- The paper presents a novel framework that extends single-shot T2V models to support narrative multi-shot video generation with explicit positional control.
- It introduces two innovative RoPE variants for precise shot transitions and spatiotemporal grounding, enhancing both subject motion and scene consistency.
- Experimental results show improved text-video alignment, inter-shot coherence, and measurable gains in narrative quality and visual performance.
MultiShotMaster: A Controllable Multi-Shot Video Generation Framework
Framework Overview and Motivations
MultiShotMaster introduces a comprehensive framework for controllable multi-shot video generation, extending the capabilities of pretrained single-shot text-to-video (T2V) architectures by leveraging novel positional encoding mechanisms and spatiotemporal grounding strategies. The key motivation is to bridge the gap between existing single-shot video generation approaches—which rely heavily on text prompts and lack narrative or structural coherence across multiple shots—and the requirements of practical content creation workflows, which necessitate precise control over shot boundaries, subject appearances, and scene consistency.
A central architectural contribution is the manipulation and extension of Rotary Position Embeddings (RoPE) in the transformer attention modules. The framework introduces two RoPE variants:
- Multi-Shot Narrative RoPE: Implements explicit phase shifts at shot boundaries, allowing flexible arrangement and precise control of shot transitions without introducing additional trainable parameters or interfering with pretrained attention dynamics.
- Spatiotemporal Position-Aware RoPE: Enables fine-grained control by injecting reference tokens (subject images, background images) at specified spatiotemporal positions via region-specific RoPE application, facilitating customized subject motion and scene consistency.
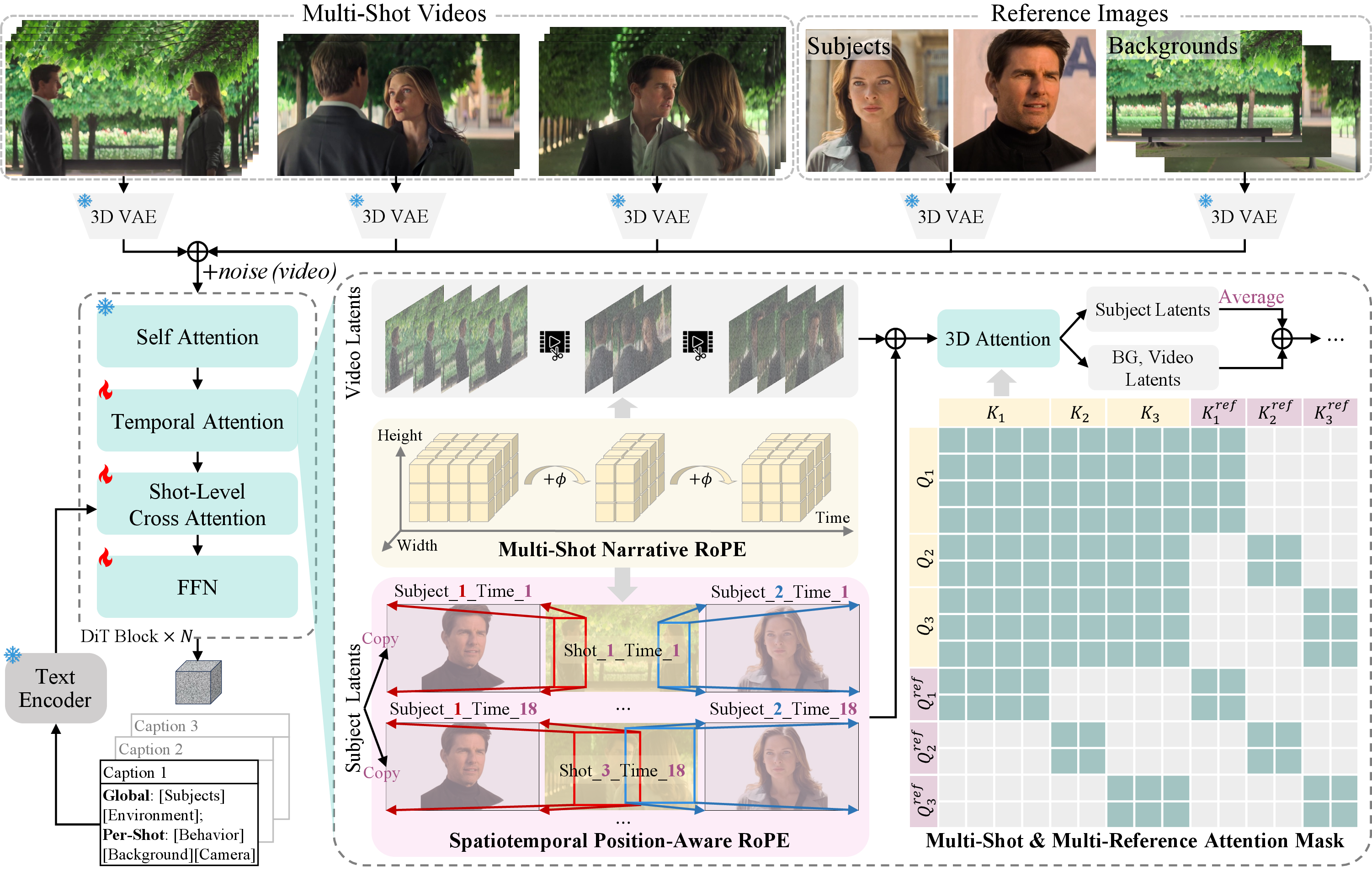
Figure 1: Overview of MultiShotMaster architecture, highlighting the integration of narrative and position-aware RoPE variants and the multi-reference attention mask for advanced controllability.
To further optimize inter-shot information flow and reference injection, the framework utilizes a hierarchical prompt structure (global caption and per-shot captions), a multi-reference attention mask, and a hierarchical multi-shot data annotation pipeline.
Data Curation and Annotation Process
The quality and consistency of training data are critical for narrative and controllable multi-shot video generation. MultiShotMaster incorporates an automated data pipeline involving:
- Shot boundary detection: Using TransNet V2 to segment lengthy source videos into discrete shots.
- Scene clustering and sampling: Aggregating shots into scenes based on storyline coherence and sampling multi-shot sequences with prioritized diversity.
- Hierarchical caption generation: Employing Gemini-2.5 for detailed global and per-shot captioning, enabling precise cross-shot subject, background, and action annotations.
- Reference extraction: Integrating YOLOv11, ByteTrack, and SAM for subject tracking/segmentation, augmented with Gemini-2.5 for cross-shot identity grouping and OmniEraser for clean background extraction.
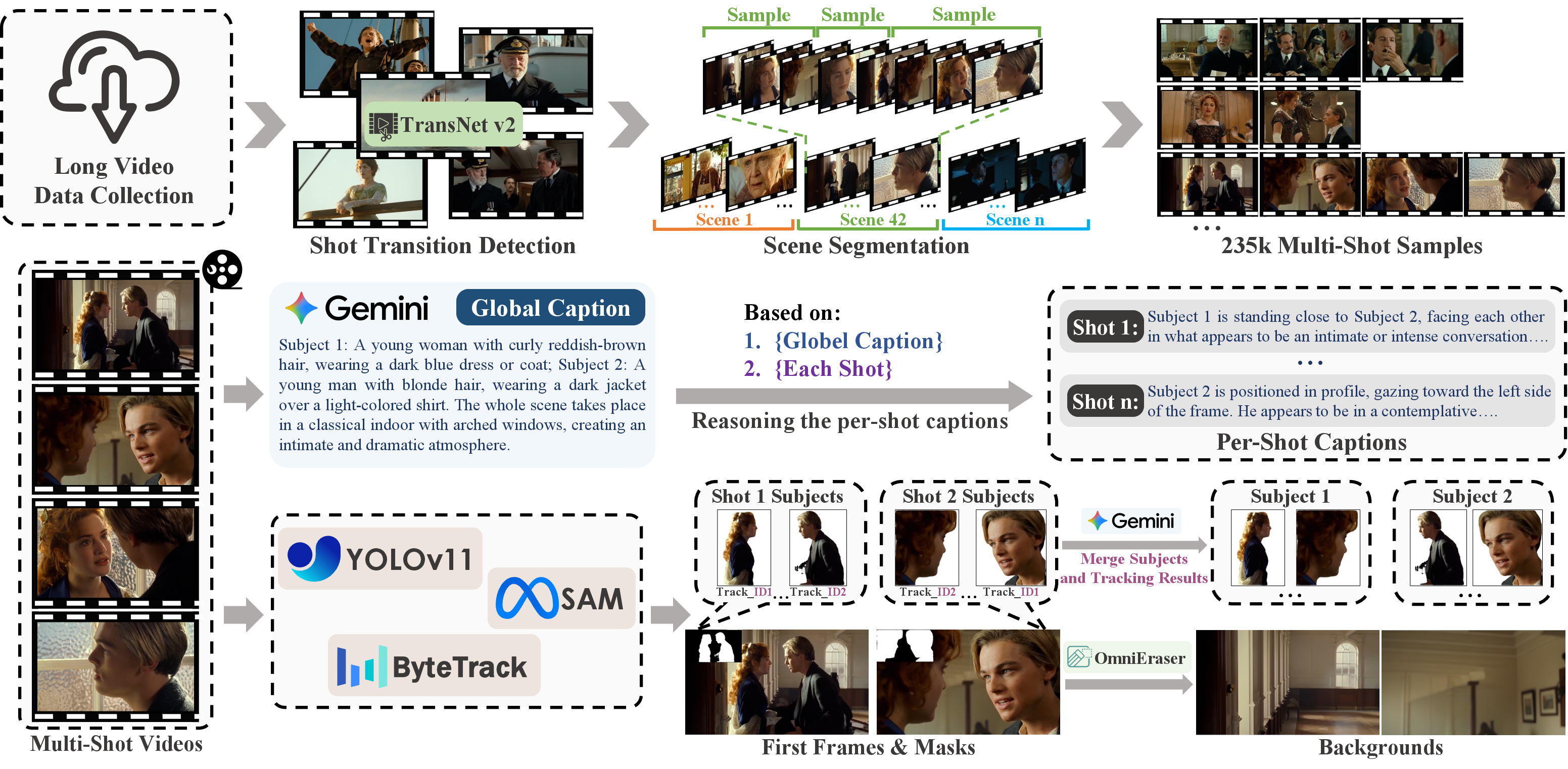
Figure 2: Multi-stage data curation pipeline, enabling robust annotation of shots, subjects, backgrounds, and hierarchical captions for training.
This pipeline ensures that the model is exposed to richly annotated, context-aware training samples, supporting the controllability objectives of the framework.
Spatiotemporal Grounded Reference Injection
MultiShotMaster enables in-context injection of reference images (for both subjects and backgrounds) and explicit motion control by associating reference tokens with specific spatiotemporal regions in the latent space. Through specialized adaptations of 3D RoPE, reference tokens are assigned position indices corresponding to target bounding boxes at designated time steps, ensuring that the attention weights are maximized for semantically aligned pixel regions.
To control subject trajectories, multiple copies of subject tokens are generated, each with unique spatiotemporal RoPE encoding. The value components are averaged post-attention across copies, allowing precise modeling of dynamic character movements within and across shots. Background tokens are handled analogously, supporting shot-level scene customization and multi-shot scene consistency.
The concatenation of multiple reference images and shot-specific video latents can dramatically expand context length, leading to unnecessary interactions and computational overhead. To address this, MultiShotMaster implements a multi-reference attention mask that selectively allocates attention. Each shot accesses only its associated reference tokens while maintaining global attention among video tokens for overall inter-shot coherence. This architectural choice ensures that context leakage is minimized and reference injection is locally precise while still supporting holistic narrative consistency.
Training Regime and Inference Architecture
The training paradigm is multi-stage:
- Stage 1: Finetuning for spatiotemporal reference injection on single-shot videos (300k samples).
- Stage 2: Joint training on curated multi-shot data, updating temporal and cross-attention modules and FFN.
- Stage 3: Subject-focused post-training, applying increased loss weight to subject regions to enforce robust identity consistency across shots.
At inference, the model supports flexible shot count and duration, hierarchical prompt parsing, and enables simultaneous controllable injection of texts, subjects, backgrounds, and grounding signals.
Experimental Results and Quantitative Analysis
MultiShotMaster demonstrates strong quantitative and qualitative results across a suite of evaluation metrics:
Notably, the method maintains cross-shot subject appearance and scene attributes, even in cases where backgrounds occupy small regions or subjects have complex trajectory specifications.
Limitations and Directions for Future Research
Despite the advantages, several limitations remain:
Future directions include integrating independent camera control mechanisms, scaling the approach to higher-resolution large-scale models, and exploring finer-grained motion and scene compositionality.
Conclusion
MultiShotMaster establishes an effective paradigm for controllable, narrative multi-shot video generation by extending transformer-based T2V models with novel RoPE variants, robust data annotation, and contextually-aware attention mechanisms. The strong results across text alignment, cross-shot consistency, and user-driven controllability imply significant potential for practical film and media generation workflows. The framework’s approach to spatiotemporal-grounded reference injection is extensible to broader multimodal generative tasks, and further research into disentangling camera and object motion could catalyze the next generation of AI-driven cinematic content creation.



