WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Abstract: This paper presents WorldPlay, a streaming video diffusion model that enables real-time, interactive world modeling with long-term geometric consistency, resolving the trade-off between speed and memory that limits current methods. WorldPlay draws power from three key innovations. 1) We use a Dual Action Representation to enable robust action control in response to the user's keyboard and mouse inputs. 2) To enforce long-term consistency, our Reconstituted Context Memory dynamically rebuilds context from past frames and uses temporal reframing to keep geometrically important but long-past frames accessible, effectively alleviating memory attenuation. 3) We also propose Context Forcing, a novel distillation method designed for memory-aware model. Aligning memory context between the teacher and student preserves the student's capacity to use long-range information, enabling real-time speeds while preventing error drift. Taken together, WorldPlay generates long-horizon streaming 720p video at 24 FPS with superior consistency, comparing favorably with existing techniques and showing strong generalization across diverse scenes. Project page and online demo can be found: https://3d-models.hunyuan.tencent.com/world/ and https://3d.hunyuan.tencent.com/sceneTo3D.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces WorldPlay, an AI system that can “play” and build virtual worlds in real time, like a smart game engine. As you move around using your keyboard and mouse, it instantly generates the next part of the video so you can explore. The big promise is that the world stays consistent: if you walk away and then come back, things look the same as before, even over long periods.
What questions does the paper try to answer?
The researchers focus on a tricky problem:
- How can an AI make fast, real-time videos while also remembering the world well enough that places don’t randomly change when you revisit them?
They also ask:
- How should the AI understand your actions (like keys and mouse) so it moves correctly?
- How can the AI use memories from past frames without slowing down or getting confused over time?
How does WorldPlay work?
To explain the approach, it helps to think of the AI like a skilled animator who draws a movie frame by frame, reacting to your controls.
Step-by-step video drawing (chunks)
Instead of making the whole video at once, WorldPlay creates it in small parts called “chunks” (16 frames at a time). This “autoregessive” approach means each new chunk is based on what it already drew plus your latest actions. Think of it like a comic artist drawing a few panels, then using those to decide how to draw the next few.
Dual Action Representation (understanding your controls)
WorldPlay reads your actions in two ways at the same time:
- Discrete keys: the typical W/A/S/D or arrow keys. These help with general movement like walking forward or turning.
- Continuous camera pose: the exact position and direction of the “camera” in the scene. This is like knowing exactly where you are and what you’re looking at.
Using both together gives precise control (so movement looks right) and accurate memory (so the AI knows exactly where you’ve been and can keep places consistent).
Rebuilt memory that stays useful over time
The AI needs to remember important past moments to keep the world stable. Instead of storing everything, it rebuilds a smart set of “memories” for each new chunk:
- Temporal memory: the most recent frames to keep motion smooth.
- Spatial memory: older frames that are important for keeping the shape of the world steady (like a landmark you saw a while ago).
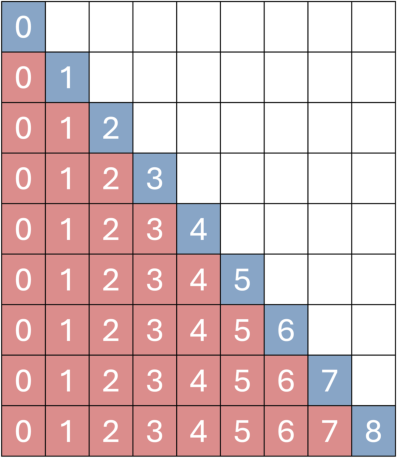
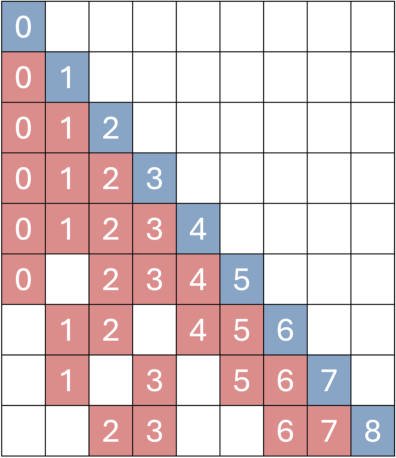
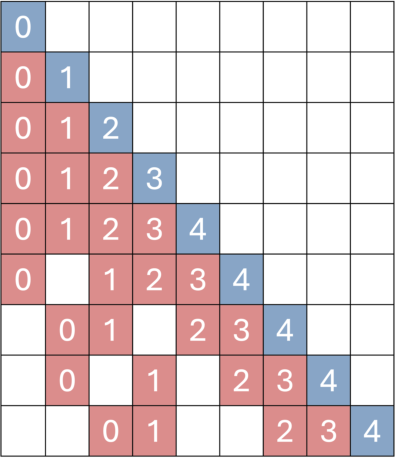
A key trick is “temporal reframing.” Imagine you have sticky notes on a long timeline. If a very old note is still important (say, it shows the exact look of a building), the AI “moves” it closer on the timeline so it still has a strong influence. In technical terms, it adjusts the “position labels” of past frames so the AI treats them as if they happened more recently. This keeps long-term scenes consistent and prevents the world from “drifting” or warping.
Context Forcing (learning to be fast without forgetting)
To make the system fast, the team uses a teacher–student training setup (called distillation):
- A “teacher” model is accurate but slow.
- A “student” model is fast but needs to learn to be accurate.
WorldPlay adds a new idea: the teacher and student must use the same kind of memory when learning. If they look at different context or history, the student learns the wrong habits. By “forcing” both to share the same memory setup, the student learns to use long-range information correctly and stays consistent, even with only a few fast steps per chunk.
Engineering for real-time speed
They also use practical speed-ups so the experience feels instant:
- Parallel processing across devices so chunks are computed efficiently.
- Streaming and progressive decoding so frames appear while later ones are still being processed.
- Efficient attention and caching: the AI “remembers” previous calculations to avoid repeating work.
Main findings and why they matter
- WorldPlay runs in real time at 24 frames per second and 720p resolution, which feels smooth and responsive.
- It keeps scenes geometrically consistent over long sessions. If you revisit a place, it looks the same, reducing weird glitches or “teleporting” objects.
- It works across many settings: realistic worlds, stylized worlds, first-person (you are the camera), and third-person (you control a character).
- It can help build 3D scenes from the generated video, and supports text-triggered events (like “make it rain now”) while you explore.
- In tests, it produced clearer, steadier videos than other methods, especially over long periods, and handled user control well without breaking consistency.
This matters because most previous systems trade off speed for memory (fast but forgetful) or memory for speed (consistent but too slow). WorldPlay shows you can have both.
Implications and potential impact
WorldPlay could improve several areas:
- Games: more believable worlds that don’t glitch when you revisit places, with fast response to player controls.
- Robotics and self-driving simulation: reliable virtual environments where consistency is crucial for learning.
- Virtual tours and filmmaking: smooth, stable scenes that hold their shape even during long shots.
- 3D content creation: easier reconstruction of high-quality 3D scenes from generated video.
- Interactive storytelling: on-the-fly events triggered by text (like weather changes or character actions).
Overall, WorldPlay is a step toward AI systems that can build and maintain complex, interactive worlds in real time, without losing track of where things are or how they should look—even when you explore for a long time.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to guide actionable follow-up research.
- Memory reconstruction algorithm is underspecified: the exact formula, weighting, and thresholds for the geometric relevance score (FOV overlap, camera distance), the size L of temporal memory, tie-breaking rules, and per-layer/context injection strategy are not provided; systematic ablations of these choices are absent.
- Temporal reframing lacks formal analysis: there is no theoretical characterization of how re-indexing positional encodings alters attention distances, stability, and interpolation/extrapolation regimes in Transformers, nor an assessment of its impact on motion chronology, causality, and event ordering.
- Long-horizon limits are unquantified: consistency is only evaluated up to ≥250 frames; there is no study beyond minutes-long sequences (e.g., >10 minutes, >10k–15k frames) of drift, accumulated error, or loop-closure metrics during repeated revisits.
- Compute–memory–latency trade-offs are not measured: the effect of the number/size of memory tokens, spatial vs temporal memory ratios, and reframing frequency on FPS, end-to-end latency, and consistency is not quantified; memory footprint and token counts per chunk are not reported.
- Action-to-pose conversion is unclear: how discrete keyboard/mouse inputs are mapped to continuous camera poses at inference (step sizes, rotation magnitudes, per-scene scale calibration) is not specified; robustness to device heterogeneity (gamepads, touch, VR controllers) is unexplored.
- PRoPE dependence on camera intrinsics/extrinsics is a potential failure mode: inference-time availability or estimation of intrinsics/extrinsics is not described; sensitivity to miscalibration, rolling shutter, and consumer video metadata errors is not evaluated.
- Dynamic scenes are insufficiently addressed: the memory selection (FOV/distance) does not incorporate explicit dynamics/visibility reasoning; performance in scenes with moving or nonrigid objects, crowds, occlusions, and rapid appearance changes is not quantified (e.g., identity persistence across occlusions).
- Physical plausibility is not measured: no benchmarks or metrics assess compliance with physics (e.g., gravity, collisions, momentum conservation, realistic kinematics); the model’s suitability for embodied control or robotics tasks remains uncertain.
- Exposure bias and error accumulation are not deeply analyzed: beyond context forcing, there is no quantitative breakdown of failure modes over long rollouts (e.g., texture drift, scale creep, pose bias) or sensitivity to stochastic user action sequences.
- Teacher design in distillation is under-detailed: how the bidirectional teacher with memory is trained, how masking avoids information leakage, and how teacher–student conditional distributions are verified to align is unclear; comparisons against alternative few-step objectives (e.g., VSD, adversarial distillation) under matched memory contexts are missing.
- Evaluation metric coverage is limited: PSNR/SSIM/LPIPS incompletely capture geometric consistency; loop-closure error, revisit similarity, and camera pose consistency vs ground-truth trajectories are not reported; per-object/geometric identity consistency metrics are absent.
- Baseline comparability and fairness need strengthening: baselines differ in resolution and real-time capability; standardized 720p evaluations, consistent trajectories, and reporting of end-to-end latency (time-to-first-frame, jitter, dropped frames) are not provided.
- 3D reconstruction application is anecdotal: there is no quantitative evaluation of reconstructions (e.g., Chamfer distance, point density, scale accuracy) against ground-truth geometry; failure analysis on reflective/translucent surfaces, thin structures, or textureless regions is missing.
- Promptable event control lacks safety/robustness analysis: the system’s handling of conflicting inputs (text vs navigation), event persistence and reversibility, state management, and safeguards against harmful or destabilizing prompts are not evaluated.
- Generalization claims are not broken down: performance across real vs synthetic vs stylized domains, per-scene scale diversity, and out-of-distribution (handheld, low-light, noisy) videos is not reported; dataset biases and domain mix effects are not analyzed.
- Hardware scalability is unclear: results rely on 8×H800 GPUs; throughput/FPS on single or mid-tier GPUs, memory usage, and quality–latency trade-offs under quantization/compression are not benchmarked.
- Chunking and denoising hyperparameters are not studied: the impact of chunk length (e.g., 8/16/32 frames) and number of denoising steps (e.g., 2–8) on latency, consistency, and failure rates is not explored; guidelines for selecting optimal settings are absent.
- Retrieval granularity is fixed at chunk-level: trade-offs vs frame- or latent-level retrieval, hybrid strategies, and learned retrieval policies (e.g., RL/attention-based selection) are not evaluated; sensitivity to misalignment between chunk boundaries and scene events is unknown.
- Occlusion- and visibility-aware memory is missing: retrieval does not explicitly model visibility, parallax, or occlusion; integrating visibility estimators or lightweight geometry priors and quantifying their benefits is an open direction.
- Multimodal/agent extensions are unexplored: there is no audio support, text–video temporal alignment analysis, or integration with agent policies (e.g., planning, multi-agent coordination); benchmarks for interactive tasks requiring perception–action reasoning are absent.
- Robustness to adversarial or atypical user actions is not evaluated: worst-case inputs (rapid spinning, zigzagging, frequent prompt injections) and recovery behaviors (graceful degradation, state reset) are untested.
- Reproducibility is limited: critical components (streaming deployment stack, quantization recipes, Sage Attention, dataset curation/labeling pipelines) and code are not released; precise implementation details needed to replicate results are missing.
Practical Applications
Immediate Applications
The following use cases can leverage WorldPlay’s current capabilities (real-time 720p streaming at 24 FPS, dual action control, long-term geometric consistency, promptable events, and integration with 3D reconstruction).
- Generative game prototyping (software/gaming)
- Description: Rapidly prototype playable levels and exploration loops from a single image or text prompt; iterate on camera and agent behaviors with consistent revisits for layout validation.
- Tools/products/workflows: WorldPlay SDK for Unity/Unreal; in-editor “Generative World” panel; consistency-aware navigation testing harness.
- Assumptions/dependencies: Cloud GPUs (e.g., 8×H800) or access to high-end local hardware; physics and gameplay logic remain external; asset/IP compliance.
- Virtual previsualization for film/TV (media/entertainment)
- Description: Real-time camera blocking and shot planning in coherent virtual scenes; revisit the same positions reliably for continuity checks and multi-shot compositions.
- Tools/products/workflows: WorldPlay Previz plug-in for NLE/VFX pipelines; camera path library using dual action representation; streaming service via NVIDIA Triton.
- Assumptions/dependencies: Integration with editorial/VFX tools; geometric consistency is high but not metrically guaranteed; production security and data governance.
- Interactive virtual tours and staging (real estate/e-commerce)
- Description: Create navigable property or showroom tours from photos/prompts; trigger text-based events (e.g., “replace sofa,” “change wall color”) with consistent revisit points.
- Tools/products/workflows: Web-based “WorldPlay Tour Builder”; furniture and layout catalog integration; promptable event scripts.
- Assumptions/dependencies: Disclosure of generative content vs. actual layouts; calibration or reference imagery improves fidelity; legal/regulatory compliance for representations.
- 3D reconstruction booster (software/3D content creation)
- Description: Generate long-term consistent view streams to feed 3D reconstruction (e.g., 3D Gaussian Splatting, point clouds), improving coverage and revisit trajectories.
- Tools/products/workflows: “WorldPlay-to-3D” pipeline; auto-trajectory planner with temporal reframing; handoff to downstream reconstruction (e.g., WorldMirror).
- Assumptions/dependencies: Camera intrinsics/extrinsics calibration for best results; reconstruction accuracy depends on downstream methods; domain-specific tuning.
- Perception data generation for robotics (robotics/ML)
- Description: Produce synthetic, consistent navigation sequences to pretrain visual models (e.g., SLAM, place recognition, long-horizon memory) and evaluate long-term consistency.
- Tools/products/workflows: Dataset generator with cycle-revisit trajectories; labelers for action/state; consistency metrics suite (PSNR/SSIM/LPIPS + pose errors).
- Assumptions/dependencies: Limited physical dynamics and contact realism; sim-to-real gap requires domain adaptation; do not rely on these sequences for physics-based policy training.
- Educational virtual labs and field trips (education)
- Description: Teacher/students explore safe virtual worlds with reliable revisits; trigger demonstrations via text prompts (e.g., “day-to-night,” “show rainfall”).
- Tools/products/workflows: Classroom-friendly WorldPlay app; curated prompt packs; assessment aligned to revisit checkpoints.
- Assumptions/dependencies: Content curation for age/safety; school infrastructure for GPU-backed streaming; accessibility features may need additional development.
- UX/HCI research with controlled visual stimuli (academia/industry)
- Description: Create reproducible, long-horizon visual sequences to study navigation, memory, and attention; reliably revisit scenes for within-subject comparisons.
- Tools/products/workflows: Experiment design tool with fixed camera paths; event injection via text; logging of action/control and frame metadata.
- Assumptions/dependencies: IRB/ethical approvals for human studies; stimulus validity depends on task; careful control of generative artifacts.
- VR/AR prototyping of environments (software/immersive tech)
- Description: Assemble stable scene prototypes to test camera/agent motion, user comfort, and UX behaviors before investing in hand-authored assets.
- Tools/products/workflows: WorldPlay XR bridge; temporal reframing presets for long-horizon UX; progressive decoding for low-latency previews.
- Assumptions/dependencies: Engine integration (Unity/Unreal/OpenXR); performance tuning for headset targets; motion sickness safeguards.
- Interactive marketing/product showcases (media/e-commerce)
- Description: Launch navigable product experiences with text-triggered events (e.g., “open door,” “swap colorway”) and consistent revisit viewpoints for A/B testing.
- Tools/products/workflows: Web SDK; prompt library for common actions; analytics on revisit and interaction paths.
- Assumptions/dependencies: Brand safety and IP vetting; disclosure of generative vs. real footage; content moderation.
- Developer APIs and streaming services (software/platform)
- Description: Offer a managed WorldPlay microservice (Triton-based) with mixed parallelism, quantization, and KV caching to embed real-time interactive worlds in apps.
- Tools/products/workflows: REST/SDK interfaces; scaling policies; cost monitoring; progressive VAE decoding.
- Assumptions/dependencies: GPU availability and cost; latency SLAs; observability for memory-context operations.
- Consistency evaluation benchmark for video models (academia)
- Description: Standardize long-horizon revisit trajectories and metrics to compare model memory, drift, and robustness over 250+ frames.
- Tools/products/workflows: Benchmark suite with cycle paths; open metrics scripts; teacher–student distillation baselines (context forcing).
- Assumptions/dependencies: Public datasets and licenses; reproducibility across hardware; fair comparison configurations.
- Third-person agent control demos (gaming/robotics)
- Description: Showcase third-person navigation and camera–agent control in stylized/real scenes using dual action representation for reliable path revisits.
- Tools/products/workflows: Agent controller mapping (keyboard/mouse + camera pose); demo scenes; input logging and replay.
- Assumptions/dependencies: No full physics or gameplay systems; requires UI/UX scaffolding for player control; tuning for different genres.
Long-Term Applications
These use cases require further research, scaling, physics, multi-agent reasoning, or ecosystem integration before deployment.
- Autonomous driving and ADAS simulation (automotive/transport)
- Description: Long-horizon, consistent urban scenes for perception and planning; multi-agent traffic with realistic dynamics and sensor models.
- Tools/products/workflows: WorldPlay + physics engine + traffic simulators; sensor emulation (LiDAR/RADAR/camera); curriculum generation via text prompts.
- Assumptions/dependencies: High-fidelity physics and regulatory compliance; accurate GIS maps; extensive validation against real-world telemetry.
- Embodied robotics training and sim-to-real (robotics)
- Description: Persistent memory worlds for multi-step tasks, mapping, and object permanence; integrate accurate contact, dynamics, and manipulation.
- Tools/products/workflows: Hybrid simulator (WorldPlay visuals + physics + task graphs); multi-agent coordination; domain randomization and adaptation.
- Assumptions/dependencies: Physics correctness; calibrated photorealism; safety and certification for downstream deployment.
- Urban planning and participatory policy simulation (public policy/civic tech)
- Description: Visualize design choices (e.g., bike lanes, zoning changes) in coherent virtual neighborhoods; gather public feedback with consistent revisit paths.
- Tools/products/workflows: GIS integration; scenario authoring via text; stakeholder engagement platforms with telemetry and analytics.
- Assumptions/dependencies: Accurate geospatial data; socio-environmental models; transparency and ethics for public use.
- Clinical VR therapeutics (healthcare/mental health)
- Description: Exposure therapy and cognitive rehabilitation in controlled, revisitable environments; therapist-triggered prompts for graded challenges.
- Tools/products/workflows: HIPAA-compliant VR platform; session scripting; physiological monitoring and outcome measures.
- Assumptions/dependencies: Clinical trials and regulatory approval; content safety; individualized protocols and accessibility standards.
- Disaster response and safety training (public safety/defense)
- Description: Simulate rare, hazardous events (e.g., fires, floods) with text-triggered dynamics and stable scene memory for repeated drills.
- Tools/products/workflows: Hazard model integration; role-based scenarios; performance analytics over long sequences.
- Assumptions/dependencies: Validated hazard physics; scenario realism; governance for sensitive content.
- Industrial digital twins and operator training (energy/utilities/manufacturing)
- Description: Persistent virtual facilities for operations training; scenario injection (equipment failure, load changes) with reliable revisits.
- Tools/products/workflows: SCADA/IIoT integration; event scripts; performance dashboards; compliance audits.
- Assumptions/dependencies: Accurate plant models and physics; cybersecurity; regulatory standards.
- Assistive navigation training for visually impaired users (healthcare/accessibility)
- Description: Safe, consistent environments for orientation and mobility practice with repeatable paths and obstacle events.
- Tools/products/workflows: Accessibility-first UX; haptic/audio feedback integration; individualized progression plans.
- Assumptions/dependencies: Clinical collaboration; user studies for efficacy/safety; accessible hardware/software.
- Multi-user collaborative worlds (software/collaboration)
- Description: Real-time co-presence in consistent generative environments for design reviews, education, and entertainment.
- Tools/products/workflows: Networking and state synchronization; conflict resolution for shared memory context; role-based permissions.
- Assumptions/dependencies: Scalable backend; multi-agent consistency; moderation and safety policies.
- Persistent mixed-reality overlays (AR/mapping)
- Description: Stable world memory to anchor virtual content to real spaces across sessions; revisitable overlays for maintenance and guidance.
- Tools/products/workflows: Spatial anchors and calibration; cross-session memory caching; device-level SLAM integration.
- Assumptions/dependencies: Robust alignment with real geometry; privacy and security; device compatibility.
- Edge/mobile deployment of interactive world modeling (software/hardware)
- Description: Bring generative worlds to consumer devices via aggressive compression, quantization, and distillation; lower-resolution real-time experiences.
- Tools/products/workflows: Mobile-optimized student models; hardware-aware attention kernels; adaptive streaming strategies.
- Assumptions/dependencies: Significant model pruning and optimization; quality–latency trade-offs; battery and thermal constraints.
- Regulatory sandboxing for AI behavior and policy testing (policy/AI governance)
- Description: Use consistent generative environments to evaluate long-horizon model behavior, memory, and safety interventions before real-world release.
- Tools/products/workflows: Sandboxed testbeds; standardized long-horizon metrics; intervention and logging instrumentation.
- Assumptions/dependencies: Agreement on benchmarks; transparency, auditability; ethics and legal review.
Notes on Core Assumptions and Dependencies Across Applications
- Compute and deployment: The cited 24 FPS at 720p requires substantial GPU capacity (e.g., 8×H800) and optimized streaming (Triton, mixed parallelism, quantization, KV caching). Cloud or on-prem GPU access and cost controls are practical dependencies.
- Geometric fidelity: WorldPlay’s consistency is strong for revisits, but metric accuracy is not guaranteed without calibration; applications requiring precise measurements need additional sensors/data or constraints.
- Physics and dynamics: The model focuses on visual consistency; physical correctness (contacts, forces, multi-agent dynamics) must be provided by external engines/simulators for many long-term applications.
- Action/control inputs: Dual action representation depends on reliable camera intrinsics/extrinsics and well-defined input mappings; tooling for calibration and user controls is advised.
- Data and domain shift: Generalization is good across real/stylized scenes, but sector-specific deployments may need domain adaptation, curated prompts, and guardrails to manage artifacts and hallucinations.
- Safety, compliance, and ethics: Healthcare, public policy, defense, and industrial use cases require validation, approvals, and governance; clear disclosure of generative elements is essential in consumer settings.
- Integration ecosystems: Many workflows presume plug-ins/SDKs for existing engines (Unity/Unreal), GIS systems, VFX/NLE tools, and IIoT/SCADA platforms; sustained productization and maintenance are required.
Glossary
- 3D Gaussian Splatting: A point-based 3D representation and rendering technique used for reconstructing scenes from images or videos. "we adopt 3D Gaussian Splatting~\cite{kerbl20233d} for 3D reconstruction on curated videos."
- 3D VAE: A variational autoencoder operating on spatiotemporal video volumes to encode/decode latent representations. "a causal 3D VAE~\cite{kingma2013auto}"
- Attention parallelism: A model-parallel strategy that partitions attention tokens across devices to accelerate inference. "combines sequence parallelism~\cite{li-etal-2023-sequence} and attention parallelism"
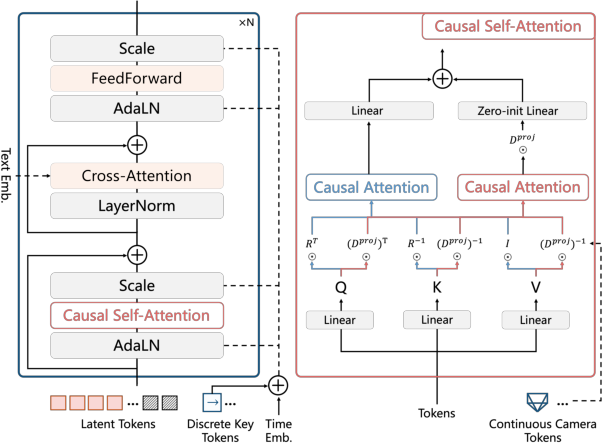
- Autoregressive diffusion transformer: A diffusion-based transformer configured to generate future frames causally, one chunk at a time. "Detailed architecture of our autoregressive diffusion transformer."
- Bidirectional teacher diffusion model: A diffusion model that conditions on both past and future (non-causal) information used for distilling a faster student. "distilling a powerful bidirectional teacher diffusion model into a fast, few-step autoregressive student."
- Camera frustums: The pyramid-shaped volume of space captured by a camera, defined by intrinsics/extrinsics, used to encode spatial relations. "to inject complete camera frustums into self-attention blocks."
- Chunk-wise autoregressive video generation model: A strategy that divides videos into fixed-size chunks and generates them sequentially for streaming. "we finetune it into a chunk-wise autoregressive video generation model."
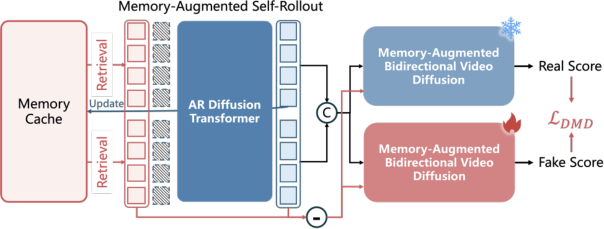
- Context Forcing: A distillation method that aligns teacher and student memory contexts to preserve long-range consistency at real-time speeds. "We also propose Context Forcing, a novel distillation method designed for memory-aware model."
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion models, serving as the core generative backbone. "a Diffusion Transformer (DiT)~\cite{peebles2023scalable}"
- Exposure bias: The training-inference mismatch where a model is trained on ground-truth inputs but tested on its own outputs, causing error compounding. "addresses exposure bias by refining the rollout strategy of CausVid."
- Field-of-view (FOV): The angular extent of the observable scene used to retrieve relevant historical frames for memory. "leveraging field-of-view (FOV) to retrieve relevant context from historical frames"
- Flow matching: A generative training objective that learns a velocity field to map noise to data in diffusion-like models. "The model is trained using flow matching~\cite{lipman2022flow}."
- Geometric relevance scores: Metrics combining FOV overlap and camera distance to select spatially useful memory frames. "guided by geometric relevance scores that incorporate both FOV overlap and camera distance."
- KV-cache mechanisms: Caching key/value tensors from attention layers to avoid recomputation and speed up autoregressive generation. "Additionally, we use KV-cache mechanisms for attention modules to eliminate redundant computations during autoregressive generation."
- Latent diffusion model (LDM): A diffusion model operating in a compressed latent space to enable efficient video synthesis. "adopt the latent diffusion model (LDM)~\cite{rombach2022high}"
- LPIPS: A learned perceptual similarity metric that correlates with human judgments of visual quality. "We employ LPIPS, PSNR, and SSIM to measure visual quality"
- Matrix multiplication quantization: Quantizing matrix multiply operations to accelerate inference with minimal quality loss. "we adopt Sage Attention~\cite{zhang2025sageattention}, float quantization, and matrix multiplication quantization to improve the inference performance."
- Memory attenuation: The degradation of long-range information influence over time within transformer positional encodings. "effectively alleviating memory attenuation."
- NVIDIA Triton Inference Framework: A production deployment system for serving models, enabling low-latency streaming generation. "using NVIDIA Triton Inference Framework"
- PRoPE: A projection-based relative positional encoding for cameras that injects frustum geometry into attention. "we leverage relative positional encoding, i.e., PRoPE~\cite{li2025cameras}"
- Reverse KL: The Kullback–Leibler divergence computed as KL(model || data), used here via score differences for distillation. "the gradient of the reverse KL can be approximated by the score difference"
- Reconstituted Context Memory: A memory mechanism that rebuilds temporal and spatial context from past frames to enforce long-term consistency. "our Reconstituted Context Memory dynamically rebuilds context from past frames"
- Rotary Positional Embedding (RoPE): A rotation-based positional encoding for transformers; extended here to 3D video latents. "3D rotary PE (RoPE)~\cite{su2024roformer}"
- Sage Attention: An efficient attention implementation designed to accelerate inference without degrading quality. "we adopt Sage Attention~\cite{zhang2025sageattention}"
- Self-rollout: Generating future chunks using the student model’s own outputs to construct a causal training trajectory. "we self-rollouts 4 chunks conditioned on the memory context"
- Sequence parallelism: A parallelization technique that splits sequences across devices to distribute computation. "combines sequence parallelism~\cite{li-etal-2023-sequence} and attention parallelism"
- Temporal Reframing: Rewriting positional indices of retrieved frames to keep long-past but important memories temporally “close.” "We propose Temporal Reframing (Fig.\ref{fig:attn-c})."
- Zero-initialized MLP: An MLP whose weights start at zero to safely introduce new conditioning pathways without destabilizing training. "we employ PE and a zero-initialized MLP to encode discrete keys"
Collections
Sign up for free to add this paper to one or more collections.