From System 1 to System 2: A Survey of Reasoning Large Language Models
Abstract: Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational LLMs excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI's o1/o3 and DeepSeek's R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \href{https://github.com/zzli2022/Awesome-Slow-Reason-System}{GitHub Repository} to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is a big, easy-to-read map of how today’s AI moves from “fast thinking” to “slow thinking.” Fast thinking (called System 1) is quick and intuitive—good for simple questions. Slow thinking (System 2) is careful, step-by-step reasoning—good for hard problems like tricky math, writing code, planning, and medical questions. The authors explain how new “reasoning” LLMs (like OpenAI’s o1/o3 and DeepSeek’s R1) are getting better at slow thinking, how they’re built, how we test them, what works, what doesn’t, and where the field is going next.
The main questions the paper answers
The paper organizes the field and answers a few simple questions:
- What makes a “reasoning LLM” different from older, fast-thinking LLMs?
- Which ideas and tools help models think step by step (like a human solving a puzzle)?
- How do we actually build and train these models?
- How do we measure if they’re good at reasoning?
- What are the current limits, and what should researchers do next?
How the research is done and the key ideas (explained with everyday examples)
This is a survey, so the authors read many papers, compare them, and explain the big patterns. To make the topic clear, they start with the basics and then show how the parts fit together.
Here are the core ideas, with simple analogies:
- System 1 vs System 2
- System 1: like answering “What’s 2+2?”—instant and automatic.
- System 2: like solving a long algebra problem—slow, step-by-step, checking your work.
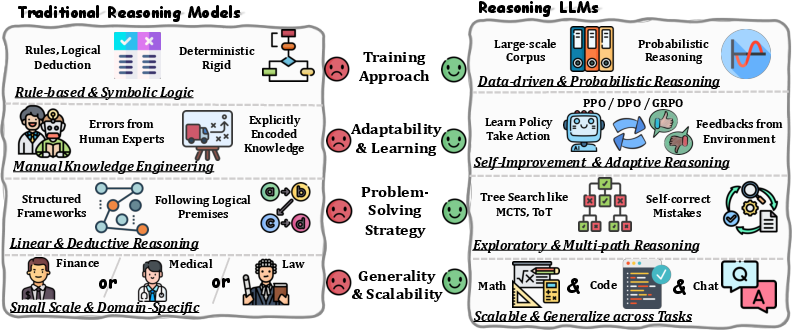
- Foundational LLMs vs Reasoning LLMs
- Foundational LLMs are great chatters—fast and fluent—but they can struggle with long, logical problems.
- Reasoning LLMs try to “think out loud,” exploring different paths, checking steps, and correcting mistakes.
- Symbolic logic (old-school AI rules)
- Think of this as if-then rules or a checklist: “If X, then do Y.” It’s strict and structured. Today’s models borrow the idea of making high-level plans (“macro actions”), like a checklist: “First define the variables, then factor, then solve.”
- Monte Carlo Tree Search (MCTS)
- Like playing chess in your head: try a move, imagine what happens next, keep the good paths, drop the bad ones. For AI reasoning, MCTS helps the model explore many solution paths and pick the best.
- Reinforcement Learning (RL)
- Learning by trial-and-error with points. Do something good? Get a reward. Do something bad? Learn to avoid it. Famous examples: AlphaGo and AlphaZero learned board games by practicing against themselves.
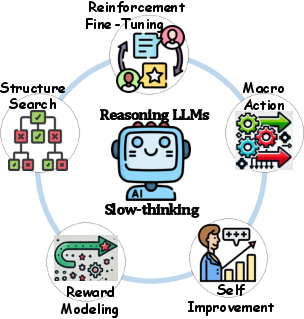
- Structure search (finding a good path to the answer)
- The model builds a “tree” of possible steps (like exploring all routes in a maze), then chooses the promising route. MCTS is a popular way to do this.
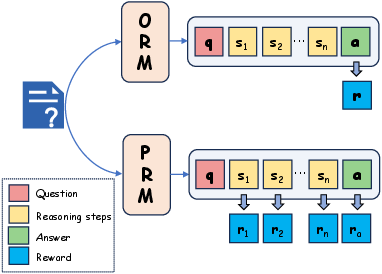
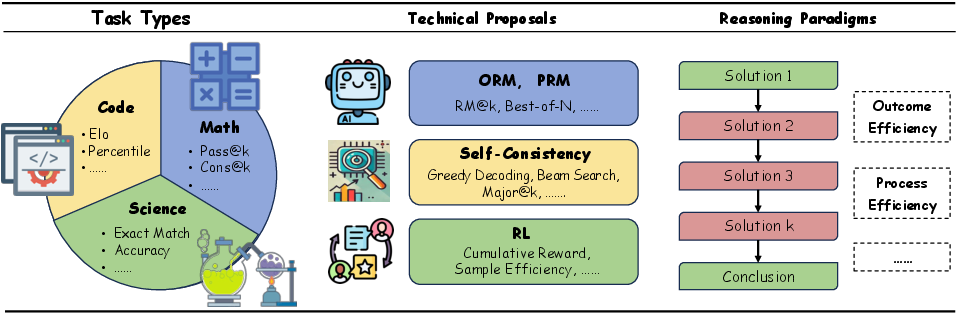
- Reward modeling (how to judge what’s “good thinking”)
- Two styles:
- Outcome Reward Model (ORM): Only grades the final answer. Like a teacher who only checks if the last answer is right.
- Process Reward Model (PRM): Grades each step. Like a teacher who checks your work line by line, so you learn where you went wrong. This helps models fix mistakes earlier.
- Self-improvement
- The model learns from its own attempts, refines its steps, and improves—similar to practicing a sport and reviewing your plays.
- Macro actions (high-level moves)
- Instead of typing every tiny step, the model uses smart shortcuts like “Summarize the problem,” “Try an example,” or “Check for mistakes.” This is like using a recipe’s main steps instead of describing every motion of your hands.
- Reinforcement fine-tuning
- Use RL to tune the model so it prefers helpful, accurate, step-by-step reasoning, not just fast guessing.
What the paper finds and why it matters
The authors summarize trends seen across many recent models:
- Reasoning models explore more and double-check themselves
- They often include mini-moves like “Wait,” “Hold on,” or “Let’s check,” which help catch mistakes.
- They try multiple solution paths before deciding, like a careful student.
- They write longer answers and take more time
- For hard math and code, they may generate thousands of tokens (lots of text) to reason things out.
- This helps on tough problems but can lead to “overthinking” on easy ones.
- They can be oddly cautious on simple tasks
- Even easy questions can trigger too much step-by-step thinking, which wastes time.
- Training can be surprisingly data-efficient—if the data is chosen well
- A small number of high-quality, hard, “think-aloud” examples can teach a lot.
- Sparse or simple reward signals can still work if the learning process is well designed.
- Bigger models benefit more
- Larger models handle complex, multi-step reasoning better and gain more from these techniques.
- MCTS helps—but it’s expensive
- Searching many paths boosts accuracy, but it can be slow and require lots of compute power.
- Grading steps (PRM) beats grading only the final answer (ORM) for complex problems
- PRM helps the model learn where and why it went wrong, making its reasoning clearer and more reliable.
- Benchmarks show real gains
- New reasoning LLMs reach strong results in math, code, multimodal tasks (mixing text and images), medicine, and more, often matching or approaching expert level on tough tests.
What this could change in the real world
If these ideas keep improving, we can expect:
- Better problem-solving tools
- Tutors that explain every step, coding assistants that debug and justify fixes, and medical AIs that reason carefully with evidence.
- More trustworthy AI
- Models that “show their work” are easier to trust and easier to fix when wrong.
- Smarter use of compute
- We need to balance deep thinking (slow but accurate) with speed (fast but riskier), especially in real-time applications.
- New research directions
- Design better rewards that match human reasoning.
- Make search (like MCTS) cheaper and faster.
- Build stronger multimodal reasoners (text, images, charts).
- Reduce overthinking on easy tasks.
- Improve safety and reduce bias using step-by-step checks.
In short, this survey shows how AI is moving from quick guesses to careful thinking. By combining planning (MCTS), trial-and-error learning (RL), step-by-step grading (PRM), and smart high-level moves (macro actions), reasoning LLMs are getting closer to human-like problem solving. The authors also provide a live GitHub resource to track new advances, making this a helpful guide for anyone building or evaluating the next generation of reasoning AI.
Collections
Sign up for free to add this paper to one or more collections.