Scaling Zero-Shot Reference-to-Video Generation
Abstract: Reference-to-video (R2V) generation aims to synthesize videos that align with a text prompt while preserving the subject identity from reference images. However, current R2V methods are hindered by the reliance on explicit reference image-video-text triplets, whose construction is highly expensive and difficult to scale. We bypass this bottleneck by introducing Saber, a scalable zero-shot framework that requires no explicit R2V data. Trained exclusively on video-text pairs, Saber employs a masked training strategy and a tailored attention-based model design to learn identity-consistent and reference-aware representations. Mask augmentation techniques are further integrated to mitigate copy-paste artifacts common in reference-to-video generation. Moreover, Saber demonstrates remarkable generalization capabilities across a varying number of references and achieves superior performance on the OpenS2V-Eval benchmark compared to methods trained with R2V data.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Saber, a new way to make short videos that include specific people or objects from given images and follow a text description. The big idea is that Saber learns this skill without using expensive, hard-to-build “reference image + matching video + text” datasets. Instead, it trains only on large collections of regular videos and their captions, and still learns to keep a subject’s identity consistent in the generated video.
What questions did the researchers ask?
- Can we generate a video that both follows a text prompt and keeps the same person or object from one or more reference images, without training on special “reference-to-video” datasets?
- How can we teach a model to focus on the important parts of reference images (like the person’s face or a specific object) and avoid simply copy-pasting them directly into the video?
- Will this approach work with different kinds and numbers of references (one image, many images, foreground subjects, or whole background scenes)?
- Can such a model match or beat methods that are trained on specialized reference-to-video data?
How did they do it? (Simple explanation)
Think of video generation like painting: you start from a canvas filled with “static” (random noise), then step by step remove the static to reveal a clear picture guided by text and reference images. Saber adds a clever training trick so the model learns to pay attention to the right parts of the references and keep identities consistent.
Training without special data
Instead of collecting special triplets (reference image + exact paired video + matching text), Saber trains on regular video-text pairs. This makes training much easier to scale, because there are lots of captioned videos available.
Masked frames as “pretend” reference images
During training, Saber picks frames from the training videos and covers part of each frame with a mask (like placing a cut-out shape over a photo). The uncovered area acts like a reference subject, and the model learns to use this partial information to build the full video while following the text.
- Why masking helps: It’s like giving the model many different “peek windows” into the subjects and backgrounds. Different shapes and sizes of masks (circles, polygons, blobby shapes) and transformations (rotations, flips, scaling) make the model robust and prevent it from just copy-pasting pixels.
Attention that focuses on the right spots
Inside the model, attention is like highlighting what to look at. Saber uses an “attention mask” to tell the model: “Pay attention to the parts of the reference image that really matter (the subject), and ignore the background.” This helps the model learn identity and appearance without dragging in irrelevant details.
Avoiding copy‑paste artifacts
Copy‑paste artifacts look like the model slapped the reference face or object straight onto the video without blending naturally. The mask augmentations (rotate, scale, shear, flip) and the attention masks break the one‑to‑one alignment between the reference and target frames. This forces the model to genuinely understand and recreate the subject, not just copy pixels.
Using references at test time
When you want to generate a video:
- If your reference image shows a subject (like a particular person or object), Saber uses a segmentation tool to cut out the subject area. The model then focuses on this foreground.
- If your reference image is a whole scene (like a beach), Saber treats the entire image as the reference.
- The model “looks at” the reference images and the text prompt together and then generates a video that matches the text while preserving the identity and look from the references.
What did they find?
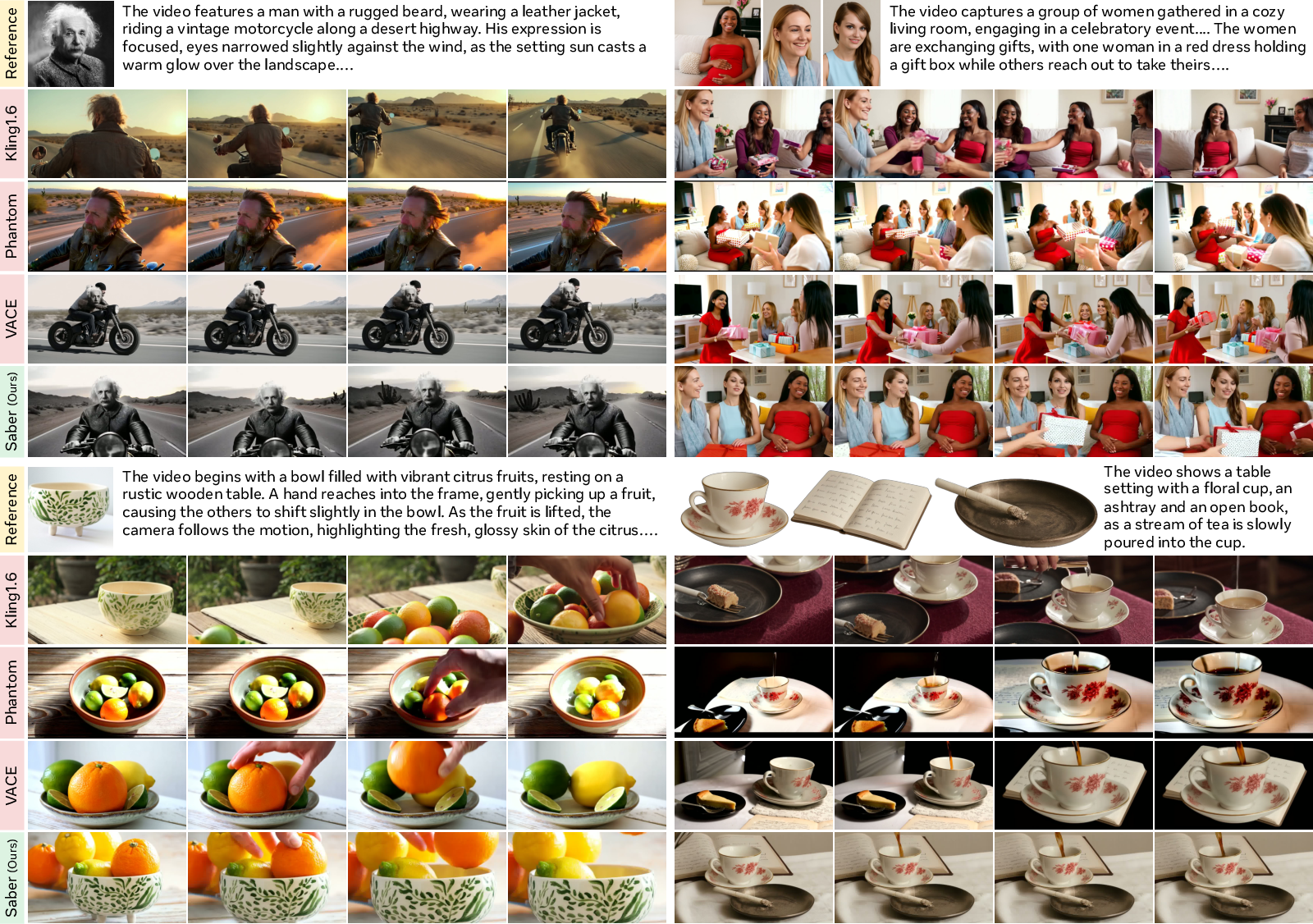
- Saber beat several strong methods trained on specialized reference-to-video datasets on a public benchmark called OpenS2V-Eval.
- It achieved the best score on “subject consistency” (called NexusScore), which means it’s very good at keeping the same identity and appearance across the video.
- It also did well on visual quality, smooth motion, and how well the video matches the text prompt.
- Saber works with different numbers of reference images (one or many) and can handle both foreground subjects (like a face or an object) and full backgrounds (like a room or landscape).
- Interesting extra abilities appeared:
- Multiple views of the same subject: If you provide front, side, and back photos of the same robot, Saber combines them into a single, coherent subject in the video.
- Strong alignment between text and references: If you change the text (like swapping clothing colors or positions of people), Saber updates the video accordingly while keeping the referenced identities.
Why does this matter? (Impact and future directions)
- Scalable training: Saber shows you don’t need costly, complex “reference-image + video + text” datasets to build a good reference-to-video generator. Training on widely available video-text data works, making it much easier to scale and improve over time.
- Personalized media: It’s a step toward creating customized stories, virtual avatars, and videos featuring your chosen people or objects, all controlled by simple text prompts.
- Better generalization: The masked training approach teaches the model to handle many different subjects and scenarios, including multiple references and backgrounds.
Limitations and next steps:
- Too many reference images (like a dozen or more) can confuse the model, causing messy compositions.
- More precise control over motion and timing in complex prompts is still challenging.
- Future work can focus on smarter ways to combine many references and on better tools for fine‑grained motion and scene control.
In short, Saber is a practical, scalable way to make videos that include and respect the look of specific subjects, guided by text, without relying on special, hard-to-build datasets.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The following points identify what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research:
- Sensitivity to segmentation quality at inference: quantify how errors from BiRefNet or alternative segmenters (Grounded-SAM, SAM2, SeMask) affect subject identity fidelity, artifact rates (e.g., gray halos), and OpenS2V metrics; evaluate segmentation-free variants and soft-masking approaches.
- Maximum number of references and collapse behavior: systematically characterize the failure threshold (e.g., K ∈ {1,2,4,8,12,16}), memory scaling, and attention saturation; develop mechanisms for reference selection, deduplication, and memory-efficient attention to avoid fragmented compositions.
- Motion control and temporal consistency: introduce explicit motion conditioning (action tokens, pose sequences, camera trajectories, optical flow targets) and assess improvements on MotionAmplitude and long-range temporal coherence beyond short clips; quantify identity drift in longer videos.
- Long-form generation: evaluate identity preservation, scene continuity, and artifact accumulation over extended durations (e.g., >20–60 seconds); study inference-time strategies (e.g., chunked denoising, temporal recurrence) for sustained coherence.
- Dataset and caption quality: analyze the impact of synthetic captions (Qwen2.5-VL) on cross-modal alignment and identity consistency; compare with human-labeled captions, noisy captions, and multi-sentence narratives; measure robustness to caption ambiguity and attribute conflicts.
- Domain generalization: test on rare/long-tail subjects (e.g., non-human entities, fine-grained categories, complex textures) and out-of-distribution scenes; provide failure taxonomies and per-category breakdowns to identify weak spots.
- Architectural generality: validate Saber’s masked training and attention-masking on other backbones (e.g., CogVideoX, HunyuanVideo, LTX-Video, Mardini); report transferability, required adaptations, and performance deltas.
- Injection strategy alternatives: compare temporal concatenation against other conditioning forms (context adapters, FiLM, side branches, learned fusion layers, LoRA-based adapters); ablate conditioning placement (early vs. mid vs. late layers) and noise levels for reference latents.
- Attention mask design: study soft/learned masks vs. binary masks to balance subject extraction with useful background context; explore dynamic gating based on saliency or segment confidence; measure trade-offs in artifact suppression vs. scene integration.
- Copy-paste artifact quantification: define objective metrics and benchmarks for copy-paste failures; evaluate the contribution of each augmentation (rotation, shear, scale, flip) and their ranges; optimize augmentation schedules and report failure rate reductions.
- Joint foreground and background referencing: develop a unified mechanism to combine subject references with background scene references in a single generation; design mask schemas and prompt grounding to avoid conflicts; evaluate on multi-element scenes.
- Reference quality and resolution: test robustness to low-res, noisy, occluded, truncated, or multi-object references; investigate multi-scale encoding and super-resolution pre-processing; report sensitivity curves for identity metrics vs. input quality.
- Compositional role grounding: build mechanisms to associate each reference to specific prompt entities (who/what/where) and roles (e.g., “the man in blue” vs. “the woman on the left”); evaluate on attribute swaps and positional changes with quantitative alignment metrics.
- 3D consistency and view synthesis: assess consistency under camera motion and viewpoint changes; investigate 3D-aware conditioning (e.g., canonicalization, mesh/NeRF priors, multi-view fusion) to reduce geometry drift and maintain appearance across views.
- Multilingual prompts and complex instructions: evaluate cross-lingual performance and prompts with nested conditions, temporal directives, or multi-sentence narratives; test alignment fidelity across languages and complex compositional text.
- Efficiency and scalability: profile memory, latency, and throughput as a function of reference count and video length; study sparse attention, token pruning, or cache mechanisms to reduce compute overhead of reference concatenation.
- Background fill strategy: compare zero/gray fills with alternatives (blurred background, noise, learned inpainting) for masked references; quantify their effects on edge artifacts and blending quality.
- Training without random shape masks: explore subject-aware mask generation during training (saliency, unsupervised segmentation, tracking) to better approximate real reference conditions; compare with current random-shape generator.
- Evaluation breadth: complement OpenS2V-Eval with human studies, user preference tests, and downstream task metrics; provide category-wise error analyses and qualitative failure modes (identity swaps, attribute misalignment, scene incoherence).
- Safety, ethics, and misuse: address risks around identity cloning, privacy, and unauthorized replication of real persons; investigate watermarking, consent mechanisms, and identity-protection filters; propose detection tools for misuse in generated videos.
- Reproducibility and data transparency: document training data composition (domains, licenses, biases), release mask-generation code and training recipes, and provide model checkpoints or distilled baselines to enable independent verification.
Glossary
- 3D-RoPE: A three-dimensional rotary positional embedding technique to improve attention mechanisms in video models. "PolyVivid~\citep{hu2025polyvivid} adds a 3D-RoPE enhancement and attention-inherited identity injection to reduce identity drift."
- Aesthetics: An automated metric assessing visual quality of generated videos. "We report automated metrics where higher scores indicate better performance, including Aesthetics for visual quality, MotionSmoothness for temporal coherence, MotionAmplitude for motion magnitude, and FaceSim for identity preservation."
- Attention mask: A mask that restricts attention to valid regions, preventing the model from attending to irrelevant background areas. "This strategy is complemented by a tailored attention mechanism, guided by attention masks, which directs the model to focus on reference-aware features while suppressing background noise."
- BiRefNet: A pre-trained segmentation network used to extract foreground subjects from reference images during inference. "During inference, we use BiRefNet~\citep{zheng2024bilateral} to segment the foreground subjects from the reference images."
- Classifier-free guidance (CFG): A generation technique that scales the influence of conditioning signals to improve fidelity and alignment. "Following the standard setting of Wan2.1~\citep{wan2025wan}, we generate videos with $50$ denoising steps and a CFG~\citep{ho2022classifier} guidance scale of $5.0$."
- Context adapter: A module enabling temporal-spatial feature interaction by processing reference images within a unified video generation framework. "VACE~\citep{jiang2025vace} introduces a context adapter to process reference images and enable temporal-spatial feature interaction within a unified framework."
- Copy-paste artifacts: Undesirable effects where content from reference images is directly pasted into generated frames without proper integration. "Mask augmentation techniques are further integrated to mitigate copy-paste artifacts common in reference-to-video generation."
- Cross-attention: A transformer mechanism that integrates conditioning information (e.g., text) with visual tokens to guide generation. "Each transformer block consists of a self-attention, cross-attention, and feed-forward (FFN) modules."
- Diffusion model: A generative model that iteratively denoises latent variables to synthesize data such as images or videos. "Wan2.1 trains the diffusion model using Flow Matching (FM), where the forward process linearly interpolates between data and noise."
- Diffusion Transformer: A transformer-based architecture tailored to diffusion processes for high-fidelity video generation. "More recently, large-scale models based on Diffusion Transformer~\citep{peebles2023scalable} and trained on massive video-text datasets~\citep{chen2024panda, wang2025koala} have achieved state-of-the-art, high-fidelity video generation~\citep{yang2024cogvideox, kong2024hunyuanvideo, chen2025goku, wan2025wan, gao2025seedance, zhang2025waver}."
- FaceSim: An identity-preservation metric evaluating how well generated faces match references. "We report automated metrics where higher scores indicate better performance, including Aesthetics for visual quality, MotionSmoothness for temporal coherence, MotionAmplitude for motion magnitude, and FaceSim for identity preservation."
- Feed-forward (FFN) module: The non-attentional component in transformer blocks that processes token-wise features. "Each transformer block consists of a self-attention, cross-attention, and feed-forward (FFN) modules."
- Flow Matching (FM): A training objective that learns the velocity field by interpolating between data and noise. "Wan2.1 trains the diffusion model using Flow Matching (FM), where the forward process linearly interpolates between data and noise."
- GmeScore: An automated metric measuring text-video alignment quality. "In addition, we use three OpenS2V-Eval metrics, NexusScore, NaturalScore, and GmeScore, which measure subject consistency, naturalness, and text-video alignment, respectively."
- Identity drift: Degradation or inconsistency of a subject’s identity across frames in generated videos. "PolyVivid~\citep{hu2025polyvivid} adds a 3D-RoPE enhancement and attention-inherited identity injection to reduce identity drift."
- Latent space: The compressed representation space produced by the VAE where videos are encoded for efficient processing. "we use the VAE to encode the video from pixel space into latent space, obtaining = { }$_{\hat{f}=1}^{\hat{F}$."
- LLaVA-based fusion module: A multimodal component based on LLaVA used to strengthen visual-text understanding for customized generation. "HunyuanCustom~\citep{hu2025hunyuancustom} employs a LLaVA-based~\citep{liu2023visual} fusion module and an image ID enhancement module to strengthen multimodal understanding and identity consistency."
- Mask augmentation: Spatial transformations applied to masks (and paired images) to disrupt trivial correspondences and reduce artifacts. "We integrate a series of spatial mask augmentations, effectively improving the visual quality of the generated videos."
- Mask generator: A procedure that creates binary masks with controlled foreground area and diverse shapes to simulate references. "we first use a mask generator to produce a binary mask ."
- MotionAmplitude: A metric quantifying the magnitude of motion in generated videos. "We report automated metrics where higher scores indicate better performance, including Aesthetics for visual quality, MotionSmoothness for temporal coherence, MotionAmplitude for motion magnitude, and FaceSim for identity preservation."
- MotionSmoothness: A metric assessing temporal coherence and smoothness of motion across frames. "We report automated metrics where higher scores indicate better performance, including Aesthetics for visual quality, MotionSmoothness for temporal coherence, MotionAmplitude for motion magnitude, and FaceSim for identity preservation."
- NaturalScore: A metric evaluating how natural and realistic the generated video appears. "In addition, we use three OpenS2V-Eval metrics, NexusScore, NaturalScore, and GmeScore, which measure subject consistency, naturalness, and text-video alignment, respectively."
- NexusScore: A metric focused on subject consistency across generated frames relative to references. "Among all sub-metrics, NexusScore best represents R2V performance by measuring subject consistency."
- OpenS2V-5M: A large-scale subject-to-video dataset containing image-video-text triplets used by prior R2V methods. "Existing R2V methods~\citep{zhou2024sugar, liu2025phantom, jiang2025vace, deng2025magref, fei2025skyreels, hu2025polyvivid, xue2025stand, li2025bindweave} typically rely on constructing explicit R2V datasets (\eg, OpenS2V-5M~\citep{yuan2025opens2v} and Phantom-Data~\citep{chen2025phantom}) that contain triplets of reference images, videos, and text prompts."
- OpenS2V-Eval: A standardized benchmark for evaluating reference-to-video generation methods. "We evaluate Saber on the OpenS2V-Eval~\citep{yuan2025opens2v} benchmark, where it consistently outperforms models~\citep{zhou2024sugar, liu2025phantom, jiang2025vace, deng2025magref, fei2025skyreels, hu2025polyvivid, li2025bindweave} that were explicitly trained on R2V data."
- Reference-to-video (R2V): A generation task that creates videos aligned with a text prompt while preserving subject identity from reference images. "Reference-to-video (R2V) generation aims to synthesize videos that align with a text prompt while preserving the subject identity from reference images."
- Self-attention: A transformer mechanism allowing video and reference tokens to interact and integrate features. "Each transformer block consists of a self-attention, cross-attention, and feed-forward (FFN) modules."
- Temporal compression ratio: The factor by which the VAE reduces the number of frames in latent space to lower computational cost. "Here, , where $4$ is the temporal compression ratio of the Wan2.1 VAE~\citep{wan2025wan}, , , and denote the height, width, and feature dimension of the video latent, respectively."
- Variational Autoencoder (VAE): A neural architecture that encodes videos into low-dimensional latents and decodes them back to pixels. "Our method builds on the Wan2.1-14B model~\citep{wan2025wan}, which consists of a variational autoencoder (VAE)~\citep{kingma2013auto}, a transformer backbone~\citep{vaswani2017attention, peebles2023scalable} and a text encoder (\ie, umt5-xxl~\citep{chung2023unimax})."
- Zero-shot: A setting where the model performs a task without being trained on explicit data for that task. "We bypass this bottleneck by introducing Saber, a scalable zero-shot framework that requires no explicit R2V data."
Practical Applications
Immediate Applications
The following applications can be deployed with current capabilities of Saber (zero-shot reference-to-video generation trained on video–text pairs) and standard tooling (e.g., segmentation models, GPU inference, prompt authoring).
- Personalized ad and creative production
- Sector: Media/advertising, social platforms
- What: Turn brand/product images into on-brief video ads and social posts while preserving identity (logos, packaging, mascots) and following a text prompt.
- Tools/workflows: Web service/API for batch creative generation; NLE plug-ins (Premiere/Final Cut/CapCut); A/B testing pipelines that vary prompts; asset libraries for references.
- Assumptions/dependencies: Rights to use brand assets; adequate reference segmentation (e.g., BiRefNet/SAM2); GPU inference capacity and QC for brand safety.
- E-commerce product videos at scale
- Sector: Retail, marketplaces
- What: Generate product showcase videos from catalog photos; swap backgrounds by toggling mask ratio to foreground/background reference modes; support multi-angle inputs for better fidelity.
- Tools/workflows: CMS/Shopify plug-in; automatic segmentation and resize/pad; templated prompts per category (shoes, furniture).
- Assumptions/dependencies: High-quality, consistent product photos; robust object segmentation for glossy/transparent items; throughput for bulk catalogs.
- Social content and UGC personalization
- Sector: Social media, creator economy
- What: Creator-facing apps where users supply selfies/props to produce short videos consistent with identity and prompt (e.g., multi-friend scenes).
- Tools/workflows: Mobile SDK/app integration; safety filters for sensitive prompts; preset styles; drag-and-drop references.
- Assumptions/dependencies: Consent and privacy controls; moderation and watermarking; mobile/cloud compute balance.
- Film/TV/games previsualization and storyboarding
- Sector: Entertainment, gaming
- What: Rapid previz of scenes using actor/prop references; multi-subject injection for cast continuity; generate cutscenes with character renders as references.
- Tools/workflows: DCC plug-ins (After Effects/Nuke/Blender); Unity/Unreal toolchains to export character renders as references; prompt libraries for cinematics.
- Assumptions/dependencies: Legal approvals for actor likeness; style matching to concept art; editorial QC.
- Instructor- and brand-aligned learning videos
- Sector: Education, corporate L&D
- What: Build explainer videos using an instructor’s or institution’s visual identity; insert lab equipment or diagrams from reference images.
- Tools/workflows: LMS plug-ins; templated prompts aligned to course outcomes; batch generation for lessons.
- Assumptions/dependencies: Rights and consent; pedagogical review; accessible captioning and alt content.
- Product support and documentation videos
- Sector: Software/hardware enterprises
- What: Turn product photos and UI screenshots into guided how-to videos; maintain exact product identity in visuals.
- Tools/workflows: Knowledge base integration; prompt templates per task; auto-segmentation for hardware shapes.
- Assumptions/dependencies: Up-to-date references; clear prompts; internal approval workflows.
- Synthetic data generation for computer vision
- Sector: CV/ML, robotics, AR
- What: Create identity-consistent videos for tasks like tracking, re-ID, or AR try-on; vary backgrounds via mask settings to widen domain coverage.
- Tools/workflows: Dataset generation scripts; prompt curricula for diverse motions; annotation overlays.
- Assumptions/dependencies: Domain gap to real data; licensing for training use; evaluation against target tasks.
- Academic research on scalable customization
- Sector: Academia/industrial research
- What: Study masked training strategies, attention masking, and generalization without triplet data; replicate and extend ablations.
- Tools/workflows: Open benchmark usage (OpenS2V-Eval/NexusScore); controlled experiments varying mask types/ratios; integration with different base T2V backbones.
- Assumptions/dependencies: Access to large video–text datasets; compute; reproducible pipelines.
- Policy, risk, and benchmark operations
- Sector: Policy, trust & safety
- What: Use Saber outputs to stress-test moderation, assess artifact risks (copy–paste avoidance), and refine evaluation metrics for subject consistency.
- Tools/workflows: Integration with provenance/watermarking; red-team prompt suites; governance dashboards.
- Assumptions/dependencies: Watermark standards; legal frameworks; access controls and audit logs.
- Developer APIs and editor integrations
- Sector: Software/IT
- What: Offer REST/gRPC endpoints for multi-reference R2V; provide segmentation-and-prepare utilities (resize/pad, mask injection) as SDKs.
- Tools/workflows: Reference ingestion pipelines; queuing for batch jobs; observability for prompt/reference mismatch.
- Assumptions/dependencies: Model licensing (Wan2.1-14B or alternatives); GPU scaling; prompt safety classifiers.
- Rapid UX/design prototyping
- Sector: Design, product marketing
- What: Generate concept videos featuring real product references for pitches and wireframes.
- Tools/workflows: Figma/PowerPoint plug-ins; style presets; quick-turn review loops.
- Assumptions/dependencies: Acceptable latency; brand compliance checks.
Long-Term Applications
These depend on further research, engineering, or ecosystem development (e.g., real-time performance, more robust motion control, multi-reference scaling beyond current limits).
- Real-time personalized avatars and streaming
- Sector: Live streaming, conferencing
- What: Live R2V that injects a user’s identity into on-the-fly video with prompt-driven scenes.
- Tools/workflows: Model distillation/acceleration (e.g., latent video transformers, low-step solvers), edge inference, latency-aware pipelines.
- Assumptions/dependencies: Significant speedups; on-device safety; resilient segmentation.
- In-engine dynamic cutscenes and player personalization
- Sector: Gaming, virtual production
- What: Generate story beats with player/asset identities during gameplay; integrate with motion control and physics.
- Tools/workflows: Unity/Unreal runtime plugins; motion priors; controllable diffusion for camera/motion.
- Assumptions/dependencies: Fine-grained motion control; real-time memory/VRAM budgets; artifact suppression in fast scenes.
- Healthcare communication and rehabilitation
- Sector: Healthcare
- What: Patient-specific educational or therapy videos using patient/clinician references to improve engagement and adherence.
- Tools/workflows: HIPAA/GDPR-compliant pipelines; consent/privacy vaults; clinician prompt libraries.
- Assumptions/dependencies: Ethical approval; safety evaluation; clinical validation of efficacy.
- Robotics and policy learning via tailored synthetic video
- Sector: Robotics, autonomous systems
- What: Generate videos of specific robots/environments for perception or policy pretraining with consistent identity and varied contexts.
- Tools/workflows: CAD-to-reference renderers; curriculum prompts; domain randomization schedulers.
- Assumptions/dependencies: Bridging sim2real gap; alignment with downstream tasks; IP for mechanical designs.
- Multimodal referencing (audio, motion, CAD)
- Sector: Media tech, design/engineering
- What: Extend references beyond images to voice timbre, motion capture, or CAD models for richer control and fidelity.
- Tools/workflows: Cross-modal encoders and attention; data pipelines for paired modalities; prompt+control mixers.
- Assumptions/dependencies: New architectures; curated multimodal datasets; synchronization benchmarks.
- 3D-aware or volumetric R2V
- Sector: AR/VR, virtual production
- What: Enforce view-consistent subject geometry across frames and cameras for XR experiences.
- Tools/workflows: 3D-aware diffusion or neural fields; multi-view supervision; camera path conditioning.
- Assumptions/dependencies: Research breakthroughs in 3D-consistent video generation; more compute; new datasets.
- Large-scale multi-reference composition (>12 refs)
- Sector: Media/entertainment, enterprise
- What: Complex scenes with many branded assets and people, maintaining coherent composition and interactions.
- Tools/workflows: Hierarchical attention and reference grouping; memory-efficient token routing; per-subject constraints.
- Assumptions/dependencies: Addressing current collapse beyond many references; better identity disentanglement.
- Public service and e-government outreach
- Sector: Government, NGOs
- What: Localized informational videos incorporating community-specific signs/landmarks as references.
- Tools/workflows: Localization prompt banks; compliance review; accessibility-by-design (captions, ASL).
- Assumptions/dependencies: Policy oversight; platform trust; provenance tagging.
- Accessibility (e.g., sign-language personalization)
- Sector: Accessibility, education
- What: Generate sign-language content using a signer’s identity for personalization and consistency.
- Tools/workflows: Motion-aware control; quality assessment with domain experts.
- Assumptions/dependencies: High motion fidelity; cultural and linguistic accuracy; community validation.
- Enterprise DAM and compliance integration
- Sector: Brand management, legal
- What: End-to-end pipelines tying approved digital assets to generation (asset whitelisting, rights management).
- Tools/workflows: DAM/MDM connectors; prompt validation via LLMs; audit trails and usage analytics.
- Assumptions/dependencies: Robust permissions; watermark/provenance standards; legal review automation.
- Marketplaces for R2V templates and presets
- Sector: Creator economy, SaaS
- What: Template packs that accept user references (people, products) with curated prompts and motion styles.
- Tools/workflows: Template authoring tools; storefronts; usage telemetry and performance scoring.
- Assumptions/dependencies: IP enforcement; safe template reviews; standardized metadata.
Cross-cutting assumptions and dependencies
- Technical: High-memory GPUs for 14B-class backbones; reliable segmentation (e.g., BiRefNet); high-quality video–text datasets; prompt engineering expertise; latency/throughput trade-offs.
- Legal/ethical: Consent for identities; IP rights for brand/product images; clear labeling/watermarking; platform and jurisdictional compliance.
- Quality: Artifact detection and rejection; human-in-the-loop review for high-stakes use; benchmark-driven QA (OpenS2V-Eval).
- Productization: Robust APIs/SDKs; monitoring for reference–output mismatch; content moderation and abuse prevention.
Collections
Sign up for free to add this paper to one or more collections.

