- The paper presents DIRL, a two-stage reinforcement learning framework that uses demonstration-based initialization and interactive exploration to enhance multi-tool spatial reasoning.
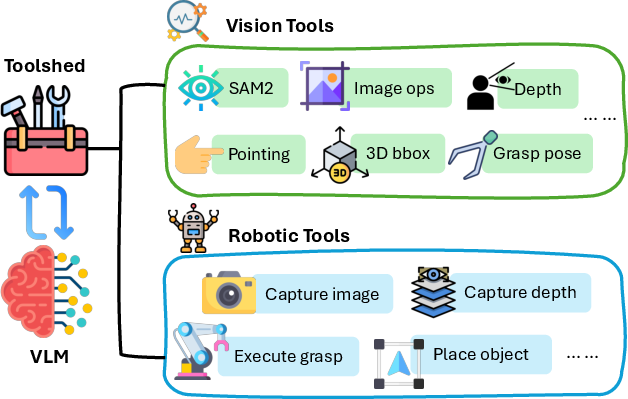
- It integrates the Toolshed infrastructure to asynchronously coordinate diverse vision and robotics tools, achieving state-of-the-art performance on spatial VQA and robotic manipulation benchmarks.
- Empirical results show significant improvements over tool-free and prompt-based methods, with notable gains in metrics such as pose estimation accuracy and robotic task success rates.
Introduction and Motivation
SpaceTools addresses a critical limitation of current vision-LLMs (VLMs): the inability to perform metrically precise spatial reasoning required by embodied systems. While VLMs excel at open-ended visual tasks, they lack the mechanisms for accurate geometric reasoning and multi-tool coordination, restricting their practical application in robotics and spatial question answering. The paper proposes that the agentic paradigm, in which VLMs interact with external perception and action modules (“tools”), can close this gap. However, naive reinforcement learning (RL) and prompting approaches suffer from intractable search spaces or overconstrained, inflexible pipelines when extending to multiple, heterogeneous tools.
The central contribution is Double Interactive Reinforcement Learning (DIRL), a two-stage RL-based framework that enables VLMs to learn grounded, multi-tool reasoning through a mix of demonstration-based initialization and interactive tool-based exploration. The DIRL paradigm is complemented by Toolshed, a scalable distributed infrastructure that provides high-throughput access to a diverse set of compute-intensive vision and robotic tools.
Double Interactive Reinforcement Learning (DIRL)
SpaceTools is grounded in a sequential decision process where a VLM policy πθ interactively queries external tools to iteratively solve spatial reasoning and robotic manipulation tasks. DIRL proceeds in two stages:
Teaching Phase: The foundation model is first supervised using a dataset comprising:
- Traces from a VLM teacher trained via IRL on a single tool, such as pointing (where RL reliably converges in a tractable action space).
- High-reward demonstrations from a universal teacher (e.g., a proprietary VLM with access to all tools via Toolshed) covering richer tool combinations.
This mixture teaches method signatures, tool invocation syntax, and basic tool-use strategies.
Exploration Phase: The model is then further trained using RL, now with access to the full tool set. The model refines its policy through interactive rollouts, learning to sequence and compose multiple tools, reasoning about reliability, chaining, and recovery from failures, guided by task-specific reward functions. Policy optimization leverages Group Relative Policy Optimization (GRPO) with KL regularization.
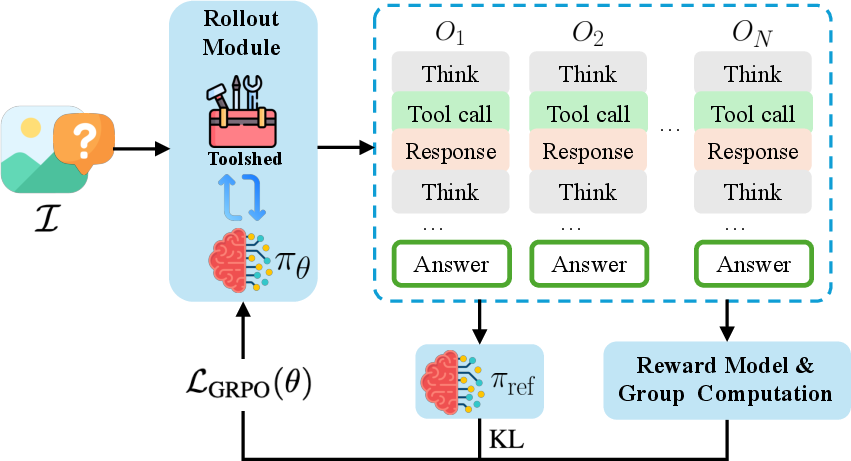
Figure 1: Interactive reinforcement learning (IRL) with Toolshed, composing reasoning and tool calls to maximize task reward.
This approach prevents the exploration collapse typical of end-to-end RL over large, combinatorial tool spaces.
Conventional synchronous tool invocation or reliance on precomputed tool outputs is inadequate for scalable RL with vision/robotic modules. Toolshed decouples tool execution from model inference, providing:
Toolshed is integrated with the VERL RL framework, facilitating batched, multi-turn, interactive rollouts where real tool outputs can impact the model’s reasoning.
The base model is Qwen2.5-VL-3B-Instruct. Tool interfaces include:
- Vision: segmentation (SAM2), pointing (RoboRefer, Molmo), depth estimation (DepthPro), 3D bounding box/pose estimation, grasp synthesis, geometric cropping.
- Robotics: image/depth capture, closed-loop grasp and place execution.
Task Suite and Evaluation Protocol
Experiments span spatial VQA, pose estimation, grasp affordance prediction, vacant-space localization, and real-world robotic manipulation. Evaluation is conducted on: RoboSpatial-Home, BLINK, RefSpatial, CVBench, BOP-ASK, and an augmented HOPE dataset for manipulation.
Metrics include normalized accuracy, mean IoU for pose estimation, and Mean Angular Coordinate Error (MACE) for grasping. The robot manipulation suite tests end-to-end input-image-to-action capabilities.
Empirical Results
State-of-the-art Spatial Reasoning
SpaceTools achieves dominant results across all evaluated spatial VQA, depth, and manipulation benchmarks. It outperforms all proprietary, open-source, and spatially-specialized baselines (including tool-augmented SFT or RL variants), e.g.:
- RoboSpatial overall: 70.00%
- Pose estimation (BOP-ASK): 34.37%
- Grasp MACE: 43.06%
Relative to tool-free SFT and RL, DIRL provides +12% and +16% absolute improvements on RoboSpatial, underscoring the necessity of interactive, reward-driven tool chaining. Compared to the strongest open/proprietary models, DIRL’s coherent tool-use yields consistent improvement, especially for tasks requiring chaining (pose, grasp, vacant region queries).

Figure 3: SpaceTools solving diverse spatial reasoning tasks by interleaving tool calls and internal reasoning steps.
Qualitative analysis shows the model dynamically modulates its tool selection/ordering, recovers from tool outputs, and restructures reasoning trajectories on-the-fly—behaviors inaccessible to approaches based on handcrafted or fixed pipelines.
Real-World Robotic Manipulation
In end-to-end embodied tasks, SpaceTools achieves 86% average success across pick, relational pick, and pick-place tasks—substantially outperforming both proprietary models and strong open-source VLMs, even when the latter are given tool access via Toolshed. Unlike tool-free or prompt-based baselines, SpaceTools chains perception and action modules coherently for physical manipulation.
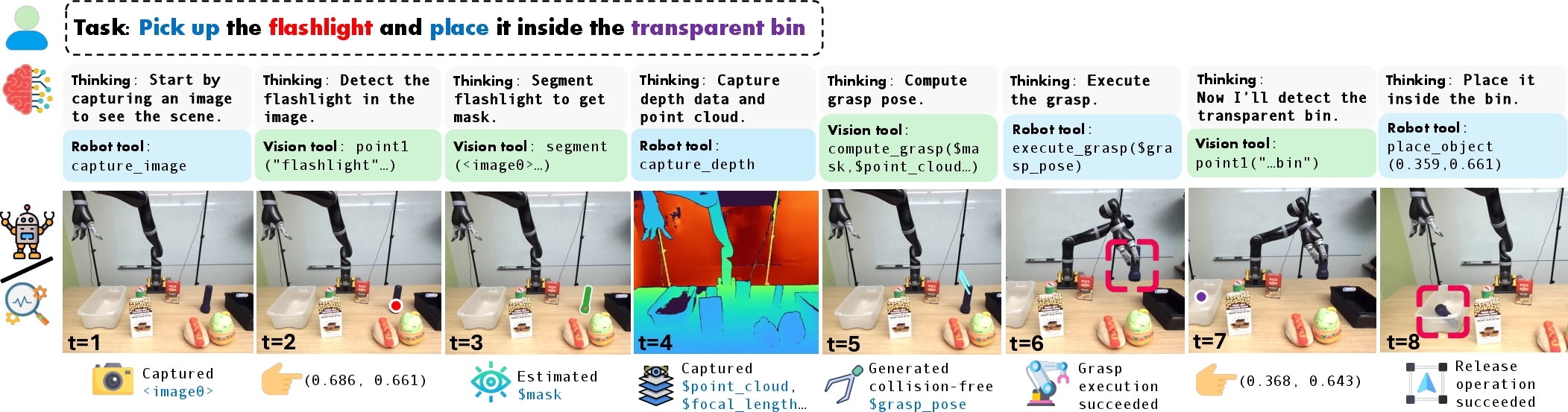
Figure 4: SpaceTools controlling a real robot to complete a pick-and-place task via alternated vision and action tool calls.
Ablations and Failure Modes
Removing either teacher (IRL or universal demonstration), or the second-stage IRL, results in sharp accuracy drops, reaffirming the critical role of both instructional priors and reward-based exploration in training.
Direct RL with all tools from scratch (without pretraining) fails to optimize, with less than 20% mean accuracy. Non-interactive RL and SFT-trained tool-using models also lag by >13% mean accuracy compared to full DIRL.
DIRL is robust but not infallible. Failure cases include erroneous grasp detection and boundary-adjacent placements in real-world scenes, revealing the limitations in tool-level precision and physical feasibility reasoning.
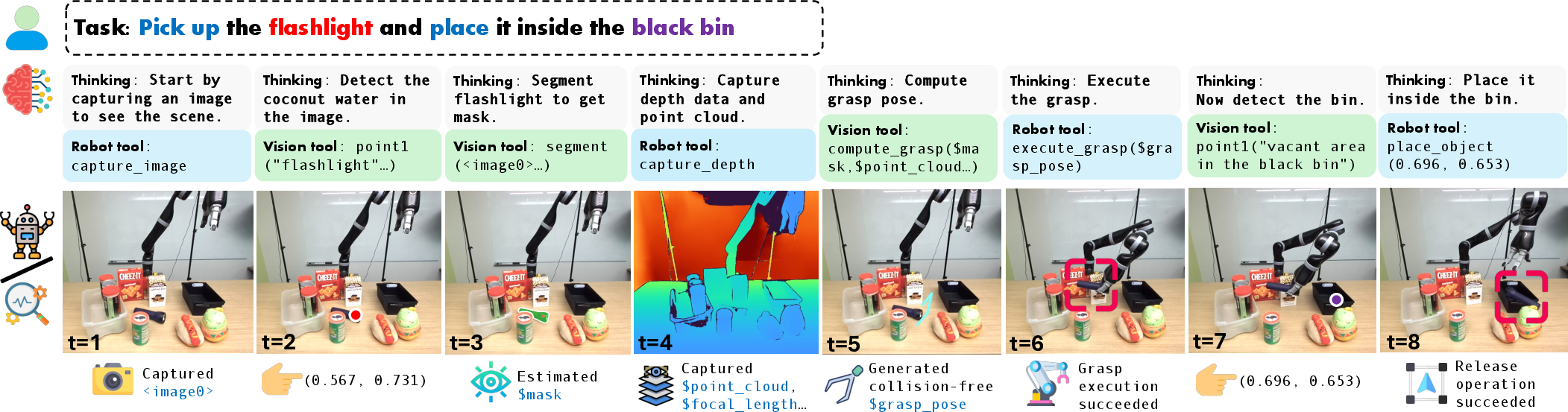
Figure 5: Failure case: a valid vacant area is identified but the placement point is too close to the boundary, resulting in task failure.
Discussion and Broader Implications
DIRL demonstrates that strong spatial reasoning and embodied control emerge not from pretraining on massive annotated datasets or hardcoded pipelines, but from interactive learning with real, heterogeneous tool outputs. The agent learns to reason about errors, ambiguities, and the semantics of external modules, yielding flexible plans adaptive to unforeseen context.
From a systems perspective, Toolshed’s decoupled design is crucial to scale RL with heavy, batched, multimodal tools. DIRL unlocks safe, efficient online exploration—critical for bringing agentic multimodal models into physical settings.
Practically, DIRL/SpaceTools enables new paradigms in embodied AI, where core models need not internalize fine-grained metric representations; these can be out-sourced to specialized modules, with the agent learning when and how to query them in context. This modular view facilitates transfer and continual improvement: e.g., tool upgrades or augmentations can improve capabilities without retraining the VLM.
Theoretical implications point to the separation of high-level, multi-step reasoning from low-level perception and control. The policy learns to rapidly traverse the action-observation hierarchy and dynamically coordinate task-specific “programs” using tool APIs.
Future Directions
Limitations include:
- Scaling DIRL to longer-horizon, closed-loop tasks (e.g., multi-stage assembly) where error propagation and global planning become more prominent.
- Perceptual robustness in extensive real-world scenarios remains a bottleneck, particularly for grasp and pose under heavy occlusion.
- The infrastructure's asynchronous parallelism could become limited by tool latency or system bottlenecks as tool coverage expands.
Extensions of this work could include RL refinement with live robot feedback, integrated learning of tool-selection heuristics, and leveraging tool intent-retrieval for explainability and verification.
Conclusion
SpaceTools, trained with DIRL and enabled by Toolshed, defines the new state-of-the-art for tool-augmented spatial reasoning and robotic manipulation in VLMs (2512.04069). The results show that scalable interactive RL with compositional tool use yields models that outperform all prior approaches in both visual geometric reasoning and real-world robotic control, while remaining broadly extensible and modular. This framework delineates a practical route for unifying vision, language, and action through learned, agentic tool-use policies.