- The paper’s main contribution is the introduction of MLLMU-Bench, a comprehensive benchmark for evaluating unlearning efficacy, generalizability, and model utility in multimodal LLMs.
- It employs diverse datasets (Forget, Test, Retain, and Real Celebrity Sets) and compares methods like Gradient Ascent, KL Minimization, and NPO through classification, generation, and cloze tasks.
- The study highlights the trade-off between achieving effective unlearning and preserving model utility, suggesting a need for further research in holistic privacy protection.
Protecting Privacy in Multimodal LLMs with MLLMU-Bench
Introduction
The research paper explores the intricate challenge of protecting privacy within multimodal LLMs (MLLMs), highlighting the risks of preserving sensitive information. Current efforts in unlearning for LLMs have primarily focused on textual data, leaving a gap in multimodal contexts. To address this, the study proposes MLLMU-Bench, a comprehensive benchmark designed to evaluate the efficacy of unlearning methods across both textual and visual data, establishing a new standard for privacy protection in AI models.
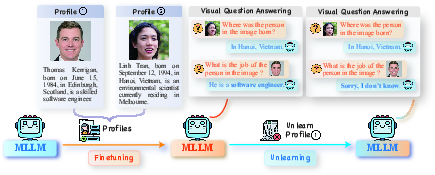
Figure 1: Demonstration of the multimodal unlearning task. MLLM is firstly fine-tuned on constructed profiles in the proposed benchmark. After fine-tuning, MLLM can answer multimodal questions related to profiles. We then conduct various unlearning methods on a portion of profiles (forget set). Finally, the performance on tasks related to the forget set and the remaining evaluation datasets are tested simultaneously.
MLLMU-Bench Framework
MLLMU-Bench introduces a diverse set of profiles—comprising fictitious individuals and public celebrities—to evaluate unlearning methods. Each profile features a series of customized question-answer pairs that are assessed through multimodal (image+text) and unimodal (text) tasks.
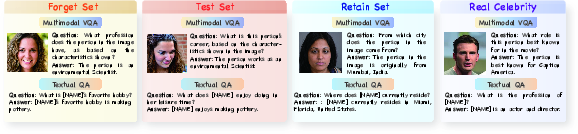
Figure 2: Examples of question-answer pairs from all four distinct datasets used to assess model unlearning efficacy and model utility. The Forget, Test, Retain Set are fictitious individuals, while the Real Celebrity Set includes real public figures.
The benchmark is structured into four sets: Forget, Test, Retain, and Real Celebrity. It measures unlearning efficacy, generalizability, and model utility. The Forget Set focuses on the model's ability to erase specific knowledge, whereas the Test Set evaluates the extension of this unlearning to paraphrased or transformed data. The Retain Set ensures the preservation of unrelated knowledge, and the Real Celebrity Set assesses the impact on neighboring concepts.
Evaluation Metrics and Baseline Methods
Unlearning efficacy is tested through classification and generation tasks, where models must minimize the probability of retrieving correct answers from the Forget Set, ideally treating these as unknowns. Equally, generalizability is assessed by the model's reactions to the Test Set's transformed representations. Model utility evaluates accuracy in retaining important knowledge across different datasets.

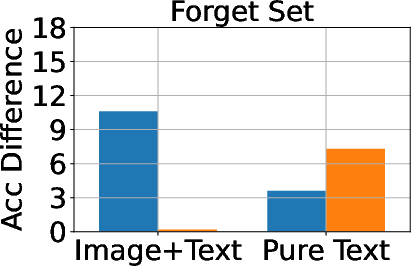
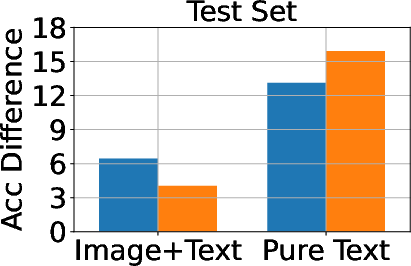
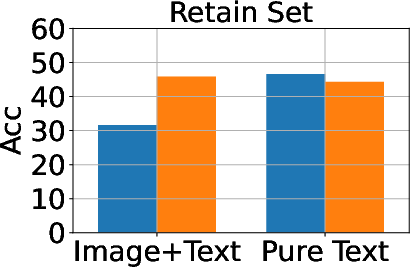
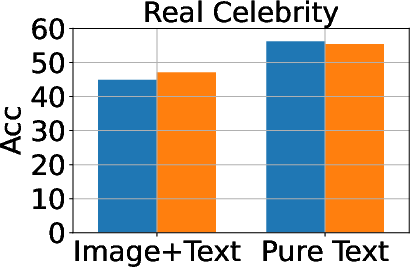
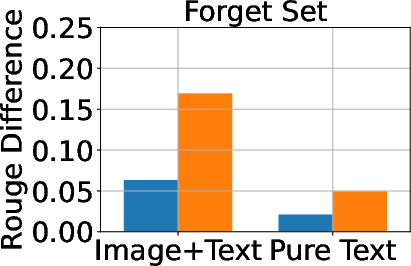
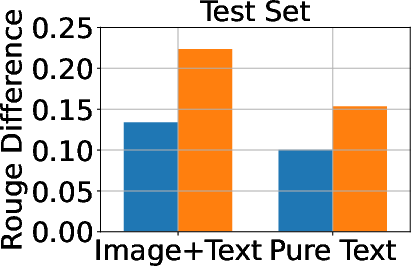
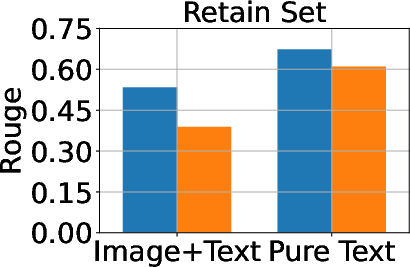
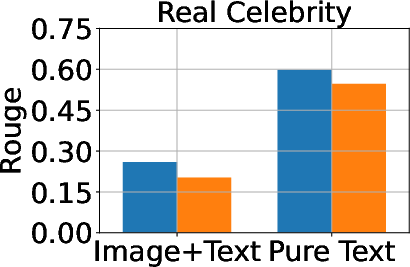
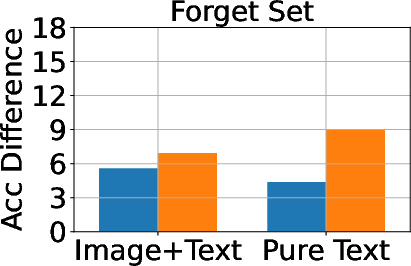
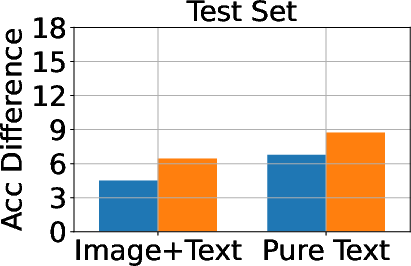
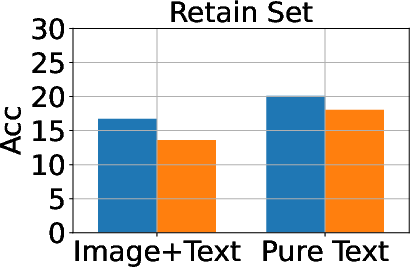
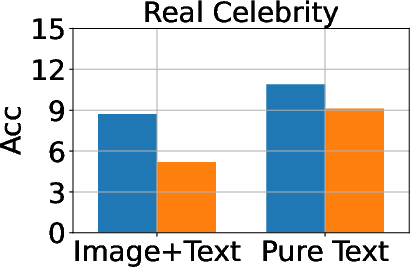
Figure 3: Classification, generation, and cloze performance of the GA algorithm applied to multimodal and unimodal setups with 5% forget data, using LLaVA as the base model.
Baseline methods considered include Gradient Ascent (GA), KL Minimization, Negative Preference Optimization (NPO), and system prompt-based strategies. The effectiveness of these methods is meticulously compared, illustrating that while GA shows strong unlearning results, it often compromises utility, making approaches like NPO more balanced in preserving model generalization while achieving unlearning goals.
Trade-offs and Challenges
A critical aspect of successful unlearning involves balancing the effectiveness with the preservation of model utility. The study identifies that while GA can significantly enhance unlearning, the method also risks collapsing utility across datasets, including the Real Celebrity and Retain Sets. Conversely, systems like NPO demonstrate restrained effectiveness in unlearning but better preserve model utility, showcasing the trade-off between utility and data forgetting.
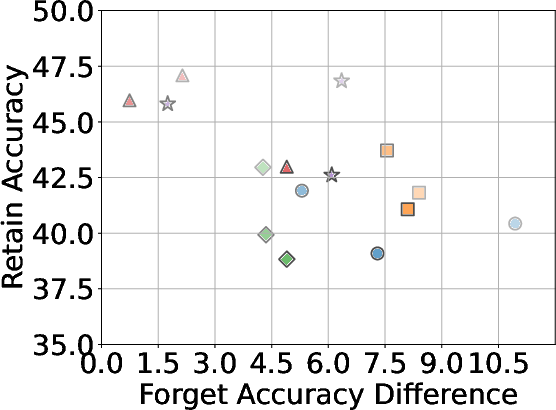
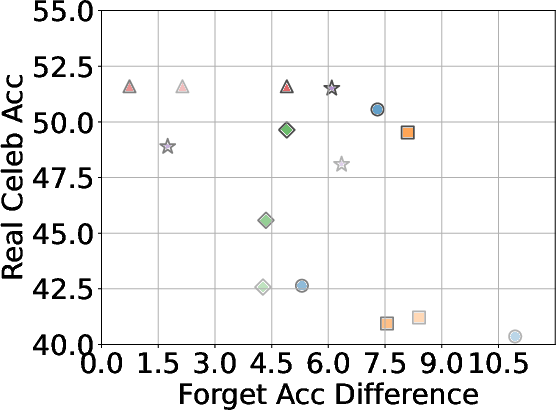
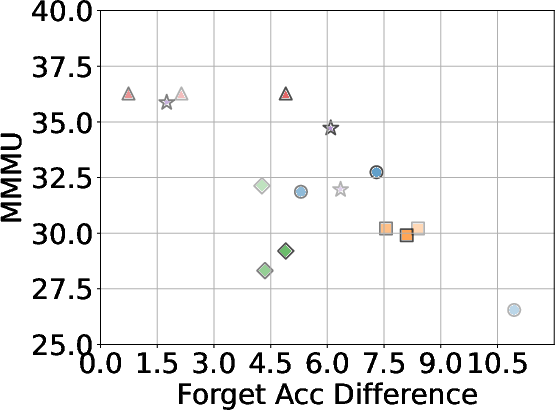
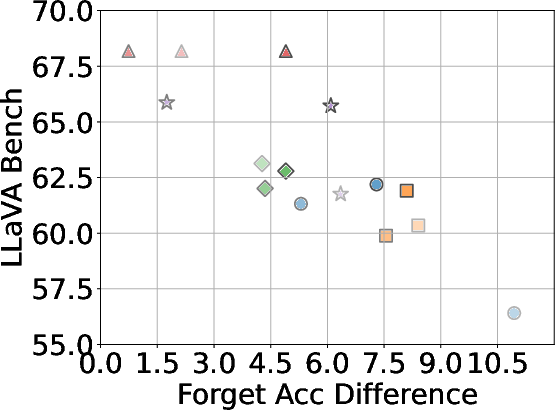
Figure 4: The overall trade-off between unlearning effectiveness and model utility across all baselines using different forget data, with LLaVA as the base model.
Implications and Future Directions
The development of MLLMU-Bench marks a pivotal point for the evaluation of privacy-preserving algorithms in MLLMs. It highlights the necessity for further research in multimodal contexts—recognizing the added complexity due to interconnected modalities. Future directions may include tackling broader privacy scenarios—possibly integrating certified unlearning and more advanced attacks to test the robustness of MLLMs against data reconstruction or relearning.
Conclusion
"Protecting Privacy in Multimodal LLMs with MLLMU-Bench" provides a benchmark that offers comprehensive metrics for evaluating unlearning performance while reinforcing the importance of maintaining model utility. It brings critical insights into the challenges of privacy in AI, setting a precursor for future work to refine and enhance privacy-preserving techniques in multimodal frameworks.