Practical Efficiency of Muon for Pretraining
Abstract: We demonstrate that Muon, the simplest instantiation of a second-order optimizer, explicitly expands the Pareto frontier over AdamW on the compute-time tradeoff. We find that Muon is more effective than AdamW in retaining data efficiency at large batch sizes, far beyond the so-called critical batch size, while remaining computationally efficient, thus enabling more economical training. We study the combination of Muon and the maximal update parameterization (muP) for efficient hyperparameter transfer and present a simple telescoping algorithm that accounts for all sources of error in muP while introducing only a modest overhead in resources. We validate our findings through extensive experiments with model sizes up to four billion parameters and ablations on the data distribution and architecture.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a practical question: how can we train LLMs faster and more cheaply? The authors compare two ways to “teach” a model during training, called optimizers. The standard optimizer is AdamW. The new one, Muon, is a simple kind of second‑order optimizer. The paper shows that Muon lets you train faster without wasting data, especially when you use very large batch sizes (lots of data processed in one go across many devices). It also explains a clever way to pick good training settings (hyperparameters) for big models using a method called muP and a “telescoping” search strategy.
What questions did the researchers ask?
- Can Muon beat AdamW in a fair, practical comparison that considers both compute (how many devices and how much work they do) and time (how long training takes)?
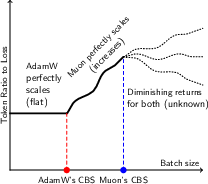
- Does Muon stay “data‑efficient” at very large batch sizes, meaning it reaches the same quality using fewer training tokens (pieces of text/code)?
- Can muP, a method for copying good training settings from small models to big models, work well with Muon?
- Is there a simple, low‑cost way to tune hyperparameters for big models reliably?
How did they do the research?
Comparing optimizers fairly: the compute–time tradeoff
Think of training as a race where you can pick:
- how many runners you use (devices),
- how big each stride is (batch size),
- and how much total energy you spend (compute).
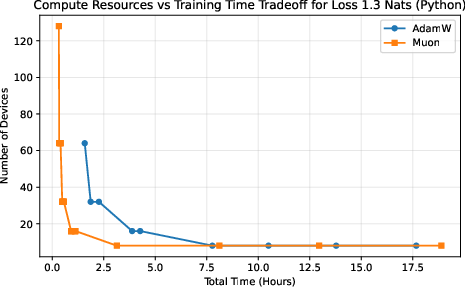
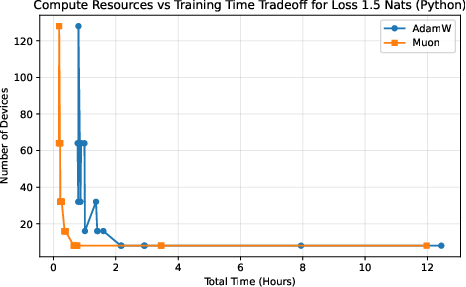
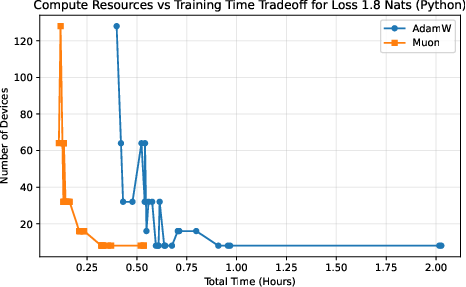
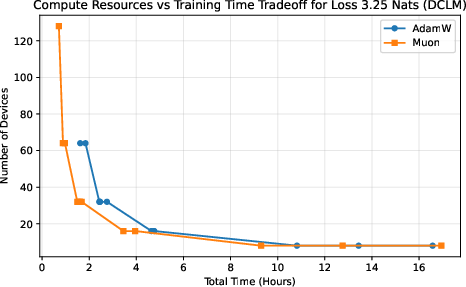
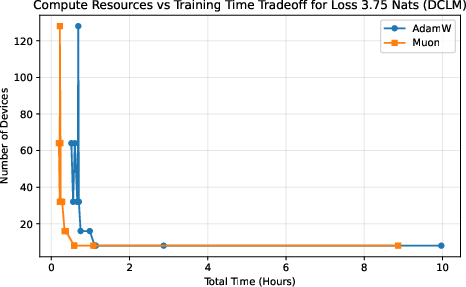
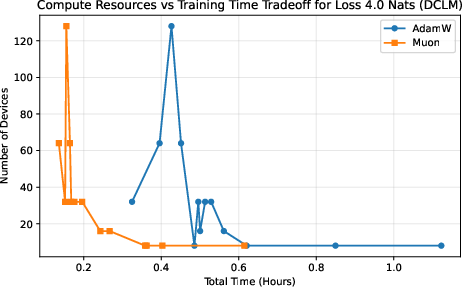
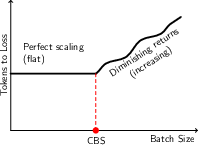
Different choices trade off training time against total cost. The authors plot “iso‑loss curves,” which are lines showing all the ways (different device counts and batch sizes) to reach the same target quality (loss). If Muon’s curve lies “better” than AdamW’s, it means Muon gives you strictly more options: either finish sooner with the same budget or spend less with the same finish time. This “frontier of best choices” is called the Pareto frontier.
What is Muon?
When you train a model, you repeatedly nudge its parameters in directions that reduce error—like finding the fastest way downhill on a landscape. AdamW looks at the slope (first‑order information). Muon looks a bit deeper at how the landscape curves and how parameters interact (second‑order flavor), but in a very simple way.
Muon’s update roughly says: “move in the single strongest direction suggested by the gradient, but keep the step well‑behaved.” It uses a fast trick (Newton–Schulz) to avoid expensive math and pairs with momentum and weight decay (common training tools). In practice, Muon only stores a small amount of extra information and adds little overhead, especially at large batch sizes.
Plain analogy:
- AdamW: a careful hiker using the slope to go downhill.
- Muon: a careful hiker who also notices the shape of the ground and steps in a more effective direction, without overthinking it.
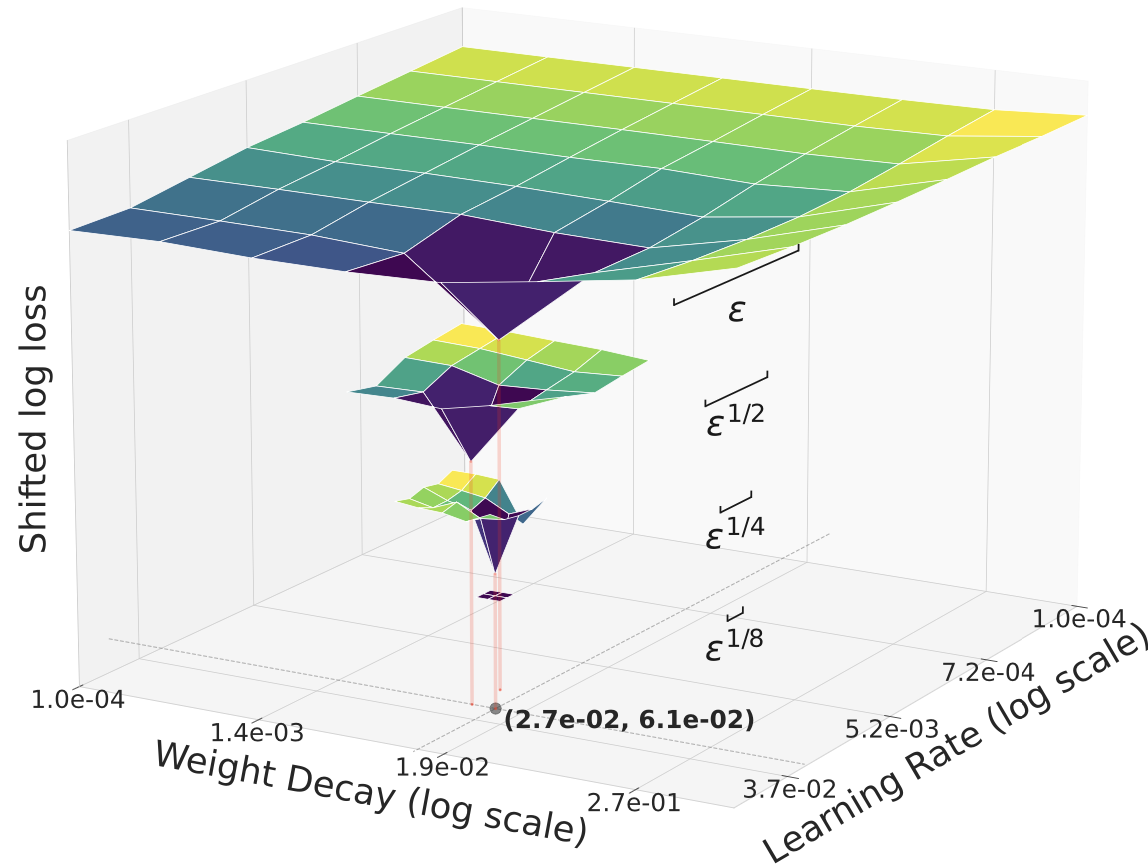
What is muP and the “telescoping” search?
Hyperparameters are the knobs you set before training (like learning rate and weight decay). Picking them for a huge model by brute force is very expensive. muP (maximal update parameterization) is a set of rules that help transfer good hyperparameters found on a small model to a larger one so they still work.
The “telescoping” algorithm is a practical tuning strategy:
- Start with a small model and do a wider hyperparameter search.
- Double the model’s width (make it bigger) and narrow the search range.
- Repeat a few times. Each stage costs about the same, and the total extra cost grows slowly, like C·log(N), where C is the cost of training the final big model and N is its width.
Analogy:
- muP: scaling a recipe from cooking for 2 people to 200 people without ruining the taste.
- Telescoping: zooming in on a map step by step to find the exact address, instead of searching the whole city every time.
What did they find and why is it important?
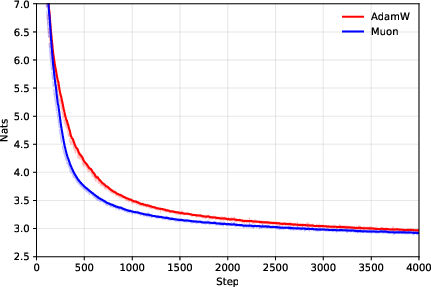
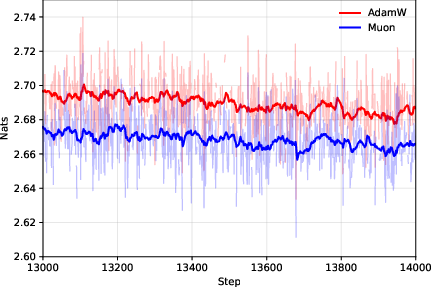
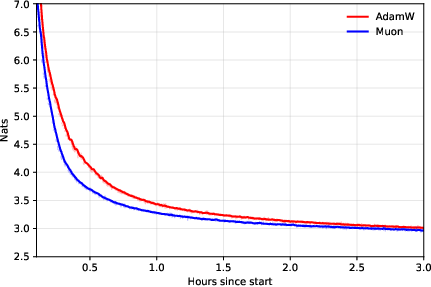
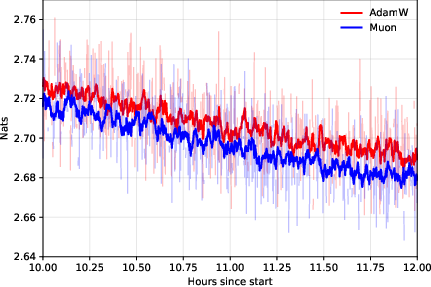
- Muon expands the compute–time Pareto frontier compared to AdamW.
- In simple terms: Muon gives you more “best choice” options—finish faster with the same compute, or use fewer devices for the same finish time.
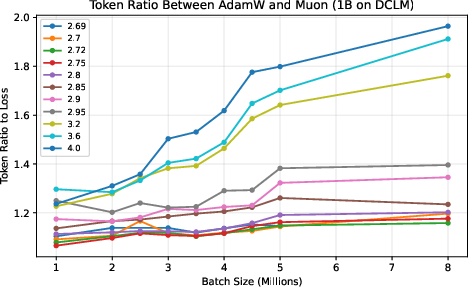
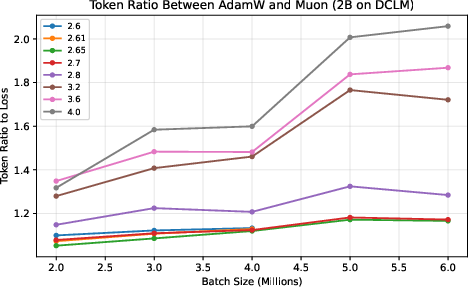
- Muon stays data‑efficient at very large batch sizes.
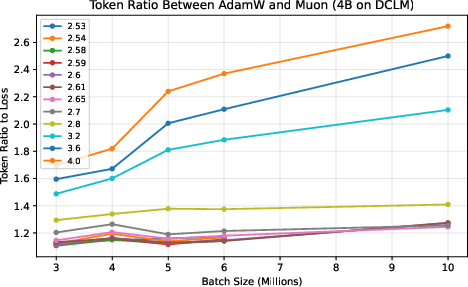
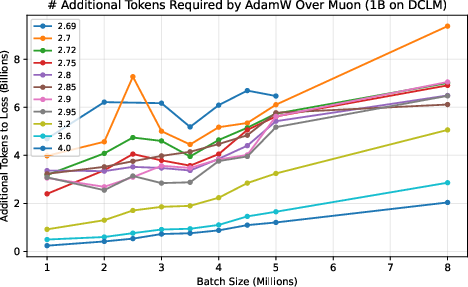
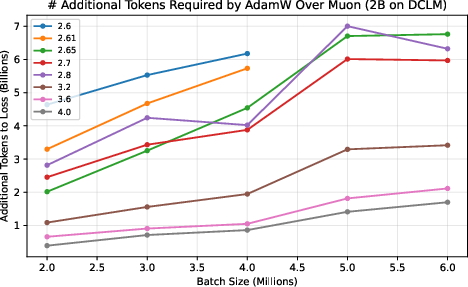
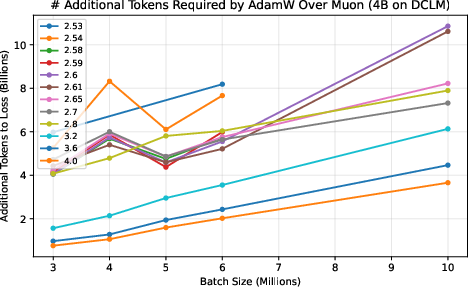
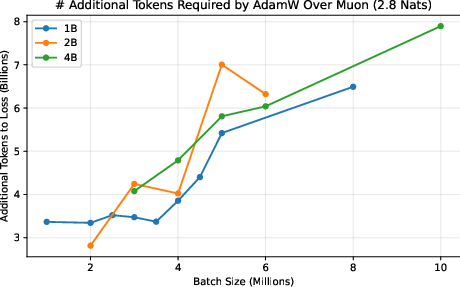
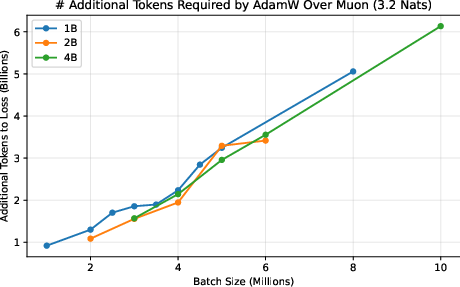
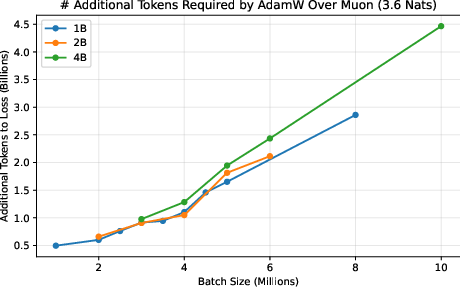
- They measure a “token ratio”: how many more tokens AdamW needs compared to Muon to reach the same quality.
- Across different model sizes (up to 4 billion parameters) and datasets (web text and Python code), Muon consistently needed about 10–15% fewer tokens. This advantage did not fade at huge batch sizes; it was flat or even grew as batch size increased.
- This matters because big training runs often use many devices and large batches to finish quickly. If your optimizer gets worse with bigger batches, you waste data and time. Muon doesn’t.
- Muon’s overhead is small and shrinks with larger batches.
- Even though Muon does a bit more math per update than AdamW, that extra cost becomes relatively smaller as batches get larger. Combined with fewer tokens needed, Muon wins in practice.
- muP works with Muon.
- The paper confirms that muP’s scaling rules transfer good settings cleanly from small to large models when using Muon, not just AdamW.
- Telescoping hyperparameter tuning is accurate and cheap.
- By narrowing the search each time the model width doubles, you keep tuning costs modest and still find near‑optimal settings.
- They validated this on models up to about 3.7B parameters, training up to 160B tokens at sequence length 8192, and achieved strong results with specific settings (learning rate and weight decay).
Why it’s important:
- Training large models is expensive. If you can reach the same quality with fewer tokens and less time, you save money and energy.
- If your optimizer works well at large batch sizes, you can scale across more devices without losing quality.
- If muP and telescoping reliably tune big models, you cut the time spent on trial‑and‑error.
Implications and impact
- For teams training LLMs, Muon is a practical drop‑in replacement for AdamW:
- It’s more flexible for resource planning because it remains data‑efficient at large batch sizes.
- It can reduce training time without increasing total compute.
- Combining Muon with muP and telescoping gives a unified recipe:
- Use Muon for optimization.
- Use muP to scale hyperparameters from small to big models.
- Use telescoping to fine‑tune those settings cheaply as you grow the model.
- Overall, this can make industry‑scale pretraining more economical and faster, helping organizations build capable models with lower cost and shorter timelines.
Key takeaways
- Muon lets you train faster or cheaper than AdamW at the same quality, especially with very large batch sizes.
- Muon needs fewer training tokens to reach the same loss, and this advantage doesn’t vanish as batch size grows.
- muP works with Muon, so you can transfer good hyperparameters from small models to big ones reliably.
- The telescoping search keeps tuning costs low while staying accurate, adding only a small, logarithmic overhead to the final training cost.
Collections
Sign up for free to add this paper to one or more collections.

