- The paper introduces a symmetry-aware RL framework that refines equivariant diffusion policies using theoretical and empirical analyses.
- The methodology leverages group-invariant kernels and equivariant denoising processes to boost sample efficiency and training stability in robot tasks.
- Empirical results demonstrate that strict and approximate equivariance improve performance on tasks like Robomimic Lift and MimicGen, mitigating Q-value divergence.
Symmetry-Aware Steering of Equivariant Diffusion Policies
Introduction and Motivation
This paper analyzes the integration of geometric symmetries into the fine-tuning of robotic policies via diffusion models. Specifically, it focuses on Equivariant Diffusion Policies (EDPs), which combine the generative capacity of diffusion models with the efficient generalization properties imparted by group-equivariant neural architectures. While EDPs excel at exploiting symmetry in the demonstration-based learning regime, practical applications often demand further policy refinement through reinforcement learning (RL), particularly via Diffusion Steering via Reinforcement Learning (DSRL). The central premise investigated is that standard (non-equivariant) steering methods inadequately leverage the symmetrical structure intrinsic to EDPs, resulting in inefficiencies and instability. The paper makes formal, theoretical, and empirical contributions, offering a symmetry-aware RL steering framework for EDPs and an in-depth analysis of its benefits and practical limitations.
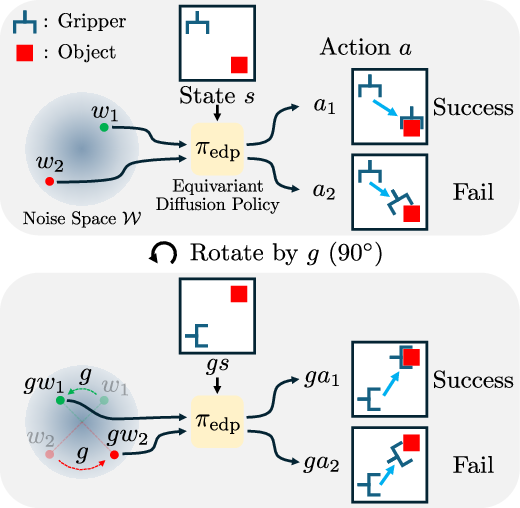
Theoretical Analysis: Equivariance in Diffusion Steering
The authors commence with a rigorous mathematical development of the symmetry properties induced by EDPs. They demonstrate that:
Building on these observations, the steering problem is recast as RL in a latent-noise MDP, where actions are sampled in the noise space. Crucially, the authors prove that if the base environment MDP and diffusion policy are G-invariant/equivariant, the latent-noise MDP inherits full group-invariance. This enables the direct application of group-equivariant RL, guaranteeing that optimal critics and actors preserve symmetry constraints.
In light of the induced latent-noise MDP’s symmetry properties, the paper formalizes a symmetry-aware steering framework operationalized via equivariant Soft Actor-Critic (Equi-SAC). In this regime, both the actor and critic enforce the appropriate equivariance and invariance constraints dictated by the group's representations. For real-world scenarios exhibiting mild symmetry breaking (e.g., induced by robot hardware limits), approximately-equivariant RL agents are proposed, implemented by mixing equivariant and non-equivariant pathways with soft regularization as in [finzi2021residual]. This relaxation accommodates imperfect symmetry while maintaining strong inductive bias.
Experimental Setup and Results
The experimental evaluation spans tasks with varying symmetry structure and complexity using robotic manipulation benchmarks: Robomimic (Lift) and MimicGen (Stack D1, Square D2). The workflow consists of pre-training a state-based EDP with limited demonstrations, then steering the policy in the latent-noise space with different RL agents:
- DSRL: vanilla non-equivariant latent-noise actor/critic
- Equi-DSRL: strictly equivariant/invariant actor/critic
- Approx-Equi-DSRL: hybrid soft-equivariant networks
For each task, mean success rates and Q-value dynamics are compared under these steering strategies. The initial state of the low-data regime task (Lift) is shown below.



Figure 2: Visualization of the Lift task—lifting a red cube with randomized object and gripper poses.
In the Lift task (only 3 demonstrations), Equi-DSRL achieves the highest peak success rate (0.840), followed closely by Approx-Equi-DSRL, both vastly outperforming the unstable standard DSRL (see Figure 3). In more complex tasks (Stack D1 with 100 demos, Square D2 with 200 demos), Approx-Equi-DSRL yields the most robust performance, benefiting from flexible symmetry exploitation while avoiding over-constraining the agent. In all settings, symmetry-aware methods mitigate severe Q-value divergence and catastrophic performance failures observed in standard DSRL, especially under high update-to-data (UTD) RL regimes.
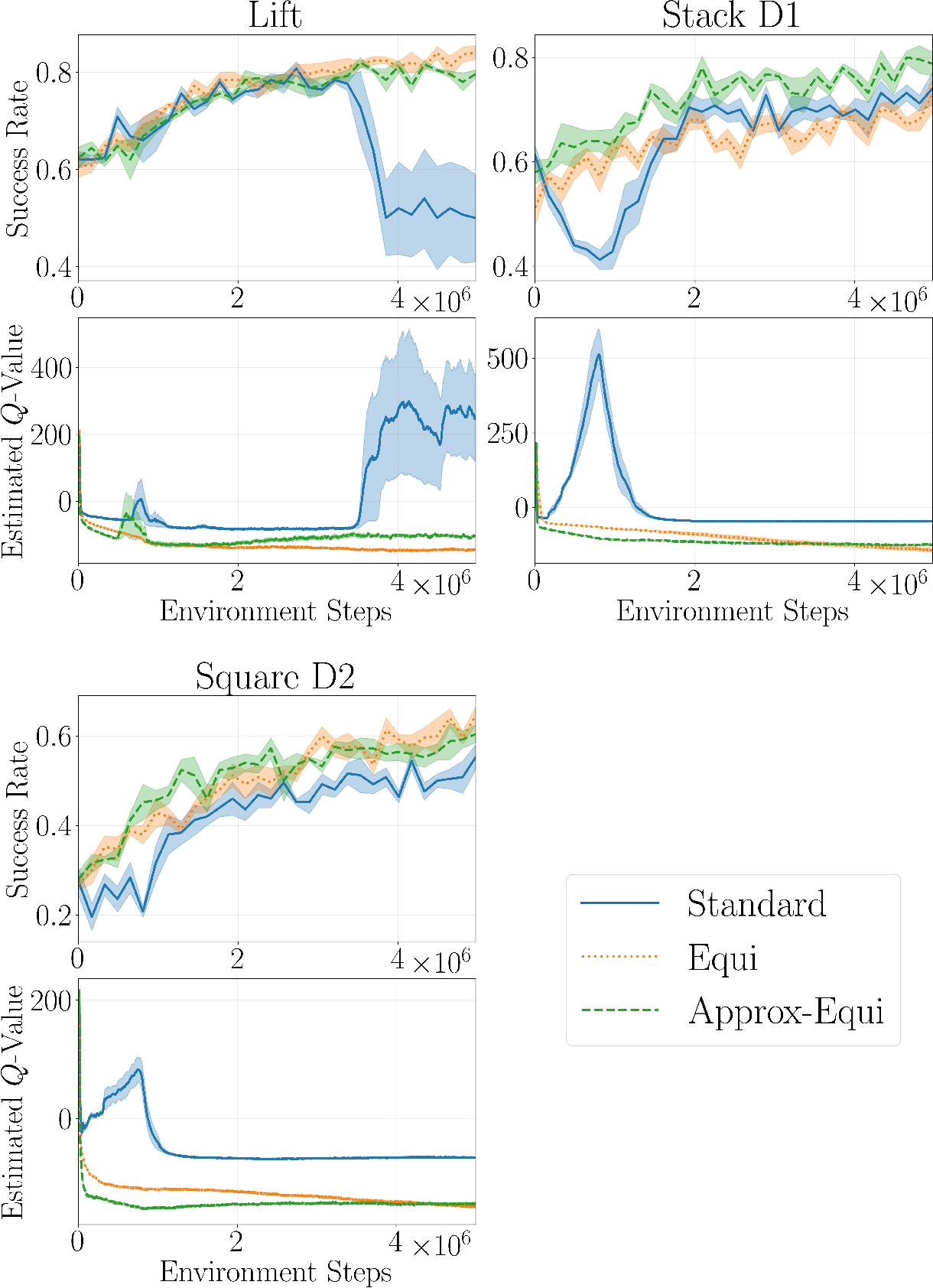
Figure 3: Comparative performance of DSRL, Equi-DSRL, and Approx-Equi-DSRL. Equivariant methods consistently improve sample efficiency and stability.
Discussion: Benefits and Limits of Symmetry-Aware Steering
The empirical evidence corroborates the theoretical claims:
- Sample Efficiency: In tasks with meaningful spatial or rotational symmetry, equivariant steering greatly improves data efficiency and the reliability of RL-derived improvements.
- Training Stability: Group invariance in the critic regularizes Q-value estimation, mitigating off-policy value overestimation and update instability prevalent in high-UTD RL with non-equivariant critics.
- Symmetry Breaking: In real manipulation domains (e.g., Stack D1), hard-enforced equivariance can degrade policy improvement due to kinematic constraints or workspace limits breaking ideal symmetry assumptions. Approximately-equivariant agents, which softly model symmetry, yield higher final performance in such cases.
The framework’s generality clarifies when strict equivariance is maximally beneficial and when soft-approximate methods are preferable, and quantifies these behaviors with strong numerical results.
Implications and Future Directions
This work delivers significant theoretical clarification on symmetry propagation in policy steering, situating DSRL for EDPs within a rigorous equivariant RL context. Practically, the combination of symmetry-aware steering and diffusion architectures enables high-fidelity policy improvements with minimal demonstration data, an essential property for scalable and efficient robot learning. However, the analysis also reveals that strict symmetry enforcement can be detrimental if real-world environments violate symmetry assumptions due to hardware or workspace asymmetries. Consequently, future research should pursue more general, adaptive mechanisms for discovering, measuring, and leveraging approximate symmetries in RL environments. Additionally, the extension of symmetry priors to steer non-equivariant base policies remains a prominent open direction.
Conclusion
The paper develops and systematically analyzes a symmetry-aware RL framework for steering EDPs, unifying diffusion-based imitation learning with geometric RL priors. It establishes both the theoretical foundation and empirical effectiveness of equivariant and approximately-equivariant steering policies, offering a robust blueprint for integrating group symmetry into general-purpose robot policy optimization. These insights have immediate ramifications for efficient data use, policy safety, and the scalable deployment of learning-based robotic systems.