BlockVid: Block Diffusion for High-Quality and Consistent Minute-Long Video Generation
Abstract: Generating minute-long videos is a critical step toward developing world models, providing a foundation for realistic extended scenes and advanced AI simulators. The emerging semi-autoregressive (block diffusion) paradigm integrates the strengths of diffusion and autoregressive models, enabling arbitrary-length video generation and improving inference efficiency through KV caching and parallel sampling. However, it yet faces two enduring challenges: (i) KV-cache-induced long-horizon error accumulation, and (ii) the lack of fine-grained long-video benchmarks and coherence-aware metrics. To overcome these limitations, we propose BlockVid, a novel block diffusion framework equipped with semantic-aware sparse KV cache, an effective training strategy called Block Forcing, and dedicated chunk-wise noise scheduling and shuffling to reduce error propagation and enhance temporal consistency. We further introduce LV-Bench, a fine-grained benchmark for minute-long videos, complete with new metrics evaluating long-range coherence. Extensive experiments on VBench and LV-Bench demonstrate that BlockVid consistently outperforms existing methods in generating high-quality, coherent minute-long videos. In particular, it achieves a 22.2% improvement on VDE Subject and a 19.4% improvement on VDE Clarity in LV-Bench over the state of the art approaches. Project website: https://ziplab.co/BlockVid. Inferix (Code): https://github.com/alibaba-damo-academy/Inferix.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces BlockVid, a new way for AI to create minute-long videos that look good and stay consistent from start to finish. It focuses on solving a common problem: long videos often lose quality over time—colors drift, characters change slightly, and backgrounds become unstable. BlockVid also brings a new benchmark (LV-Bench) and new metrics to fairly measure how well long videos keep their quality and coherence.
Key Questions the Paper Tries to Answer
- How can we make AI generate long (minute-long) videos that stay clear, consistent, and realistic throughout?
- How do we reduce “error buildup” over time, where small mistakes stack up and degrade the video?
- How can we properly test and compare different video models on long videos, not just short clips?
How the Method Works (Explained Simply)
Think of making a movie in “chunks” or scenes. BlockVid builds long videos by generating them chunk by chunk, and it combines two popular AI ideas:
- Diffusion: like starting with a blurry image and slowly cleaning it up to make it sharp.
- Autoregression: like writing a story one chapter at a time, using previous chapters to guide the next.
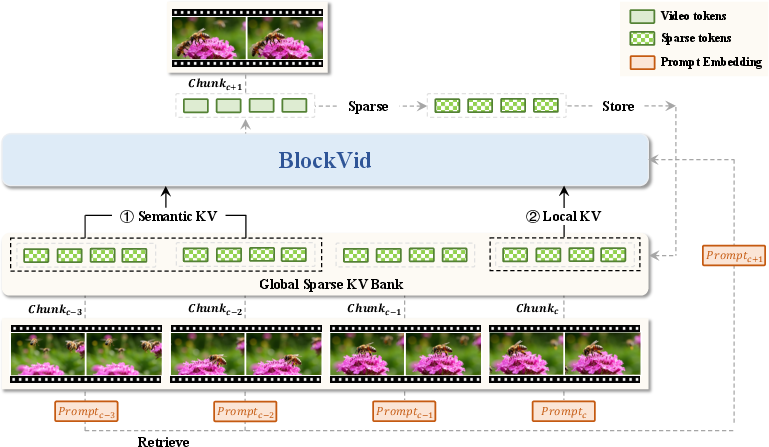
The model keeps a “memory” called a KV cache (Key-Value cache). This cache stores important information from previous chunks so the next chunk knows what to keep consistent (like the character’s clothes or the room’s lighting). But regular caches can accidentally store mistakes too, which get worse over time. BlockVid fixes this with three main innovations:
- Semantic Sparse KV Cache: Instead of saving everything, BlockVid filters and saves only the most important “memory pieces.” It also searches past chunks that match the current prompt (like finding the right chapter notes), so it keeps the useful context without carrying forward errors.
- Block Forcing (plus Self Forcing): These are training strategies. Self Forcing teaches the model using its own outputs so it learns to handle its mistakes. Block Forcing adds a “stay on track” rule, nudging each new chunk to match the meaning and style of the earlier chunks, reducing drift (like reminding a movie director to keep the same actor’s look and the same scene tone).
- Chunk-Level Noise Scheduling and Shuffling: “Noise” is controlled randomness used during generation. BlockVid carefully adjusts noise per chunk: early chunks get lower noise to establish the scene cleanly; later chunks get slightly higher noise so they adapt to the established context. It also lightly shuffles noise around chunk boundaries to make transitions smoother, like blending two scenes so they don’t feel choppy.
To evaluate long videos properly, the authors created LV-Bench, a dataset of 1,000 minute-long videos with detailed notes every 2–5 seconds, and new metrics (VDE) that measure how much the video “drifts” over time in:
- Subject (does the main character stay recognizable?)
- Background (does the setting stay stable?)
- Motion (is movement smooth?)
- Aesthetics (does it keep looking good?)
- Clarity (does it stay sharp?)
Main Findings and Why They Matter
- BlockVid consistently beats other strong methods on both LV-Bench and VBench (a popular video benchmark).
- On LV-Bench, BlockVid reduces identity drift (VDE Subject) by 22.2% and clarity drift (VDE Clarity) by 19.4% compared to top baselines.
- It also achieves high scores in subject consistency, background consistency, motion smoothness, aesthetic quality, and image quality.
- In short: BlockVid makes longer videos that look better and stay consistent over time.
These results matter because many real uses—like filmmaking, digital storytelling, games, and simulations—need long, stable, coherent videos. Better long videos help bring us closer to “world models,” where AI can simulate realistic scenes over extended periods.
Implications and Impact
- For creators: More reliable tools to generate long, cinematic videos with fewer glitches.
- For AI research: A stronger foundation for building “world models” that understand and simulate complex environments over time.
- For evaluation: LV-Bench and VDE give the community fair, detailed ways to measure long-video quality, not just short clips.
- Future directions: Extending BlockVid to multi-shot or movie-style videos (with scene changes), growing LV-Bench, and adding 3D-aware modeling to improve realism even more.
Overall, BlockVid shows a practical path toward high-quality, minute-long video generation by smartly managing memory, training with stability in mind, and carefully controlling noise to keep videos coherent from start to finish.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be directly actionable for future research.
- Efficiency characterization is missing: no measurements of end-to-end throughput, latency, and memory footprint across chunk sizes, KV cache sizes, and different noise schedules; the claimed parallelism and KV-caching efficiency are not quantified.
- Scalability is untested for longer horizons and higher resolutions: behavior beyond one minute, at 1080p/4K, and across different frame rates is unknown.
- KV-bank growth and eviction policy are unspecified: how the global KV bank is bounded, pruned, or updated to avoid unbounded memory and stale context accumulation is not addressed.
- Semantic retrieval relies solely on prompt embeddings: the effectiveness and failure modes of text-only retrieval versus visual or multimodal embeddings (e.g., CLIP/VideoCLIP) are not evaluated.
- Limited semantic retrieval breadth due to l=2: the impact of increasing top-l retrieval (accuracy vs. memory/latency) and strategies for dynamic l selection are unexplored.
- Saliency probing hyperparameters lack guidance: sensitivity to τ (attention coverage), M (token count), and top-k selection is not systematically studied; no robust tuning cookbook is provided.
- Block Forcing weighting γ is under-specified: how γ affects drift, fidelity, and stability across content types, and whether a learned or adaptive γ improves outcomes, remains open.
- Averaging past chunks for x_cond may blur semantics: alternatives (attention-weighted aggregation, learned fusion, contrastive selection, or content-aware weighting) are not investigated.
- Interaction between Block Forcing and Self Forcing is not analyzed: convergence properties, stability risks (e.g., adversarial training collapse), and optimal loss weighting schedules are missing.
- Error reinforcement via generated history is unmitigated: mechanisms to detect and quarantine corrupted context (e.g., drift detectors, refresh/anchoring strategies) are not explored.
- Noise schedules are static and content-agnostic: adaptive or feedback-driven noise scheduling based on scene complexity, detected drift, or motion dynamics is not studied.
- Noise shuffle window s is fixed: trade-offs and adaptivity for s across chunk lengths, motion regimes, and boundary types (hard cuts vs. smooth transitions) are not quantified.
- Chunking strategy is rigid: the effects of variable chunk lengths, overlaps, and boundary anchoring on coherence and error propagation are not evaluated.
- Real-world robustness is untested: performance under occlusions, fast camera motion, abrupt illumination changes, heavy scene clutter, or multi-object interactions is not characterized.
- Multi-shot and movie-style generation are acknowledged but unaddressed: how the method handles scene transitions, narrative coherence, and cross-scene memory is left open.
- 3D-aware and physics-consistent modeling is missing: camera geometry, depth, and physical constraints (e.g., collision, dynamics) are not integrated or evaluated.
- Control modalities are limited: support for audio, camera trajectory control, depth/mask conditioning, or structured editing constraints is not explored.
- Personalization and identity locking are not studied: maintaining a specific subject identity across minutes (humans/animals) under large pose/appearance changes is untested.
- Safety and misuse considerations are absent: identity cloning risks, content moderation, watermarking, and responsible release practices are not discussed.
- Benchmark scope and release clarity: LV-Bench’s public availability, licensing, and reproducibility details are unclear; coverage across domains (e.g., indoor/outdoor, non-human subjects) may be biased.
- VDE metric definitions need validation: precise implementations for clarity/motion/aesthetic/background/subject drift, correlation with human judgments, sensitivity to intended scene changes, and robustness across genres are not provided.
- Fairness of comparisons is uncertain: differences in initialization, training data (private LV-1.1M), compute budgets, and model sizes across baselines are not normalized or audited.
- Inference quality–speed trade-offs are unmeasured: how KV sparsity, retrieval breadth, and noise shuffling affect FPS and latency is not reported.
- VAE compression effects are unexamined: the causal 3D VAE’s compression ratio impact on long-horizon fidelity, artifacts, and motion consistency is not analyzed.
- Failure case analysis is minimal: systematic characterization of typical drift patterns (color shifts, background bleed, identity morphing) and conditions that trigger them is missing.
- Generalization beyond LV-Bench/VBench is unknown: performance on diverse, real-world minute-long videos from unseen domains and camera styles is not evaluated.
- Discriminator architecture and training dynamics are unspecified: Self Forcing’s discriminator design, stability tricks, and loss weight scheduling are not detailed or ablated.
- Memory compression alternatives are untested: exploring low-rank KV compression, quantization, or error-aware cache pruning (e.g., GEAR-like methods) is left open.
- Adaptive recovery mechanisms are absent: strategies like periodic re-grounding to anchor frames, reconditioning checkpoints, or hybrid AR–diffusion refreshes are not investigated.
- Code, models, and data release plans are unclear: without open resources, reproducing LV-Bench/VDE and verifying reported gains remains difficult.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage BlockVid’s findings (semantic-aware sparse KV cache, Block Forcing, chunk-wise noise scheduling/shuffling) and LV-Bench/VDE metrics. Each bullet notes sectors, practical tooling/workflows, and feasibility dependencies.
- Media & Entertainment: previz and animatics for minute-long scenes
- Description: Rapidly generate coherent minute-long scene drafts from storyboard text + an image guide to accelerate pre-production.
- Tools/Workflow: BlockVid inference server (KV cache + block diffusion), chunk-level prompt authoring, cosine noise schedule with s=4 shuffle at chunk boundaries, editors plug-in for Premiere/Resolve.
- Dependencies/Assumptions: 480p-ready pipeline, GPU capacity, content rights and safety filters.
- Advertising & Marketing: stable product demos and brand narratives
- Description: Produce coherent minute-long product showcases without identity/background drift for A/B campaigns.
- Tools/Workflow: BlockVid with “Subject Consistency” and “Background Consistency” gating via VDE metrics; semantic retrieval for brand scenes.
- Dependencies/Assumptions: Brand asset ingestion, prompt engineering expertise, synthetic media labeling policies.
- Social Media/Creator Tools: one-click long-form video generation
- Description: Turn captions + reference images into stable minute-long reels (travel stories, tutorials).
- Tools/Workflow: Web app with chunk prompts, semantic KV cache retrieval from user library, VDE-based quality gate.
- Dependencies/Assumptions: Cloud GPUs, content moderation, watermarking.
- Game Studios: environmental previz and cutscene prototyping
- Description: Coherent long-take scene sketches for level design and narrative pacing tests.
- Tools/Workflow: BlockVid integration into game toolchains; chunk-wise semantic KV retrieval for lore continuity; VDE metrics for drift detection pre-ship.
- Dependencies/Assumptions: Asset compliance, IP policies, fidelity expectations (480p prototype target).
- EdTech: minute-long explainer videos with consistent identity
- Description: Generate stable teacher/character-led explainers (science experiments, language dialogues).
- Tools/Workflow: Templates for chunk prompts per lesson module; VDE Subject to ensure consistent teacher avatar across segments.
- Dependencies/Assumptions: Accuracy review (human-in-the-loop), accessibility (captions), age-appropriate content filters.
- Corporate Training & Safety: coherent procedure and hazard simulations
- Description: Long-form scenarios (evacuation, equipment use) with stable background continuity for plants/warehouses.
- Tools/Workflow: Scenario authoring via chunk prompts and semantic KV recall across similar procedures; VDE Background/Clarity thresholds.
- Dependencies/Assumptions: Domain expert validation, safety disclaimers, governance for synthetic media.
- Healthcare (patient education): procedure walkthroughs and rehab routines
- Description: Stable guided minute-long sequences illustrating exercises or pre-op/post-op steps.
- Tools/Workflow: Clinician-curated chunk prompts; BlockVid outputs assessed by VDE Motion (smoothness) for clear demonstrations.
- Dependencies/Assumptions: Medical accuracy review, HIPAA-aligned deployment, clear disclaimers (non-diagnostic content).
- Retail & E-commerce: catalog-to-video pipelines
- Description: Turn product pages into coherent minute-long showcases with consistent identity and background.
- Tools/Workflow: Batch generation with semantic KV retrieval from product families; integrate LV-Bench-derived VDE thresholds in QC.
- Dependencies/Assumptions: SKU metadata quality, synthetic labeling, GPU scheduling.
- Vision ML Engineering: production QA with LV-Bench + VDE metrics
- Description: Adopt LV-Bench and VDE as coherence-aware metrics to monitor drift during model updates.
- Tools/Workflow: CI/CD step with minute-long evals; regression gates on VDE Subject/Background/Motion/Clarity/Aesthetic.
- Dependencies/Assumptions: Access to LV-Bench split, standardized evaluation harness.
- Model Efficiency R&D: semantic sparse KV cache as a reusable library
- Description: Integrate sparse KV caching into existing transformers (video or text) to cut memory and reduce long-horizon error.
- Tools/Workflow: OSS library implementing top-k token selection and prompt-embedding retrieval; benchmarks against rolling KV.
- Dependencies/Assumptions: Framework compatibility (PyTorch/JAX), careful mask handling.
- Content Moderation & Policy Ops: coherence-aware deepfake risk screening
- Description: Use VDE metrics to flag identity/background drift indicative of manipulations in long videos.
- Tools/Workflow: Moderation pipeline with VDE Subject/Background monitors; mismatch alerts to human reviewers.
- Dependencies/Assumptions: Threshold tuning per domain, false positive calibration, policy alignment.
- Scientific Research: reproducible long-video benchmarks
- Description: Use LV-Bench for ablations on long-horizon coherence, training strategies (Block/Self Forcing), and noise schedules.
- Tools/Workflow: Two-stage post-training recipe; cosine schedule; s=4 shuffling; semantic KV top-l retrieval (l=2).
- Dependencies/Assumptions: Compute availability, dataset licensing, adherence to benchmark protocols.
Long-Term Applications
These longer-horizon opportunities require further scaling, research, higher resolutions/audio integration, or multi-shot cinematic robustness.
- World Models for Agentic/Embodied AI
- Description: Minute-long coherent simulations for training/diagnosing agents (navigation, manipulation).
- Tools/Workflow: BlockVid-like semi-AR simulators; policy-conditioned chunk prompts; VDE-based stability guarantees.
- Dependencies/Assumptions: 3D-aware modeling, physics consistency, domain transfer validations.
- Autonomous Driving & Robotics Sim
- Description: Long-take synthetic scenarios for rare event coverage and behavior learning.
- Tools/Workflow: Scene libraries with semantic KV retrieval across road types; drift monitors (VDE Motion/Background) for realism gates.
- Dependencies/Assumptions: High-fidelity dynamics, sensor models, safety certification; bridging sim-to-real gaps.
- Cinematic-Grade Multi-Shot Generation
- Description: Movie-style compositions with scene transitions, maintained global narrative coherence.
- Tools/Workflow: Expanded Block Forcing across shots; multi-shot semantic memory; editor-integrated workflows.
- Dependencies/Assumptions: Multi-shot coherence research, higher resolutions (4K), audio score/speech generation.
- Digital Twins & Smart Cities
- Description: Long-form synthetic urban sequences for planning, crowd flow, emergency drills.
- Tools/Workflow: City twin scenario authoring with semantic KV banks (districts, venues); drift-aware evaluation pipelines.
- Dependencies/Assumptions: Data governance, privacy, alignment with real sensor feeds.
- Education at Scale: Personalized video tutors
- Description: Coherent minute-long lessons sequenced across curricula with consistent instructor avatars and environments.
- Tools/Workflow: Adaptive chunk prompt generation from learner models; VDE gating for continuity; LMS integration.
- Dependencies/Assumptions: Pedagogical validation, bias/safety guardrails, multilingual support.
- Healthcare Simulation & Telemedicine Training
- Description: Long scenario-based training (team handoffs, operating room workflows) with stable identities and contexts.
- Tools/Workflow: Role-conditioned chunk prompts; drift monitors for team identity consistency; integration in CME modules.
- Dependencies/Assumptions: Clinical validation, liability frameworks, secure deployment.
- Finance & News: minute-long explainers with narrative coherence
- Description: Stable identity and background for market or policy briefings, reducing visual drift that erodes trust.
- Tools/Workflow: Prompt-to-video pipelines with semantic KV retrieval across topic series; watermarking and provenance.
- Dependencies/Assumptions: Compliance (synthetic disclosures), reputational risk controls.
- Coherence Certification & Standards
- Description: Regulatory or industry standards for long-video generative quality using VDE-style metrics.
- Tools/Workflow: Certification bodies adopt LV-Bench-like evaluations; publish thresholds and audit procedures.
- Dependencies/Assumptions: Multi-stakeholder consensus, test suite maintenance, legal frameworks.
- Cross-Modal Block Diffusion (Video+Audio)
- Description: Extend block diffusion to synchronized audio tracks for coherent soundscapes and dialogue.
- Tools/Workflow: Joint semantic KV across audio-visual tokens; cross-modal Block Forcing objectives.
- Dependencies/Assumptions: Audio alignment research, licensing for voice timbres, safety around voice cloning.
- Real-Time Streaming Generative Video
- Description: Interactive experiences (live events, virtual influencers) generating stable minute-long segments continuously.
- Tools/Workflow: KV cache warm-starts, low-latency sparse retrieval, adaptive chunk noise schedules.
- Dependencies/Assumptions: Latency constraints, scalability, robust moderation.
- Synthetic Data at Scale for Vision Tasks
- Description: Long-take labeled sequences (tracking, re-ID) generated and validated with coherence metrics.
- Tools/Workflow: Data engine combining GPT-4o-like captioning with VDE checks; domain adaptation steps.
- Dependencies/Assumptions: Label quality assurance, transfer to real data, licensing clarity.
- Enterprise Knowledge Videos
- Description: Stable long-form visual SOPs and “how-to” sequences tailored per department.
- Tools/Workflow: Knowledge-base conditioned chunk prompts, semantic KV memory across SOP families; VDE QC.
- Dependencies/Assumptions: SME review, governance, secure content handling.
Key Assumptions and Dependencies Across Applications
- Compute and throughput: BlockVid was trained on multi-GPU clusters; real deployments need GPU scheduling and cost controls.
- Resolution/audio: Current evidence centers on 480p video without audio; many long-term uses require higher resolution and synchronized audio.
- Data curation: LV-Bench and LV-1.1M rely on GPT-4o captions and human validation; expansion requires consistent quality assurance and licensing.
- Safety/compliance: Watermarking, provenance, synthetic labeling, identity consent, and domain expert review are essential for regulated sectors.
- Multi-shot and 3D realism: The paper notes limitations in multi-shot composition; future work should address scene transitions and 3D/physics fidelity.
Glossary
- 3D causal VAE: A variational autoencoder that compresses video volumes with causal temporal structure for latent representation. "The 3D causal VAE compresses its spatio-temporal dimensions to while expanding the number of channels to 16, resulting in the latent representation ."
- AdamW: An optimizer that decouples weight decay from gradient updates to improve generalization. "We employ AdamW and stepwise decay schedule for all stages of post-training."
- Autoregressive (AR): A generative modeling approach that predicts each next element conditioned on previously generated outputs. "In contrast, AR-based frameworks \citep{wang2024loong} support variable-length generation and KV Cache management, but their generation quality lags behind video diffusion, and decoding is not parallelizable."
- Block diffusion: A semi-autoregressive paradigm that generates sequences in blocks using diffusion within each block while conditioning on past blocks. "Block diffusion (semi-autoregressive or chunk-by-chunk diffusion) decodes long sequences in blocks: within each block the model performs iterative diffusion denoising, while across blocks it conditions on previously generated content via KV caches."
- Block Forcing: A training objective that aligns denoising with semantic history to maintain cross-chunk coherence and reduce drift. "To address these limitations, we introduce a Block Forcing loss, which decomposes the learning objective into two complementary parts."
- Causal mask: An attention mask that enforces causal (past-to-future) dependencies across chunks. "where the denotes a chunk-level causal mask."
- Chunk-aware noise shuffling: An inference technique that locally permutes per-frame noises near chunk boundaries to smooth transitions. "Inspired by FreeNoise~\citep{qiu2023freenoise}, we further adapt local noise shuffling to the chunk-by-chunk setting."
- Chunk-level noise scheduler: A strategy that assigns progressively increasing noise levels across chunks to stabilize long-horizon generation. "We further develop a chunk-level noise scheduler that smoothly increases noise levels and an inter-chunk noise shuffling strategy to enhance temporal consistency and reduce error accumulation over extended durations."
- Cosine schedule: A smooth scheduling function (e.g., for noise) that follows a cosine curve to modulate levels over time. "We adopt a cosine schedule, which provides smooth acceleration and deceleration:"
- Diffusion Transformer (DiT): A transformer-based diffusion architecture with bidirectional attention, typically without KV caching. "Most current video diffusion models \citep{wan2025wan} rely on the Diffusion Transformer (DiT) \citep{peebles2023scalable}âwhich uses bidirectional attention without KV caching."
- Exposure bias: The mismatch caused by training on ground-truth sequences but inferring from model outputs, leading to compounding errors. "A major challenge in long video generation is the training-inference gap: during training the model is conditioned on ground-truth frames (teacher forcing), but at inference it relies on its own imperfect outputs, leading to exposure bias and error accumulation."
- Flow Matching: A training framework that learns a velocity field to transport noise to data along a continuous trajectory. "the stochastic interpolant formulation~\citep{albergo2022building} of Flow Matching~\citep{lipman2022flow}."
- InfiniBand: A high-bandwidth, low-latency interconnect technology used in distributed training clusters. "InfiniBand interconnects provide high-bandwidth communication across nodes for distributed training."
- KV cache: Cached key–value tensors from transformer attention used to speed and stabilize long, variable-length generation. "KV-cache-induced long-horizon error accumulation"
- LV-Bench: A benchmark of 1,000 minute-long videos with fine-grained chunk-level annotations for evaluating long-range coherence. "we propose LV-Bench, a collection of 1,000 minute-long videos with fine-grained annotations for every 2â5 second chunk."
- Rolling KV: A caching strategy that retains and reuses the most recent keys and values across generation steps. "We further explore rolling KV \citep{huang2025self}, dynamic sparse KV \citep{he2024zipvl}, and our semantic sparse KV under different attention thresholds ."
- Semantic sparse KV cache: A method that stores only salient KV tokens and retrieves semantically relevant past context to reduce error accumulation. "The proposed semantic sparse KV cache selectively stores salient tokens from past chunks and retrieves the most semantically aligned context for the current prompt, thereby efficiently maintaining long-range consistency without propagating redundant errors."
- Self Forcing: A sequence-level training loss that exposes the model to its own roll-outs and adversarially matches generated and real video distributions. "Although Self Forcing mitigates the trainingâinference gap, it stabilizes predictions only within a single chunk and lacks mechanism for maintaining cross-chunk coherence."
- Stochastic interpolant: A formulation that defines a continuous path between data and noise to guide flow matching training. "stochastic interpolant formulation~\citep{albergo2022building} of Flow Matching~\citep{lipman2022flow}."
- Teacher forcing: A training technique that conditions the model on ground-truth inputs rather than its own predictions. "during training the model is conditioned on ground-truth frames (teacher forcing), but at inference it relies on its own imperfect outputs"
- Video Drift Error (VDE): A family of metrics that quantify temporal drift (e.g., subject, background, clarity) in long video generation. "we further introduce Video Drift Error (VDE) metrics based on Weighted Mean Absolute Percentage Error (WMAPE) \citep{kim2016new,de2016mean}, integrated with original VBench metrics"
- VBench: A benchmark suite for video generation evaluating aspects like consistency, motion smoothness, and image quality. "Existing benchmarks and metrics like VBench \citep{huang2024vbench} focus on diversity or object categories but fail to capture error accumulation and coherence over extended durations."
- Weighted Mean Absolute Percentage Error (WMAPE): A forecast accuracy metric weighting absolute percentage errors, used to define drift-based video metrics. "Weighted Mean Absolute Percentage Error (WMAPE) \citep{kim2016new,de2016mean}"
Collections
Sign up for free to add this paper to one or more collections.