SceneDesigner: Controllable Multi-Object Image Generation with 9-DoF Pose Manipulation
Abstract: Controllable image generation has attracted increasing attention in recent years, enabling users to manipulate visual content such as identity and style. However, achieving simultaneous control over the 9D poses (location, size, and orientation) of multiple objects remains an open challenge. Despite recent progress, existing methods often suffer from limited controllability and degraded quality, falling short of comprehensive multi-object 9D pose control. To address these limitations, we propose SceneDesigner, a method for accurate and flexible multi-object 9-DoF pose manipulation. SceneDesigner incorporates a branched network to the pre-trained base model and leverages a new representation, CNOCS map, which encodes 9D pose information from the camera view. This representation exhibits strong geometric interpretation properties, leading to more efficient and stable training. To support training, we construct a new dataset, ObjectPose9D, which aggregates images from diverse sources along with 9D pose annotations. To further address data imbalance issues, particularly performance degradation on low-frequency poses, we introduce a two-stage training strategy with reinforcement learning, where the second stage fine-tunes the model using a reward-based objective on rebalanced data. At inference time, we propose Disentangled Object Sampling, a technique that mitigates insufficient object generation and concept confusion in complex multi-object scenes. Moreover, by integrating user-specific personalization weights, SceneDesigner enables customized pose control for reference subjects. Extensive qualitative and quantitative experiments demonstrate that SceneDesigner significantly outperforms existing approaches in both controllability and quality. Code is publicly available at https://github.com/FudanCVL/SceneDesigner.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “SceneDesigner: Controllable Multi-Object Image Generation with 9-DoF Pose Manipulation”
Overview: What is this paper about?
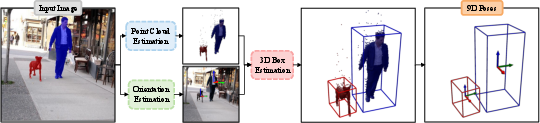
This paper introduces a tool called 3DSceneDesigner that lets people create images where multiple objects are placed exactly where they want, at the size they want, and facing the direction they want. Think of arranging furniture in a room or posing several toys on a table, then asking an AI to draw a realistic picture of it. The big deal here is full control over each object’s 9 “degrees of freedom” (9-DoF): position, size, and orientation.
Key goals and questions
The researchers set out to answer a simple but hard question: How can we tell an image-generation model exactly where to put multiple objects, how big they should be, and which way they should face—and have it obey those instructions reliably?
More specifically, they wanted to:
- Control 9 properties for each object: 3 for location (left-right, up-down, near-far), 3 for size (width, height, depth), and 3 for orientation (rotation around three axes—like pitch, yaw, and roll).
- Handle many objects at once, without mixing them up.
- Keep image quality high and make the method easy to use and generalize to lots of real-world scenes.
How did they do it? (Methods in simple terms)
They combined four main ideas. Here’s what they mean in everyday language:
1) A simple “3D label map” for objects: CNOCS
- Problem: Past methods either used 2D hints (like flat boxes) or needed detailed 3D models for each object category—both were limiting.
- Their idea: Wrap each object in a simple cardboard-like 3D box (a “cuboid”) and label the surfaces so the AI knows which part is which and how it’s turned.
- This labeling is called CNOCS (Cuboid Normalized Object Coordinate System). It’s like painting coordinates onto the cuboid so the model understands the object’s position, size, and direction from the camera’s viewpoint.
- Why this helps: It keeps enough 3D information to control orientation precisely, without needing exact 3D shapes for every object (which would be hard to get).
2) A new training dataset: ObjectPose9D
- They built a dataset that teaches the model how objects look in the real world with their 9-DoF poses.
- They started with a dataset that already had accurate poses but limited variety (OmniNOCS), then added lots of everyday images from MS-COCO.
- For each image, they estimated 3D boxes and directions using tools (like Orient Anything and MoGe), then had humans clean up mistakes. They also added helpful captions using a vision-LLM.
- Result: A diverse dataset that helps the model learn to control many kinds of objects in many scenes.
3) Two-stage training with a “reward” for good behavior
- Stage 1: Teach the model the basics—how to follow the 3D map (CNOCS) and the text description.
- Stage 2: Fine-tune it using a reward system, similar to how games score you. The model gets a higher score when:
- Objects appear in the right place and at the right size.
- Objects face the correct direction (for example, a dog facing away versus towards the camera).
- They purposely rebalanced the training to include more rare cases (like back views), which normal photos rarely show. This makes the model better at uncommon poses.
- They used memory-saving tricks so this “reward training” works efficiently.
4) Disentangled Object Sampling (DOS): drawing each object on its own “layer”
- Multi-object scenes are hard: models can confuse which pose belongs to which object or leave objects out.
- Their fix: During image generation, they partially draw each object separately using its own mask (like painting on different layers), then blend them together. This reduces confusion and helps the model match each object to its correct pose.
- They also support “personalization,” meaning you can control the pose of your own character or item by loading special weights learned for that subject.
Main findings and why they matter
The team compared 3DSceneDesigner with strong baselines and found:
- Better control: Objects land in the right spots and sizes more often, and face the correct direction much more reliably, including tricky back-facing views.
- Works with several objects: Their DOS technique reduces mix-ups between objects and ensures each one follows its own pose instructions.
- Higher quality and better text matching: The pictures look more realistic and match the written prompt more closely.
- Human testers preferred results from 3DSceneDesigner in quality, pose accuracy, and text alignment.
In short, it’s more accurate, more flexible, and higher quality than previous methods for the same task.
What does this mean going forward? (Implications and impact)
- Practical uses:
- Design and advertising: Quickly stage products or room layouts with precise poses.
- Film/animation and games: Arrange scenes with multiple characters facing specific ways.
- AR/VR and education: Create clear, controlled visuals for training and learning.
- Personalization: You can control the exact pose of a specific character or object you care about.
- Caution and ethics: Like any powerful image tool, it could be misused to create deceptive content. The authors suggest responsible use, detection tools, and clear guidelines to reduce harm.
Quick recap
- The paper tackles a tough problem: controlling where multiple objects go in a picture, how big they are, and which way they face—all at once.
- Their key idea, CNOCS, gives the model a simple but effective 3D map without needing detailed 3D models.
- A new dataset and a two-stage “reward” training process make the model good at both common and rare poses.
- A clever inference trick (DOS) helps keep objects separate and correctly posed in multi-object scenes.
- The result is a more controllable, higher-quality image generator that can be very useful—if used responsibly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research.
- Orientation control and evaluation are limited to azimuth: elevation and roll are not quantitatively assessed, and the reward/metrics appear to rely primarily on azimuth, leaving full 3D orientation fidelity unverified.
- CNOCS’s cuboid abstraction cannot model category-specific geometry, concavities, thin structures, or articulated parts; there is no mechanism to control fine-grained shape, articulation, or non-rigid deformations.
- Physical plausibility is not addressed: there is no constraint or evaluation for object-object collisions, contact realism, occlusion ordering with uncontrolled scene elements, shadows, lighting consistency with pose, or global scene coherence.
- 3D location/size accuracy is measured via 2D detection IoU after projection, which does not validate true depth placement or scale in 3D; no metric evaluates depth consistency, scene scale, or camera-space errors.
- Camera intrinsics/pose assumptions are unclear for COCO images (monocular reconstruction without ground-truth cameras); how CNOCS and evaluation depend on or generalize across unknown camera parameters is not analyzed.
- The ObjectPose9D annotation pipeline relies on Orient Anything and MoGe; error rates, systematic biases, inter-annotator agreement, and calibration against ground-truth 3D are not reported, making dataset accuracy and reliability uncertain.
- Orientation-ambiguous categories are excluded (“bottle”, etc.), limiting coverage; the method’s behavior and failure modes on ambiguous or symmetrically oriented objects remain unknown.
- Robustness to erroneous, noisy, or contradictory CNOCS inputs (e.g., conflicting text and pose, overlapping boxes, extreme or infeasible poses) is not studied.
- Multi-object semantic binding remains heuristic: DOS masks and per-object conditioning do not resolve ambiguous entity references, repeated categories, synonyms, or coreference; optimal assignment strategies and training-time solutions are unexplored.
- DOS introduces computation overhead and complexity; there is no quantitative analysis of latency, memory, or scalability (e.g., to many objects, high resolutions, or real-time interactive use).
- Scalability to large numbers of objects and heavily occluded scenes is not evaluated; failure modes and performance degradation with increasing scene complexity are unknown.
- Generalization across base models is claimed (diffusion vs. flow), but no experiments compare performance, stability, or training cost across architectures (e.g., SDXL, SD3 variants).
- Personalization is mentioned (user-specific weights), but procedures, compatibility, identity preservation vs. pose control trade-offs, and leakage across multiple custom subjects are not evaluated.
- The RL finetuning reward depends on external predictors (Grounding DINO, Orient Anything), risking reward hacking and overfitting to those models; robustness to domain shift or alternative evaluators is not assessed.
- RL finetuning design choices (γ, λ, β, truncation schedule, step selection) lack sensitivity analyses; training stability, variance across seeds, and convergence guarantees are not discussed.
- The effect of using intermediate coarse images for reward computation (instead of final outputs) on alignment and image quality is not quantified or theoretically justified.
- Dataset balancing protocol for the RL stage (“balanced distribution”) is under-specified: how bins are defined, sampling strategy, and impacts on rare poses/categories are not reported.
- Evaluation breadth is limited: comparisons exclude recent non-open-sourced baselines (e.g., ORIGEN), and benchmarks do not cover diverse viewpoints (top-down, aerial), domains (medical, industrial), or very high-resolution synthesis.
- Human evaluation (20 participants) lacks statistical analyses (e.g., confidence intervals, inter-rater reliability), potential biases, and task design details; reproducibility and significance are unclear.
- High-resolution generation (>512×512), upscaling, and cross-resolution consistency are not explored; performance at 1024×1024 or larger is unknown.
- Handling of articulated or multipart objects (e.g., humans, animals with limb poses) is not addressed; the framework controls whole-object orientation but not part-level pose.
- Conflict resolution between text semantics and CNOCS (e.g., text specifying one orientation while CNOCS encodes another, or text-driven attributes like “looking at camera” vs. back-facing) is not studied.
- Temporal consistency and extension to video remain open: maintaining object identity and pose across frames, handling camera motion, and integrating CNOCS with video diffusion are unexplored.
- Safety and traceability mechanisms (e.g., watermarking, provenance, misuse detection) are not implemented or evaluated, despite acknowledged social risks.
- Release status and documentation for ObjectPose9D (licenses, annotation tools, quality audit, splits) are not detailed; community validation and benchmarking support are unclear.
Practical Applications
Immediate Applications
The following applications leverage the paper’s current capabilities—multi-object 9-DoF pose control via CNOCS, ObjectPose9D, a ControlNet-style branch, RL-based finetuning, and Disentangled Object Sampling (DOS)—and can be deployed with existing text-to-image pipelines (e.g., Stable Diffusion 3.x, SDXL).
- Creative production for advertising and e-commerce
- Sector: marketing, retail, media
- Use cases: Generate consistent product photos across angles and sizes; create multi-product scene compositions (e.g., storefronts, shelf arrangements); produce ad creatives with explicit object placements and orientations.
- Tools/products/workflows:
- “Pose-aware photo studio” plug-in for SDXL/ComfyUI with a CNOCS panel to drag 3D cuboids per object and export pose-controlled images.
- Batch template workflows: predefine CNOCS templates per SKU (canonical angles, sizes, relative positions) and auto-render product variations; use DOS to avoid concept confusion in multi-product shots.
- Assumptions/dependencies: Base model’s visual quality and style consistency; objects must have unambiguous orientation; compute overhead for DOS and RL-tuned models; content rights and licensing of underlying T2I models.
- Interior design and architecture concepting
- Sector: architecture, real estate, furniture
- Use cases: Rapid layout exploration using cuboid placeholders for furniture; generate mood boards with controlled placement and facing direction; create multiple arrangement options from the same prompt.
- Tools/products/workflows: CNOCS-based scene prototyping UI embedded in design tools; export images for client review; iterative prompt + CNOCS refinement loops.
- Assumptions/dependencies: Lack of precise shape control may limit highly detailed object geometry; reliable performance depends on supported categories and clean scene segmentation.
- Film/game previsualization and storyboarding
- Sector: entertainment, gaming
- Use cases: Shot planning with explicit actor/prop poses and orientations; block out scenes with controlled multi-object layouts before detailed asset creation.
- Tools/products/workflows: “Pose storyboard generator” that ingests shot descriptions and CNOCS overlays to produce quick previs frames; DOS to maintain entity disentanglement.
- Assumptions/dependencies: Base model fidelity for complex multi-entity scenes; text prompt clarity; potential manual cleanup for fine-grained creative requirements.
- Education and training in visual arts and geometry
- Sector: education
- Use cases: Teaching perspective, orientation, and spatial reasoning by generating controlled examples (e.g., same object rotated by specific angles).
- Tools/products/workflows: Classroom tool where instructors set CNOCS cubes and prompt content; produce sequences showing pose transformations.
- Assumptions/dependencies: Orientation must be unambiguous; generated content should align with curricular standards.
- Synthetic datasets for object detection and pose estimation
- Sector: software, robotics (perception), autonomous driving (limited to static images)
- Use cases: Create labeled images with known 9D poses to augment training data for 2D detectors and orientation estimators; domain randomization by varying CNOCS parameters.
- Tools/products/workflows: Data generation pipelines that emit images plus pose metadata; automated QA using Grounding DINO IoU and Orient Anything pose checks (mirroring the paper’s reward functions).
- Assumptions/dependencies: Label fidelity depends on external estimators used for validation (e.g., Grounding DINO, Orient Anything); static-image limitation; require bias audits since ObjectPose9D and COCO selection excluded ambiguous categories.
- Personalized character and avatar pose control
- Sector: gaming, social media, branding
- Use cases: Consistent character brand shots with controlled orientation and placement; user-specific character personalization combined with pose conditioning.
- Tools/products/workflows: Integration of personalization weights (DreamBooth/Textual Inversion–style) with CNOCS-based pose control; DOS for multi-character scenes.
- Assumptions/dependencies: Personalization quality and base model consistency; responsible use and identity consent.
- Research infrastructure for controllable generation
- Sector: academia
- Use cases: Benchmarking multi-object 9-DoF pose control; studying RL vision alignment with explicit pose rewards; evaluating map-based pose conditioning versus embedding-based approaches.
- Tools/products/workflows: ObjectPose9D dataset and CNOCS map generator; RL finetuning recipe (reward functions using IoU and orientation KL); DOS inference scheduler.
- Assumptions/dependencies: Access to GPUs for training/finetuning; adherence to dataset licenses; reproducible pipelines for external estimators.
- Developer tooling and integration
- Sector: software
- Use cases: CNOCS generation module and API; ComfyUI/Automatic1111 nodes for pose-controlled generation; batch render scripts with DOS.
- Tools/products/workflows: Packaged “SceneDesigner” nodes; CNOCS map exporters; reward-based finetuning scripts for custom domains.
- Assumptions/dependencies: Compatibility with the chosen base model (SD3/SDXL), plugin ecosystem, and compute budgets.
Long-Term Applications
These applications require further research, scaling, or additional development—such as shape control beyond cuboids, video/temporal consistency, real-time inference, or stronger scene understanding.
- AR/VR spatial content authoring
- Sector: AR/VR, creative tools
- Use cases: Real-time pose-aware generative content placed in a user’s environment; author scenes with explicit object sizes/orientations relative to camera intrinsics and scene geometry.
- Tools/products/workflows: CNOCS-driven AR authoring UI coupled with on-device reconstruction; live occlusion reasoning.
- Assumptions/dependencies: Real-time generation; accurate camera calibration and scene reconstruction; robust occlusion handling; mobile hardware optimization.
- Robotics and autonomous systems sim-to-real data generation
- Sector: robotics, autonomous driving
- Use cases: Large-scale synthetic data with controlled multi-object poses for training 6D/9D pose estimators and planners; domain randomization across orientations and layouts; curriculum learning.
- Tools/products/workflows: Pose-programmable generators that emit image sequences or videos with metadata; integration with simulators (e.g., CARLA, Isaac) for physics and temporal consistency.
- Assumptions/dependencies: Extension from static images to temporally coherent video; physics-aware scene dynamics; validation against real-world distributions.
- CAD-to-image and 3D asset pipelines
- Sector: manufacturing, product design, game asset creation
- Use cases: Convert CAD-defined geometry and poses into photorealistic images; maintain consistent orientations across viewpoints for catalogs.
- Tools/products/workflows: CAD import → CNOCS mapping → pose-driven generation; hybrid pipelines with 3DGS/NeRF for multi-view consistency.
- Assumptions/dependencies: Precise shape control beyond cuboids (CNOCS currently abstracts with cuboids); view-consistent generation; licensing for CAD content.
- True 3D-aware photo/video editing
- Sector: consumer/pro media tools
- Use cases: Edit existing images/videos by re-posing objects with disentangled control; maintain background integrity and occlusion correctness.
- Tools/products/workflows: 3D reconstruction of object(s) + CNOCS-guided edits; temporal DOS-like schedulers for multi-object sequences.
- Assumptions/dependencies: Reliable instance segmentation and reconstruction; temporal coherence; risk of identity manipulation (requires safeguards).
- Content provenance and policy tooling
- Sector: policy, platform governance
- Use cases: Watermarking and content credentials indicating pose-conditioned generative content; standardized pose metadata to improve transparency.
- Tools/products/workflows: Embedding CNOCS-derived metadata and provenance signatures; platform-level policies for labeling synthetic content.
- Assumptions/dependencies: Industry adoption of content provenance standards; regulatory alignment; compatibility with existing watermarking.
- Retail planograms and digital twins
- Sector: retail operations
- Use cases: Generate planogram visuals (shelf arrangements with explicit orientation/size); simulate store layouts for training shelf-monitoring models.
- Tools/products/workflows: Pose-scripted multi-object scene generation; QA using IoU/orientation scores; integration with planogram management systems.
- Assumptions/dependencies: Multi-object robustness at larger scales; category coverage; potential need for exact product geometry.
- Healthcare and rehabilitation instruction visuals
- Sector: healthcare
- Use cases: Create pose-specific instructional imagery (e.g., exercises, device positioning) with controlled orientations and spatial layouts.
- Tools/products/workflows: Clinical content generation tool with CNOCS templates per activity; review by medical professionals.
- Assumptions/dependencies: Clinical validation and safety review; avoidance of misleading depictions; identity/privacy safeguards.
- Multi-object video generation with trajectory control
- Sector: entertainment, simulation
- Use cases: Extend 9-DoF control to time—pose trajectories for multiple entities; cinematic control (blocking, facing, movement).
- Tools/products/workflows: DOS-like temporal schedulers; trajectory-conditioned models (building on 3DTrajMaster/FMC paradigms).
- Assumptions/dependencies: New datasets with temporal pose annotations; training stability; motion realism.
- Pose-aware creative analytics and A/B testing
- Sector: marketing technology
- Use cases: Systematically vary object poses and placements to measure engagement; optimize angles, sizes, and layouts.
- Tools/products/workflows: Programmatic CNOCS sweeps; analytics pipelines linking pose parameters to performance metrics.
- Assumptions/dependencies: Integration with marketing platforms; statistical rigor; consistent style across variants.
Cross-cutting assumptions and dependencies to monitor
- External estimators: Orientation and detection quality (e.g., Orient Anything, Grounding DINO) directly affect reward functions and QA; updates may change behavior.
- Category selection: Ambiguous-orientation categories are filtered; expanding coverage will require improved orientation disambiguation and representation.
- Base model capability: Multi-object quality and attribute leakage are limited by the underlying T2I model; DOS mitigates but increases compute.
- Compute and licensing: RL finetuning and DOS add memory/time; verify licenses for SD3/SDXL and dataset usage (COCO-derived annotations).
- Safety and ethics: Potential misuse for deceptive content; deploy watermarking/provenance and consent-aware personalization; institutional policies needed.
Glossary
- 3D Gaussian Splatting: A scene representation that models images as collections of Gaussian primitives for efficient 3D reconstruction and manipulation. "3DitScene~\cite{3DitScene} reconstructs the 3D Gaussian Splatting~\cite{3DGS} of the scene, and manipulates the 3D Gaussians of the designated object through arbitrary 3D-aware operations."
- 3D bounding boxes: Axis-aligned or oriented cuboids that approximate the extent of objects in 3D space. "LOOSECONTROL~\cite{loosecontrol} employs 3D bounding boxes for controlling the location and size of the object in 3D space."
- 6D pose: An object's 3D rotation and 3D translation describing its orientation and position. "To estimate 6D poses and sizes of multiple objects, NOCS~\cite{NOCS} constructs the correspondences between pixels and normalized coordinates."
- 9D pose: A full object pose including 3D location, 3D size, and 3D orientation. "achieving simultaneous control over the 9D poses (location, size, and orientation) of multiple objects remains an open challenge."
- 9-DoF: Nine degrees of freedom describing an object's 3D position, size, and orientation. "CNOCS Map: Effective Representation of 9-DoF poses"
- AdamW optimizer: A variant of Adam with decoupled weight decay for improved training stability. "We use AdamW optimizer with an initial learning rate of ."
- Azimuth angle: The angle of rotation around the vertical axis, often used to describe orientation. "{1) } calculates the absolute error of azimuth angles (in degrees) between the input condition and the estimated one from Orient Anything~\cite{orient-anything}"
- Branched network: An auxiliary network branch added to a base model to inject structured control signals. "3DSceneDesigner incorporates a branched network to the pre-trained base model and leverages a new representation, CNOCS, which encodes 9D pose information from the camera view."
- CAD model: A precise, category-specific 3D model used to define an object's shape. "Unlike the original NOCS map, the points are located on surface of 3D bounding box instead of the precise shape determined by CAD model."
- Category-agnostic: A design that works across object categories without requiring category-specific models or shapes. "This simplification retains essential geometric cues while supporting category-agnostic pose encoding."
- CLIP: A model for measuring text–image alignment via joint embeddings. "Furthermore, CLIP~\cite{CLIP} is used to estimate the text-image alignment and FID presents visual quality."
- CNOCS (Cuboid NOCS): A cuboid-based Normalized Object Coordinate System that encodes 9D pose from camera view without requiring precise CAD shapes. "we introduce the Cuboid NOCS (CNOCS) map to only consider a cuboid shape for general purpose."
- ControlNet: An architecture adding conditional control maps to diffusion models to enforce structure in generation. "ControlNet~\cite{ControlNet} and its following works~\cite{UniControl,Uni-ControlNet} introduce a branched network to process the geometry guidance, resulting in the image with high structure fidelity."
- ControlNet-like architectures: Variants of ControlNet used to inject structured guidance such as geometry or depth maps. "Inspired by the success of ControlNet-like architectures~\cite{ControlNet,Uni-ControlNet,UniControl,T2I-Adapter} in structural control, LOOSECONTROL~\cite{loosecontrol} adopts 3D bounding boxes for 3D-aware guidance."
- Disentangled Object Sampling (DOS): An inference technique that isolates object regions during sampling to prevent concept confusion and ensure pose–object correspondence. "At inference time, we propose Disentangled Object Sampling, a technique that mitigates insufficient object generation and concept confusion in complex multi-object scenes."
- Diffusion models: Generative models that iteratively denoise data starting from noise using a learned noise predictor. "Diffusion-based methods~\cite{NCSM,Score-Matching,DDPM} learn a noise prediction model, and remove the estimated noise from noisy image during sampling."
- Denoising Diffusion Probabilistic Models (DDPM): A class of diffusion models formalizing the forward and reverse noising processes probabilistically. "Diffusion-based methods~\cite{NCSM,Score-Matching,DDPM} learn a noise prediction model, and remove the estimated noise from noisy image during sampling."
- Flow matching: A generative modeling approach training a velocity field that transports noise to data along straight trajectories. "Flow matching~\cite{fm1,fm2,fm3} achieves the goal by training a neural network to model the velocity field, moving the noise to data along straight trajectories."
- Fréchet Inception Distance (FID): A metric assessing generative image quality by comparing feature distributions of generated and real images. "Furthermore, CLIP~\cite{CLIP} is used to estimate the text-image alignment and FID presents visual quality."
- Gradient checkpointing: A memory-saving technique that recomputes intermediate activations during backpropagation. "we leverage randomized truncated backpropagation and gradient checkpointing like in AlignProp~\cite{AlignProp}, while feeding the coarse image estimated from intermediate step to the reward function instead of the clean one."
- Grounding DINO: A detection model used to localize objects, often guided by text. "we use Grounding DINO~\cite{G-DINO} to detect generated objects."
- Intersection over Union (IoU): A metric measuring overlap between predicted and target regions. "compute its Intersection over Union (IoU) with the projected one from 3D bounding box."
- KL divergence: A measure of difference between probability distributions, used here for orientation discrepancy. "Then, calculates the KL divergence between the target distribution and the estimated distribution from Orient Anything."
- Multimodal LLM (MLLM): A LLM capable of processing and generating across text and vision modalities. "Besides, Multimodal LLM (MLLM)~\cite{Qwen-vl} is also employed to generate descriptive captions for each image, enriching the dataset with aligned textual information."
- NOCS (Normalized Object Coordinate System): A coordinate system mapping pixels to normalized object-space coordinates for category-consistent pose estimation. "Normalized Object Coordinate System (NOCS): To estimate 6D poses and sizes of multiple objects, NOCS~\cite{NOCS} constructs the correspondences between pixels and normalized coordinates."
- Object-centric representations: Feature representations focused on individual objects to enable disentangled control of appearance and pose. "NeuralAssets~\cite{NeuralAssets} learns object-centric representations that enable disentangled control over object appearance and pose in neural rendering pipelines."
- ObjectPose9D: A dataset aggregating images and annotations for multi-object 9D pose control. "we construct a new dataset, ObjectPose9D, which provides 9D pose annotations across diverse real-world scenarios."
- OmniNOCS: A dataset providing accurate pose annotations used as a foundation for ObjectPose9D. "we begin with the publicly available OmniNOCS dataset~\cite{OmniNOCS}, which offers accurate pose annotations but is limited in object and background diversity."
- One-step generative models: Models that generate in a single forward pass, contrasted with multi-step diffusion frameworks. "Additionally, it relies on one-step generation models, hampering its compatibility with general models."
- Orient Anything: A model that estimates object orientation from images. "Orient Anything~\cite{orient-anything} is used to infer the object orientation and we filter the objects with low prediction confidence."
- Point clouds: Sets of 3D points used to estimate geometry and fit 3D bounding boxes. "Diffusion Handles~\cite{DiffusionHandles} leverages the point clouds estimated from the input image, and guides the sampling process through transformed points and depth-conditioned ControlNet~\cite{ControlNet}."
- Policy gradient: A reinforcement learning method optimizing model parameters via gradients of expected rewards. "Other RL-based methods like DDPO~\cite{DDPO} leverage policy gradient algorithm for finetuning."
- Randomized truncated backpropagation: A training technique that truncates and randomizes the backward pass through time/steps to reduce memory. "we leverage randomized truncated backpropagation and gradient checkpointing like in AlignProp~\cite{AlignProp}, while feeding the coarse image estimated from intermediate step to the reward function instead of the clean one."
- Reinforcement Learning from Human Feedback (RLHF): An approach aligning models with human preferences via reward optimization. "Therefore, we resort to the technique from RLHF (Reinforcement Learning from Human Feedback)."
- Spherical harmonics: Basis functions on the sphere used to encode angular information of 3D points. "Then, we can construct a series of Laplace's spherical harmonics depending on a user-defined degree as point embedding, where represent indices of degree and order, respectively."
- Stable Diffusion: A widely used diffusion-based text-to-image framework. "Zero-1-to-3~\cite{Zero-1-to-3} infers the novel perspective of reference subject, but relies on external inpainting tools~\cite{StableDiffusion} to create a complex background."
- Textual Inversion: A technique that learns new textual tokens to represent user-provided visual concepts. "Other methods~\cite{NeTI,Break-A-Scene} like DreamBooth~\cite{DreamBooth} and Textual Inversion~\cite{TI} learn new concepts given by users, endowing the text-to-image (T2I) models with customization capability."
- Velocity field: The vector field guiding transport from noise to data in flow matching generative models. "Flow matching~\cite{fm1,fm2,fm3} achieves the goal by training a neural network to model the velocity field, moving the noise to data along straight trajectories."
- Inpainting: Filling in or synthesizing missing/occluded regions in an image, often guided by context or prompts. "Zero-1-to-3~\cite{Zero-1-to-3} infers the novel perspective of reference subject, but relies on external inpainting tools~\cite{StableDiffusion} to create a complex background."
- Euler angles: A three-parameter representation of 3D orientation via sequential axis rotations. "{1)~Constant function.} We can simply assign a predefined vector for any point, such as Euler angles."
- Cross- or self-attention mechanism: Neural attention operations that integrate conditioning signals (cross) or intra-feature relations (self) into generation. "a straightforward method is to project the location, size, and orientation to embeddings, respectively, while integrating the features into network through cross- or self-attention mechanism~\cite{Continuous-3D-Words,compass,InstanceDiffusion,GLIGEN,Boximator,TrackDiffusion}."
- mean Intersection over Union (mIoU): The average IoU across samples, used to evaluate spatial alignment accuracy. "For validation metrics, we use mean Intersection over Union () and spatial accuracy for assessing the precision of location and size."
Collections
Sign up for free to add this paper to one or more collections.

