- The paper demonstrates that gradual depth-growing techniques (MIDAS and LIDAS) mitigate the curse of depth by restructuring Transformer layers for improved reasoning.
- It employs strategic layer insertion and reordering to form computational blocks that fully leverage deep layers for enhanced performance on reasoning tasks.
- Swap experiments and attention dynamics analyses reveal that these depth-grown models achieve robust, efficient architecture designs while reducing computational waste.
Do Depth-Grown Models Overcome the Curse of Depth? An In-Depth Analysis
Introduction
Transformers have revolutionized the landscape of natural language processing, primarily due to their scalability in depth. However, the inefficiency in utilizing all layers, known as the "Curse of Depth," has highlighted resource wastage inherent in traditional models. Recent advancements, such as the MIDAS method, propose that gradually growing a Transformer's depth can enhance its reasoning capabilities without incurring high computational costs. This paper provides a mechanistic understanding of how gradual depth growth might overcome the inherent limitations of deep models (2512.08819).
Gradual Depth Growth and the Curse of Depth
The core issue with deep Transformer models is that not all layers contribute equally to output quality; deeper layers often underperform due to the Curse of Depth. Studies have shown that the latter layers of non-grown models, particularly in pre-layernorm architectures, contribute minimally. This work establishes how gradual depth-growing techniques like MIDAS counteract these diminishing returns by restructuring the Transformer into more effective computational units, or 'blocks', which utilize depth more efficiently (Figure 1).
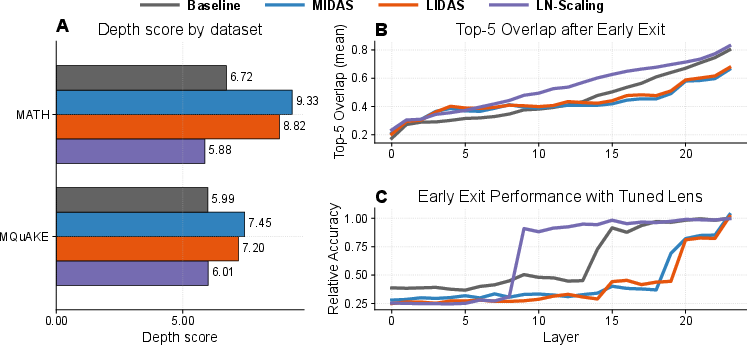
Figure 1: Depth-grown models use their depth more (1.7B).
MIDAS and LIDAS: Growing Architecture
MIDAS utilizes a strategy whereby new layers are strategically introduced into the middle of the model, yielding performance improvements on reasoning-heavy benchmarks. This process progressively evolves the model's depth, resulting in distinct computational circuits resistant to the Curse of Depth. Building on this, the paper introduces LIDAS, which rearranges layers more symmetrically around the model's mid-point, further enhancing performance without degrading language-model performance (2512.08819).
Computational Blocks and Layer Utilization
The paper rigorously evaluates how gradual growth fosters unique cyclical and permutable patterns within mid-network blocks. As evidenced by swap experiments, grown models exhibit robustness to layer ordering interventions, suggesting these blocks are less dependent on strict layer sequences (Figure 2). Further, the results emphasize that grown models fully utilize their depth, with later layers contributing significant novel computations (2512.08819).
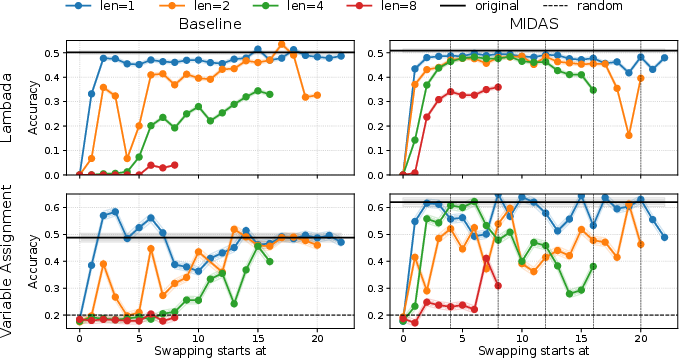
Figure 2: Effect of swapping blocks of layers on Lambada (top row) and the reasoning primitive Variable Assignment Math (bottom row).
Attention Dynamics and Symmetry
In analyzing grown models' internal mechanisms, the paper reveals that sublayers within blocks adopt cyclical roles, with particular attention to how layers aggregate and affect the residual stream (Figure 3). Notably, LIDAS aligns attention sublayers more effectively with the residual, fostering better integration of newly introduced features. This arrangement grants LIDAS a performance edge over MIDAS and baseline architectures (2512.08819).
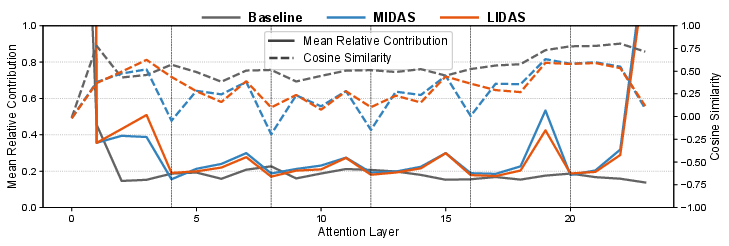
Figure 3: Attention layer contributions to the residual stream.
Implications and Future Directions
The paper's insights offer a blueprint for developing more efficient, depth-effective Transformer architectures. By showcasing the utility of incremental growth strategies, it suggests a pathway towards overcoming current architectural inefficiencies. Future exploration may focus on optimizing block sizes and growth patterns to enhance specific tasks, while also considering computational cost reduction strategies applicable across various domains (2512.08819).
Conclusion
This work illustrates how gradual depth growth strategies, specifically through MIDAS and LIDAS, advance the efficiency of Transformers by effectively utilizing their available depth. This reformulation not only increases reasoning capabilities but also provides a more resilient architectural framework that transcends current inefficiencies characterized by the Curse of Depth. As such, it forms a pivotal step towards more logically structured and computationally efficient models (2512.08819).

