How Do LLMs Use Their Depth?
Abstract: Growing evidence suggests that LLMs do not use their depth uniformly, yet we still lack a fine-grained understanding of their layer-wise prediction dynamics. In this paper, we trace the intermediate representations of several open-weight models during inference and reveal a structured and nuanced use of depth. Specifically, we propose a "Guess-then-Refine" framework that explains how LLMs internally structure their computations to make predictions. We first show that the top-ranked predictions in early LLM layers are composed primarily of high-frequency tokens, which act as statistical guesses proposed by the model early on due to the lack of appropriate contextual information. As contextual information develops deeper into the model, these initial guesses get refined into contextually appropriate tokens. Even high-frequency token predictions from early layers get refined >70% of the time, indicating that correct token prediction is not "one-and-done". We then go beyond frequency-based prediction to examine the dynamic usage of layer depth across three case studies. (i) Part-of-speech analysis shows that function words are, on average, the earliest to be predicted correctly. (ii) Fact recall task analysis shows that, in a multi-token answer, the first token requires more computational depth than the rest. (iii) Multiple-choice task analysis shows that the model identifies the format of the response within the first half of the layers, but finalizes its response only toward the end. Together, our results provide a detailed view of depth usage in LLMs, shedding light on the layer-by-layer computations that underlie successful predictions and providing insights for future works to improve computational efficiency in transformer-based models.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “How Do LLMs Use Their Depth?”
Overview
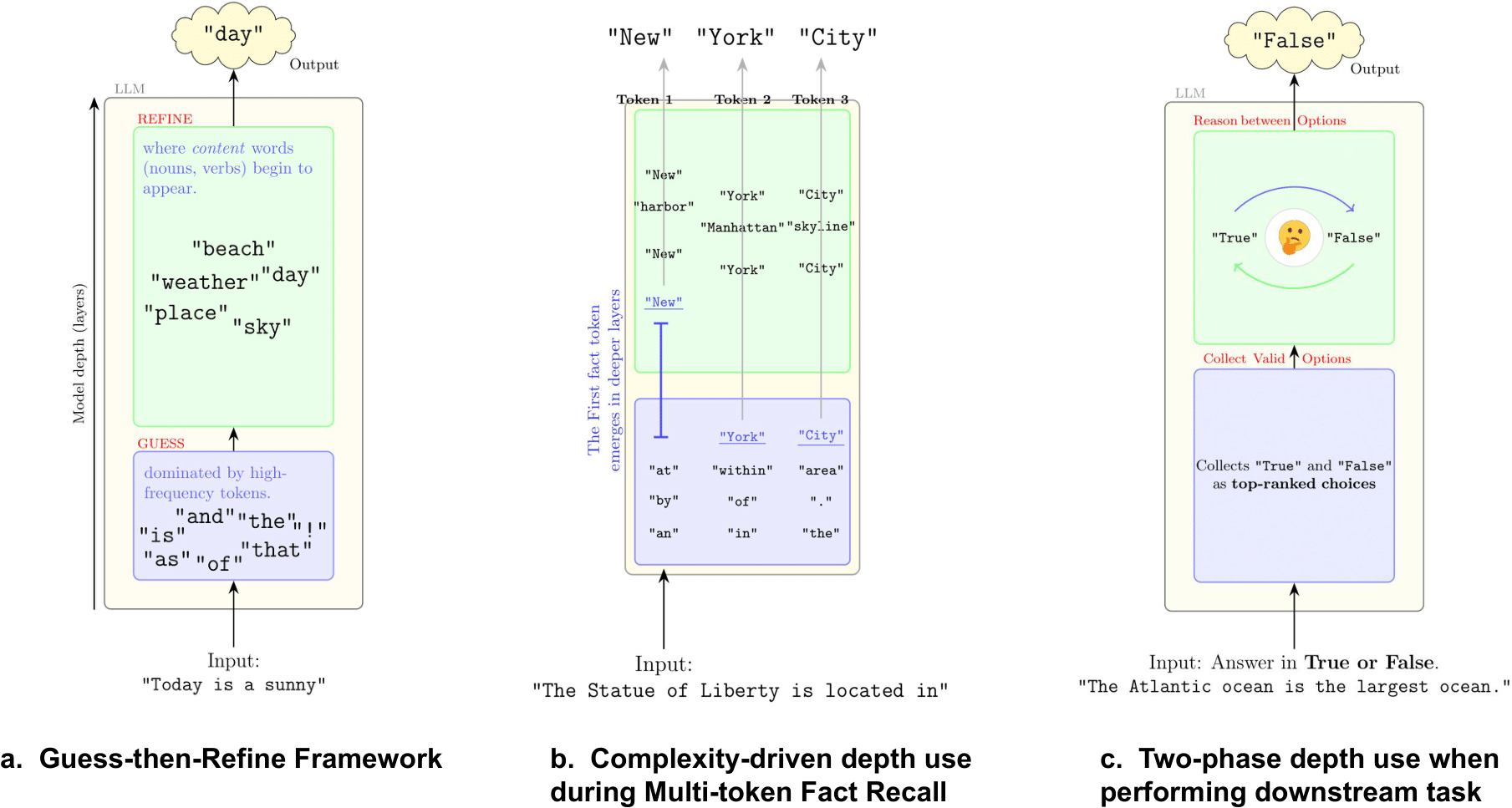
This paper asks a simple question about LLMs like GPT-2 and Llama: when they generate text, how do they use their many layers to make a prediction? The authors show that LLMs follow a “Guess-then-Refine” strategy. Early layers make quick, statistical guesses (often very common words like “the” or punctuation), and later layers use more context to refine those guesses into the final, correct word.
Key questions the paper explores
- Do LLMs decide the next word only at the very end, or do they form early guesses and improve them?
- Are some kinds of words (like “the” vs. “elephant”) decided earlier than others?
- For multi-word answers (like place names), does the first word need more thinking than later words?
- In multiple-choice tasks, when does the model figure out which options are valid and when does it actually choose the final answer?
How the researchers studied this (simple explanation)
Think of an LLM’s layers like steps in a thought process: step 1 is a quick hunch, step 2 adds more information, and so on until the final step.
The authors used a tool called TunedLens. You can imagine TunedLens as “translator goggles” that let you peek inside the model after each layer to see which word the model would pick at that moment. They used it to track how the top candidate words change from the first layer to the last.
What they did:
- Next-word prediction on real text (from Wikipedia). They looked at early vs. late layer guesses and grouped words by how common they are in the training data (very common vs. rare).
- Part-of-speech analysis (e.g., function words like “the,” “of,” and punctuation vs. content words like nouns and verbs) to see which appear early or late.
- Fact recall with single-token and multi-token answers (e.g., “New York City”) to see how depth is used across the parts of an answer.
- Multiple-choice tasks (like A/B/C/D or positive/negative): they tracked how the ranks of the options changed across the layers.
Models tested included GPT-2 XL, Pythia-6.9B, Llama 2-7B, and Llama 3-8B.
They also checked that TunedLens wasn’t “cheating” or adding its own bias, to make sure the results reflect the model’s real internal computations.
Main findings and why they matter
1) Guess-then-Refine: Early layers guess, later layers fix
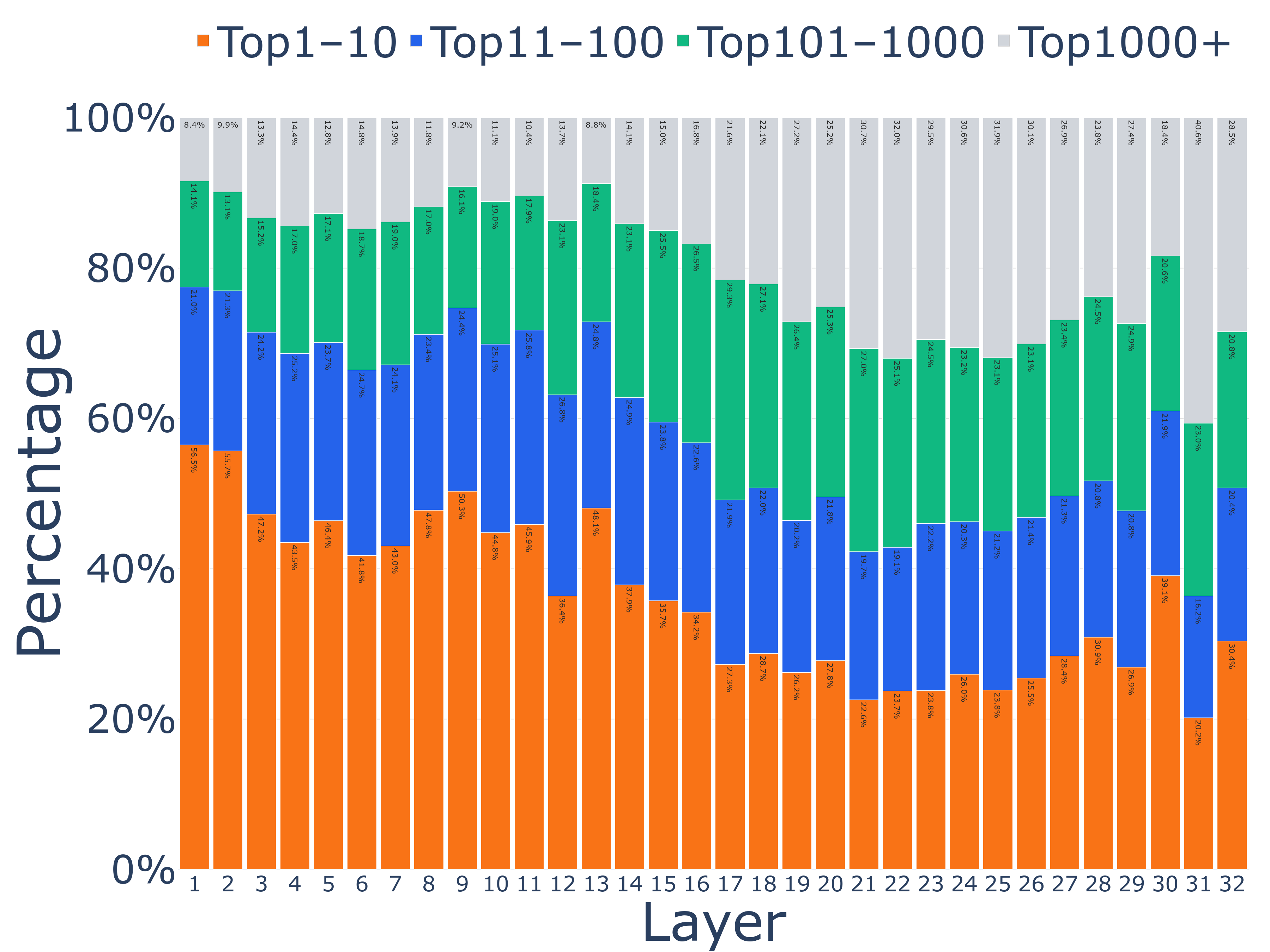
- Early layers heavily favor very common tokens. For example, in one model, early top guesses were from the 10 most frequent tokens more than half the time, even though only about one-third of final outputs were from that group.
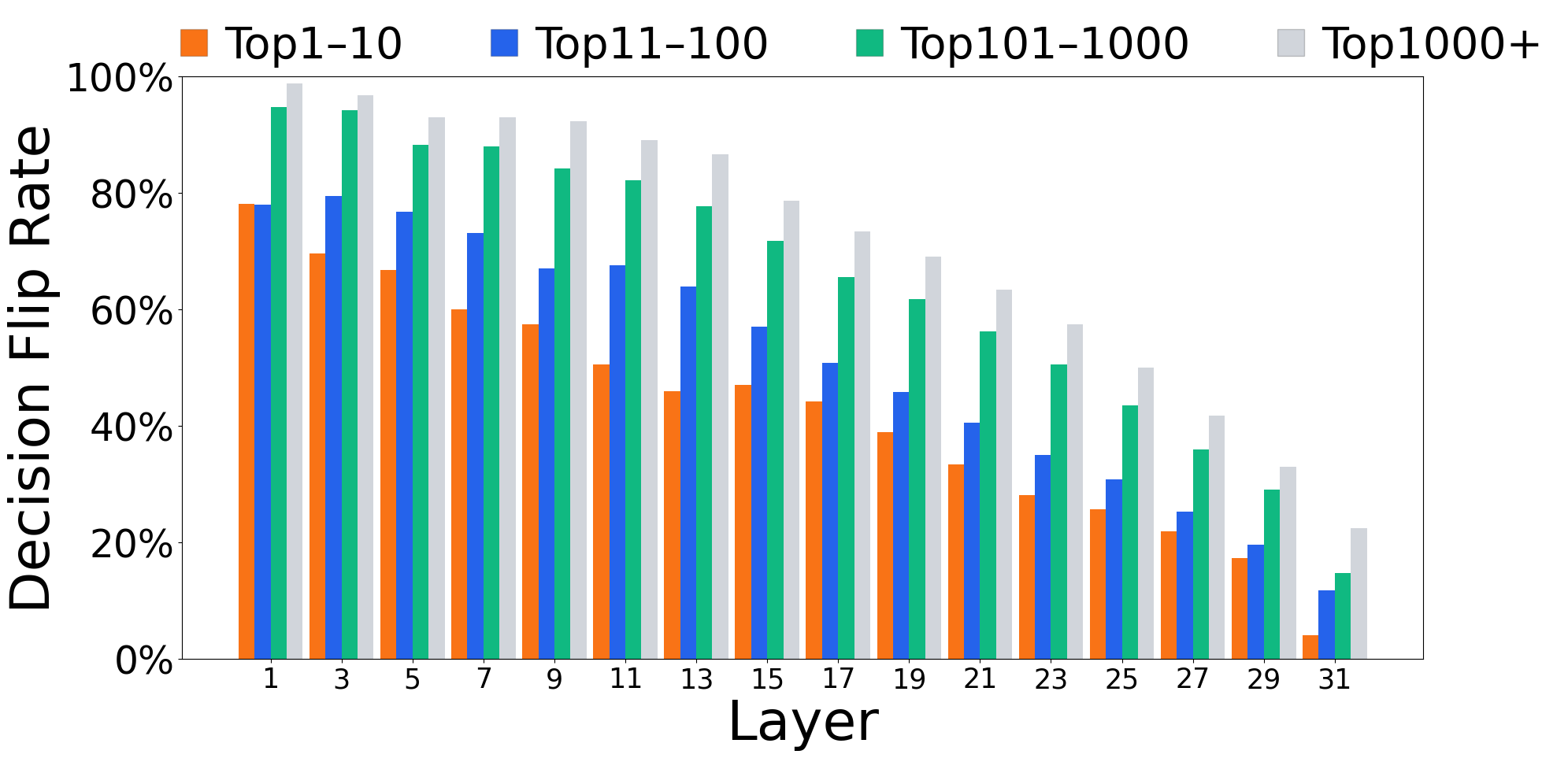
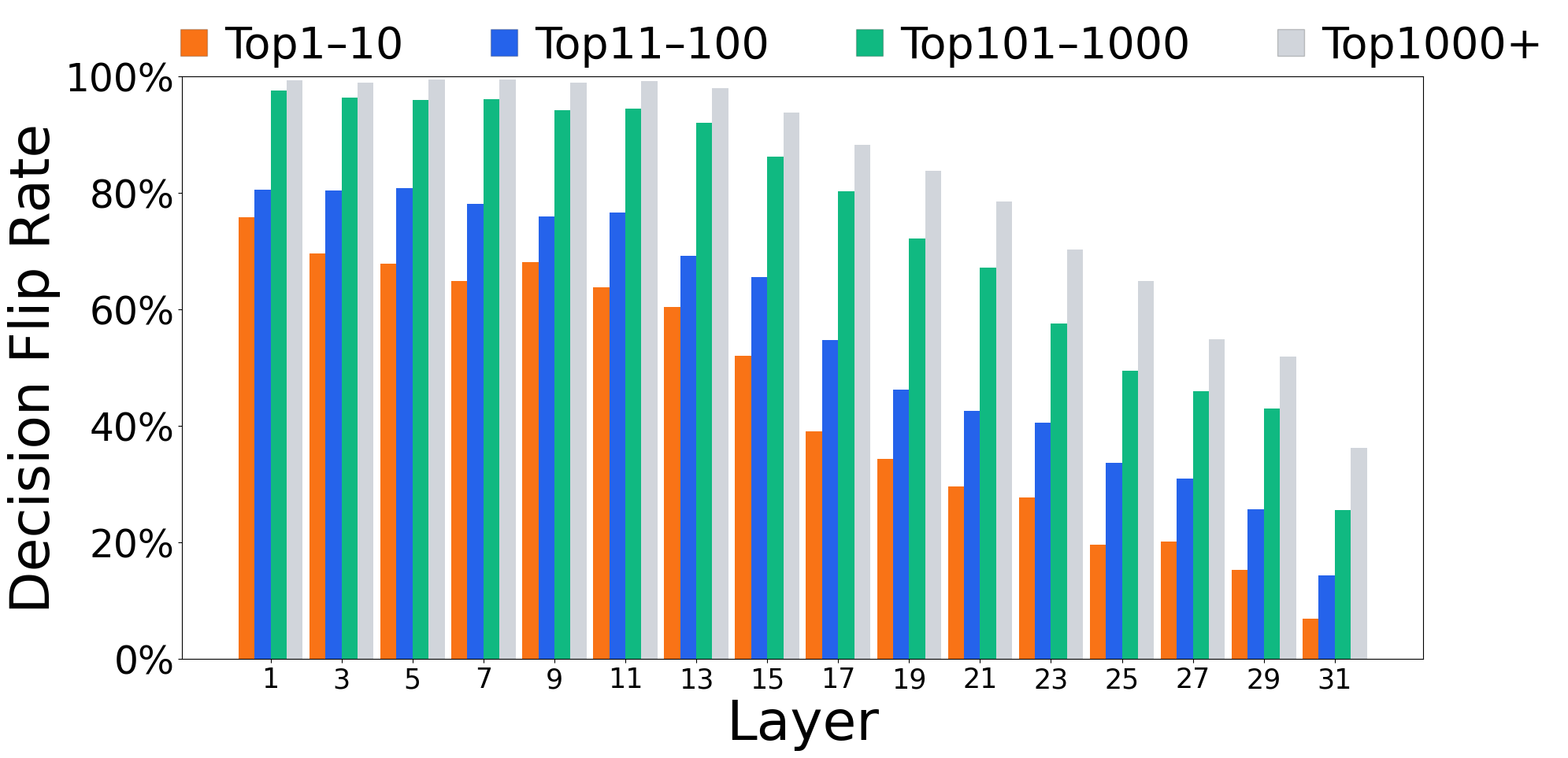
- These early guesses are not final: around 60–80% (often even more) of early top guesses get replaced by later layers. Even early guesses that were common words get revised more than 70% of the time.
- Why this matters: Early layers don’t have much context yet, so the best quick strategy is to guess common words. Deeper layers gather more context and refine the choice. This shows the model doesn’t just “know the answer” early and copy it forward — it actually reasons over depth.
2) LLMs use depth based on difficulty (“complexity-aware” depth use)
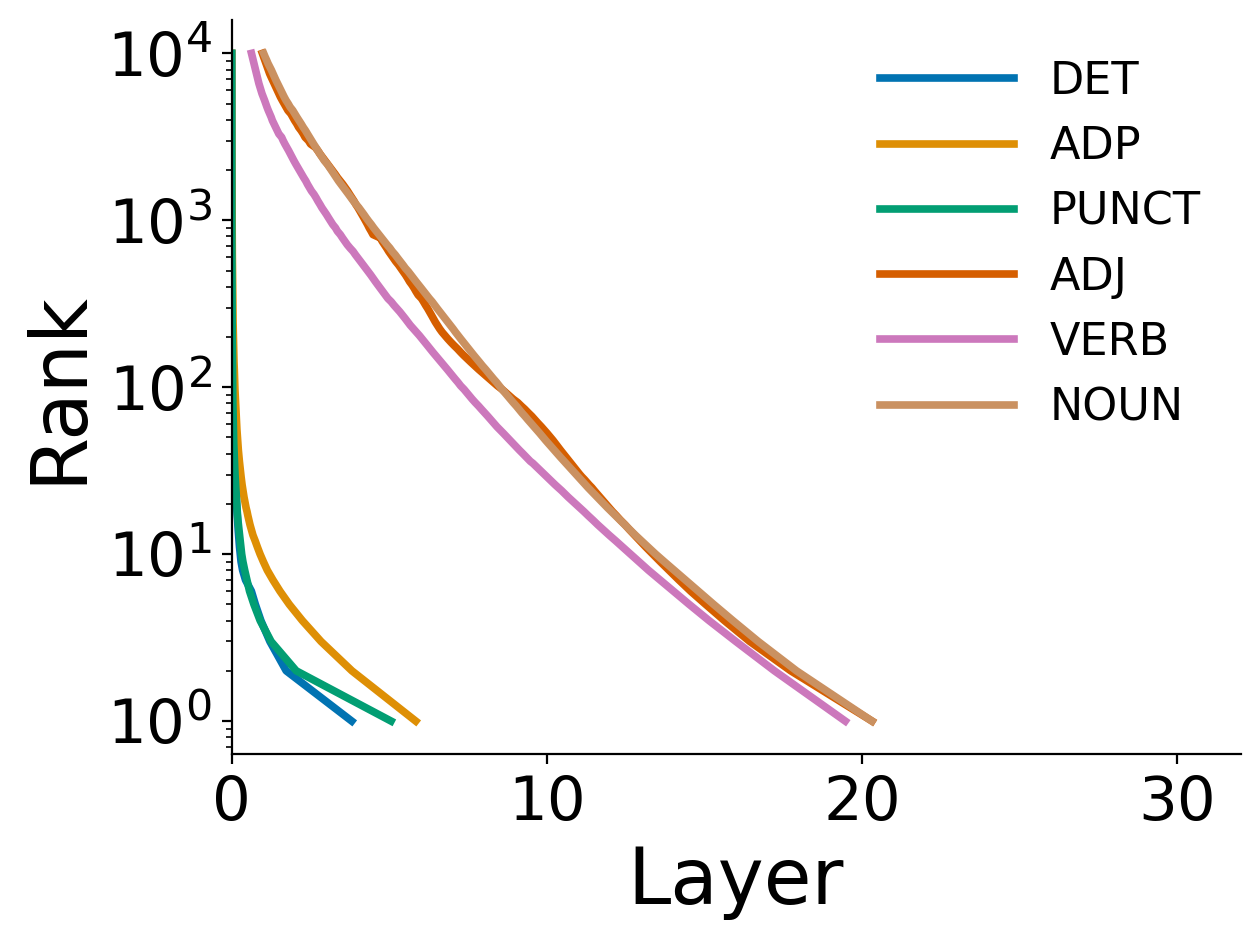
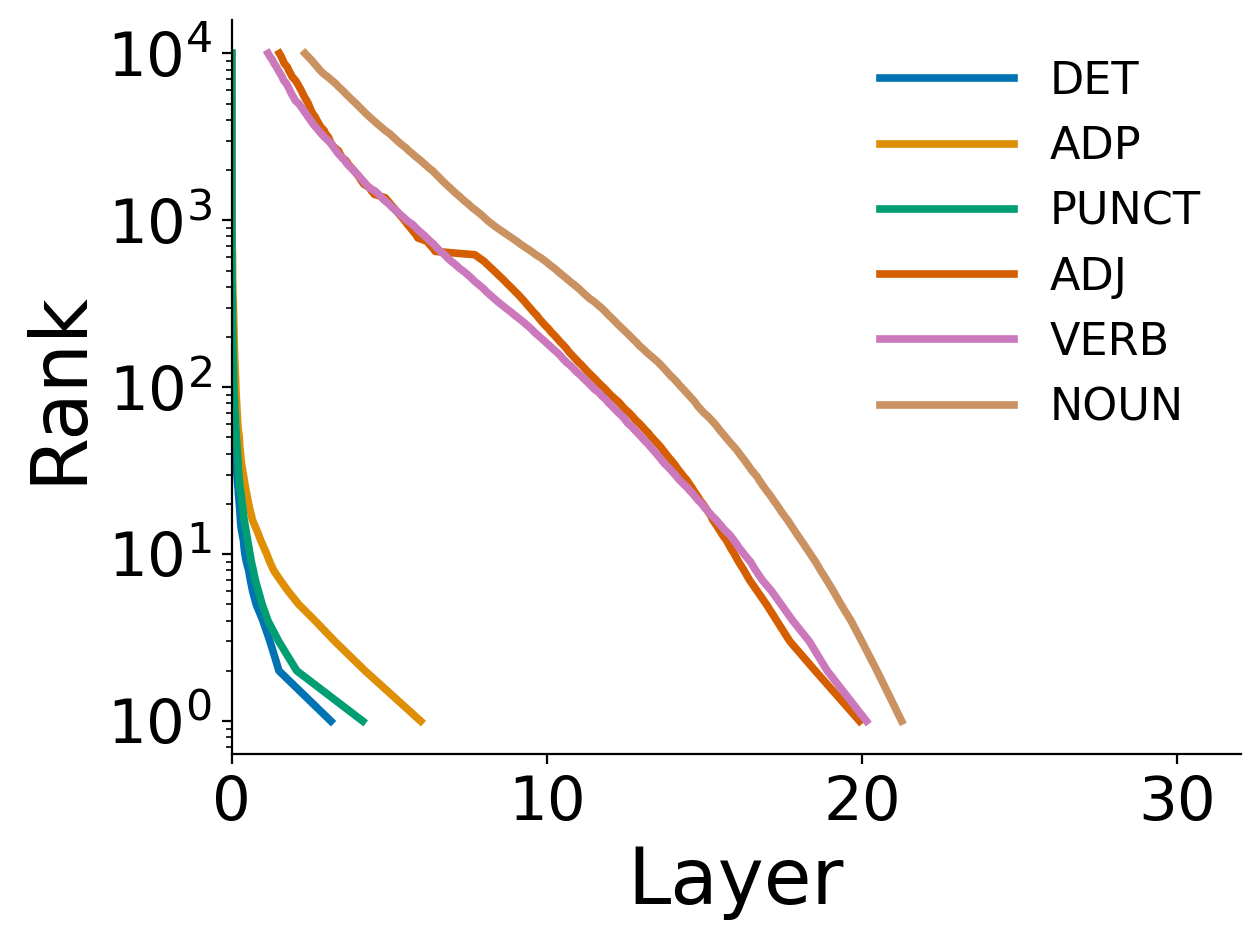
- Part-of-speech (POS) study: function words (like “the,” “of,” “in”) and punctuation become correct much earlier in the layers. Content words (nouns, verbs, adjectives) need more layers because they depend more on meaning and context.
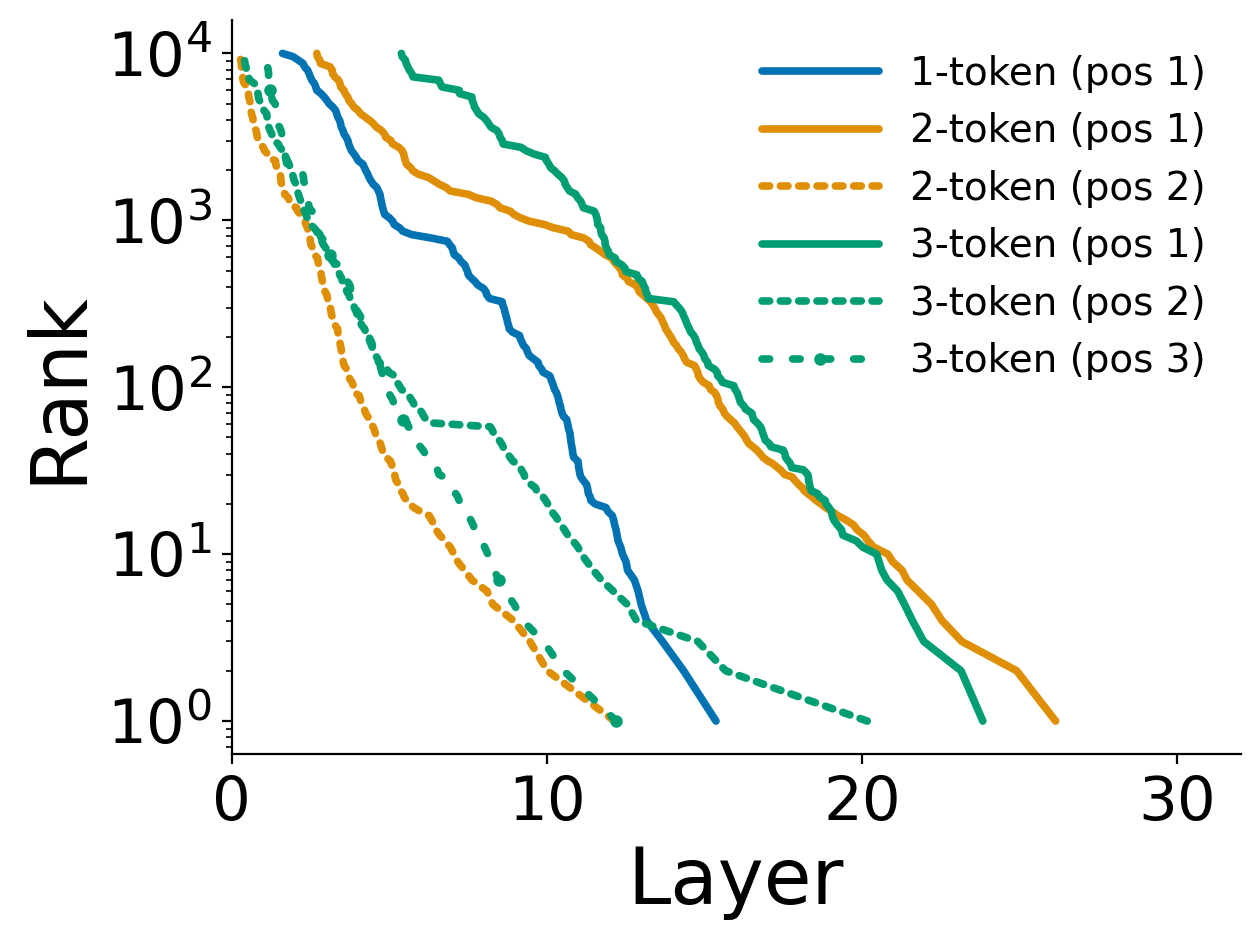
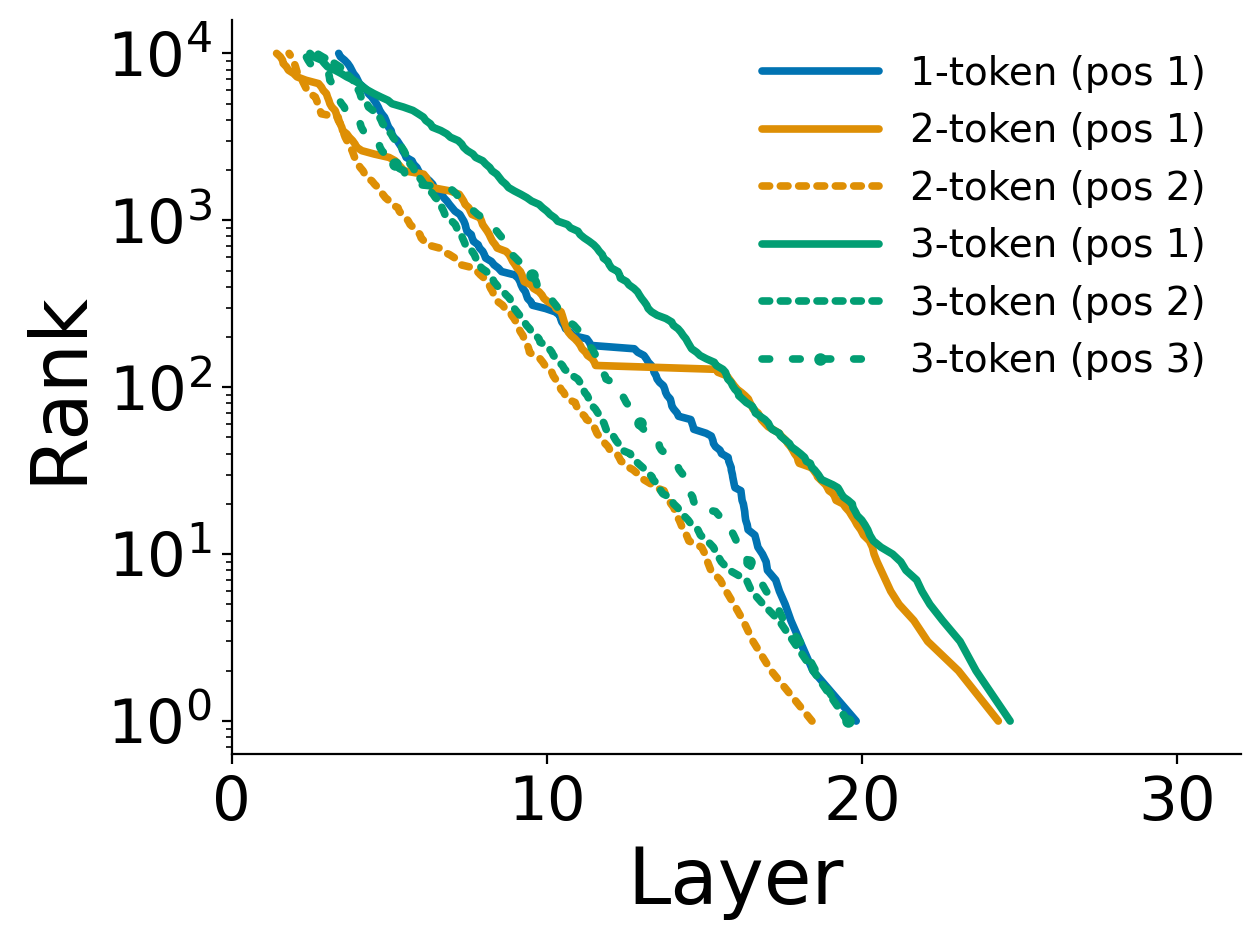
- Multi-token fact recall (e.g., “New York City”):
- The first token (e.g., “New”) typically requires the deepest computation (appears correct late).
- The following tokens (e.g., “York,” “City”) appear correctly much earlier once the first token is set.
- Single-token facts generally appear earlier than the first token of multi-token facts.
- Why: picking the initial direction is hard; once the model commits to “New,” the rest is easier to complete.
- Multiple-choice tasks (e.g., A/B/C/D; positive/negative):
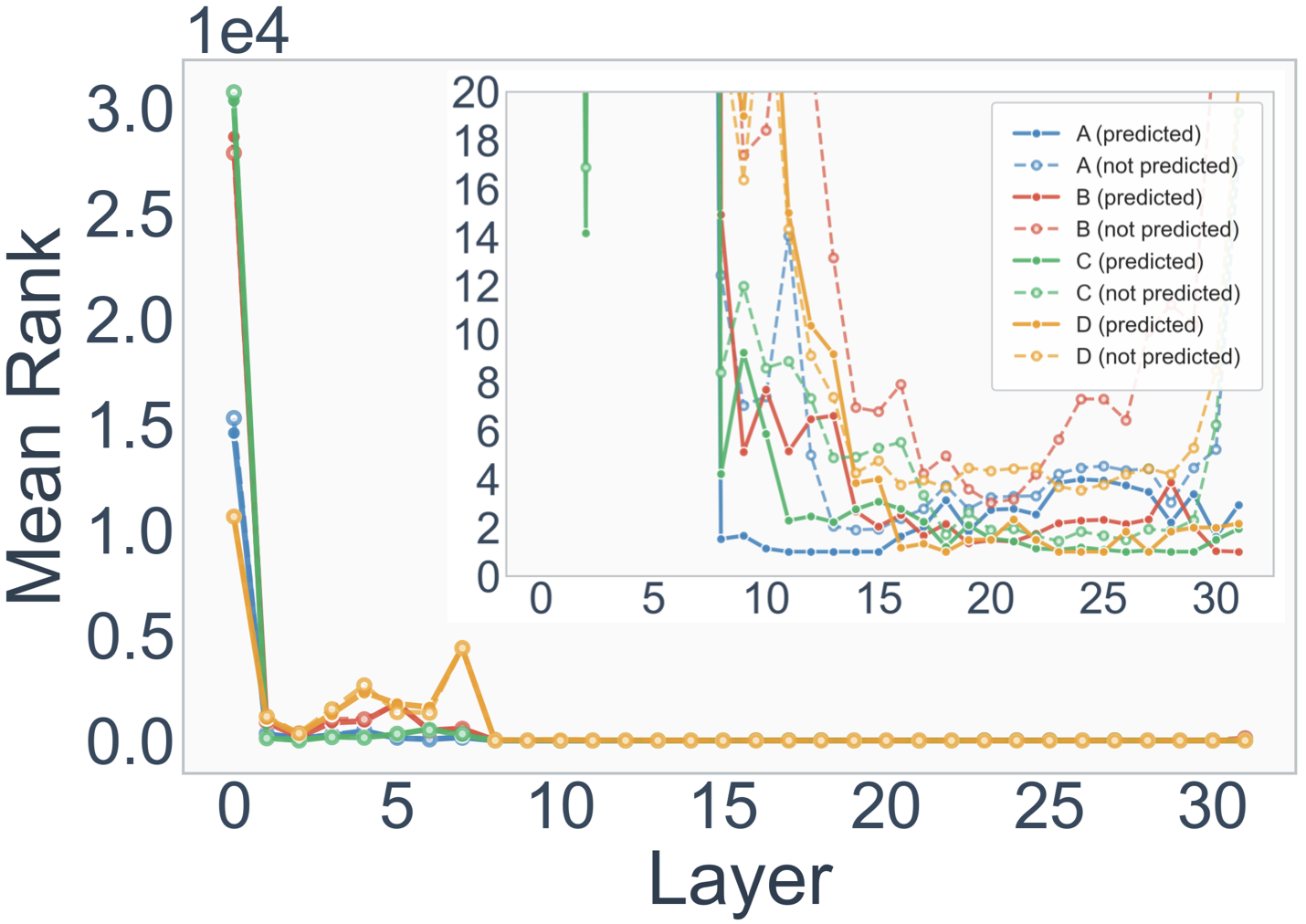
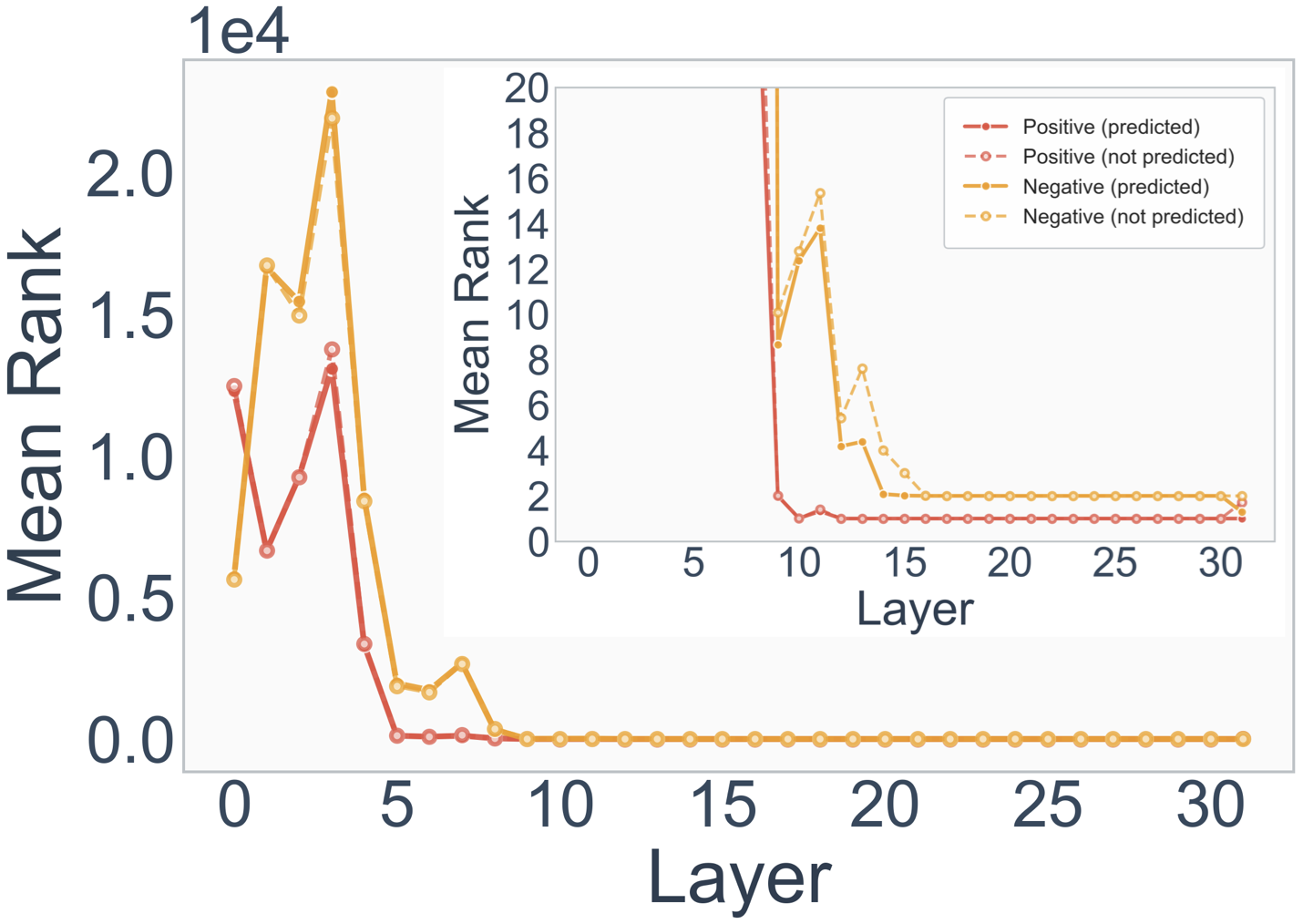
- Early layers pull the valid options into the top candidate list — the model quickly recognizes the format (e.g., that an answer should be A/B/C/D).
- Later layers do the hard part: deciding which option is actually correct, often only finalizing near the last layers.
- Sometimes there are mid-layer biases (e.g., leaning toward “A” or “positive” early) that get corrected later.
Why all this matters: It shows LLMs don’t use all layers equally. Easier subtasks (spotting function words, recognizing answer format) happen earlier. Harder subtasks (content-heavy words, first token of a fact, final option choice) need more layers.
Implications and potential impact
- Better efficiency: Since some parts are easy and resolved early, we might speed up models by using fewer layers for easy predictions and saving full depth for hard ones. But we must be careful: exiting too early risks stopping during the “refine” phase and locking in a wrong guess.
- Safer, more interpretable models: Peeking into layers helps us understand what the model knows when, how it narrows down choices, and where errors come from. This could guide debugging and safety checks.
- Smarter design and training: Knowing that models are “early guessers, late refiners” could inspire architectures and training methods that explicitly support fast guessing plus strong late reasoning.
- Task-aware compute: Systems could adapt depth to the difficulty of the token or subtask (e.g., give more layers to the first token of a multi-token fact, fewer layers to punctuation).
In short: LLMs start with quick, common-sense guesses and then progressively refine them as they “think” deeper. They naturally spend more depth on harder parts. Understanding this can help us make models faster, more accurate, and easier to trust.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and open questions the paper leaves unresolved, intended to guide future research.
- Probe dependence: The conclusions rely on TunedLens (affine translators trained with KL-divergence). Do the reported dynamics persist under alternative probing methods (e.g., direct unembedding, layer-wise logistic regressors on vocabulary, contrastive/MI-based probes, nonlinear translators), and how sensitive are findings to the probe’s training objective and hyperparameters?
- Frequency-source mismatch: Token-frequency buckets are computed on English Wikipedia rather than on the models’ actual pretraining corpora. How do results change when frequency is measured on the true training data or on diverse domains, and under domain shift (biomedical, legal, code)?
- Tokenization confounds: POS analyses map predicted subword tokens to word-level POS using SpaCy, potentially introducing mismatches across tokenizers and models. How robust are findings to different tokenization schemes (GPT-2 BPE vs SentencePiece), multi-subword tokens, punctuation/whitespace tokens, and special tokens?
- Context length and prompt style: The study uses variable-length prefixes and a 4-shot setup for downstream tasks but does not systematically control or vary prompt formatting, chain-of-thought, demonstration order, or prefix length. How do these factors modulate depth usage and the guess–refine dynamics?
- Scaling and architecture generality: Results are shown for 4 decoder-only models up to 8–6.9B parameters. Do the patterns hold for larger models (e.g., 13B–70B+), instruction-tuned/RLHF chat models, Mixture-of-Experts, and encoder–decoder architectures (tested via DecoderLens)?
- Mechanistic attribution: Which specific attention heads/MLP blocks implement “early statistical guessing” vs “late contextual refinement”? Can causal interventions (activation patching, head ablations, layer freezing) validate mechanistic roles and shift the depth of onset/refinement?
- Causality vs correlation: The paper infers that early layers lack context/knowledge access, causing frequency-driven guesses, but provides no causal proof. Can targeted interventions that restrict context aggregation or move knowledge retrieval earlier demonstrate causal links?
- Early-exiting implications: The work suggests early exiting may preempt necessary refinement but does not quantify accuracy/latency trade-offs or propose detection signals for “refinement complete.” What metrics can reliably gate per-token early exit without inflating errors?
- Formalizing “complexity”: “Easier vs harder” tokens/tasks are discussed qualitatively. Can we define and validate quantitative complexity predictors (e.g., surprisal, entropy, mutual information, syntactic/semantic features) that forecast required depth per token/task?
- Lookahead planning in multi-token facts: Subsequent tokens of multi-token facts emerge earlier than the first token. Is this due to explicit future-token planning? Can probes for future-token representations, masked lookahead controls, or controlled synthetic tasks verify planning vs frequency/format biases?
- Error-case analysis: The study focuses on correct predictions (e.g., for MQuAKE). How do depth usage and flip dynamics differ for incorrect predictions, near-misses, or ambiguous contexts? What failure modes correspond to persistent early guesses or stalled refinement?
- Cross-lingual generality: All experiments are in English. Do guess–refine and complexity-aware depth use hold in other languages (rich morphology, different scripts), and how do tokenization/frequency distributions affect onset and refinement?
- Decoding settings: Analyses center on next-token predictions under implicit greedy settings. How do sampling hyperparameters (temperature, top-k/p, beam search) affect layer-wise ranks, margins, flip rates, and refinement behavior?
- Rank margins and saturation: The paper tracks rank thresholds and flip rates but not logit margins or sequential lock-in dynamics beyond references. Can unified margin-based analyses connect pre-saturation refinement with known top-k saturation processes?
- Selection bias in fact recall: Restricting to correctly answered items may mask different depth dynamics in failed or uncertain fact retrieval. Include incorrect/low-confidence cases to assess whether and how refinement differs.
- Option-choice biases: Downstream tasks show mid/late-layer biases (e.g., toward “A” or “positive”). What causes these biases (format priors, dataset artifacts, pretraining distributions), how stable are they across tasks/models, and how can they be mitigated?
- Training trajectory: The emergence of guess–refine may evolve over training. Do intermediate checkpoints (e.g., Pythia training suite) show changes in depth usage, onset/refinement timing, and task-specific dynamics across training stages or fine-tuning (instruction/RLHF)?
- Knowledge localization tie-in: The paper links later-layer emergence in fact recall to knowledge in MLP layers via prior work but does not test causally. Do targeted knowledge edits (e.g., ROME-style) or causal tracing shift the depth at which fact tokens emerge?
- Structural/syntactic factors: Beyond POS, how do dependency distance, clause boundaries, syntactic complexity, and discourse structure influence the layer at which tokens become top-ranked?
- Practical dynamic-depth routing: Can per-token/per-position dynamic routing skip layers for “easy” tokens while preserving global coherence? What safeguards are needed to prevent error propagation from premature early guesses?
- Robustness to domain shift: When prompts come from domains with frequency distributions differing from the buckets used, do early high-frequency guesses still dominate? Test with controlled domain-specific corpora and matched frequency estimations.
- Statistical rigor: The paper lacks confidence intervals, hypothesis tests, and variance analyses. Provide statistical significance for flip rates, onset layers, and rank-crossing thresholds and report per-layer variability across prefixes/tasks.
- Reproducibility details: More explicit reporting of TunedLens training settings (objective variants, per-layer translator initialization, data splits), prefix creation, and dataset subsampling is needed to facilitate replication and sensitivity studies.
- Encoder–decoder tasks: The paper cites DecoderLens but does not test seq2seq tasks (translation, summarization). Do encoder representations and decoder depth exhibit analogous guess–refine patterns?
- Compute profiling: Depth usage is discussed conceptually but not linked to measured compute. Profile per-layer latency/energy vs accuracy gains to quantify efficiency potential of dynamic-depth strategies.
- RLHF/alignment effects: Instruction-tuned and RLHF models may alter early option-format identification and late reasoning. How do alignment training and safety filters reshape depth usage and refinement?
- Bucket design sensitivity: Frequency buckets (Top1–10, 11–100, 101–1000, 1000+) are heuristic. Test sensitivity to bucket boundaries and consider continuous frequency or surprisal-based analyses.
- Normalization/architecture components: The paper notes LayerNorm vs RMSNorm but does not isolate their effects. Do normalization types, residual scaling, or attention/MLP depth ratios modulate early guessing or refinement timing?
Practical Applications
Immediate Applications
Below are concrete, deployable ways to use the paper’s “Guess-then-Refine” and “Complexity-Aware Depth Use” findings, with sector tags, example tools/workflows, and feasibility notes.
- Depth-aware early-exit that avoids premature guesses
- Sector: software (LLM serving), cloud/edge inference, energy
- What: Add a refinement-aware gate that only early-exits when layer-wise ranks stabilize and the “high-frequency guess” pattern subsides (e.g., when Top-10 frequency tokens drop from top-1 and flip rates are low).
- Workflow: Use TunedLens or a lightweight proxy to monitor rank stability across layers; set per-task depth thresholds (e.g., deeper for factual, shallower for function words).
- Assumptions/dependencies: Access to intermediate activations/logits or a reliable probe; minor latency overhead for gate logic; tuned per-model thresholds.
- Two-stage, constrained-choice classification
- Sector: software (NLP classification), finance (fraud flags), healthcare (triage), education (grading)
- What: Exploit that early layers collect valid options into top ranks; shortlist candidates early, resolve final choice later.
- Workflow: Early layers feed a “shortlist head” that narrows ABCD or label sets; final layers (or a small verifier head) choose among 1–2 finalists.
- Assumptions: Access to intermediate ranks; works best when label space is small and fixed.
- Retrieval triggers based on depth signals (RAG)
- Sector: enterprise search, customer support, knowledge management
- What: If fact tokens do not emerge by mid-depth (or early predictions remain frequency-dominated), trigger retrieval earlier to support factual grounding.
- Workflow: Depth-based heuristics call retriever before final layers; merge retrieved context and continue.
- Assumptions: Tuned thresholds by task; slight added engineering to interleave retrieval with forward pass.
- Depth-aware quantization and pruning
- Sector: ML systems, energy
- What: Apply more aggressive quantization/pruning to early layers (statistical guesses) and preserve precision in later layers (contextual refinement).
- Workflow: Calibrate per-layer error budgets; test accuracy/latency trade-offs.
- Assumptions: Model- and hardware-dependent; requires A/B validation.
- Knowledge editing that targets first-token selection
- Sector: product QA, assistants, enterprise chat
- What: For multi-token facts, focus editing on layers/tokens where the first token of answers emerges (hardest step) to minimize collateral changes.
- Workflow: Use editing methods (e.g., ROME-like) with depth/time-of-onset diagnostics; validate that downstream tokens remain consistent.
- Assumptions: Requires open weights and editor; access to layer-wise probes.
- Error triage via “guess vs. refine” taxonomy
- Sector: software QA, LLM evaluation
- What: Diagnose whether errors stem from early statistical guesses or late refinement; prioritize fixes accordingly (prompting, retrieval, fine-tuning).
- Workflow: Add a “depth usage profile” to evaluation dashboards; tag failure mode; iterate prompts/training.
- Assumptions: Probe required; per-task profiling time.
- Bias-aware guardrails for early-exit and suggestions
- Sector: safety, compliance, UX
- What: Block early exit when top-ranked tokens are from high-frequency buckets known to induce generic or biased outputs; wait for late-layer confirmation.
- Workflow: Frequency-bucket checks combined with simple safety rules; for autocomplete, suppress low-value early suggestions (e.g., “the”, “of”) in sensitive contexts.
- Assumptions: Empirical thresholds; potential latency cost on guarded tokens.
- Prompting tactics that front-load constraints
- Sector: software, education, data labeling
- What: Explicitly surface output format early (“Answer: [A/B/C/D]”) to leverage early option collection, reducing late-layer indecision and bias.
- Workflow: Prompt templates for MCQ/NLI/SST tasks that anchor label tokens early; verify improved convergence and accuracy.
- Assumptions: Prompt-sensitive; task dependent.
- Depth-aware compute scheduling on edge devices
- Sector: mobile keyboards, on-device assistants
- What: Allocate fewer layers to function words/punctuation and more to content words or first tokens of entities.
- Workflow: Lightweight POS proxy (or heuristics) to modulate layer depth per token; measure latency/battery savings.
- Assumptions: Needs token-level control; must ensure QoS for content tokens.
- Developer tooling: Depth Usage Profiler
- Sector: academia, software
- What: A lightweight tool (built on TunedLens) showing where tokens appear, flip rates by layer, and complexity profiles by task.
- Workflow: Integrate into eval pipelines/model cards; track pre/post fine-tuning.
- Assumptions: Probe training per model; open weights preferred.
- Depth-aware caching and KV reuse
- Sector: ML systems, serving infra
- What: Cache shallow computations for tokens likely to be function words; avoid redundant deep passes where early certainty is high.
- Workflow: Token-level gating tied to rank stability; profile cache hit rates.
- Assumptions: Careful engineering to avoid correctness regressions.
Long-Term Applications
These ideas require further research, scaling, or deeper integration with infrastructure and policy.
- Learned dynamic-depth controllers
- Sector: software, systems
- What: Train halting/gating modules that predict per-token depth budgets, aligning with guess-then-refine and task complexity.
- Tools/products: Depth-Adaptive Decoding libraries; training with auxiliary halting losses.
- Dependencies: Dataset- and model-specific training; robust calibration.
- Speculative decoding 2.0 (guesser–refiner co-design)
- Sector: software, cloud
- What: Use a shallow “guesser” to emit high-frequency candidates; a deeper “refiner” verifies/corrects, sharing KV caches and avoiding redundant work.
- Workflow: Asynchronous pipelines that interleave shallow proposals and deep confirmations.
- Dependencies: Careful synchronization; throughput vs. latency trade-offs.
- Hardware–software co-design for layer skipping
- Sector: semiconductors, cloud
- What: Accelerator kernels and schedulers optimized for per-token partial-depth execution, non-uniform precision, and late-layer emphasis.
- Dependencies: New runtime APIs; memory orchestration for partial passes; vendor support.
- Fine-tuning objectives to calibrate early guesses
- Sector: ML research/engineering
- What: Auxiliary losses that discourage overconfident early high-frequency guesses and reward calibrated late-layer refinement.
- Dependencies: Access to training; risk of slower convergence; requires careful weighting.
- Depth-aware MoE routing
- Sector: large-scale LLM serving
- What: Route tokens to experts based on depth-stage and complexity (e.g., use cheap experts for function words; knowledge experts for late factual refinement).
- Dependencies: Routing policy learning; expert specialization; added systems complexity.
- Depth-aware RAG orchestration standards
- Sector: enterprise AI, standards bodies
- What: Protocols specifying when to retrieve (e.g., if fact tokens don’t emerge by layer L), and how to merge retrieved context mid-pass.
- Dependencies: APIs for mid-pass intervention; model cooperation.
- Safety certification for early-exit systems
- Sector: policy, regulated industries
- What: Auditable criteria showing that early-exit does not truncate necessary refinement in high-stakes tasks (clinical, legal).
- Dependencies: Benchmarks for “refinement sufficiency”; third-party audits; regulatory buy-in.
- Public model-card fields for depth usage
- Sector: policy, academia
- What: Standardized reporting of refinement depth, flip rates, and task-dependent depth needs.
- Dependencies: Consensus on metrics; willingness from model providers to expose internals.
- Knowledge maintenance pipelines focusing on first-token control
- Sector: enterprise knowledge management
- What: Automated detection and editing of the first-token selection locus in multi-token facts to reduce collateral updates and drift.
- Dependencies: Editing tools at scale; eval harnesses for regressions.
- Depth-aware training data curation
- Sector: data engineering
- What: Reweight or curate corpora to reduce excessive early frequency bias (e.g., inverse-frequency auxiliary sampling for early-layer objectives).
- Dependencies: Access to pretraining; unclear impact on downstream generalization.
- UX for “draft then refine” assistants
- Sector: productivity, education
- What: Interfaces that delay or visually mark low-confidence early drafts and surface final, refined outputs when late-layer confirmation occurs.
- Dependencies: Confidence calibration; user studies; real-time layer signaling.
- Robotics and real-time decision systems
- Sector: robotics, autonomous systems
- What: Allocate shallow, low-latency guesses for fast control loops and defer high-stakes decisions to deeper refinement cycles.
- Dependencies: Tight latency budgets; reliability guarantees; hybrid controllers.
- Finance and trading risk gates
- Sector: finance
- What: Early shortlist generation (candidates, warnings) with execution permitted only after late-layer confirmation surpasses stability thresholds.
- Dependencies: Regulated audit trails; strict SLAs; robust calibration.
- Healthcare decision support with refinement assurance
- Sector: healthcare
- What: For diagnostic or treatment suggestions, require late-layer convergence for the first decision token of multi-token recommendations.
- Dependencies: Clinical validation; liability frameworks; EHR integration.
- Depth-aware compression curricula
- Sector: model compression
- What: Compression strategies that preserve late-layer capacity while aggressively compressing early layers, guided by depth-usage profiles.
- Dependencies: Task-specific tuning; potential distribution shift.
- Standard APIs to expose intermediate signals
- Sector: platform providers
- What: Secure, rate-limited interfaces to obtain depth/rank stability signals for orchestration (without exposing raw activations).
- Dependencies: Privacy, IP concerns; performance impact.
Cross-cutting assumptions and dependencies
- Observations were validated on open-weight models (GPT2-XL, Pythia-6.9B, Llama 2-7B, Llama 3-8B) and English corpora; behavior may vary for larger, multilingual, or instruction-tuned models.
- Many applications require access to intermediate layer signals; proprietary APIs may not expose them. Proxies (e.g., distilled probes) could approximate signals with some loss.
- TunedLens fidelity is strong in early layers but not perfect; production systems should use conservative thresholds and task-specific calibration.
- Dynamic-depth execution complicates GPU/TPU scheduling and KV-cache management; careful engineering is needed to realize net speed/energy gains.
- Safety-critical domains should treat refinement-aware gating as a safety control, not a shortcut; independent validation is required.
Glossary
- Adpositions: Grammatical relation words (e.g., prepositions/postpositions) that link other words; common in POS tagging. "Adpositions include prepositions and postpositions"
- Affine mapping: A linear transformation plus bias used to translate representations between spaces. "TunedLens learns an affine mapping between the output representations of each layer and the final unembedding matrix"
- Attention layers: Transformer components that aggregate contextual information across tokens. "the input has not been through enough attention layers to aggregate a complete contextual representation of the input"
- DecoderLens: A lens method extending layerwise decoding to encoder–decoder transformers. "DecoderLens \citep{langedijk2023decoderlens} extends the lens idea to encoderâdecoder models and reports that specific subtasks are handled at lower or mid layers."
- Dynamic depth models: Models that adaptively use different numbers of layers depending on task complexity. "LLMs are natural dynamic depth models and use their depth intelligently based on the complexity of the task."
- Early exiting: Halting computation before the final layer to save compute during inference. "Early exiting strategies may choose to exit while refinement is still ongoing, thus increasing the token selection error rate and over-predicting"
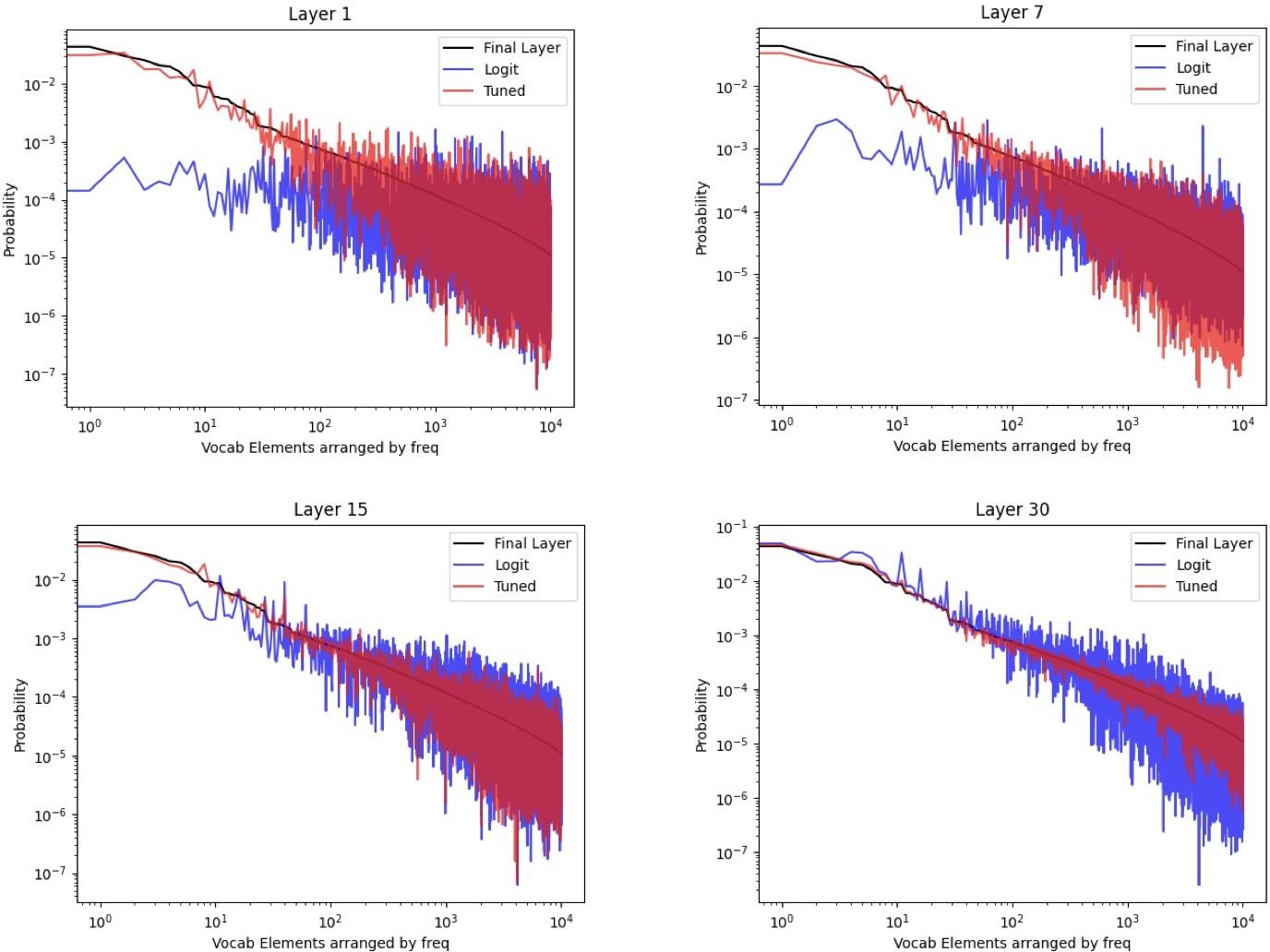
- Frequency-Conditioned Onset: The tendency for early-layer predictions to favor high-frequency tokens before context is integrated. "We call this “Frequency-Conditioned Onset”, where LLMs tend to use corpus statistics while making candidate proposals in early layers."
- Function words: High-frequency grammatical words (e.g., determiners, prepositions) that carry little lexical content. "Part-of-speech analysis shows that function words are, on average, the earliest to be predicted correctly."
- Guess-then-Refine: A framework where models make early statistical guesses and later refine them using context. "We propose a “Guess-then-Refine” framework for understanding model computations across layers"
- In-context learning: The ability of models to learn from examples provided in the prompt at inference time. "Many prior works have studied the internal mechanisms of in-context learning in LLMs"
- Iterative inference: Progressive, layer-by-layer refinement of predictions within transformers. "and explicitly frames transformers as performing iterative inference across depth."
- KL-divergence: A measure of the difference between probability distributions, used as a training objective. "The TunedLens probes are trained to minimize the KL-divergence between the final layer probability distribution and an intermediate layer probability distribution"
- LayerNorm: A normalization technique applied within transformer layers to stabilize training and inference. "We use normalization to mean both LayerNorm used in GPT-family of models and RMSNorm used in the Llama-family of models."
- LogitLens: A technique that decodes intermediate layer representations using the final unembedding to inspect token-level predictions. "The LogitLens framework provides some initial insights by using the final unembedding layer of a model to decode intermediate layer representations in the token space."
- Lookahead planning: Internal computation that anticipates future tokens or structure during generation. "present evidence of lookahead planning in LLMs"
- MMLU: A benchmark of multiple-choice questions across many subjects to assess broad language understanding. "As the model performs tasks like MMLU (response options: ABCD) and sentiment analysis ( response options: positive/negative), we track the mean rank of the options through the layers."
- MQuAKE: A dataset designed to evaluate factual recall, including multi-token facts. "In this case study, we track the predicted tokens through intermediate layers during fact recall using the MQuAKE dataset"
- MRPC: The Microsoft Research Paraphrase Corpus, used for paraphrase detection. "Natural Language Inference (NLI) and Paraphrase Dectection (MRPC)."
- Natural Language Inference (NLI): A task that determines entailment, contradiction, or neutrality between sentence pairs. "Natural Language Inference (NLI) and Paraphrase Dectection (MRPC)."
- Option-constrained downstream tasks: Tasks where the model’s output must be one of a fixed set of options (e.g., MCQ, True/False). "we analyze the layer-wise prediction dynamics when the models perform downstream tasks with a constrained set of option choices, such as answering multiple-choice (MCQ) or True/False questions."
- Rank threshold: A specified cutoff in token ranking (e.g., top-k) used to track when a token becomes competitive. "We plot the average layer at which a particular rank threshold is crossed by the predicted token at intermediate layers."
- RMSNorm: A normalization variant based on root mean square, used in some transformer families. "We use normalization to mean both LayerNorm used in GPT-family of models and RMSNorm used in the Llama-family of models."
- TunedLens: An approach that trains affine probes to align intermediate layer representations with the final unembedding for faithful decoding. "Here, we leverage TunedLens to detail and quantify token prediction patterns across LLM layers."
- TunedLens probe: The trained probe component of TunedLens used to decode intermediate representations. "This analysis is done using the TunedLens probe \citep{tunedlens} probe, which allows us to decode earlier layer representations with higher fidelity."
- Unembedding matrix: The matrix that projects hidden states into vocabulary logits for token prediction. "Intermediate activations in LLMs can be projected onto the vocabulary space using the unembedding matrix"
Collections
Sign up for free to add this paper to one or more collections.