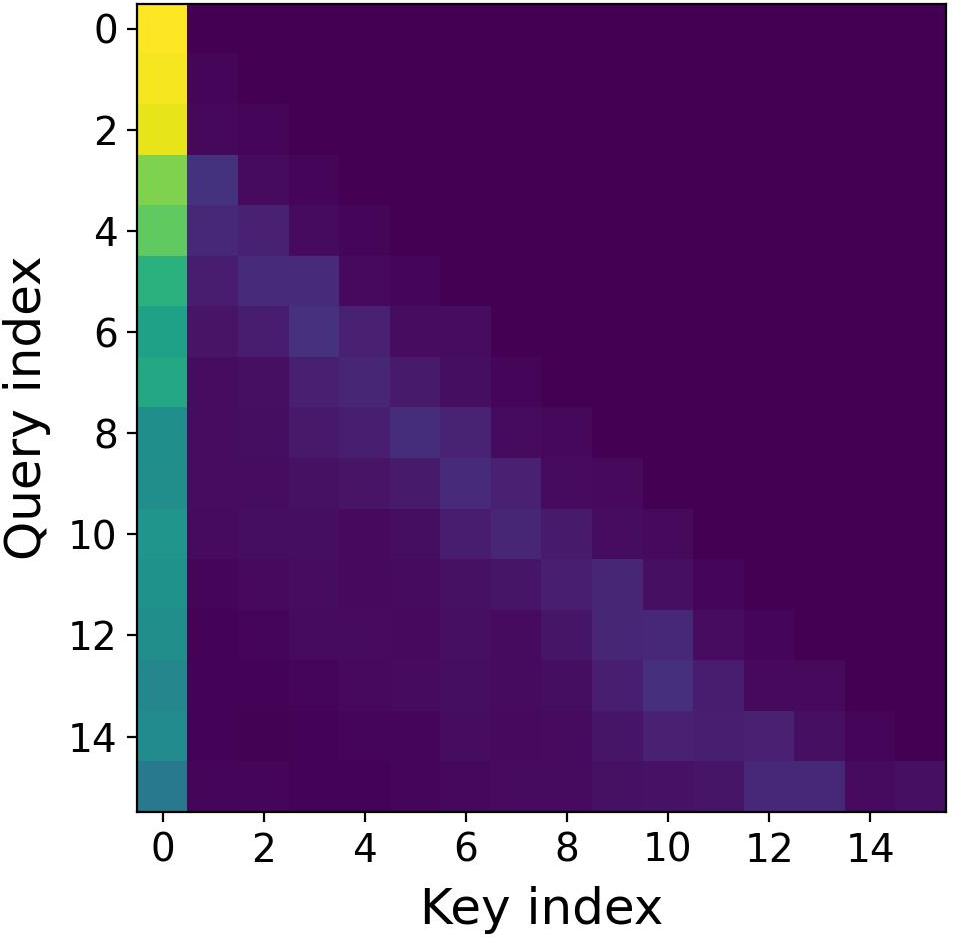
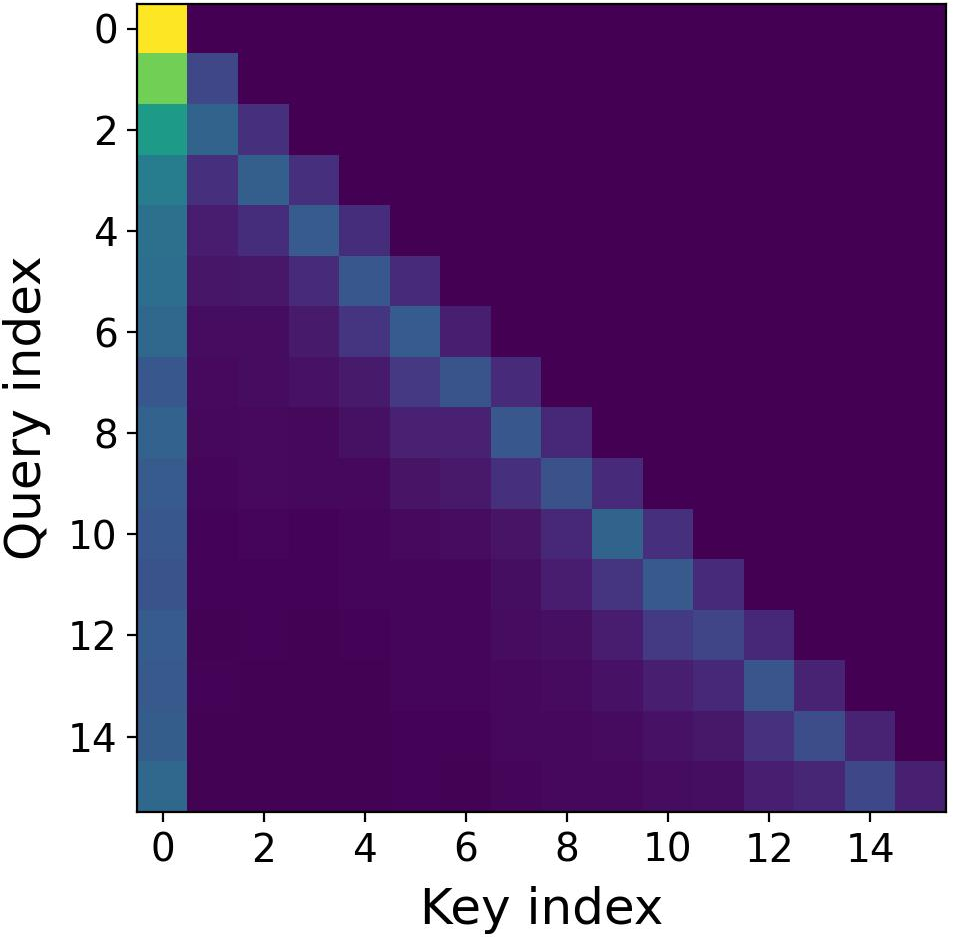
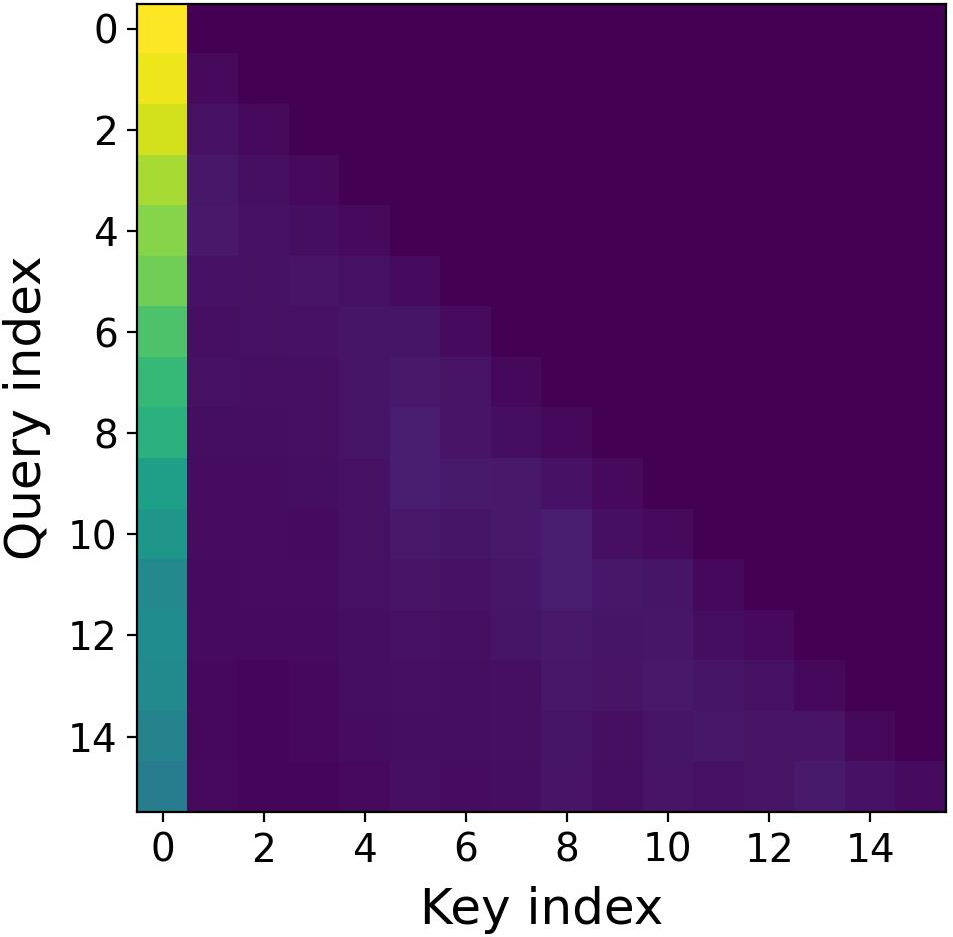
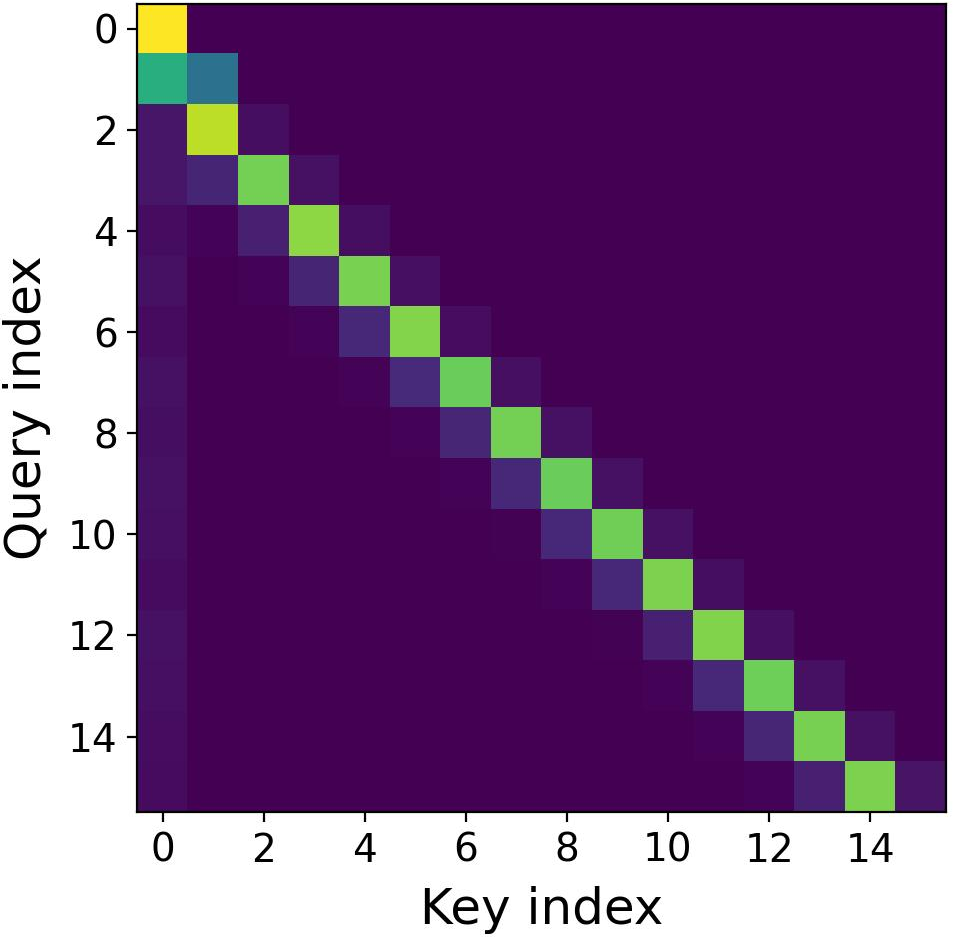
- Real attention tends to focus more on nearby words (local context).
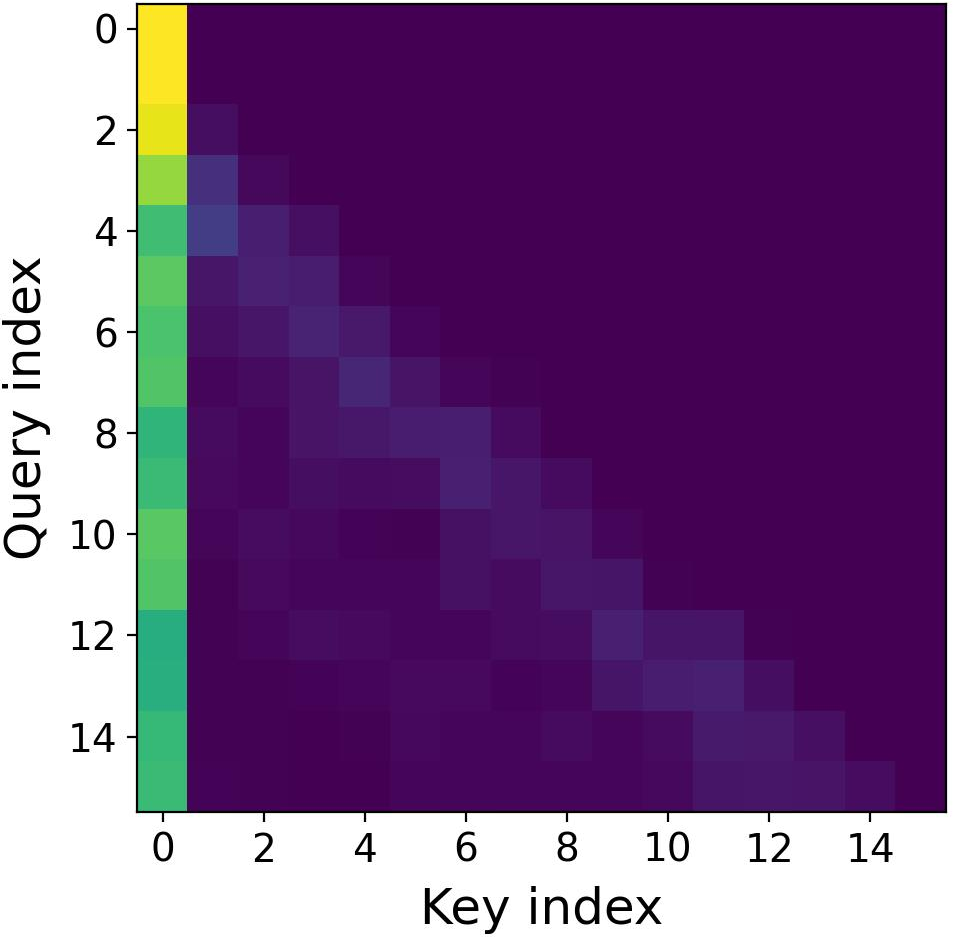
- Imaginary attention tends to give more weight to far-away words (global context).
- Using both is like having one team that listens closely to what was just said, and another team that remembers earlier parts of the conversation. Together, they balance short-range and long-range memory.
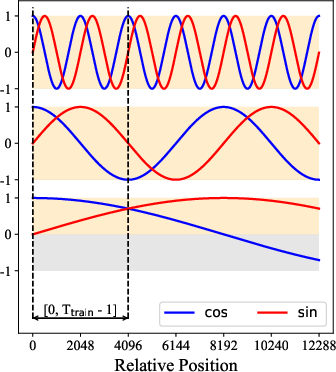
- It also helps with “length extrapolation,” meaning the model stays more stable when used on texts longer than what it saw during training. Because both positive and negative parts of the sine/cosine rotations are learned, the model is less surprised by new, longer inputs.
What did they find?
Here are the key results from their experiments on models with around 376M and 776M parameters:
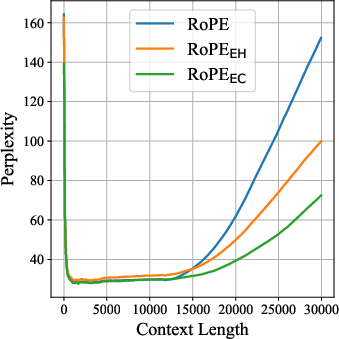
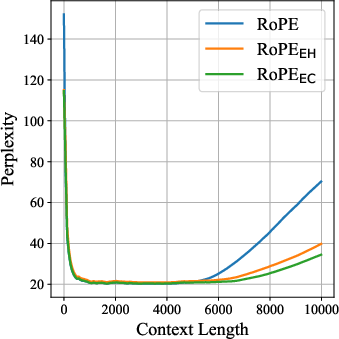
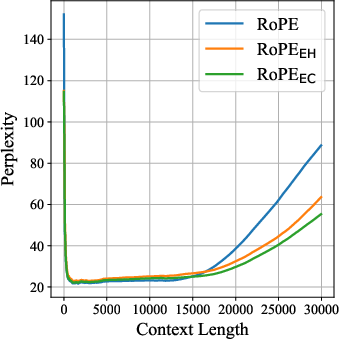
- Better long-context performance:
- On long-text benchmarks (RULER and BABILong, up to 64k tokens), RoPE++ consistently beats standard RoPE.
- The advantage grows as the context gets longer.
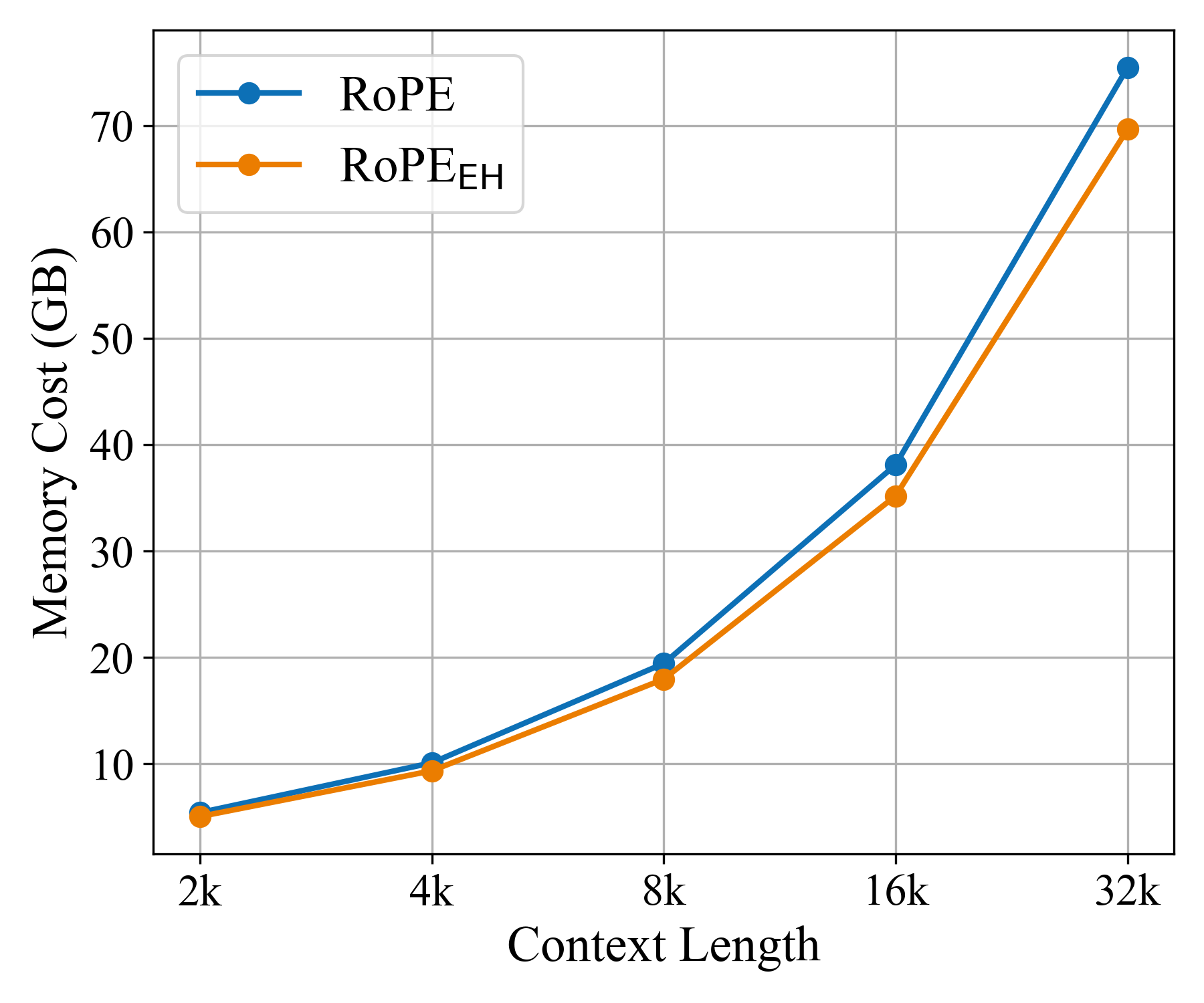
- Memory and speed benefits:
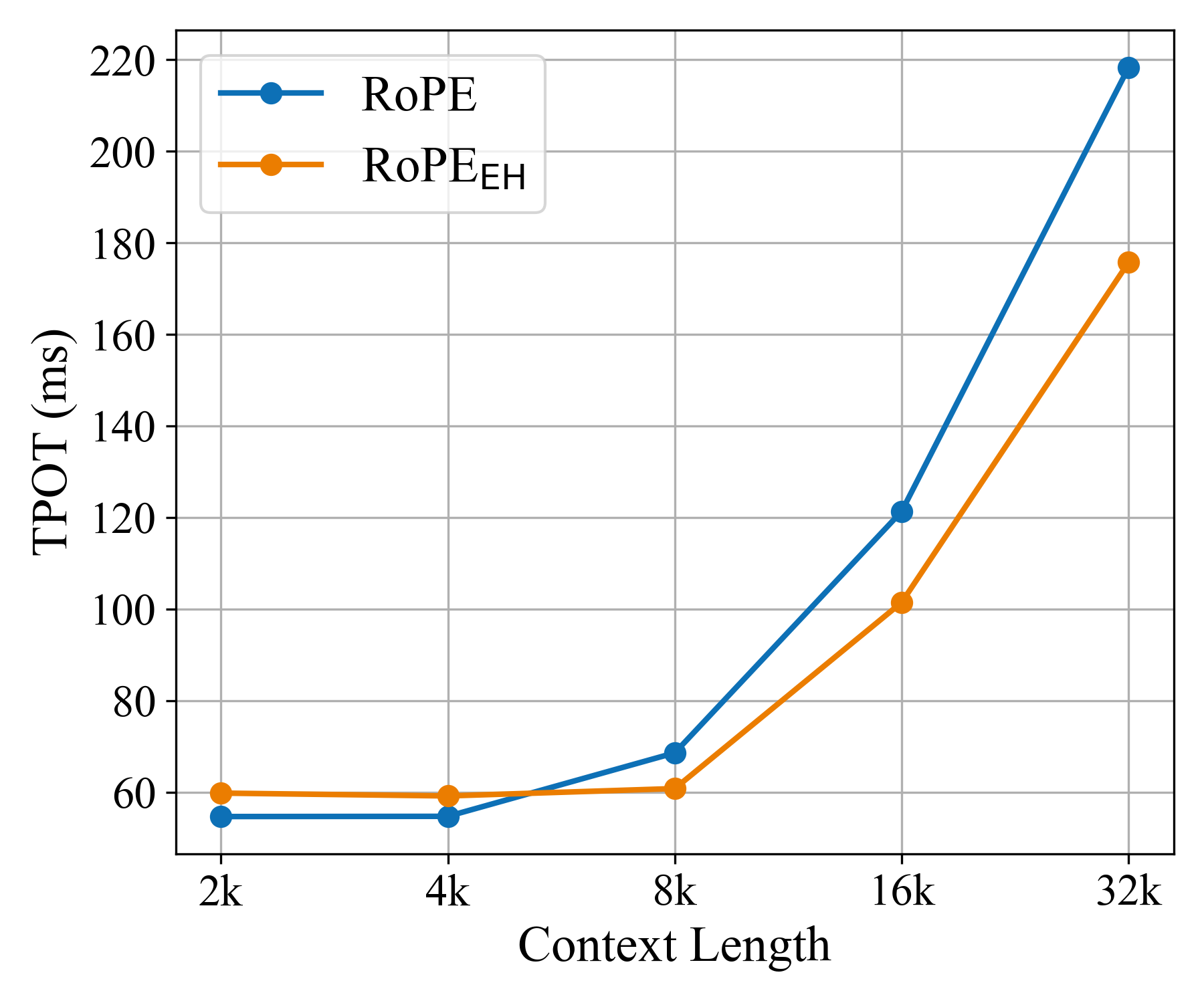
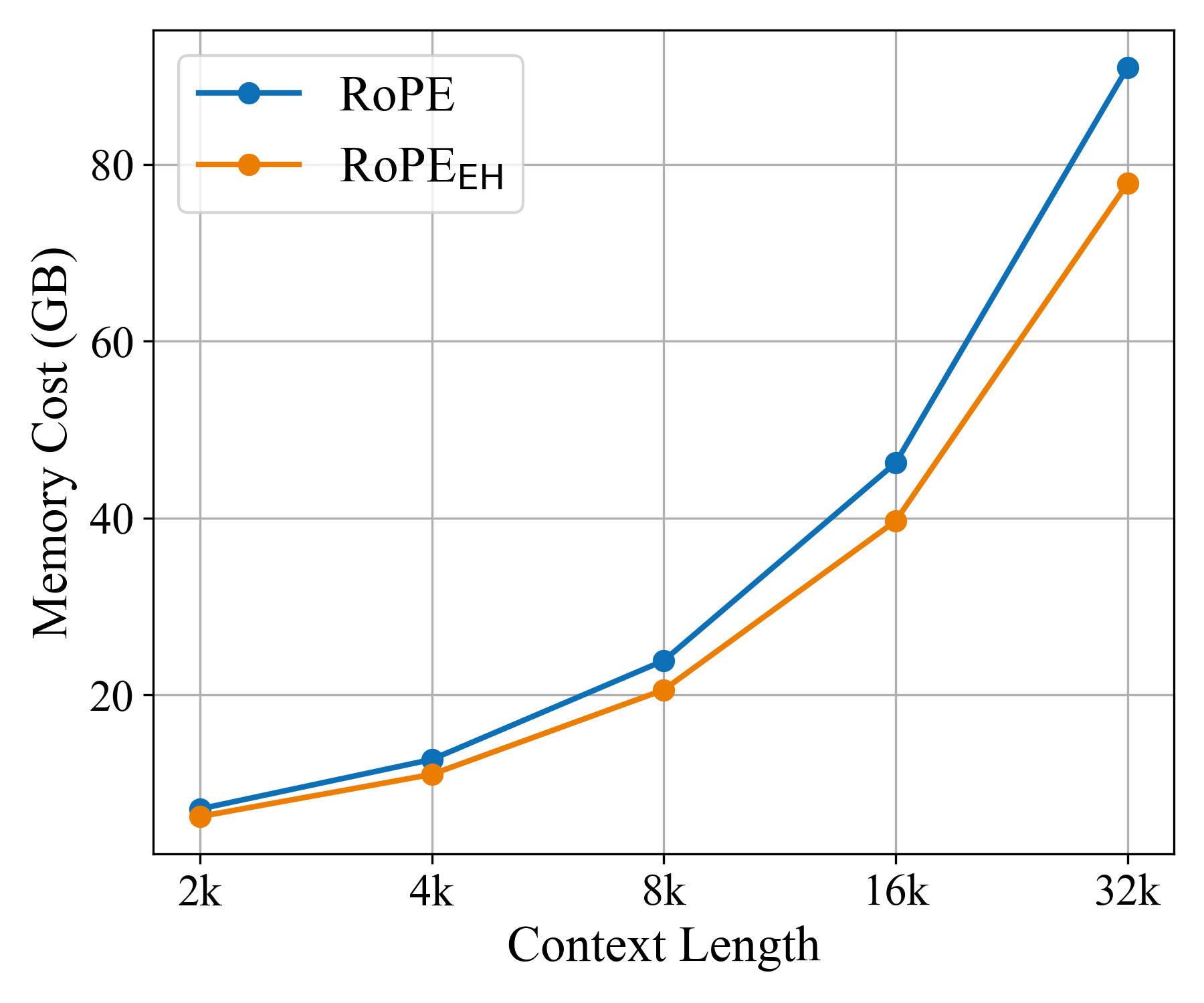
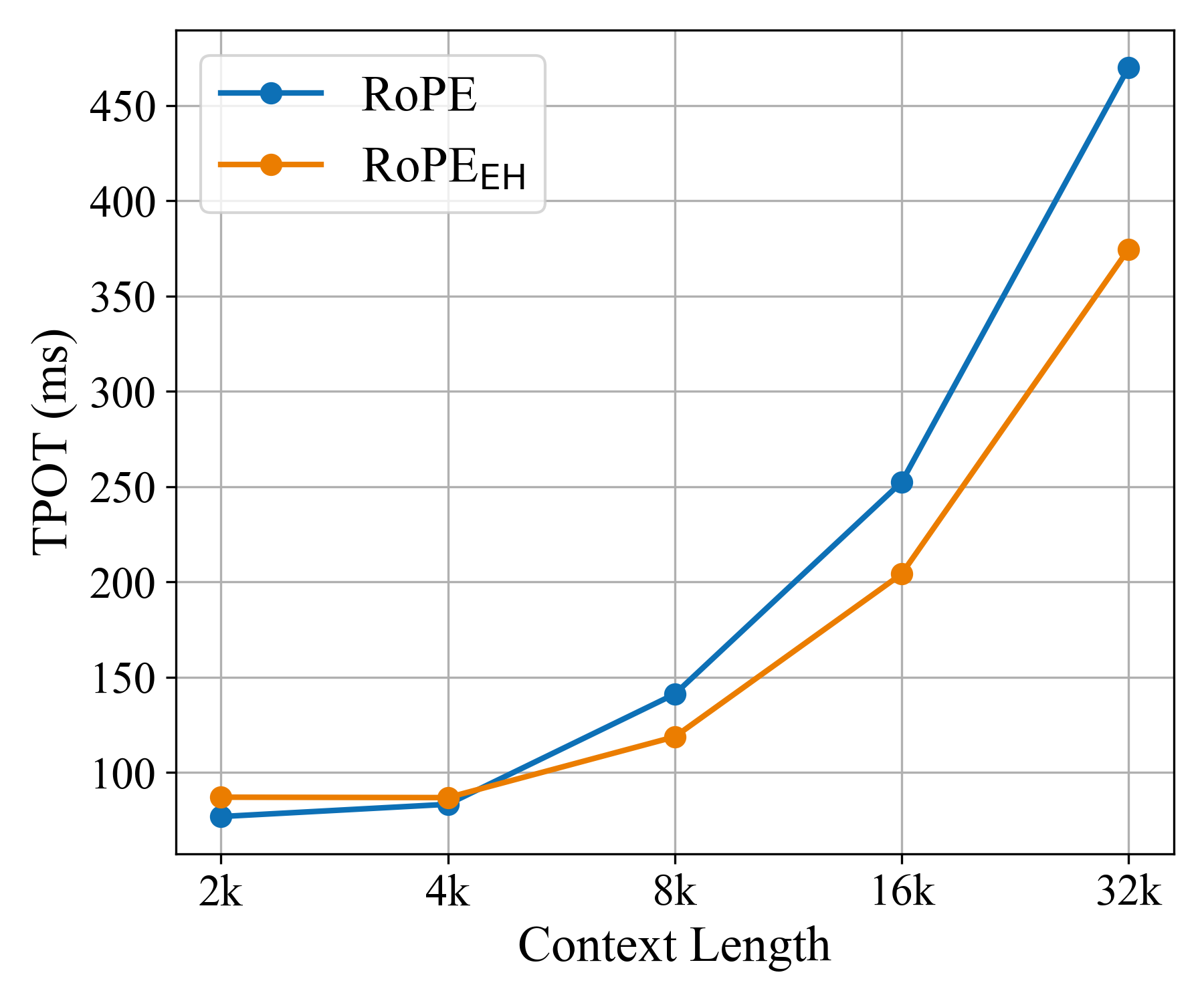
- RoPE++ EH delivers similar or better accuracy while using about half the KV cache. This reduces memory and speeds up generation, especially for long inputs.
- RoPE++ EC delivers higher accuracy at the same cache size by adding more heads (real + imaginary).
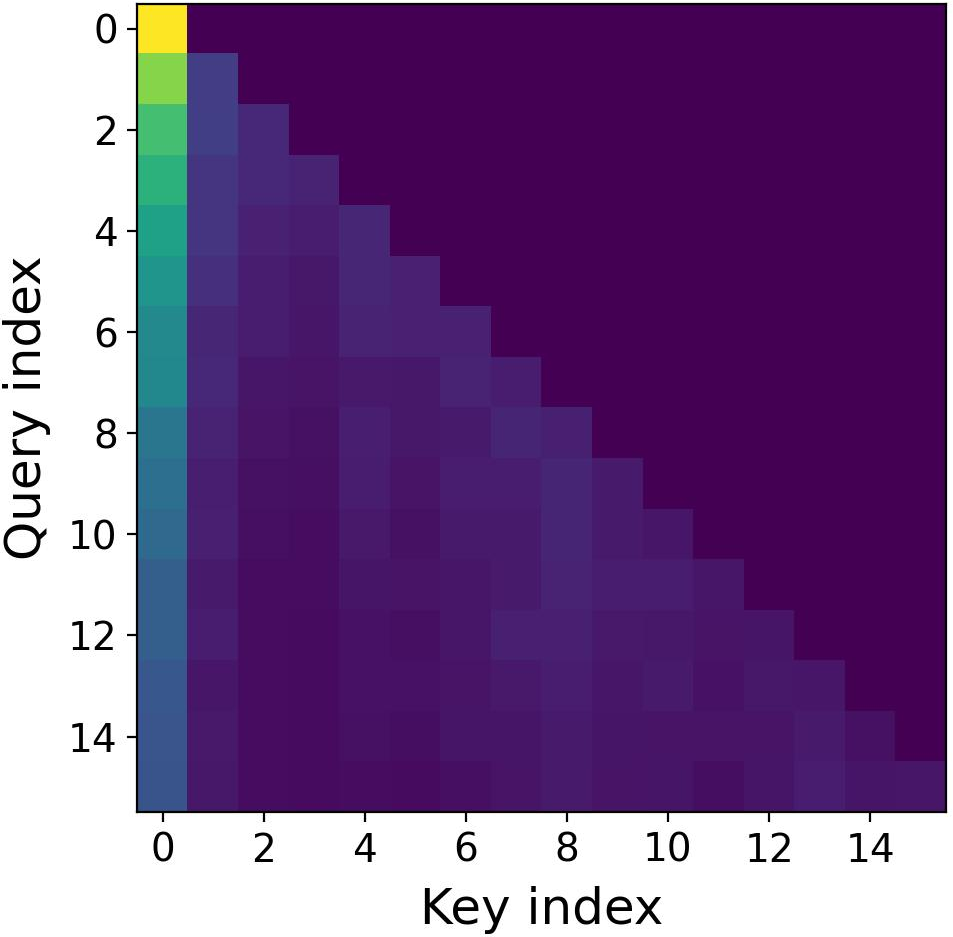
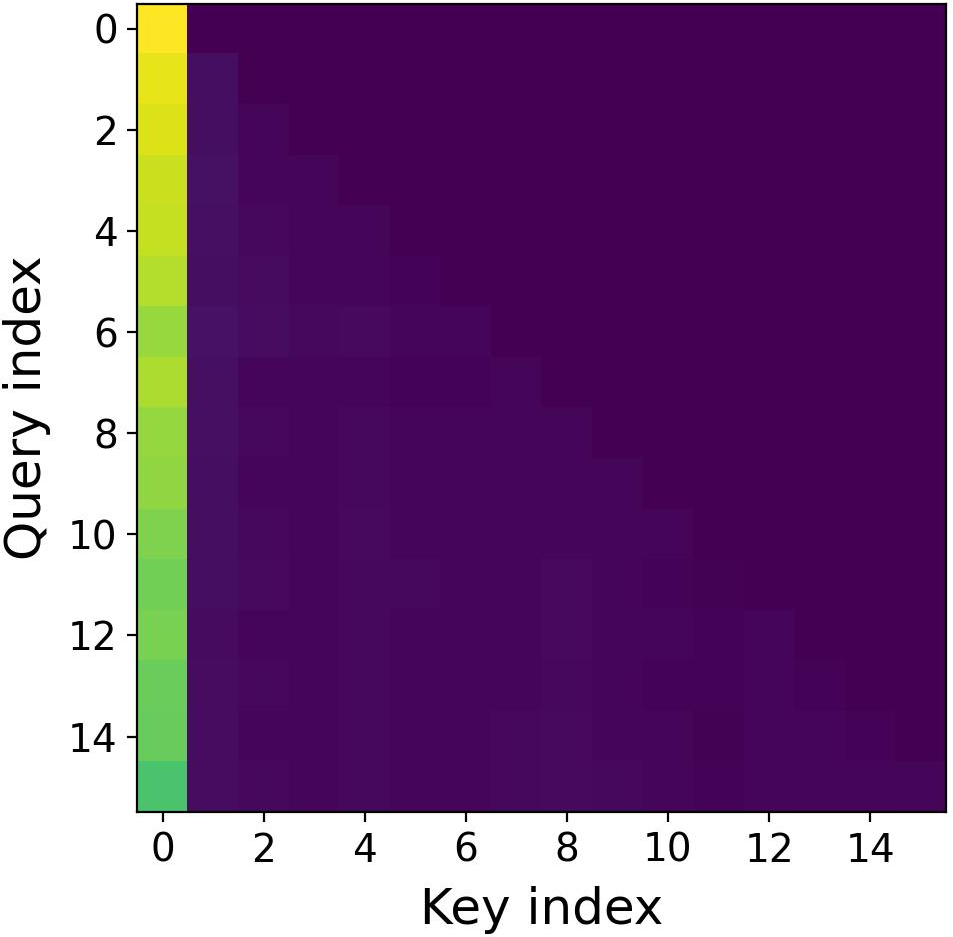
- Imaginary heads matter most for long-range:
- Visualizations show imaginary heads pay more attention to distant parts of the text (global focus).
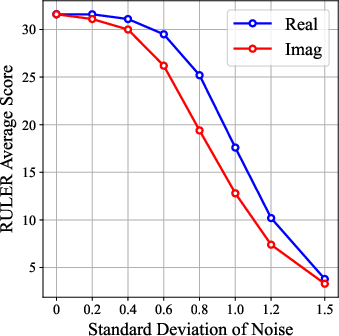
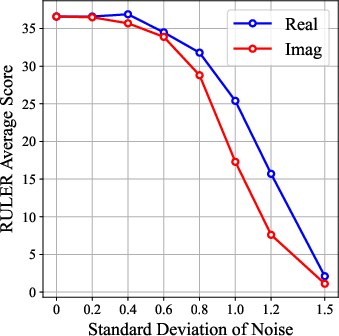
- When they added noise separately to real vs. imaginary attention, damaging the imaginary attention hurt long-context performance more. This suggests imaginary heads are especially important for long texts.
- Good short-context performance too:
- RoPE++ also performs well on regular tasks (like question answering and reading comprehension), often matching or beating standard RoPE.
- Plays well with other techniques:
- RoPE++ works alongside known long-context methods (like YaRN and Position Interpolation), and still improves results.
Why does it matter?
- Models that handle long documents better are useful for legal papers, books, scientific articles, logs, and multi-step reasoning.
- RoPE++ improves accuracy for long contexts without major changes, and can even save memory and time (with the EH setup).
- It’s simple to adopt (mostly a rotation trick) and open-sourced, so others can try it easily.
- By keeping both “near” and “far” signals, LLMs become more reliable when used beyond their training limits.
In short
RoPE++ teaches LLMs to use both parts of the “rotation” math (real + imaginary) when deciding which words to pay attention to. This extra signal helps them remember and use information from much earlier in a text, improves performance on long documents, and can reduce memory costs. It’s a practical, plug-in improvement over a widely used technique (RoPE) for position encoding in modern LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- Scaling to larger LLMs: No evidence beyond 776M/376M. It remains unknown whether gains hold or change at 7B–70B+ scales, including scaling laws and stability at very large batch sizes.
- Ultra‑long context generalization: Evaluations stop at 64k; claims about benefits “growing with length” are not tested at 128k–1M+ tokens or on streaming scenarios with frequent KV eviction.
- Real‑world long‑document tasks: Long-context evaluation uses synthetic benchmarks (RULER, BABILong); performance on real datasets (e.g., LongBench, Qasper, NarrativeQA, GovReport, multi‑doc RAG) is not assessed.
- Instruction/Chat alignment: Effects after SFT/RLHF or DPO are unknown, including whether imaginary attention behavior persists or needs calibration after alignment.
- Cross‑domain robustness: No analysis across heterogeneous corpora (code, math, biomedical, multilingual). It’s unclear if imaginary attention helps or hurts domain transfer.
- Phase choice rigidity: Only a fixed −π/2 phase shift is used. It’s unknown whether learnable per‑head phase offsets, mixtures of phases, or data‑adaptive phase schedules outperform a fixed shift.
- Calibration between real and imaginary heads: The two components may have different logit statistics; no exploration of per‑component scaling, temperature, or learned gating to balance contributions.
- Theoretical guarantees: The paper provides intuition via characteristic curves but no formal bounds or conditions under which imaginary components provably improve length extrapolation or attention expressivity.
- Frequency/base sensitivity: Robustness to rotary base choices, NTK scaling schedules, and head‑wise frequency allocations is not systematically studied.
- Layer‑wise allocation: No ablation on where imaginary heads help most (early/middle/late layers); it’s unknown if selective application by layer or block yields better cost–benefit.
- Head budget trade‑offs: The constraint that imaginary and real must share Wq is asserted but not rigorously justified; alternatives (e.g., partial sharing, low‑rank coupling, or learnable mixing) are untested.
- RoPE++_EC compute/params overhead: EC doubles heads and enlarges Wo, but the FLOPs/parameter growth and wall‑clock training cost vs. accuracy trade‑offs are not quantified.
- Prefill vs decode latency: Efficiency results report decode TPOT; prefill latency, memory bandwidth pressure, and end‑to‑end throughput under realistic serving workloads (paged attention, batching) are not measured.
- MQA/GQA deployment: Although claimed compatible, there is no empirical validation across MQA vs GQA with varying k:v ratios, nor analysis of throughput/quality trade‑offs per configuration.
- KV‑cache ecosystem: Interactions with KV compression, paging, and mixed‑precision caches are unexplored, especially for RoPE++_EH (halved cache) under production constraints.
- Quantization and low precision: Effects under INT8/FP8/4‑bit quantization (weights, activations, KV cache) are unknown; whether imaginary heads are more sensitive to quantization noise isn’t evaluated.
- Sparse and retrieval attention: Combination with block‑sparse, local–global hybrids, LongLoRA/flash‑decomposed attention, or retrieval-augmented attention remains unexplored.
- Stability and optimization: No analysis of gradients/logit norms, training instabilities, or necessary regularizers when adding imaginary heads; convergence sensitivity across seeds is not reported.
- Short‑context regressions: Cases where short‑context accuracy drops (observed in some tables) are not analyzed; conditions causing such regressions and mitigation strategies are unknown.
- Backward compatibility: Feasibility of retrofitting existing RoPE models with RoPE++ via lightweight fine‑tuning (without full retraining) is not investigated.
- Multi‑modal and encoder–decoder models: Claims of promise for heterogeneous inputs are not validated; behavior in cross‑attention, bidirectional encoders, or VLMs is unknown.
- Safety/robustness: Adversarial prompt sensitivity, long‑context prompt injection, and catastrophic forgetting under extended context are not studied.
- Interpretability depth: While attention maps suggest global focus for imaginary heads, more rigorous mechanistic analysis (e.g., probing tasks, causal scrubbing) is absent.
- Hyperparameter guidance: No principled recipe for selecting imaginary/real head ratios, output projection sizing, or optimization hyperparameters across model sizes and datasets.
- Failure modes at extrapolation extremes: Behavior beyond half/full sinusoidal periods under severe distribution shift (e.g., highly repetitive or periodic inputs) is not characterized.
- Data efficiency: Whether imaginary heads reduce the amount of long‑context training data needed (tokens to reach a target length generalization) is untested.
- Energy/cost accounting: End‑to‑end energy and dollar costs for pretraining/fine‑tuning RoPE++ variants vs RoPE at matched accuracy are not provided.
- License and deployment constraints: Potential kernel/FlashAttention modifications needed for production deployment, portability across hardware (TPUs, AMD GPUs), and memory‑layout implications are not detailed.
Glossary
- Absolute position embedding: A positional encoding scheme that assigns each token an embedding based on its absolute index in the sequence. "Notably, the newly introduced imaginary component retains the key property of the original RoPE, that it can still be formulated either as a relative position or as an absolute position embedding."
- AdamW: An optimization algorithm that decouples weight decay from the gradient update to improve training stability. "We use AdamW~\citep{loshchilov2017fixing} optimizer with weight decay 0.1"
- ALiBi: A position-bias technique that adds linear biases to attention scores to aid length generalization without explicit positional embeddings. "as well as ALiBi~\citep{presstrain}."
- BABILong: A synthetic benchmark designed to evaluate long-context reasoning and memory in LLMs. "evaluate downstream performance at varying lengths with the classical synthetic benchmarks, RULER~\citep{hsieh2024ruler} and BABILong~\citep{kuratov2024babilong}."
- Complex multiplication: Multiplication of complex numbers or vectors, used here to implement rotational position encoding in attention. "including unifying relative and absolute information via rotation matrices and complex multiplication"
- Complex plane: The two-dimensional plane representing complex numbers, used to rotate query/key vectors for positional encoding. "by applying rotations to query and key vectors in the complex plane."
- Complex-valued dot product: The dot product computed in the complex domain, whose real and imaginary parts can carry different positional information. "utilize only the real component of the complex-valued dot product for attention score calculation."
- Cosine-annealing learning rate scheduler: A schedule that decreases the learning rate following a cosine curve, often used for long training runs. "using a cosine-annealing learning rate scheduler and keeping all other settings."
- Data-sensitivity: The property of a positional encoding or model to adapt its behavior based on data characteristics rather than fixed rules. "lack of data-sensitivity~\citep{golovneva2024contextual,yang2025path}"
- Dual-component attention score: An attention scoring scheme that combines both real and imaginary parts of complex computations. "to create a dual-component attention score."
- FlashAttention: An efficient attention implementation that reduces memory usage and accelerates computation via tiling and recomputation. "perform the real and imaginary attention in a single pass in FlashAttention~\citep{daoflashattention}."
- FoPE: Fourier Position Embedding, a method that leverages Fourier features to encode positions for better length generalization. "including FoPE~\citep{hua2024fourier}"
- Gaussian noise: Random noise drawn from a normal distribution, used here to perturb attention components for ablation. "We add Gaussian noise with equal standard deviation to the imaginary and real attention components separately"
- GQA (Grouped Query Attention): An attention variant that groups queries to reduce memory and compute while retaining performance. "merely doubling the attention head group size, as shown in Figure~\ref{rope_pp_gqa_ec}. We refer to this configuration as RoPE++$_\textbf{EC$}, namely RoPE++ with equal cache size. The only cost of RoPE++ is an additional imaginary attention computed alongside the real one under the fixed QKV parameter budget. Conversely, if the total head number is kept fixed, both QKV parameters and KV cache sizes are halved. We refer to this configuration as RoPE++$_\textbf{EH$}, namely RoPE++ with equal attention head number, as shown in Figure~\ref{rope_pp_gqa_eh}. In long-context scenarios, RoPE++ halves the cache and raises throughput. Because the imaginary attention doubles the number of output heads, must be twice as large as . Therefore, in RoPE++ equals the original RoPE size, whereas in RoPE++ is double-sized. Experiments in Section~\ref{sec_exp} show that RoPE++ outperforms the original RoPE, especially on long-context tasks, and RoPE++ delivers comparable or even superior results." [Note: includes "GQA~\citep{ainslie2023gqa}" in earlier sentence: "plugs directly into MHA or GQA~\citep{ainslie2023gqa}"]
- Imaginary attention: The attention component derived from the imaginary part of the complex-valued computation, capturing long-range positional cues. "We observe that the imaginary attention still follows a rotation form"
- Imaginary component: The imaginary part of a complex number; here, the portion of attention previously discarded in standard RoPE. "we propose an extension that re-incorporates this discarded imaginary component."
- KV cache: The stored key and value tensors used during autoregressive decoding to avoid recomputation across time steps. "no extra KV cache is introduced"
- LLM: A transformer-based neural network trained on large corpora to perform a wide range of language tasks. "LLM based on attention mechanism~\citep{Vaswani2017attention} now dominates NLP"
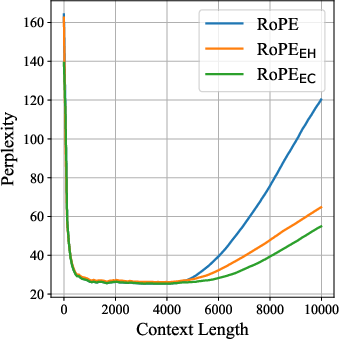
- Length extrapolation: The ability of a model to generalize to sequence lengths longer than those seen during training. "RoPE also has notable shortcomings, including poor length extrapolation~\citep{presstrain,chen2023extending,dynamicNTK}"
- Linear PI: Linear Positional Interpolation, a technique for extending context length by interpolating positional indices. "RoPE++ can not only be combined with NTK for context extension during long-context training, but can also be combined with other long-context techniques such as Linear PI~\citep{chen2023extending}"
- Multi-Head Attention (MHA): An attention mechanism that uses multiple parallel heads to capture diverse relationships in sequences. "plugs directly into MHA or GQA~\citep{ainslie2023gqa}"
- NTK: Neural Tangent Kernel-based scaling used to extend context length by adjusting positional frequencies. "RoPE++ can not only be combined with NTK for context extension during long-context training"
- Out-of-distribution (OOD): Inputs that differ significantly from the training distribution, often leading to degraded performance. "out-of-distribution (OOD) negative embeddings"
- Perplexity: A measure of LLM uncertainty; lower values indicate better predictive performance. "we measure perplexity on WikiText~\citep{DBLP:conf/iclr/MerityX0S17} and LAMBADA"
- Phase information: The angle component of complex numbers; in this context, positional phase details useful for attention. "contains valuable phase information"
- QKV parameters: The parameters of the query, key, and value projection matrices in attention. "halving QKV parameters as well as KV cache"
- Query and key vectors: The transformed token representations used to compute attention scores. "by applying rotations to query and key vectors in the complex plane."
- Relative position: The positional difference between tokens that RoPE injects into attention scores. "it injects their relative position , namely the relative distance, into the attention scores"
- Rotation matrix: A matrix that rotates vectors; used to implement RoPE by rotating Q/K features. "including unifying relative and absolute information via rotation matrices and complex multiplication"
- Rotary base: The base frequency parameter controlling RoPE’s rotation rate across dimensions. "we scale the rotary base from 10000 to 500000"
- Rotary Position Embedding (RoPE): A positional encoding method that rotates query/key features to encode positions and their differences. "Rotary Position Embedding (RoPE)~\citep{su2024roformer} has become the canonical choice"
- RULER: A synthetic long-context benchmark to evaluate retrieval and reasoning over extended sequences. "RULER~\citep{hsieh2024ruler}"
- Semantic aggregation: The tendency of attention to assign higher weights to semantically similar tokens, independent of exact distance. "including unifying relative and absolute information via rotation matrices and complex multiplication, and semantic aggregation as well as long-context decay."
- Semantic locality: The property that attention focuses more on nearby, semantically related tokens. "the real attention exhibits stronger semantic locality"
- Sine integral function: A special function, Si(x), describing accumulated sine behavior; used to approximate imaginary attention’s characteristic curve. "approximating a sine integral function"
- Sinusoidal period: The full cycle length of sine/cosine functions; relevant to how much positional variation a model observes. "once the training length exceeds half the sinusoidal period"
- Sparse attention: An attention variant that limits which positions can attend to each other to reduce computational cost. "or coupling RoPE with sparse attention~\citep{lu2024longheads,xiao2024infllm,liu2024reattention}"
- Time-Per-Output-Token (TPOT): A decoding efficiency metric measuring time taken to generate each token. "assessing the memory cost as well as Time-Per-Output-Token (TPOT)"
- YaRN: Yet another method for context extension via scaling/interpolation of positional encodings. "YaRN~\citep{pengyarn}"
Practical Applications
Immediate Applications
The following applications leverage RoPE++’s dual (real+imaginary) attention and its two deployment configurations—RoPE++EC (equal cache, double heads) and RoPE++EH (equal heads, half KV cache)—to improve long-context modeling and efficiency in production systems.
- Enterprise document analysis and contract review (Software, Legal, Finance)
- Use RoPE++EC to boost accuracy when parsing lengthy documents (contracts, RFPs, 10-K/10-Q filings, audit reports) without increasing KV cache.
- Use RoPE++EH to reduce inference memory footprint and cloud costs when analyzing large batches of documents.
- Assumptions/Dependencies: FlashAttention or equivalent attention kernel support; minor model re-training or fine-tuning to capture task-specific domain; adherence to shared Wq across real/imaginary heads and Wo sizing per paper.
- Codebase question answering and repository comprehension (Software/DevTools)
- Apply RoPE++EC to improve retrieval across entire repos, long commit histories, and multi-file contexts in IDE assistants and CI/CD analyzers.
- Assumptions/Dependencies: Integration into existing MHA/GQA stacks; long-context pre-training or continued training with scaled rotary base/PI/YaRN for maximal benefits.
- Log analytics and incident investigation at scale (Software, Security, Energy)
- Deploy RoPE++EH on memory-constrained nodes to scan long system logs, SCADA records, and security events faster with half KV cache.
- Assumptions/Dependencies: Streaming inference workflows; robust context management; long-context benchmarks (RULER/BABILong) used for acceptance tests.
- Clinical timeline summarization and longitudinal patient records (Healthcare)
- Use RoPE++EC to more reliably combine multi-year EHR notes, labs, imaging reports into cohesive summaries or decision-support prompts.
- Assumptions/Dependencies: HIPAA-compliant deployment; institution-specific fine-tuning; evaluation on long clinical documents to validate performance.
- Customer support and call center analytics (Enterprise)
- Improve understanding of multi-session transcripts and lengthy customer threads with RoPE++EC; scale cost-effectively with RoPE++EH on large batches.
- Assumptions/Dependencies: Existing RAG pipelines; prompt composition with large histories; KV cache tuning per configuration.
- Knowledge management and personal productivity (Daily Life)
- Personal assistants that ingest entire notebooks, multi-chapter books, or multi-year chat logs benefit from RoPE++EC for better recall over long histories.
- Assumptions/Dependencies: On-device memory constraints favor RoPE++EH; basic fine-tunes on personal data can further improve performance.
- Compliance monitoring and regulatory analysis (Policy, Finance)
- Government or corporate compliance teams can use RoPE++EH to cut inference memory while scanning long policy documents and regulatory updates.
- Assumptions/Dependencies: Validated performance on long policy corpora; internal approval to adopt modified attention.
- Education: Course-scale tutoring and syllabus/Q&A (Education)
- Apply RoPE++EC to tutor over entire course materials, forums, and lectures; better retrieval over long sequences.
- Assumptions/Dependencies: Fine-tuning with institutional content; guardrails for pedagogy and hallucination mitigation.
- Retrieval-Augmented Generation (RAG) with large prompt assemblies (Software)
- Combine RoPE++EC with YaRN or Linear PI to stabilize long-context RAG prompts and lower perplexity when concatenating many retrieved passages.
- Assumptions/Dependencies: Good chunking/merge strategies; RAG orchestration aware of long-context decay characteristics.
- Cloud inference cost reduction and throughput optimization (Software/Infra)
- Swap to RoPE++EH in memory-bound deployments to reduce KV cache by half, increasing throughput and lowering latency for long-context workloads.
- Assumptions/Dependencies: Kernel-level integration; monitor TPOT gains; ensure Wo size change is accounted for.
- Benchmarking and model selection for long-context use (Academia/Industry ML)
- Use the authors’ released code and checkpoints to evaluate on RULER/BABILong; pick RoPE++ configuration per memory/performance needs.
- Assumptions/Dependencies: Reproducible pipeline; acceptance metrics tailored to your domain.
Long-Term Applications
These applications may require further research, scaling, productization, or cross-modal development to reach maturity.
- Million-token context assistants and archival analytics (Software, Policy)
- End-to-end systems that ingest entire archives (FOIA releases, legislative records, corporate historical emails) for compliance and research.
- Assumptions/Dependencies: Training at million-token scales with NTK/YaRN-like methods; advanced memory management; strong retrieval orchestration.
- Multimodal long-context sequences (text–video–audio) (Robotics, Education, Media)
- Extend the imaginary attention’s global focus to video-text understanding (lecture series, surveillance streams, robotics logs) where long-range dependencies are crucial.
- Assumptions/Dependencies: Cross-modal RoPE variants; multi-modal datasets; stability under heterogeneity.
- Long-horizon planning and agent memory (Robotics, Software)
- Agents using RoPE++ to maintain extended instruction histories, operational logs, and environment narratives for better planning and compliance with constraints.
- Assumptions/Dependencies: Policy architectures that exploit long-context attention; safety validation for decision-making.
- On-device long-context LLMs in constrained hardware (Healthcare, Mobile, Edge)
- RoPE++EH enables practical long-context reasoning on hospital servers, kiosks, or edge devices with strict memory budgets.
- Assumptions/Dependencies: Hardware-specific kernels; model distillation; local privacy-preserving training.
- Complex-valued network research and tooling (Academia/ML)
- New theory and tools around dual-component attentions; curriculum to teach imaginary head semantics; broader adoption of complex-valued LLM ideas.
- Assumptions/Dependencies: Community benchmarks; interpretability tooling to visualize real vs. imaginary head roles.
- Head-level weighting, gating, and adaptive routing (Software/ML Systems)
- Products that adaptively emphasize imaginary heads for global context and real heads for local semantics, potentially improving controllability.
- Assumptions/Dependencies: Training procedures that respect RoPE++ constraints (shared Wq, inseparability noted by the authors); careful head weighting without breaking the formulation.
- KV cache compression and memory-efficient inference suites (Software/Infra)
- Libraries that bundle RoPE++EH with KV compression (e.g., Fourier-approximated caches) for cost-effective long-context deployments.
- Assumptions/Dependencies: Verified stability across tasks; alignment with vendor accelerators.
- Safety and reliability improvements via context completeness (Policy, Healthcare)
- Regulatory-grade pipelines that reduce hallucinations by leveraging long histories (case notes, provenance chains) encoded with RoPE++.
- Assumptions/Dependencies: Empirical validation of safety effects; governance frameworks; audit trails.
- Domain-specific long-context pretraining (Finance, Energy, Legal)
- Train sector-specific long-context models (e.g., energy maintenance logs, legal case histories, financial narratives) with RoPE++EC for accuracy gains.
- Assumptions/Dependencies: Access to high-quality, domain-specific long-sequence corpora; scaling strategies for rotary base and interpolation.
- Hardware co-design for attention kernels (Semiconductor/AI Infra)
- Accelerators optimized for interleaved real/imaginary attention, enabling lower-latency dual-component computations at scale.
- Assumptions/Dependencies: Vendor collaboration; standardization of RoPE++ attention ops; proof of workload demand.
- Standardized long-context evaluation frameworks and policy benchmarks (Academia, Policy)
- Public benchmarks and governance-tailored test suites using RoPE++ for legislative drafting, regulatory interpretation, and public records analysis.
- Assumptions/Dependencies: Multi-stakeholder coordination; datasets with appropriate licensing; measurement for fairness and robustness.
- Productized “LongThread” assistants and “Repo Navigator” suites (Software)
- Commercial tools specialized for multi-session chat continuity and whole-repo comprehension, with configuration toggles for RoPE++EC/EH depending on deployment constraints.
- Assumptions/Dependencies: User experience and scaling; SRE support for memory/performance trade-offs; continued long-context finetuning.
Notes on feasibility across applications:
- RoPE++ requires shared Wq between real/imaginary heads and appropriate Wo sizing (EC: double Wo; EH: Wo equals original size).
- The imaginary attention cannot exist independently of the real attention under RoPE++; configurations like “100% imaginary” are not supported by design.
- Benefits increase with longer contexts and are amplified by continued long-context pre-training (e.g., rotary base scaling, YaRN, Linear PI).
- Reported gains were demonstrated on 376M and 776M models; further scaling studies are advisable for very large models.
- Integration is facilitated by FlashAttention and MHA/GQA compatibility; careful engineering is required to ensure kernel changes and cache management are correct.
Collections
Sign up for free to add this paper to one or more collections.

