- The paper presents a decoupled sparsity framework that separates query-agnostic prefill pruning from query-aware token retrieval, ensuring multi-turn conversation fidelity.
- It achieves up to 4.0x speedup in prefilling, 2.5x in decoding, and 2.6x overall inference acceleration while maintaining accuracy in long-context visual tasks.
- The approach leverages Triton kernel optimizations for efficient visual and textual salience computations, enhancing performance in document understanding and video analysis.
SparseVILA: Decoupling Visual Sparsity for Efficient VLM Inference
SparseVILA addresses the persistent challenges of scalability and efficiency in Vision LLMs (VLMs), which integrate visual and textual reasoning across diverse applications. By proposing a decoupled sparsity framework, SparseVILA optimizes VLM inference through selective token pruning during prefill and query-focused token retrieval during decoding. This strategy is pivotal in mitigating latency issues associated with extensive visual token processing in complex tasks such as high-resolution image understanding and long-video analysis.
Introduction to SparseVILA
VLMs are integral to conversational systems that leverage both visual and textual data, yet their scalability faces constraints due to the vast number of visual tokens processed during inference. Traditional methods of alleviating latency through model pruning and KV cache compression often compromise the fidelity of multi-turn conversational tasks by permanently discarding irrelevant visual tokens during initial context stages.
SparseVILA offers a novel approach by decoupling the sparsification process into query-agnostic pruning for prefilling and query-aware retrieval during decoding, maintaining multi-turn conversation fidelity. This framework ensures significant speedup in inference times—up to 4.0× faster in prefilling and 2.5× faster in decoding, ultimately achieving a 2.6× improvement in end-to-end speed and enhancing accuracy on document-understanding and reasoning tasks.
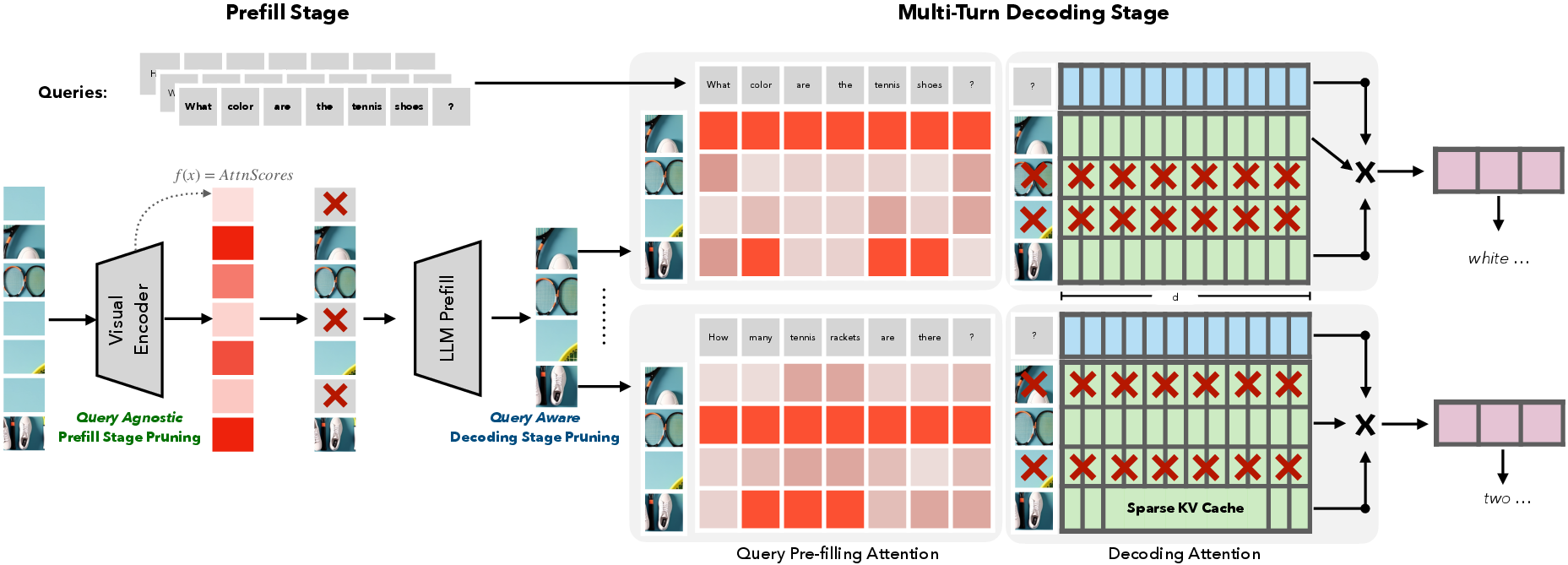
Figure 1: SparseVILA's decoupled sparsity framework facilitates efficient VLM inference by organizing token pruning and retrieval across multiple stages ensuring context preservation and query relevance.
Query-Agnostic and Query-Aware Sparsity
The prefill phase of SparseVILA involves query-agnostic pruning that identifies and removes redundant tokens based on salience scores without the need for textual input. This is crucial for maintaining stable performance across multi-turn interactions, where context preservation is paramount.
In contrast, during decoding, SparseVILA employs query-aware retrieval. Tokens relevant to the current query are dynamically activated from the visual cache for attention computation, ensuring efficient generation without compromising integrity across turns. The employed Triton kernels demonstrate substantial acceleration benefits, providing up to 10.0× and 1.8× speedups for visual and textual salience computations respectively.
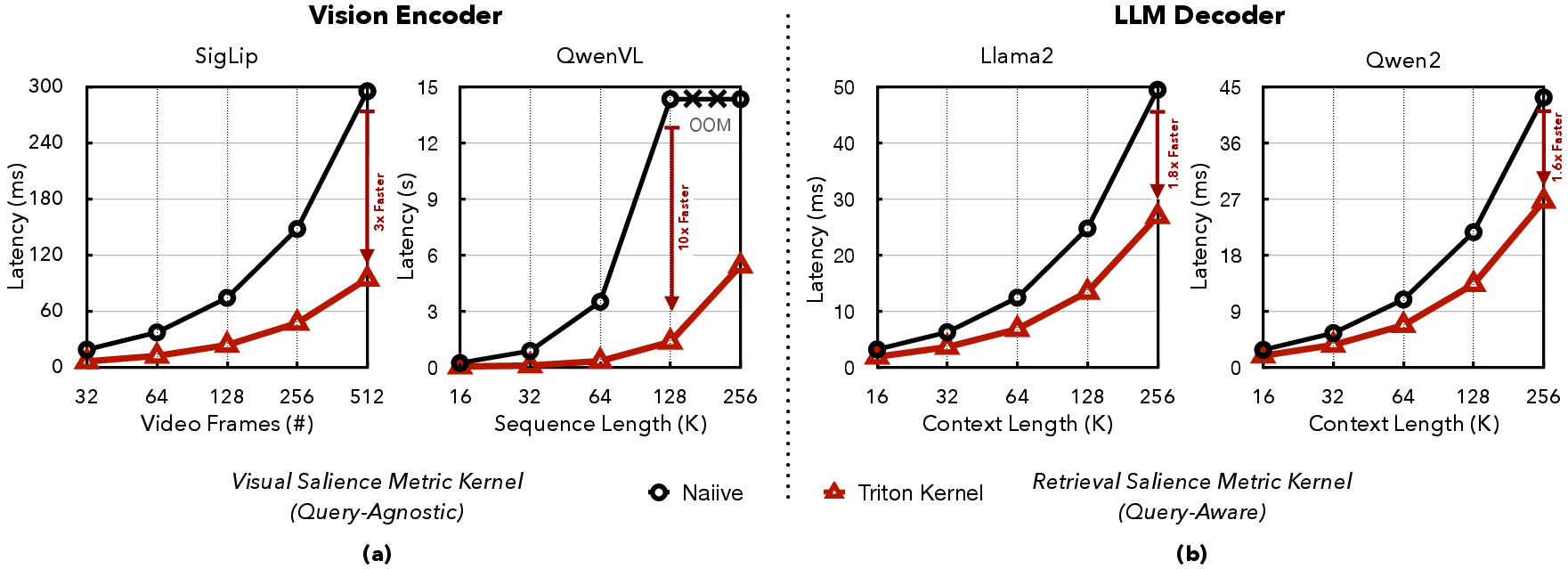
Figure 2: Triton kernels in SparseVILA accelerate both query-agnostic and query-aware salience computations, enhancing inference efficiency.
Results from Benchmarks
SparseVILA consistently performs well across various visual and video benchmarks, maintaining competitive accuracy while significantly reducing latency. Notably, the model excels in long-context scalability; it supports sustained performance up to 200 frames, whereas alternative methods fail beyond 32 frames, showcasing superior adaptability to extended visual scenarios.

Figure 3: SparseVILA's efficient visual retrieval sustains perfect performance up to 200 frames, demonstrating robust long-context scalability.
Additionally, SparseVILA's effectiveness in multi-turn evaluations is illustrated by its retention of stable visual sinks and retrieval tokens across layers, enabling efficient yet faithful query-conditioned decoding.
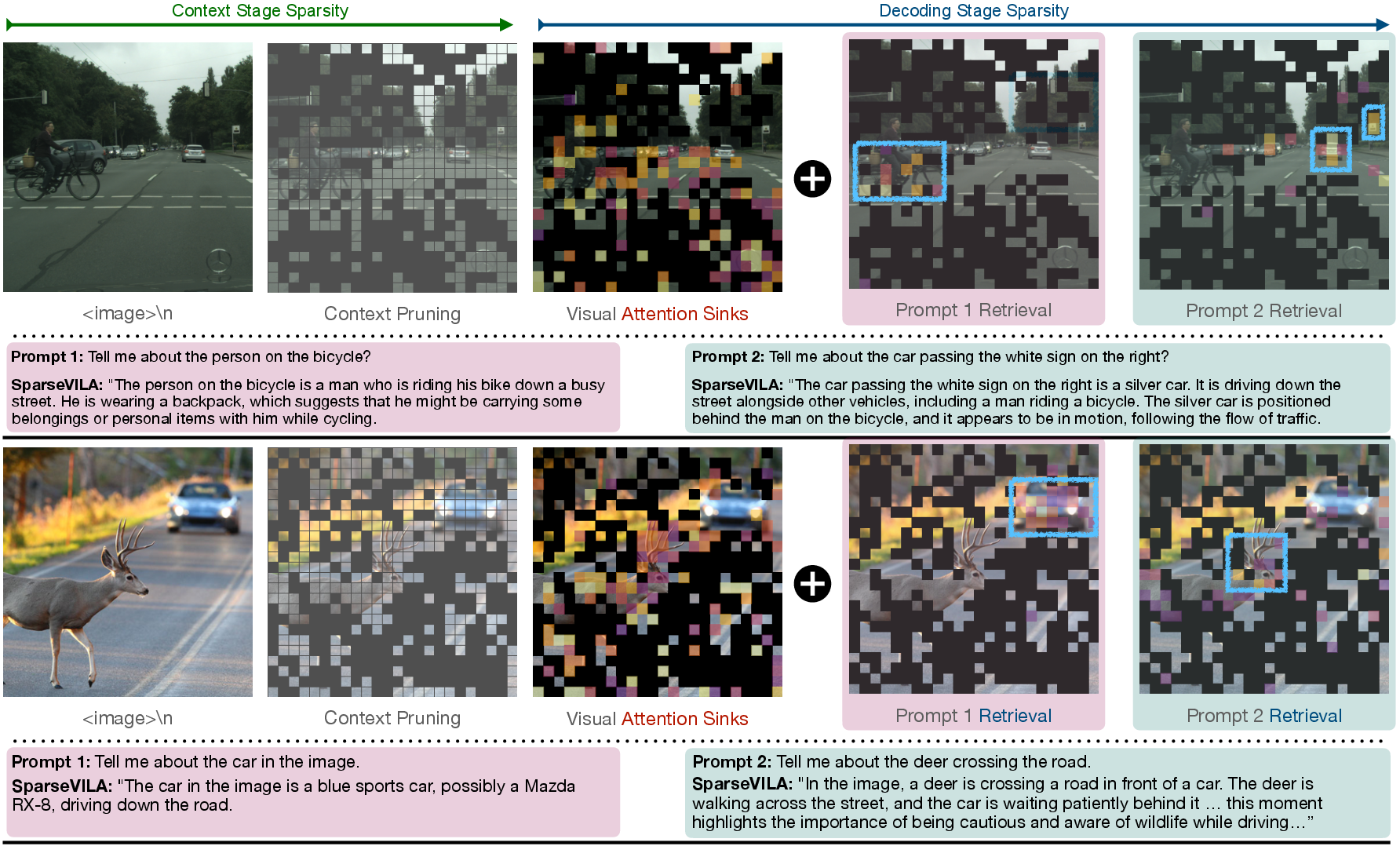
Figure 4: Visualization of token selection frequencies highlights SparseVILA's ability to maintain stable sink tokens while retrieving query-specific tokens efficiently.
Conclusion
SparseVILA establishes a compelling framework for efficient multimodal inference by effectively decoupling visual token sparsity into strategic stages. This training-free, architecture-agnostic framework significantly accelerates large VLMs, promising enhanced scalability without sacrificing model capability across varied applications. SparseVILA's innovative approach presents promising avenues for future research in multimodal AI, particularly in the pursuit of balancing efficiency and fidelity in VLMs.
SparseVILA's foundational insights into sparsity distribution pave the way for advanced applications in AI, setting new benchmarks in the optimization of multimodal systems. As AI systems continue to evolve, frameworks like SparseVILA will be crucial in enabling the real-time, interactive capabilities required by increasingly sophisticated multimodal tasks.