Hyperparameter Transfer Enables Consistent Gains of Matrix-Preconditioned Optimizers Across Scales
Abstract: Several recently introduced deep learning optimizers utilizing matrix-level preconditioning have shown promising speedups relative to the current dominant optimizer AdamW, particularly in relatively small-scale experiments. However, efforts to validate and replicate their successes have reported mixed results. To better understand the effectiveness of these optimizers at scale, in this work we investigate how to scale preconditioned optimizers via hyperparameter transfer, building on prior works such as $μ$P. We study how the optimal learning rate and weight decay should scale with model width and depth for a wide range of optimizers, including Shampoo, SOAP, and Muon, accounting for the impact of commonly used techniques such as blocking and grafting. We find that scaling the learning rate according to $μ$P improves transfer, but can still suffer from significant finite-width deviations that cause drifting optimal learning rates, which we show can be mitigated by blocking and explicit spectral normalization. For compute-optimal scaling, we find scaling independent weight decay as $1/\mathrm{width}$ is nearly optimal across optimizers. Applying these scaling rules, we show Muon and Shampoo consistently achieve $1.4\times$ and $1.3\times$ speedup over AdamW for training Llama-architecture LLMs of sizes ranging from $190$M to $1.4$B, whereas the speedup vanishes rapidly with scale under incorrect scaling. Based on these results and further ablations, we argue that studying optimal hyperparameter transfer is essential for reliably comparing optimizers at scale given a realistic tuning budget.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a practical problem in training large neural networks: picking the right “settings” (hyperparameters) for different optimizers as models get bigger. The authors focus on newer “matrix‑preconditioned” optimizers (Shampoo, SOAP, and Muon) that can learn faster than the standard AdamW optimizer, especially on small models. But when people tried these new optimizers on bigger models, the results were mixed. The paper asks: Are we choosing the hyperparameters in the right way when we scale up?
Their main idea is that if you scale the hyperparameters (like the learning rate and weight decay) in a smart, consistent way across model sizes, these new optimizers do deliver reliable speedups—even for models with hundreds of millions to over a billion parameters.
Goals and Questions
The paper sets out to answer a few simple questions:
- How should we change the learning rate and weight decay when we train bigger or deeper models with matrix‑preconditioned optimizers?
- Can we find rules that let us “transfer” the best settings from a small model to a larger one without retuning everything?
- Do these rules actually help in real training, and do they make the new optimizers (Shampoo, SOAP, Muon) consistently faster than AdamW?
Methods and Approach (in everyday terms)
Here’s how the authors approached the problem:
- Think of training a neural network like teaching a class with different grade levels. The “hyperparameter transfer” idea is about taking teaching strategies that work for a small class (small model) and adjusting them in a predictable way so they also work for much larger classes (bigger models) without having to reinvent everything.
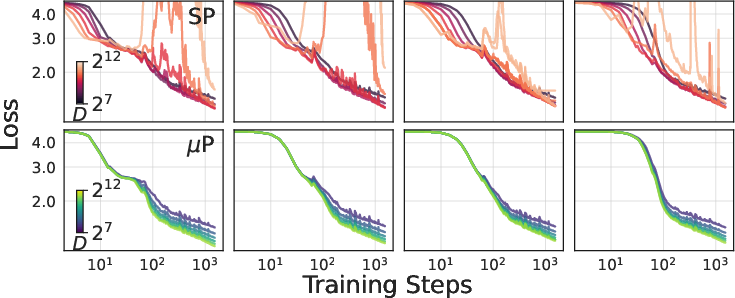
- They use a theory called Maximal Update Parameterization (µP). In simple words, µP gives a recipe for scaling the learning rate (how big each step is) depending on the model’s “width” (how many features are in a layer) and “depth” (how many layers).
- Width: More features per layer means you need to adjust step sizes so updates remain balanced.
- Depth: More layers means you should scale the effect of each residual block (a building block of transformers) so the whole model stays stable.
- Matrix‑preconditioned optimizers:
- AdamW changes each weight using element‑by‑element rules.
- Shampoo, SOAP, and Muon look at whole weight matrices and adjust the update using information about directions inside those matrices. Imagine steering not just by looking straight ahead (elementwise) but by looking at the whole road map (matrix), which can make learning faster per step.
- Two practical tools to make scaling work better:
- Blocking: Split large weight matrices into smaller blocks. This lowers overhead and reduces weird behavior that can happen in very wide models.
- Spectral normalization of updates: Scale each update so its “strength” (spectral norm) is controlled layer‑by‑layer. Think of it like making sure your steering wheel never turns too sharply, no matter how fast you’re going.
- They tested the rules on:
- Width scaling: making models wider.
- Depth scaling: making models deeper (transformers with more residual blocks).
- “Compute‑optimal” training: training each model for a number of tokens roughly proportional to its size (a common practice to use compute efficiently).
- They trained LLMs with Llama‑style architectures from about 190 million to 1.4 billion parameters on realistic datasets (OpenWebText, FineWeb) and compared AdamW to Muon and Shampoo.
Main Findings and Why They Matter
Here are the key results, explained plainly:
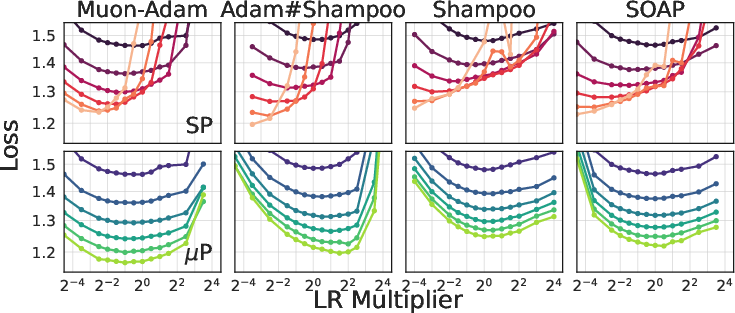
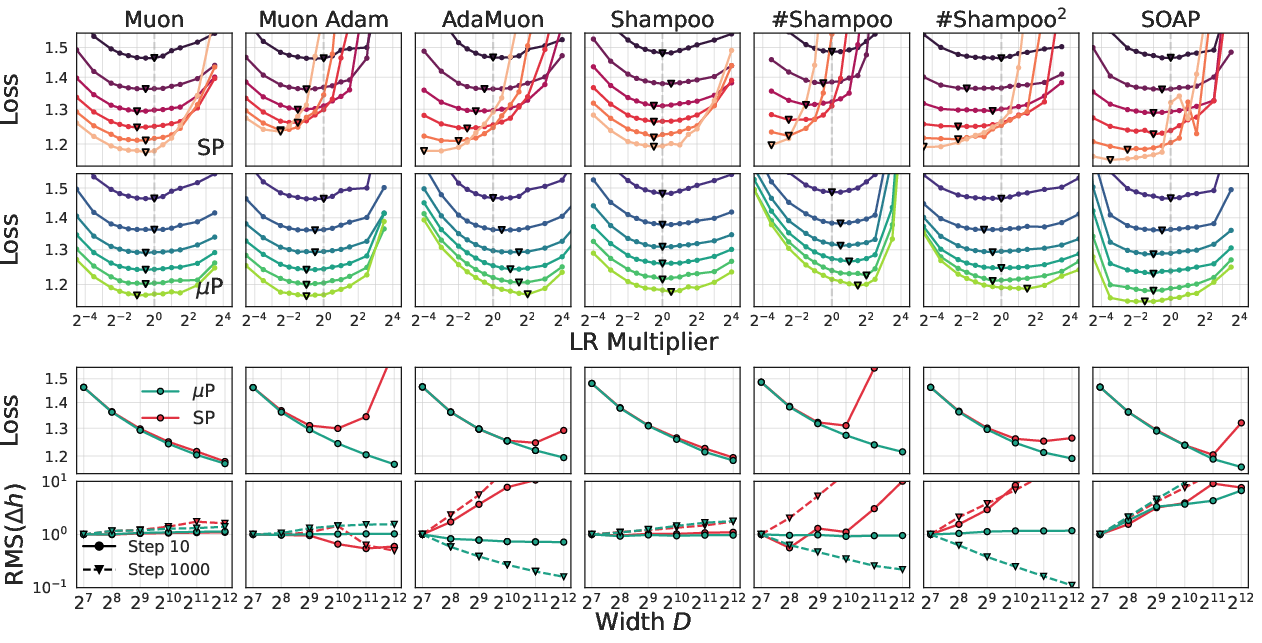
- Learning rate scaling (µP) helps across widths and depths:
- If you scale the learning rate as µP suggests, you can reuse good settings from small models on larger ones, and training remains stable.
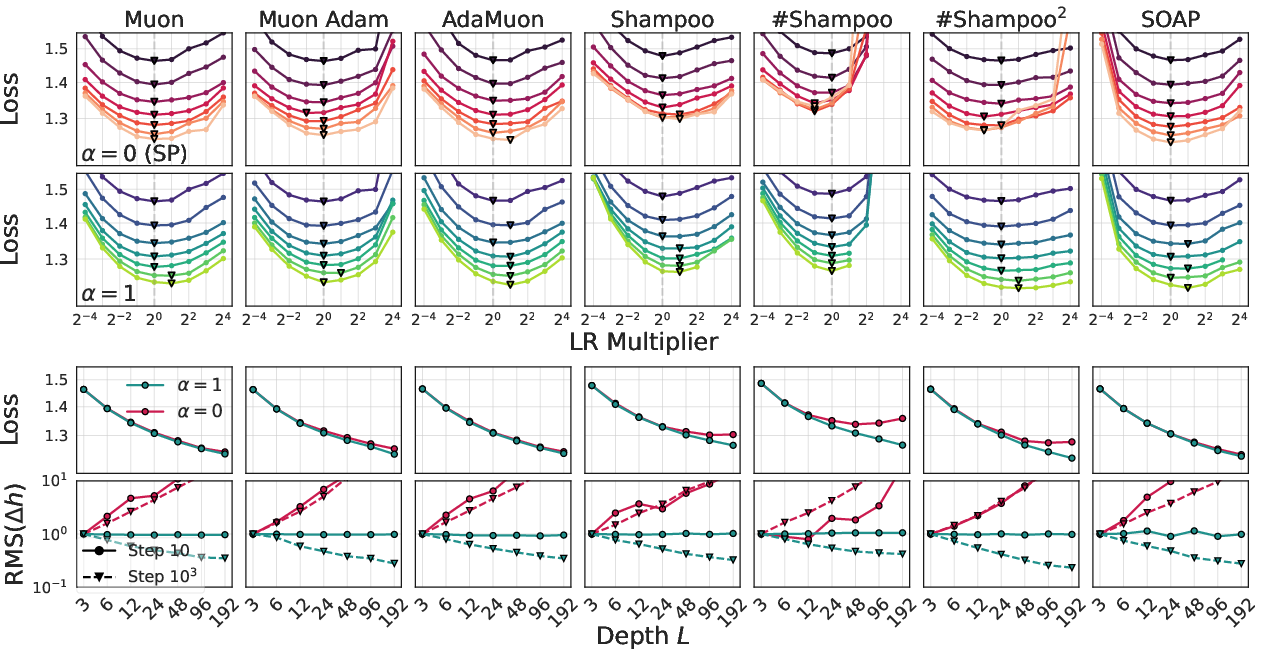
- For deep transformers, reducing each residual block’s output by 1/L (where L is the number of layers) and adjusting the learning rate accordingly keeps feature learning steady from shallow to deep models.
- Fixes for real‑world “finite width” issues:
- On real (not infinitely wide) models, some optimizers can show drifting “best” learning rates as width grows. Two fixes help a lot:
- Blocking (use fixed block sizes for matrix preconditioning).
- Spectral normalization (explicitly control the update strength per layer).
- These make the learning rate transfer more reliable and reduce sensitivity.
- Weight decay should shrink with width:
- The best “independent weight decay” (the L2 penalty decoupled from the step size) scales like 1/width across optimizers. This rule consistently worked better than keeping it constant.
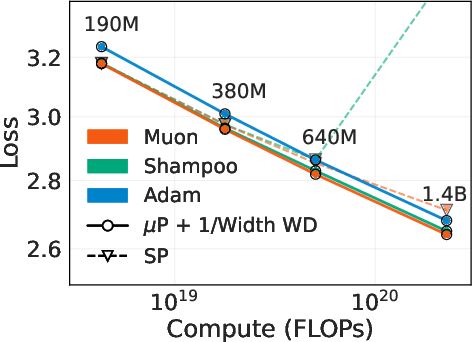
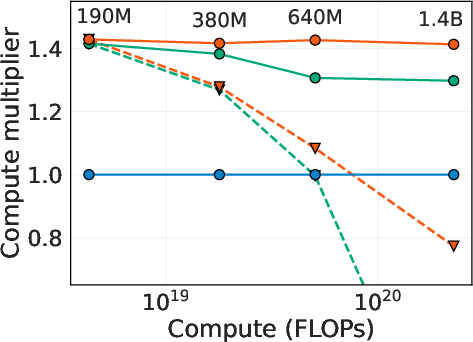
- Consistent speedups at scale:
- With the right scaling, Muon and Shampoo were reliably faster than well‑tuned AdamW:
- Muon: about 1.4× speedup.
- Shampoo: about 1.3× speedup.
- These speedups held from 190M up to 1.4B parameters.
- Without proper scaling (wrong learning rate or weight decay), those speedups quickly disappear as models get bigger.
- Optimizers change the “best” training ratio:
- IsoFLOP analysis suggests Muon’s faster learning means you often need fewer tokens per parameter (TPP) to reach the best accuracy for a fixed compute budget compared to Adam. In simple terms: Muon gets more out of each step, so the optimal training length is shorter.
Why it matters: A tiny change in validation loss can translate into big differences in compute needed (because loss-vs-compute scales slowly). Having reliable scaling rules is crucial for fair, accurate comparisons of optimizers—and for saving time and money when training large models.
Implications and Potential Impact
- Better, fair comparisons: If everyone uses consistent scaling rules, we can compare optimizers more fairly. Otherwise, “bad” hyperparameters can make a good optimizer look worse than it really is.
- Practical wins for large models: Muon and Shampoo can be real upgrades over AdamW at scale—but only if you pick the right learning rate and weight decay as models grow.
- Simpler tuning: You can tune on a small model, apply µP scaling, and then get near‑optimal behavior on larger models without doing massive sweeps.
- Design directions: The results suggest putting more emphasis on:
- Scaling rules that account for finite widths (not just theory for infinite width).
- Built‑in stability tools (blocking, spectral normalization) to make optimizers robust across sizes.
- Understanding why 1/width weight decay works so well across different optimizers.
In short: The paper shows that smart hyperparameter transfer unlocks the true potential of matrix‑preconditioned optimizers, delivering consistent speedups across model sizes. With better scaling, training LLMs can be faster and more compute‑efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, stated as concrete and actionable points for future research.
- Finite-width theory: Develop non-asymptotic analyses that capture realistic batch sizes, momentum, multi-step dynamics, and rank growth to explain when and why Maximal Update Parameterization (MUP) fails for expressive preconditioners (e.g., SOAP).
- SOAP scaling: Derive robust scaling rules for SOAP that account for dense eigenbasis-projected gradients at finite width and large batch sizes, and validate them empirically at scale.
- Update normalization design: Propose and test alternatives to RMS-based update normalization that avoid late-time undershooting of the spectral norm due to stable rank bottlenecks; quantify trade-offs with explicit spectral normalization.
- Spectral normalization at scale: Establish the computational, convergence, and generalization impacts of explicit spectral norm normalization in very large models (tens–hundreds of billions of parameters), including power-iteration accuracy, overhead, and stability.
- Compute-optimal LR scaling: Precisely characterize how optimal learning rate scales with width under compute-optimal training beyond ~10× width changes; e.g., fit and validate power-law corrections to MUP for matrix-preconditioned optimizers.
- Weight decay theory: Provide a theoretical justification for independent weight decay scaling as 1/width across optimizers, including its interaction with EMA timescales, and determine conditions under which alternative scalings outperform 1/width.
- Coupled vs independent weight decay: Systematically compare coupled and independent weight decay (and schedules) for Shampoo, SOAP, and Muon, and derive scaling prescriptions for each.
- Layer-wise scaling prescriptions: Formalize and validate per-layer scaling for embedding and readout layers (especially with large vocabularies), including when to use Adam, one-sided preconditioning, grafting, or blocking.
- Block size selection: Develop principled, possibly adaptive, block-size selection strategies (per layer and per width) that balance preconditioning quality, stability, and hardware efficiency; quantify their effect on scaling laws.
- Exponent tuning in Shampoo/SOAP: Determine optimal e_L and e_R choices across layers and model sizes; analyze sensitivity of scaling to these exponents and provide guidelines.
- Attention-specific scaling: Fully derive and test attention-specific scaling rules (e.g., 1/d_head vs 1/√d_head for logits), including multi-query attention, RoPE, and other transformer variants.
- Momentum effects: Extend scaling derivations to include momentum explicitly (for Adam-grafting, SOAP, Adafactor-like variants) and validate their impact on LR/WD transfer across steps.
- Grafting assumptions: Verify when the “LR scales as Q₁ under Q₁#Q₂” heuristic holds by analyzing stable-rank conditions; identify cases where grafting breaks LR transfer and propose corrections.
- Large-batch regime: Quantify how scaling behavior and speedups change with batch sizes typical of frontier LLM training (millions of tokens per step), including gradient noise scale and stable-rank dynamics.
- Wall-clock and systems constraints: Provide end-to-end wall-clock benchmarks (including optimizer transforms, memory bandwidth, communication, kernel efficiency) on GPUs and TPUs to validate that observed FLOP-based speedups translate to real training-time gains.
- Generalization beyond language modeling: Test scaling rules and speedups on other modalities (vision, multimodal), architectures (CNNs, MoE), and tasks (supervised/finetuning) to assess robustness.
- Depth scaling choices: Explore the impact of different residual multipliers (α in 1/Lα) for matrix-preconditioned optimizers, beyond α=1 (CompleteP), under both width-only and compute-optimal regimes.
- Very-large-scale validation: Evaluate whether the reported 1.3–1.4× speedups persist or change at much larger scales (tens–hundreds of billions of parameters), different sequence lengths, and longer horizons.
- Hyperparameter transfer reliability: Identify early-time indicators (e.g., “coordinate checks”) that reliably predict final compute efficiency for matrix-preconditioned optimizers; quantify their predictive validity.
- Epsilon (ε) scaling: Analyze sensitivity of regularization ε in Shampoo/SOAP to width/depth, block size, and training dynamics; provide robust ε scaling and defaults for stability.
- Preconditioning for non-2D parameters: Extend scaling rules and empirical validation to parameters that do not fit 2D matrix assumptions (e.g., convolutional kernels, embedding tables with factorization, gating in MoE).
- LR schedules: Study interaction between MUP-based LR scaling and typical schedules (warmup, cosine decay) for matrix-preconditioners; determine schedule-dependent corrections to scaling rules.
- Generalization outcomes: Assess whether improved compute efficiency (loss vs FLOPs) translates into better downstream performance (perplexity vs tasks), and whether spectral normalization or blocking affect generalization.
- Optimizer diversity: Validate proposed scaling rules for other matrix-preconditioned methods (K-FAC, PSGD) and mixed schemes (e.g., AdaMuon), beyond the brief derivations claimed to be “straightforward.”
- Stable-rank measurement: Develop practical methods to estimate update stable rank online and test normalization schemes that target stable-rank-aware spectral norms.
- IsoFLOP analysis breadth: Extend IsoFLOP studies to more optimizers, datasets, and training regimes to determine optimizer-dependent tokens-per-parameter optima and the role of LR/WD scaling in these optima.
- Attention to hardware constraints: Investigate how hardware topology (e.g., pipeline/tensor parallelism), communication overheads, and precision (FP8, BF16) interact with matrix preconditioning and scaling rules.
- Reproducibility and tuning budgets: Quantify sensitivity to tuning budgets, initialization seeds, and dataset shuffle; establish minimal tuning protocols that ensure fair optimizer comparisons at scale.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can be implemented now, derived from the paper’s findings on hyperparameter transfer for matrix‑preconditioned optimizers (Muon, Shampoo, SOAP) and finite‑width mitigation via blocking and spectral normalization.
- Industry (software, AI/ML, cloud): Upgrade LLM training pipelines to use the paper’s scaling rules
- What to deploy:
- Per‑layer learning‑rate transfer following the Maximal‑Update Parameterization (MUP) for matrix‑preconditioned optimizers, including width and depth rules (e.g., residual scaling by $1/L$ and LR adjustments).
- Independent weight decay scaled as () under compute‑optimal training.
- Blocking of matrix preconditioners (e.g., block sizes 128–512) to reduce overhead and improve finite‑width transfer.
- Optional spectral normalization of per‑layer updates via online power iteration (two mat‑vecs per layer) to stabilize learning rate transfer and reduce sensitivity.
- Expected impact:
- Consistent speedups versus AdamW across model sizes (e.g., Muon ≈ , Shampoo ≈ on 190M–1.4B Llama‑style models).
- Reduced hyperparameter sweep cost by tuning on a base (small) model and transferring.
- Tools/workflows:
- Integrate into PyTorch/JAX/TF trainers, Hugging Face Trainer, PyTorch Lightning, DeepSpeed/Megatron‑LM/FSDP.
- Use W&B Sweeps or internal AutoML with transfer functions from base to larger models.
- Assumptions/dependencies:
- Availability of correct Muon/Shampoo/SOAP implementations with efficient blocking; optimizer overhead is negligible or well‑optimized.
- Batch sizes and training horizons that resemble common LLM regimes; spectral normalization mat‑vec overhead is acceptable.
- Compute multiplier comparisons exclude optimizer transform FLOPs (consistent with prior work).
- Academia (ML research and reproducibility): Standardize benchmarking with hyperparameter transfer
- What to deploy:
- Adopt MUP‑based LR scaling and $1/D$ independent weight decay when comparing optimizers at scale.
- Apply residual branch scaling (CompleteP‑style, $1/L$) and depth‑aware LR rules across residual architectures.
- Use isoFLOP analyses to set tokens‑per‑parameter (TPP) based on optimizer (e.g., Muon tends to lower optimal TPP than Adam).
- Expected impact:
- Fair, robust optimizer comparisons that do not conflate tuning quality with algorithmic merit.
- More reproducible scaling studies, fewer contradictory conclusions caused by mis‑scaled hyperparameters.
- Tools/workflows:
- Publish code with default scaling functions; provide transfer checks (early‑time feature update “coordinate check”).
- Assumptions/dependencies:
- Benchmarks report scaling rules used; datasets and model families are comparable; small differences in loss translate to large compute estimates ( scaling exponent).
- Policy and operations (energy, procurement, sustainability): Compute‑planning and cost reduction using matrix‑preconditioned optimizers
- What to deploy:
- Use observed compute multipliers to estimate cost, energy, and time savings when switching from AdamW to Muon/Shampoo under proper transfer.
- Prioritize training configurations that align with compute‑optimal scaling (e.g., $1/D$ weight decay, LR transfer) when negotiating cloud budgets.
- Expected impact:
- Measurable reduction in FLOPs to reach target loss; improved scheduling and carbon accounting.
- Tools/workflows:
- Internal cost models and sustainability dashboards ingest optimizer choice and scaling rules.
- Assumptions/dependencies:
- Real runtime overheads of optimizers remain small; benefits persist at production batch sizes and sequence lengths.
- Applied sectors (healthcare, education, finance, robotics): Faster model training for domain‑specific NLP and multimodal models
- What to deploy:
- Apply Muon/Shampoo with LR/WD transfer to mid‑scale models (hundreds of millions to low billions of parameters) for clinical note analysis, educational assistants, financial document understanding, or robotics instruction models.
- Expected impact:
- Shorter training cycles, lower costs to reach target performance, enabling more frequent model refreshes.
- Tools/workflows:
- Sector‑specific pipelines built on Hugging Face/Lightning/DeepSpeed with transfer‑aware hyperparameter schedulers.
- Assumptions/dependencies:
- Domain data and tokenizers similar enough that scaling behaviors carry over; matrix preconditioners are implemented efficiently on available hardware.
- Engineering practice (tooling): Improve optimizer libraries and defaults
- What to deploy:
- Ship optimizer wrappers that encapsulate:
- Width/depth‑aware LR functions per layer for Muon/Shampoo/SOAP.
- $1/D$ independent weight decay scheduling under compute‑optimal training.
- Blocked preconditioning and optional spectral normalization toggles.
- Correct grafting behavior: when using Q1#Q2, scale LR as if using Q1 (assuming stable ranks have ratio ).
- Expected impact:
- “Plug‑and‑play” configurability that yields robust transfer without manual derivations.
- Tools/products:
- Open‑source packages or internal libraries for optimizer scaling (e.g., a “AutoMUP for Matrix Preconditioning” module).
- Assumptions/dependencies:
- Alignment with framework APIs; robust unit tests for transfer invariants and finite‑width checks.
Long-Term Applications
Below are use cases that benefit from further research, scaling, or ecosystem development before broad deployment.
- Frontier‑scale foundation model training (software/cloud, energy)
- Vision:
- Systematic adoption of matrix‑preconditioned optimizers with correct hyperparameter transfer for trillion‑parameter models, integrated with distributed training frameworks.
- Needs:
- Verified scaling at extreme widths/depths and very large batch sizes; refined corrections beyond first‑order MUP where finite‑width effects matter.
- Kernel‑level acceleration for preconditioning, power iteration, and spectral normalization (GPU/TPU/NPU).
- Assumptions/dependencies:
- Stable and low‑overhead implementations; robust scaling beyond 1.4B proven across diverse architectures and modalities.
- Automated hyperparameter transfer services (AutoML, MLOps)
- Vision:
- Platform features that learn transfer functions (LR, WD, residual scaling) from base models and continuously adapt them across changing width/depth/training horizons.
- Needs:
- Meta‑learning of transfer corrections under compute‑optimal regimes (beyond pure MUP), dynamic adjustment for batch size and training length.
- Assumptions/dependencies:
- High‑quality telemetry to fit transfer laws; standardized API hooks in trainers; validation on multiple datasets and architectures.
- Optimizer research: finite‑width‑robust matrix preconditioners
- Vision:
- New optimizers that bake in finite‑width guarantees (e.g., minimizing reliance on asymptotics), preserving gains without sensitive LR drift in late training.
- Needs:
- Theory linking stable rank, RMS normalization, and spectral constraints; practical designs that avoid SOAP‑style failure modes at realistic widths/batches.
- Assumptions/dependencies:
- Cross‑verification on large‑batch regimes, multiple preconditioners, and grafted variants.
- Standards and policy: reproducibility protocols and sustainability reporting
- Vision:
- Benchmarking standards that mandate hyperparameter transfer documentation (MUP depth/width rules, $1/D$ WD) and compute‑efficiency reporting (compute multipliers, isoFLOP curves).
- Needs:
- Community buy‑in (industry consortia, research conferences); alignment with emerging carbon accounting and AI governance frameworks.
- Assumptions/dependencies:
- Transparent compute logs; consistent treatment of optimizer overheads; sector‑specific metrics (e.g., tokens‑per‑parameter targets across tasks).
- Sector‑specific model economics (healthcare, education, finance, energy)
- Vision:
- Organizational planning models that incorporate optimizer‑aware training costs to justify frequent domain model updates and rapid iteration.
- Needs:
- Empirical validations in domain distributions (clinical notes, educational content, financial filings), and multi‑modal extensions.
- Assumptions/dependencies:
- Transferability of scaling rules to non‑text modalities; data and privacy constraints for frequent training.
- Education and workforce development
- Vision:
- Curricula and practitioner guides on matrix preconditioning, hyperparameter transfer, compute‑optimal scaling, and spectral normalization.
- Needs:
- Didactic materials, lab exercises, and open notebooks demonstrating small‑to‑large model transfer and isoFLOP planning.
- Assumptions/dependencies:
- Availability of accessible implementations and datasets; alignment with university and industry training programs.
Glossary
- AdaMuon: An optimizer that applies Adam updates to Muon’s orthogonalized gradient to combine spectral preconditioning with adaptive elementwise scaling. "AdaMuon \citep{si2025adamuon} applies Adam on top of Muon's orthogonalized gradient."
- Adafactor: A memory-efficient adaptive optimizer that factorizes second-moment estimates to reduce storage and computation. "Adam, Adafactor \citep{shazeer2018adafactor}, Lion \citep{chen2023symbolic}, etc.)"
- AdamW: A variant of Adam that decouples weight decay from the gradient-based update, improving generalization and tuning behavior. "AdamW \citep{loshchilov2017decoupled} continues to dominate deep learning workloads, including training frontier-scale LLMs \citep{dubey2024llama,yang2025qwen3,liu2024deepseek}"
- Blocking: A technique that partitions parameters (or gradients) into fixed-size blocks so matrix preconditioners operate on smaller submatrices, reducing overhead and improving stability. "To make Shampoo more practical, blocking \citep{shi2023distributed,anil2020scalable} partitions the parameter into sub-blocks, reducing the peak memory and compute overhead of the preconditioners."
- CompleteP: A depth-scaling scheme that multiplies residual outputs by 1/L and tunes learning rates to ensure nontrivial feature learning in each layer. "CompleteP \citep{dey2025don} uses to ensure nonotrivial feature learning in each layer, demonstrating better results in training deep transformers."
- Compute multiplier: A metric that quantifies speedup as the compute-efficiency gain relative to a baseline optimizer for achieving the same loss. "We quantify the speedup of each approach with its compute multiplier, which measures the compute-efficiency gain over AdamW (with $\ and scaled weight decay) for achieving the same loss (details in \Cref{app:compute-multiplier})."</li> <li><strong>Compute-optimal scaling</strong>: A regimen that co-scales model size and training steps to maximize performance per unit of compute, guiding hyperparameter transfer across scales. "For compute-optimal scaling, we find scaling independent weight decay as $1/\mathrm{width}$ is nearly optimal across optimizers."</li> <li><strong>Depth scaling</strong>: Adjusting residual block magnitudes and learning rates as model depth changes to maintain stable feature learning across layers. "Extending this idea to depth scaling, subsequent works have proposed to multiply the residual block output in transformers or other residual networks by $1/L^\alpha$ and scale the learning rate accordingly to ensure the magnitude of feature learning is stable across depth"
- Eigenbasis: The basis formed by the eigenvectors of a matrix; rotating updates into this basis can simplify or stabilize optimization. "recognizes that Shampoo effectively applies Adafactor in the preconditioner's eigenbasis and builds on this insight by applying Adam in this eigenbasis instead."
- Empirical Fisher: A data-dependent approximation to the Fisher information matrix derived from gradients, often used for preconditioning. "Besides Shampoo, K-FAC \citep{grosse2016kfac} and Preconditioned Stochastic Gradient Descent \citep{li2017preconditioned} also leverage structured-matrix approximations to the (empirical) Fisher as preconditioners."
- Frobenius norm: The square root of the sum of squared matrix entries; commonly used to normalize update magnitudes. "Grafting \citep{anil2020scalable, shi2023distributed, agarwal2020disentangling} normalizes the Frobenius norm of the Shampoo update by that of another optimizer, such as Adam, improving the stability."
- Grafting: A technique that matches the norm (often Frobenius) of one optimizer’s update to another’s to stabilize learning, e.g., Adam-grafting onto Shampoo. "Grafting \citep{anil2020scalable, shi2023distributed, agarwal2020disentangling} normalizes the Frobenius norm of the Shampoo update by that of another optimizer, such as Adam, improving the stability."
- IsoFLOP analysis: A procedure that explores model/data configurations with constant FLOPs to find the compute-optimal tokens-per-parameter ratio. "In \Cref{fig:isoflops}, we conduct IsoFLOP analysis to identify the optimal TPP for Adam and Muon"
- K-FAC: An optimizer that uses Kronecker-factored approximations of curvature (Fisher) matrices for efficient second-order preconditioning. "Besides Shampoo, K-FAC \citep{grosse2016kfac} and Preconditioned Stochastic Gradient Descent \citep{li2017preconditioned} also leverage structured-matrix approximations to the (empirical) Fisher as preconditioners."
- Kronecker-factored approximation: Approximating a large matrix (e.g., Fisher) as a Kronecker product of smaller matrices to reduce computation and storage. "The Shampoo preconditioner can be interpreted as a one-step Kronecker-factored approximation of the empirical Fisher using power iteration \citep{morwani2024new}."
- Master Theorem: A theorem governing the deterministic infinite-width limits of Tensor Programs, ensuring well-defined training dynamics as width grows. "the full training process admits a well-defined, deterministic infinite-width limit by the Master Theorem \citep{yang2023iv}"
- Matrix-preconditioned optimizer: An optimizer that applies matrix-level preconditioning (often per weight matrix) rather than elementwise scaling to accelerate convergence. "matrix-preconditioned optimizers apply matrix-level preconditioning to the gradient of 2D parameter matrices."
- Maximal-Update Parameterization: A scaling rule (μP) for hyperparameters with width/depth that ensures Θ(1) feature updates per layer, enabling robust transfer across scales. "The Maximal-Update Parametrization ($) \citep{yang2021infty} pioneered a series of work on hyperparameter (HP) transfer"</li> <li><strong>Muon</strong>: A spectral-norm-based optimizer that approximates UVᵀ from the gradient SVD and performs steepest descent in the spectral norm. "The Muon optimizer \cite{jordan2024muon} leverages this insight, using an iterative method to approximate $U V^\top$ directly, and can be viewed alternatively as steepest descent in the spectral norm."
- Power iteration: An iterative algorithm to estimate dominant eigenvectors/eigenvalues, used to build/approximate preconditioners. "The Shampoo preconditioner can be interpreted as a one-step Kronecker-factored approximation of the empirical Fisher using power iteration \citep{morwani2024new}."
- Preconditioner: A matrix or transformation applied to gradients to condition the optimization problem, improving stability and convergence speed. "The Shampoo preconditioner can be interpreted as a one-step Kronecker-factored approximation of the empirical Fisher"
- RMS-based update normalization: Normalizing updates to have a fixed root-mean-square magnitude, often via Adam-style second moments or grafting. "particularly when used with RMS-based update normalization (\Cref{fig:width-scaling})."
- Shampoo: A matrix-preconditioned optimizer that uses left/right curvature estimates to precondition gradients via (L+εI){-e_L} and (R+εI){-e_R}. "A representative example is Shampoo \citep{gupta2018shampoo,anil2020scalable, shi2023distributed}"
- SOAP: An optimizer that rotates gradients into the preconditioner’s eigenbasis and applies Adam in that basis. "SOAP \citep{vyas2024soap}, another Shampoo-inspired algorithm, recognizes that Shampoo effectively applies Adafactor in the preconditioner's eigenbasis and builds on this insight by applying Adam in this eigenbasis instead."
- Spectral norm: The largest singular value of a matrix, used to measure and control update magnitude in spectral methods. "can be viewed alternatively as steepest descent in the spectral norm."
- Spectral normalization: Explicitly constraining the update spectral norm (e.g., via power iteration) to achieve robust, finite-width learning-rate transfer. "Spectral normalization, as proposed in \citep{large2024scalable}, normalizes the update spectral norm to exactly, rather than asymptotically, $\sqrt{d_/d_},$"
- Stable rank: A scale-sensitive measure of effective matrix rank defined via norms, affecting spectral vs RMS-normalized update magnitudes. "Thus has a spectral norm $\Theta\qty(\sqrt{d_d_/\mathrm{srank}(U)})$ where denotes the stable rank."
- Steepest descent: An optimization method that moves in the direction of greatest decrease under a chosen norm; Muon uses steepest descent in spectral norm. "can be viewed alternatively as steepest descent in the spectral norm."
- SVD: Singular Value Decomposition; factorizes a matrix into UΣVᵀ and underlies Muon’s UVᵀ approximation of gradient directions. "where is the SVD of the gradient matrix."
- Tensor Program: A formalism for expressing training computations that yields deterministic infinite-width limits under the Master Theorem. "which shows that it can be expressed as a Tensor Program \citep{yang2023iv}."
- Tensor Program Master Theorem: See Master Theorem entry; governs infinite-width behavior of Tensor Programs. "the full training process admits a well-defined, deterministic infinite-width limit by the Master Theorem \citep{yang2023iv}"
- Tokens-per-parameter (TPP): The ratio of training tokens to model parameters; determines the compute-optimal training regime. "Optimizers that achieve faster convergence are likely to have a smaller compute-optimal tokens-per-parameter (TPP) ratio"
- Weight decay (coupled): A regularization applied within the adaptive update (as in AdamW’s decoupling discussion) that can be constant but suboptimal for some optimizers. "Thus, constant coupled weight decay happens to work well for AdamW, but can be highly suboptimal for other optimizers (e.g., Muon)."
- Weight decay (independent): A separate regularization term scaled independently of the optimizer’s adaptive components; often set proportional to inverse width. "For compute-optimal scaling, we find scaling independent weight decay as is nearly optimal across optimizers."
Collections
Sign up for free to add this paper to one or more collections.