The Unreasonable Ineffectiveness of the Deeper Layers
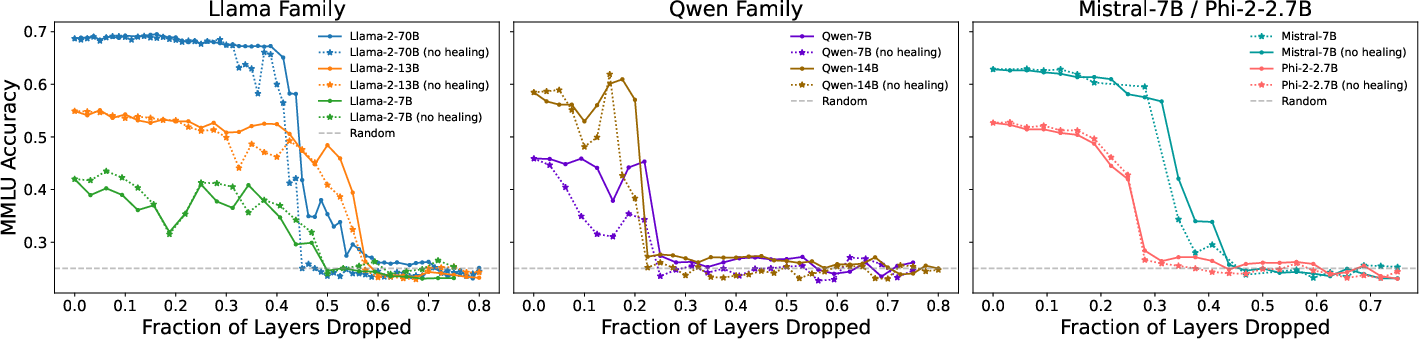
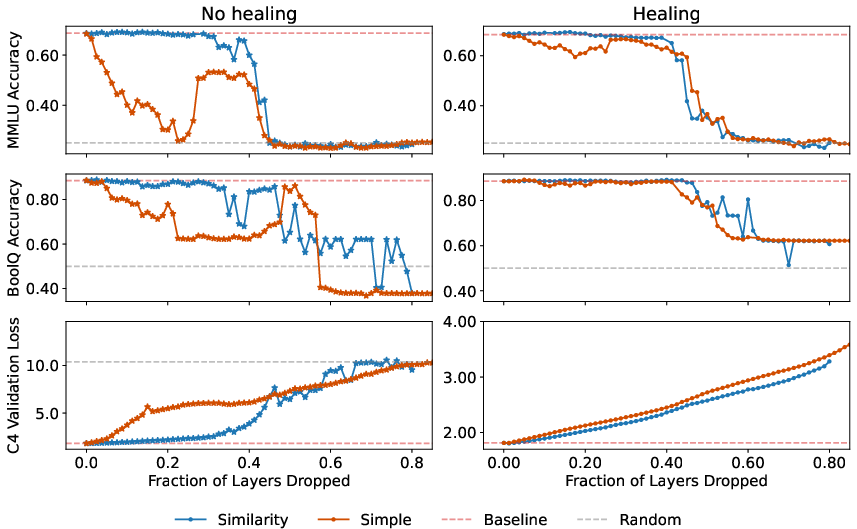
Abstract: How is knowledge stored in an LLM's weights? We study this via layer pruning: if removing a certain layer does not affect model performance in common question-answering benchmarks, then the weights in that layer are not necessary for storing the knowledge needed to answer those questions. To find these unnecessary parameters, we identify the optimal block of layers to prune by considering similarity across layers; then, to "heal" the damage, we perform a small amount of finetuning. Surprisingly, with this method we find minimal degradation of performance until after a large fraction (up to half) of the layers are removed for some common open-weight models. From a scientific perspective, the robustness of these LLMs to the deletion of layers implies either that current pretraining methods are not properly leveraging the parameters in the deeper layers of the network or that the shallow layers play a critical role in storing knowledge. For our study, we use parameter-efficient finetuning (PEFT) methods, specifically quantization and Low Rank Adapters (QLoRA), such that each of our experiments can be performed on a single 40GB A100 GPU.
- Language models are unsupervised multitask learners. 2019. URL https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
- OpenAI. Introducing chatgpt, Nov 2022. URL https://openai.com/blog/chatgpt.
- OpenAI. Gpt-4 technical report, 2023.
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Harm De Vries. Go smol or go home, July 2023. URL https://www.harmdevries.com/post/model-size-vs-compute-overhead/.
- Beyond chinchilla-optimal: Accounting for inference in language model scaling laws. arXiv preprint arXiv:2401.00448, 2023.
- Llm. int8 (): 8-bit matrix multiplication for transformers at scale. arXiv preprint arXiv:2208.07339, 2022.
- Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
- The case for 4-bit precision: k-bit inference scaling laws. In International Conference on Machine Learning, pages 7750–7774. PMLR, 2023.
- Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning, pages 38087–38099. PMLR, 2023.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Optimal brain damage. In D. Touretzky, editor, Advances in Neural Information Processing Systems, volume 2. Morgan-Kaufmann, 1989.
- Second order derivatives for network pruning: Optimal brain surgeon. In S. Hanson, J. Cowan, and C. Giles, editors, Advances in Neural Information Processing Systems, volume 5. Morgan-Kaufmann, 1992.
- Learning both weights and connections for efficient neural network. Advances in neural information processing systems, 28, 2015.
- Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710, 2016.
- The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635, 2018.
- Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023a.
- nostalgebraist. interpreting gpt: the logit lens. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens, 2020.
- Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112, 2023.
- Neural ordinary differential equations. Advances in neural information processing systems, 31, 2018.
- Tensor programs vi: Feature learning in infinite-depth neural networks. arXiv preprint arXiv:2310.02244, 2023.
- Shortgpt: Layers in large language models are more redundant than you expect. arXiv preprint arXiv:2403.03853, 2024.
- Compressing neural networks with the hashing trick. In International conference on machine learning, pages 2285–2294. PMLR, 2015.
- Data-free parameter pruning for deep neural networks. arXiv preprint arXiv:1507.06149, 2015.
- Learning structured sparsity in deep neural networks. Advances in neural information processing systems, 29, 2016.
- Network trimming: A data-driven neuron pruning approach towards efficient deep architectures. arXiv preprint arXiv:1607.03250, 2016.
- Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE international conference on computer vision, pages 1389–1397, 2017.
- Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2752–2761, 2018.
- Auto-sizing neural networks: With applications to n-gram language models. arXiv preprint arXiv:1508.05051, 2015.
- Compression of neural machine translation models via pruning. arXiv preprint arXiv:1606.09274, 2016.
- Sequence-level knowledge distillation. arXiv preprint arXiv:1606.07947, 2016.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv preprint arXiv:1905.09418, 2019.
- Are sixteen heads really better than one? Advances in neural information processing systems, 32, 2019.
- Fastformers: Highly efficient transformer models for natural language understanding. arXiv preprint arXiv:2010.13382, 2020.
- Reducing transformer depth on demand with structured dropout. arXiv preprint arXiv:1909.11556, 2019.
- Accelerating training of transformer-based language models with progressive layer dropping. Advances in Neural Information Processing Systems, 33:14011–14023, 2020.
- Layer-wise model pruning based on mutual information. arXiv preprint arXiv:2108.12594, 2021.
- Large language model distillation doesn’t need a teacher. arXiv preprint arXiv:2305.14864, 2023.
- On the effect of dropping layers of pre-trained transformer models. Computer Speech & Language, 77:101429, 2023.
- Comflp: Correlation measure based fast search on asr layer pruning. arXiv preprint arXiv:2309.11768, 2023a.
- Dynabert: Dynamic bert with adaptive width and depth. Advances in Neural Information Processing Systems, 33:9782–9793, 2020.
- The truth is in there: Improving reasoning in language models with layer-selective rank reduction. arXiv preprint arXiv:2312.13558, 2023.
- Slicegpt: Compress large language models by deleting rows and columns. arXiv preprint arXiv:2401.15024, 2024.
- Structured pruning learns compact and accurate models. arXiv preprint arXiv:2204.00408, 2022.
- Block pruning for faster transformers. arXiv preprint arXiv:2109.04838, 2021.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Can chatgpt understand too? a comparative study on chatgpt and fine-tuned bert. arXiv preprint arXiv:2302.10198, 2023.
- Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. arXiv preprint arXiv:1909.00512, 2019.
- wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems, 33:12449–12460, 2020.
- Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- Knowledge distillation of large language models. arXiv preprint arXiv:2306.08543, 2023.
- Tinybert: Distilling bert for natural language understanding. arXiv preprint arXiv:1909.10351, 2019.
- Want to reduce labeling cost? gpt-3 can help. arXiv preprint arXiv:2108.13487, 2021.
- Tinystories: How small can language models be and still speak coherent english? arXiv preprint arXiv:2305.07759, 2023.
- Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463, 2023a.
- Textbooks are all you need. arXiv preprint arXiv:2306.11644, 2023.
- Specializing smaller language models towards multi-step reasoning. arXiv preprint arXiv:2301.12726, 2023.
- Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. arXiv preprint arXiv:2305.02301, 2023.
- Lion: Adversarial distillation of closed-source large language model. arXiv preprint arXiv:2305.12870, 2023a.
- Loftq: Lora-fine-tuning-aware quantization for large language models. arXiv preprint arXiv:2310.08659, 2023b.
- Adaptive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv:2303.10512, 2023.
- Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR, 2023.
- Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774, 2024.
- Locating and editing factual associations in gpt. Advances in Neural Information Processing Systems, 35:17359–17372, 2022.
- Knowledge neurons in pretrained transformers. arXiv preprint arXiv:2104.08696, 2021.
- Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models. arXiv preprint arXiv:2301.04213, 2023.
- Dissecting recall of factual associations in auto-regressive language models. arXiv preprint arXiv:2304.14767, 2023.
- Jump to conclusions: Short-cutting transformers with linear transformations. arXiv preprint arXiv:2303.09435, 2023.
- Language models represent space and time. arXiv preprint arXiv:2310.02207, 2023.
- Neurons in large language models: Dead, n-gram, positional. arXiv preprint arXiv:2309.04827, 2023.
- Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pages 22137–22176. PMLR, 2023b.
- Task-specific skill localization in fine-tuned language models. arXiv preprint arXiv:2302.06600, 2023.
- Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- Mistral 7b. arXiv preprint arXiv:2310.06825, 2023b.
- Phi-2: The surprising power of small language models, Dec 2023.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044, 2019.
- Are emergent abilities of large language models a mirage? arXiv preprint arXiv:2304.15004, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023b.
- Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online, October 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6.
- Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv e-prints, 2019.
- Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022.
- Platypus: Quick, cheap, and powerful refinement of llms. arXiv preprint arXiv:2308.07317, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.