Lavida-O: Elastic Large Masked Diffusion Models for Unified Multimodal Understanding and Generation
Abstract: We propose Lavida-O, a unified Masked Diffusion Model (MDM) for multimodal understanding and generation. Unlike existing multimodal MDMs such as MMaDa and Muddit which only support simple image-level understanding tasks and low-resolution image generation, Lavida-O presents a single framework that enables image-level understanding, object grounding, image editing, and high-resolution (1024px) text-to-image synthesis. Lavida-O incorporates a novel Elastic Mixture-of-Transformers (Elastic-MoT) architecture that couples a lightweight generation branch with a larger understanding branch, supported by token compression, universal text conditioning and stratified sampling for efficient and high-quality generation. Lavida-O further incorporates planning and iterative self-reflection in image generation and editing tasks, seamlessly boosting generation quality with its understanding capabilities. Lavida-O achieves state-of-the-art performance on a wide range of benchmarks including RefCOCO object grounding, GenEval text-to-image generation, and ImgEdit image editing, outperforming existing autoregressive models and continuous diffusion models such as Qwen2.5-VL and FluxKontext-dev, while offering considerable speedup at inference. These advances establish Lavida-O as a new paradigm for scalable multimodal reasoning and generation.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Lavida-O, a single AI model that can both understand images and create or edit them. Think of it as a smart “visual storyteller” that can answer questions about pictures, find objects inside them, make new images from text, and edit existing photos following instructions—all in one system.
What are the main questions the paper explores?
The authors set out to answer a few simple questions:
- Can one model handle many different visual tasks (like image understanding, object finding, image creation, and editing) instead of using separate models?
- Can a newer type of model called a masked diffusion model be fast and high-quality enough to compete with popular “one-token-at-a-time” models?
- How can we make such a model efficient to train and run, while keeping image quality high?
- Can the model use its understanding skills (like planning and checking its own work) to improve the images it creates or edits?
How does Lavida-O work? Key ideas explained simply
Lavida-O is built around a masked diffusion model, plus a clever architecture called Elastic-MoT, and a few practical tricks that make it both fast and good at following instructions.
Masked diffusion in plain words
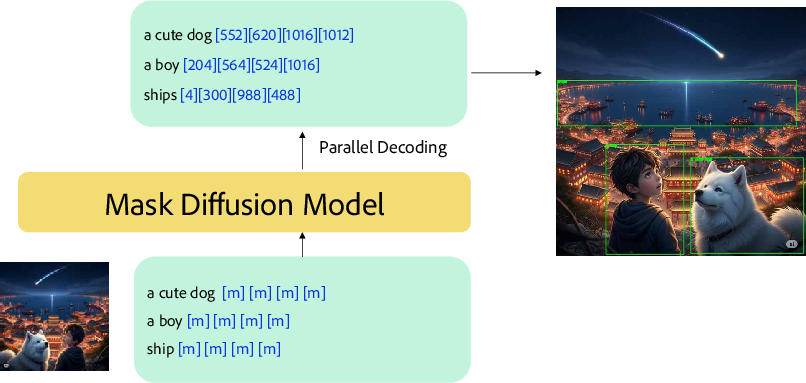
Imagine starting with a blank “grid” where all the pieces are covered by masks (like a scratch-off card). The model gradually uncovers pieces until the full answer appears. Unlike models that write one word or pixel at a time in order, this model can reveal many parts at once, which can be faster.
- For text, those “pieces” are word tokens.
- For images, those “pieces” are tiny image tokens (like small LEGO bricks that form a picture).
A single model for many tasks
Lavida-O takes in:
- The input image’s meaning (a “semantic” summary),
- The image’s fine details (compressed tokens),
- The user's text prompt.
It then predicts the final output: text answers, object boxes, new images, or edited images.
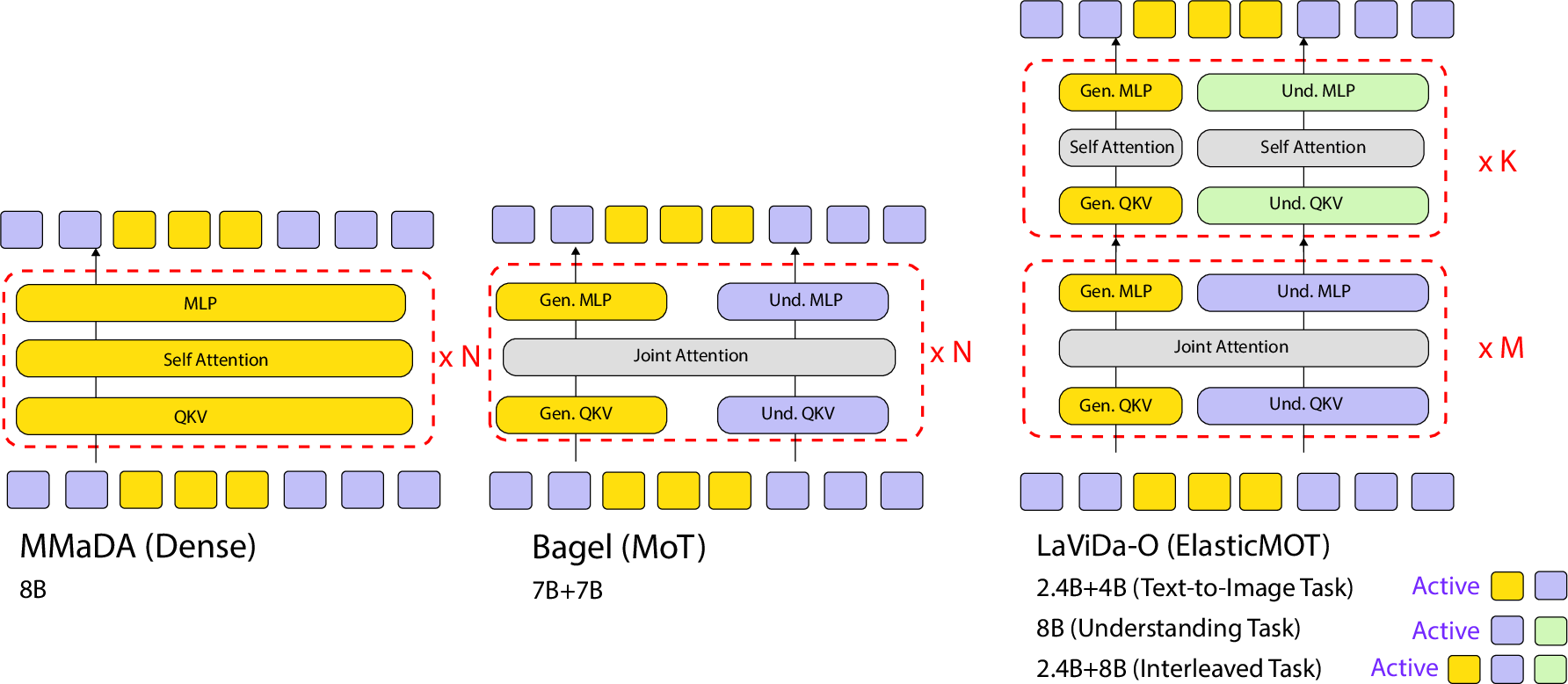
Elastic-MoT: two “brains” that share work
Think of the model as having:
- A big “understanding brain” (for reading and reasoning),
- A smaller “art brain” (for drawing and editing images).
Elastic-MoT connects them cleverly:
- The smaller art brain is cheaper to train but still strong at image creation.
- The two brains talk closely in early layers to share information, then work mostly within their own specialty later. This saves time and power without hurting quality.
Turning images into tokens
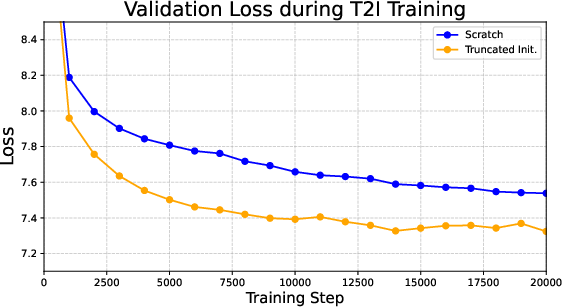
To draw or edit, the model turns images into sequences of small tokens (like tiny tiles in a mosaic). A token compression step reduces how many tiles it needs, so the model runs faster. Training starts at low resolution and gradually moves up to high resolution (256 → 512 → 1024 pixels), like practicing with small canvases before moving to big ones.
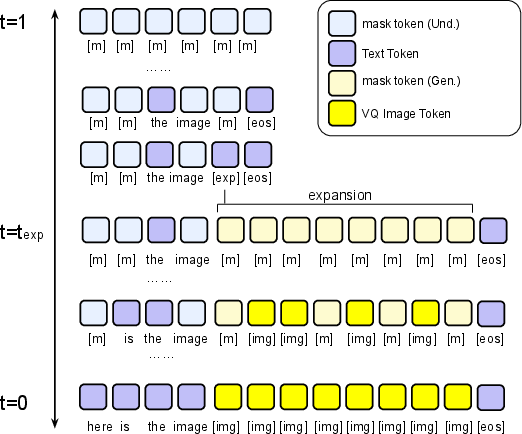
Modality-aware masking: when to “expand” into an image
Because the model decodes in parallel, it needs to know when to switch from text to image. The paper introduces a special “expand” token (think: a placeholder that says “an image goes here”). When this shows up, the model replaces it with the right number of image tokens and continues generating the picture. This makes mixing text and image generation smooth.
Smarter generation tricks
- Universal text conditioning: The model can read extra hints in plain text (like “SCORE: 5.4” or “CONTRAST: high”), guiding it to produce better-looking images—no fancy embeddings needed.
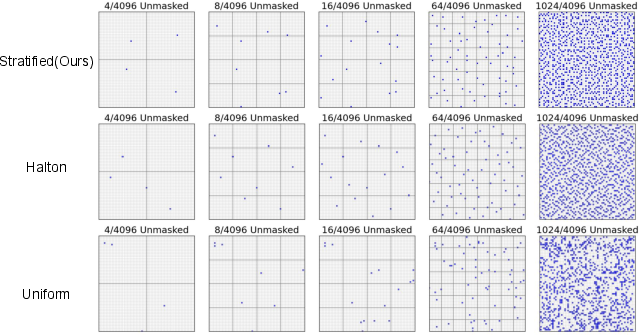
- Stratified sampling: Instead of revealing neighboring image tokens too quickly (which can cause blur or artifacts), the model uncovers tokens spread evenly across the whole image, like coloring one square in each quadrant before filling in details. This leads to more balanced, sharper results.
Planning and self-reflection
Lavida-O uses its understanding skills to improve its creations:
- Planning: It can sketch a layout first (like drawing boxes for “dog here, tree there”) before making the final image. For editing, it first pinpoints exactly where to change.
- Reflection: After making an image, it checks if it matches the prompt. If not, it fixes mistakes in a second pass. This boosts accuracy for tricky prompts.
Fast object grounding with coordinate tokens
To find objects, the model predicts box coordinates directly as fixed tokens (like numbers snapped to a grid from 0 to 1). Because masked diffusion can reveal multiple tokens at once, it can decode many boxes in parallel, which is fast.
What did the researchers find, and why is it important?
Here are the main results, described simply:
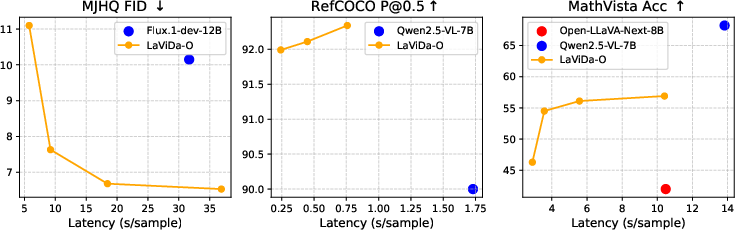
- Stronger image generation: On text-to-image benchmarks, Lavida-O makes high-quality images and follows instructions well. With planning and reflection turned on, its score on GenEval goes up even more. It also achieves a very good FID score (a measure of image realism), better than several well-known models.
- Better image editing: On the Image-Edit benchmark, Lavida-O ranks highly overall, and on some categories (like replacing or removing objects), it even beats GPT-4o. That shows the power of combining understanding and generation in one system.
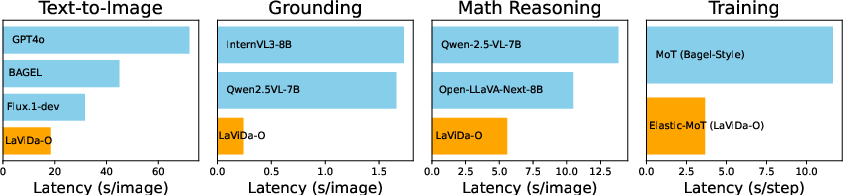
- Accurate object finding: On RefCOCO tasks, Lavida-O’s precision is competitive with leading models and is very fast—up to 6.8× speedup over a popular autoregressive model on grounding.
- Fast and efficient: Thanks to Elastic-MoT and token compression, Lavida-O trains and runs faster. The smaller “art brain” plus partial cross-attention reduce compute without hurting quality.
- Unified and scalable: It handles understanding, object grounding, high-res image synthesis (up to 1024×1024), and instruction-based editing—all in one framework.
Why this matters:
- Combining understanding and creation makes tasks like editing much better, because the model knows both what to change and how to change it.
- Masked diffusion can be a strong alternative to “one-token-at-a-time” models, with speed benefits and better control.
Implications and potential impact
Lavida-O points toward a future where one versatile model can:
- Help users create or fix images with precise instructions—useful for designers, students, and everyday photo editing.
- Understand complex scenes, then plan and generate images that faithfully match complicated prompts.
- Run faster and cheaper, making advanced visual AI more accessible.
Beyond practical uses, the paper also introduces helpful techniques—like Elastic-MoT, modality-aware masking, stratified sampling, and simple text-based conditioning—that other researchers can reuse. Overall, it suggests that unified masked diffusion models are ready to compete with, and sometimes surpass, other leading approaches for multimodal understanding and generation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper; each item suggests concrete directions future work could pursue.
- Elastic-MoT scaling laws: Determine the optimal capacity split between the understanding (8B) and generation (2.4B) branches, and the optimal number of shared vs. decoupled layers (M/K), under fixed compute and data; report full ablations across model sizes, M, and routing depth.
- Cross-branch interference and forgetting: Quantify whether joint Stage-3 training induces degradation in either generation or understanding (catastrophic forgetting), and evaluate mitigation strategies (e.g., selective freezing, L2 regularization, auxiliary losses).
- Routing via modality-aware masking: Characterize how the choice of the collapse timestamp t_exp affects stability, sample quality, and interleaving frequency; provide methods to control the number and placement of [exp] expansions, prevent degenerate repeated expansions, and support multiple images/variable-length expansions within one output.
- Failure analysis for routing: Identify failure cases where [exp] triggers at undesired positions or counts; design decoding-time constraints or priors to enforce user-specified image placement and count.
- Token compression trade-offs: Quantify how 4× VQ token compression impacts texture fidelity, small details (e.g., text, thin structures), and edit faithfulness; compare compression ratios, adaptive compression, and whether conditioning tokens should or should not be compressed.
- VQ tokenizer design choices: Report the tokenizer architecture, codebook size, and training; analyze codebook collapse risks, OOD generalization, and artifacts at 1024 px; compare with alternative discrete tokenizers or hierarchical/semantic tokenizations.
- Stratified sampling ablations: Provide quantitative comparisons to confidence-based and other spatial strategies across step counts; study sensitivity to grid depth, aspect ratios, non-square images, and interactions with guidance/scores; clarify whether stratification should apply to text tokens and how it interacts with [exp] expansions.
- Universal text conditioning robustness: Evaluate how appending micro-conditions as plain text behaves when conditions conflict with user prompts, are adversarially formatted, or omitted; compare to learned embeddings for micro-conditions; measure effects on bias/fairness and on user control fidelity.
- Planning and reflection procedures: Formalize stopping criteria, confidence thresholds, and failure detection for reflection loops; quantify overhead vs. gains; explore RL/self-training to learn when to plan/reflect; analyze failure modes where planning misguides generation or reflection induces regressions.
- Edit category weaknesses: Investigate why categories like Extract and Hybrid lag (per Image-Edit results) and develop targeted data, objectives, or planning strategies to close per-category gaps.
- Grounding beyond boxes: Extend to segmentation masks, points, or phrases-to-mask grounding; compare against segmentation SOTAs and measure pixel-level alignment.
- Box quantization design: Study the impact of 1025-level coordinate quantization on small-object/edge precision; explore non-uniform or learnable quantization and higher-resolution bins; report IoU distributions, not just [email protected], and robustness under occlusion/crowding.
- Parallel decoding scalability: Benchmark latency and accuracy as the number of queried boxes increases; characterize throughput limits and memory growth for many-object grounding or dense layout planning.
- Interleaved generation limits: Specify and test maximum number of images per sequence, long-context behavior, and memory usage; provide mechanisms for user control over image positions in the output stream.
- Resolution and aspect ratio coverage: Evaluate generation/editing beyond 1024×1024, unusual aspect ratios, and very high resolution (tiling or progressive SR); report degradation curves and memory/perf trade-offs.
- Training data transparency: Detail sources, licenses, filtering, synthetic vs. real editing pairs, and distribution balance for understanding vs. generation; measure dataset-induced biases and their effect on outputs.
- Evaluation breadth and human preference: Complement GenEval/DPG/FID with human preference studies, compositional generalization (e.g., CREPE, PartiPrompts), multilingual prompts, and real-image edit fidelity metrics (LPIPS/SSIM/PSNR).
- Fairness of comparisons: Normalize across models for training compute, data volume/quality, and resolution; provide compute budgets and hardware specs; report energy use to support efficiency claims.
- Safety and misuse: Integrate and evaluate content moderation, watermarking, and identity/privacy safeguards; assess whether reflection can detect policy violations, not just prompt misalignment.
- Uncertainty and calibration: Leverage MDM token confidences for calibrated uncertainty in grounding and VQA; develop abstention/verification strategies and measure calibration (ECE/Brier).
- Robustness: Test under low-quality/noisy inputs, heavy occlusion, distribution shift, adversarial prompts, and instruction injection; provide robustness benchmarks and defenses.
- Extendability to video/audio: Analyze how Elastic-MoT and modality-aware masking generalize to temporal/audio tokens; propose schedules, routing, and memory strategies for long sequences.
- One-step vs multi-step decoding: Systematically map speed–quality trade-offs across tasks; explore adaptive step scheduling conditioned on uncertainty or content complexity.
- Structured dependence in MDMs: Address violations of the independence assumption by exploring block diffusion/structured factorization; provide theory and empirical comparisons to the proposed stratified sampling workaround.
- Control signals integration: Add spatial/structural controls (sketch, depth, segmentation, pose, layout) within the unified MDM and study interactions with planning; define a user-facing API for controllable generation/editing.
- Release and reproducibility: Clarify whether code, checkpoints, and training recipes will be released; include ablation scripts and seeds to reproduce key findings.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging Lavida-O’s unified masked diffusion framework, Elastic-MoT architecture, object grounding, high-resolution generation, stratified sampling, and planning/reflection mechanisms.
- Sector: Creative software and media
- Actionable use case: Instruction-based localized image editing in consumer/professional tools (e.g., “remove the glass on the left,” “replace the sky,” “add a logo at top-right”), with automatic region selection via grounding and iterative self-correction via reflection.
- Potential tools/workflows: “Smart Edit” panel that plans edit regions (boxes/masks), executes the edit, evaluates alignment to instructions, and auto-refines; background removal/replacement and compositing assistants; layout-first text-to-image storyboarding at 1024px.
- Assumptions/dependencies: Access to the model via API or SDK; safety filters for content; integration with existing VQ tokenizers and image IO; compute budget (8B+2.4B parameters suggests cloud inference or high-end workstations).
- Sector: E-commerce, marketing, and advertising
- Actionable use case: Automated banner and product imagery generation with controllable micro-conditions (resolution, crop, luminance/contrast) and layout planning for text/logo/Product placements; bulk background cleanup and replacement with brand-safe constraints.
- Potential tools/workflows: “Layout-first generator” that emits bounding boxes for product, text, CTA, then synthesizes; batch pipelines for variation generation and A/B testing; catalog enhancement (color correction, object removal) at scale.
- Assumptions/dependencies: Brand safety and compliance checks (reflection loop plus policy filters); prompt templating; annotated style guides for conditioning; cloud deployment and GPU scheduling for throughput.
- Sector: Document intelligence and analytics
- Actionable use case: ChartQA and DocVQA-driven visual extraction—identify, ground, and read targeted elements (titles, axes, legends, tables), return precise coordinates and values.
- Potential tools/workflows: “Visual RAG” operators that combine grounding with structured extraction; audit-ready overlays showing exact regions used for answers; parallel decoding of multiple fields (quantized coordinates).
- Assumptions/dependencies: High-quality OCR/text pipelines for embedded text; domain prompts; privacy/compliance for document processing.
- Sector: Robotics and edge perception
- Actionable use case: Fast referring expression comprehension (“pick up the red cup near the sink”) with parallel bounding-box decoding; low-latency (1-step/4-step) modes for near real-time interaction.
- Potential tools/workflows: HRI modules that translate natural language into groundable targets; visual servoing pipelines that consume quantized boxes; confidence-aware sampling for robustness.
- Assumptions/dependencies: Calibrated cameras, synchronization with control stack; robustness under motion/blur; safety validation in physical settings.
- Sector: Education and accessibility
- Actionable use case: Generation of instructional visuals with planned layouts (diagrams, step-by-step scenes) and iterative correction; descriptive assistance for images and edits for learners with visual impairments.
- Potential tools/workflows: Teacher co-pilots for classroom materials; visual accessibility aides that ground and explain specific regions; templated diagram generators with micro-conditioning.
- Assumptions/dependencies: Content appropriateness and bias checks; curriculum-aligned prompt libraries; device compatibility (likely cloud-hosted).
- Sector: Software/UI design
- Actionable use case: Layout-first synthesis of UI mockups (bounding boxes for panels/components, then generate textures/icons) and quick localized edits to existing screens.
- Potential tools/workflows: “Layout planner” that outputs component grid, followed by image synthesis; plugin for design suites to refine local elements with grounding; iterative alignment testing via reflection.
- Assumptions/dependencies: Domain datasets (UI components), design-system conditioning; human-in-the-loop review; alignment with accessibility standards.
- Sector: Policy and safety operations
- Actionable use case: Inline compliance checks in generation pipelines—use understanding branch to detect policy violations (nudity, logos, harmful symbolism), trigger reflection/regeneration.
- Potential tools/workflows: “Guarded generation” workflow: generate → assess → if misaligned, correct via reflection loop; audit overlays (grounded regions) for review; controllable micro-conditioning to avoid problematic distributions.
- Assumptions/dependencies: Robust classifiers/policies; escalation paths for ambiguous cases; watermarking and provenance metadata; legal review for editing features (copyright, likeness).
- Sector: Research and academia
- Actionable use case: Benchmarking unified masked diffusion vs AR/diff baselines; studying stratified sampling and modality-aware masking; building datasets for interleaved planning/editing tasks.
- Potential tools/workflows: Open evaluation harnesses for GenEval/RefCOCO/ImgEdit; ablation libraries for token compression and cross-modal attention schedules; reproducible pipelines for progressive upscaling.
- Assumptions/dependencies: Access to training data and compute; reproducible tokenizers; licensing for model weights and datasets.
Long-Term Applications
These applications require further research, scaling, or development (e.g., new tokenizers, datasets, distillation/quantization, safety advances, or broader integration).
- Sector: Video understanding and generation
- Long-term use case: Extend modality-aware masking, stratified sampling, and Elastic-MoT to spatio-temporal VQ tokens for video editing (localized regions over time), text-to-video synthesis, and layout-first storyboarding with temporal plans.
- Dependencies: High-quality video tokenizers, large-scale video datasets with temporal grounding, efficient sampling strategies for temporal grids, robust RL for reflection across sequences.
- Sector: On-device and edge deployment
- Long-term use case: Quantized/distilled Lavida-O variants for laptops, mobile, or embedded devices, enabling local editing and grounding with acceptable latency and power.
- Dependencies: Advanced post-training quantization (4–8 bit) for VLMs, sparse activation, memory optimization for MoT, hardware-aware schedulers; potential smaller generation branches and selective layer activation.
- Sector: Healthcare imaging and scientific annotation
- Long-term use case: Grounded annotation of medical imagery (highlight lesions/structures), layout-guided synthesis for anonymization or augmentation; strict “understanding-only” workflows for clinical decision support.
- Dependencies: Regulated datasets, domain-specific training, clinical validation and certification; hard safety constraints (no generative edits in diagnosis pipelines), bias and explainability guarantees.
- Sector: 3D, AR/VR, and spatial computing
- Long-term use case: Referent grounding in 3D scenes (“place the lamp next to the sofa”), layout-first generation of textures and scene assets, interleaved understanding for alignment with physical constraints.
- Dependencies: 3D tokenization and multi-view consistency, scene graphs and physics-aware prompting, new micro-conditioning for spatial parameters.
- Sector: Enterprise content governance and provenance
- Long-term use case: End-to-end provenance pipelines that combine planning logs, grounded evidence (boxes/masks), and reflection audit trails; unified watermarking and verifiable provenance for generated edits.
- Dependencies: Standards (C2PA-like), robust watermarking for masked diffusion outputs, policy harmonization across jurisdictions, model-level safety finetuning.
- Sector: Multi-agent and RL-enhanced generation
- Long-term use case: Train reflection loops with reinforcement learning to optimize prompt alignment, safety, and user satisfaction; collaborative planners that negotiate layouts before synthesis.
- Dependencies: Reliable reward models for visual alignment and safety, scalable RL infrastructure for large MDMs, human preference datasets.
- Sector: Programmatic synthesis and CAD/industrial design
- Long-term use case: Procedural layout planning (with constraints) followed by high-fidelity synthesis for product imagery, packaging, and surface textures; automatic defect localization via grounding.
- Dependencies: Domain-specific constraints engines, high-resolution texture tokenization, integration with CAD workflows, IP and compliance constraints.
- Sector: Evaluation and standardization of unified MDMs
- Long-term use case: Community benchmarks for interleaved planning/editing and referential grounding at scale; standardized micro-conditioning schemas (text-based) across models.
- Dependencies: Shared datasets and protocols, tooling for stratified sampling comparison, consensus on reporting speed-quality tradeoffs.
Cross-cutting assumptions and dependencies
- Model availability and licensing: Access to Lavida-O weights or comparable implementations; legal clarity for commercial embedding.
- Compute and deployment: Cloud GPUs are likely necessary initially; on-device use depends on quantization/distillation outcomes.
- Data quality and coverage: Robust training mixtures (understanding + generation + editing) and high-quality VQ tokenizers; micro-conditions must be well-calibrated.
- Safety and compliance: Content filters, watermarking, and provenance are critical, especially for editing and high-fidelity generation; reflection loops must be tuned to avoid failure modes.
- Integration complexity: Elastic-MoT requires careful routing and attention scheduling; modality-aware masking must align with product UX (when to “expand” into image tokens).
Glossary
Below is an alphabetical list of advanced domain-specific terms drawn from the paper, each with a short definition and a verbatim usage example from the text.
- AR+diff: A unified modeling setup that uses autoregressive objectives for text and diffusion objectives for images. "Some works, such as BLIP3o and BAGEL, employ AR modeling for text generation and continuous diffusion modeling for image generation (AR+diff)"
- Autoregressive (AR): A modeling paradigm that generates sequences by predicting the next token step-by-step. "Most current unified models are built on Autoregressive (AR) LLMs."
- Bidirectional context: The ability of a model to condition on both left and right contexts when predicting tokens. "MDMs can achieve comparable performance to AR LLMs while offering many advantages, such as better speed-quality tradeoffs, controllability, and bidirectional context."
- Catastrophic forgetting: Degradation of previously learned tasks when training a single model on new tasks without safeguards. "Dense models use the same set of parameters for all tasks, requiring a mix of understanding and generation data during training to prevent catastrophic forgetting, which is not data-efficient."
- Confidence-based sampling: An MDM decoding strategy that unmasks high-confidence tokens first. "Most MDMs use confidence-based sampling, unmasking high-confidence tokens first."
- Continuous diffusion models: Diffusion-based generative models operating in continuous (latent or pixel) spaces. "In contrast, many open-source large-scale continuous diffusion models such as Flux are readily available."
- Elastic Mixture-of-Transformers (Elastic-MoT): A MoT variant with a smaller generation branch and limited cross-modal interaction layers, improving efficiency. "Lavida-O incorporates a novel Elastic Mixture-of-Transformers (Elastic-MoT) architecture that couples a lightweight generation branch with a larger understanding branch, supported by token compression, universal text conditioning and stratified sampling for efficient and high-quality generation."
- Forward diffusion process: In MDMs, the process that progressively masks tokens over time. "the forward process q(X_t|X_s) gradually masks the tokens over the time interval [0,1]"
- Fréchet Inception Distance (FID): A metric assessing generative image quality via feature-distribution distance. "and FID scores on 30k prompts from the MJHQ dataset."
- Independence assumptions: The factorization assumption that token predictions are conditionally independent in the objective. "where p_\theta(X_0|X_t) is factorized into \prod_{i=1}L p_\theta(X_0i|X_t) based on independence assumptions"
- Interleaved generation: Mixed text-image generation within a single sequence or task. "Lavida-O uniquely supports localized understanding, high-resolution image synthesis, image editing and interleaved generation."
- Iterative self-reflection: A loop where the model evaluates and revises its own generations using its understanding abilities. "Lavida-O further incorporates planning and iterative self-reflection in image generation and editing tasks, seamlessly boosting generation quality with its understanding capabilities."
- Joint attention: Attention mechanisms that allow tokens from different modalities/branches to interact. "can interact through joint attention mechanisms."
- Masked Diffusion Models (MDMs): Discrete-token diffusion models that progressively mask/unmask tokens to generate sequences. "Masked Diffusion Models (MDMs) have emerged as a competitive alternative to AR models."
- Masked Generative Modeling (MGM): Generative training by masking parts of sequences and predicting them. "Masked Generative Modeling (MGM) has emerged as an alternative to AR models for modeling sequences of discrete tokens."
- MaskGIT: A masked-token image generation approach that unmask tokens in stages. "Later works such as MaskGIT explored using MGM for generative modeling."
- Micro-conditioning: Adding auxiliary conditions (e.g., resolution, crop) to steer image generation. "A common approach to improving the quality of text-to-image models is micro-conditioning, which conditions the image generation process on extra parameters such as original image resolution, crop coordinates, and image quality scores."
- Mixture-of-Transformers (MoT): An architecture with separate transformer branches (experts) for modalities that can still interact. "A common design in this category is the mixture-of-transformers (MoT) architecture, where image and text inputs are processed by different parameter sets but can interact through joint attention mechanisms."
- Modality-aware masking: A masking scheme that manages routing between text and image branches in MDMs via special tokens/timestamps. "To address this issue, we design a modality-aware masking process."
- Object grounding: Aligning textual references to specific visual objects through localized understanding. "Lavida-O achieves state-of-the-art performance on a wide range of benchmarks including RefCOCO object grounding, GenEval text-to-image generation, and ImgEdit image editing"
- Parallel decoding: Decoding multiple tokens simultaneously rather than sequentially. "unified MDMs offer significantly faster sampling speeds by allowing parallel decoding of multiple tokens."
- Planning: A generation aid where the model first produces a layout or edit plan before synthesizing the final image. "Lavida-O further incorporates planning and iterative self-reflection in image generation and editing tasks"
- [email protected]: A localization metric using an IoU threshold of 0.5 to score correctness. "reporting the [email protected] metric."
- Progressive upscaling: Training by gradually increasing image resolution to stabilize and scale generation. "Lavida-O introduces several techniques such as Elastic Mixture-of-Transformers (Elastic-MoT), progressive upscaling (gradually increasing the image resolution during training), and token compression that enable efficient scaling."
- Referring Expression Comprehension (REC): Tasks that locate objects in images based on natural-language expressions. "We evaluate the object grounding capabilities of Lavida-O on RefCOCO Referring Expression Comprehension (REC) tasks"
- Routing: The mechanism deciding which branch (understanding vs. generation) processes each token in MoT-based MDMs. "One of the challenges in adapting MoT architecture for MDMs is routing—the mechanism to determine which branch should be activated for each token."
- SigLIP: A vision encoder trained with a sigmoid loss for image-text alignment. "LaViDa uses a SigLIP vision encoder to convert input images into continuous semantic embeddings "
- Stratified random sampling: Unmasking tokens across spatial strata to reduce local correlation during generation. "To mitigate this, we introudced a stratified sampling process."
- Token compression: Reducing the number of discrete tokens (e.g., VQ tokens) to improve computation efficiency. "we introduce a token compression module that reduces the number of VQ tokens by a factor of 4."
- Universal text conditioning: Appending conditioning metadata as plain text to prompts to steer generation. "Lavida-O employs stratified sampling and universal text conditioning."
- VQ-Encoder: A vector-quantized encoder that maps images into discrete codebook tokens for generation. "representing target images as sequences of discrete tokens using a VQ-Encoder"
- VQGAN: A vector-quantized GAN used as a discrete tokenizer for images. "discrete tokenizers like VQGAN are used to convert images into discrete tokens."
- Visual Question Answering (VQA): A task where models answer questions about images using vision-language understanding. "Visual Question Answering (VQA) models for question-answering"
Collections
Sign up for free to add this paper to one or more collections.