Hunyuan3D-Omni: A Unified Framework for Controllable Generation of 3D Assets
Abstract: Recent advances in 3D-native generative models have accelerated asset creation for games, film, and design. However, most methods still rely primarily on image or text conditioning and lack fine-grained, cross-modal controls, which limits controllability and practical adoption. To address this gap, we present Hunyuan3D-Omni, a unified framework for fine-grained, controllable 3D asset generation built on Hunyuan3D 2.1. In addition to images, Hunyuan3D-Omni accepts point clouds, voxels, bounding boxes, and skeletal pose priors as conditioning signals, enabling precise control over geometry, topology, and pose. Instead of separate heads for each modality, our model unifies all signals in a single cross-modal architecture. We train with a progressive, difficulty-aware sampling strategy that selects one control modality per example and biases sampling toward harder signals (e.g., skeletal pose) while downweighting easier ones (e.g., point clouds), encouraging robust multi-modal fusion and graceful handling of missing inputs. Experiments show that these additional controls improve generation accuracy, enable geometry-aware transformations, and increase robustness for production workflows.
First 10 authors:



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Hunyuan3D-Omni, a new AI system that can create 3D models (like characters, furniture, or objects) with much better control. Instead of only using a single photo or text to make a 3D object, this system can also use extra “hints” such as point clouds, voxels, bounding boxes, and skeleton poses. These hints help the AI build shapes more accurately and in the exact way a creator wants.
Objectives
The paper aims to answer simple but important questions:
- How can we make 3D models from a single image more accurate and less blurry or distorted?
- Can we control the size, shape, and pose of the generated 3D objects using different kinds of input?
- Is it possible to handle many types of control signals in one single model, instead of training many separate models?
Methods and Approach
To understand the method, think of the AI like a smart builder that reads instructions and uses tools to sculpt a 3D shape.
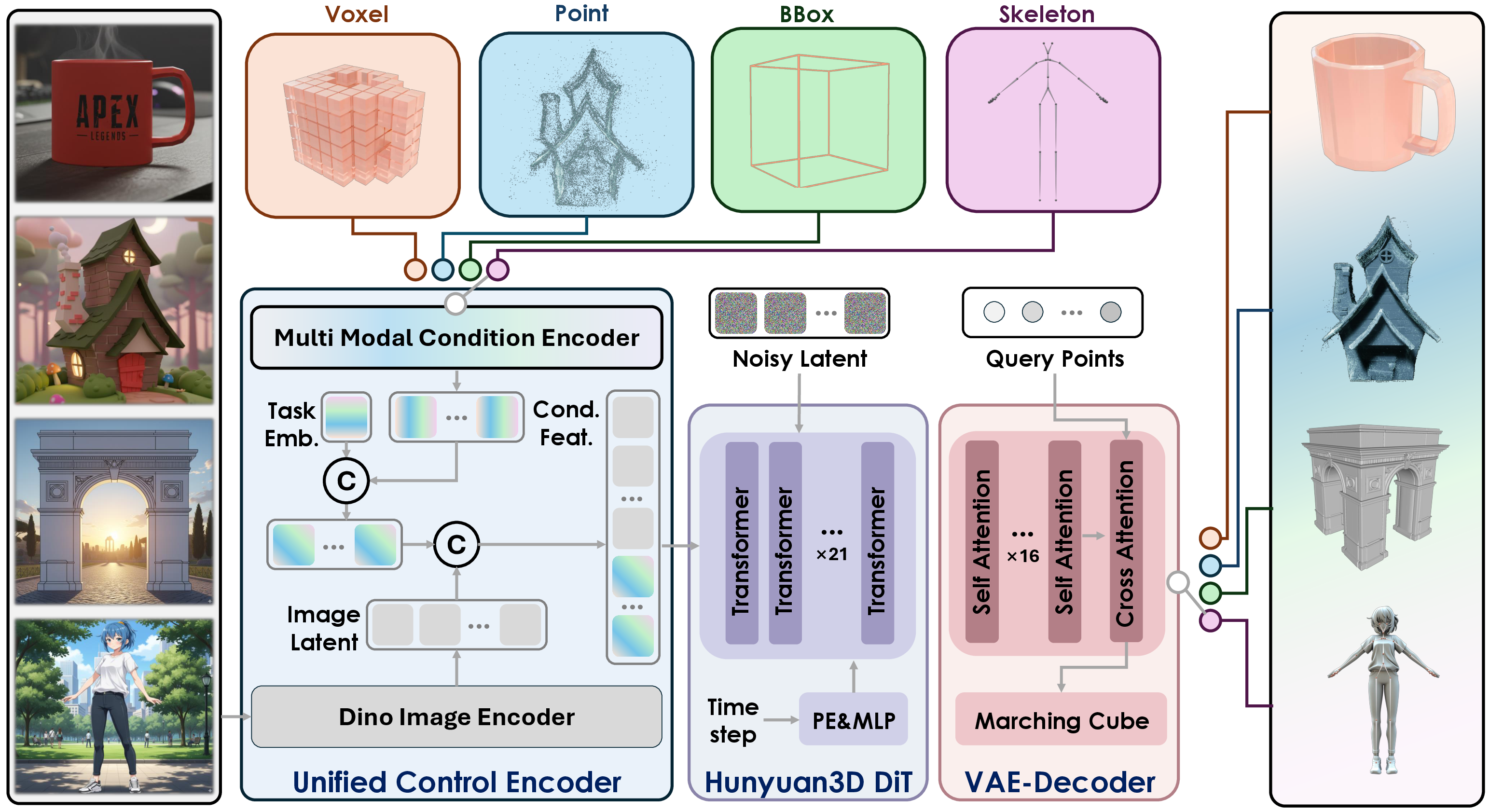
- Base system: The model builds on an earlier 3D generator called Hunyuan3D 2.1. It already knows how to turn an image into a 3D shape quickly and with good quality.
- Two core parts:
- A 3D “compressor and builder” (called a 3D VAE): Imagine compressing a big 3D model into a smaller, tidy bag of numbers (a “latent vector set”) so it’s easier to work with. Later, a decoder turns that bag of numbers back into a full 3D shape.
- A “noisy-to-clean” generator (called a diffusion/flow model): Picture starting with random noise (like TV static) and gradually sculpting it into a detailed 3D shape, guided by clues from the input image and the extra control hints.
- Extra control signals: The model accepts different types of hints beyond images. Here’s what each one means in everyday terms:
- Point clouds: Like a constellation of dots marking the surface of the object in 3D space. They give the AI a sense of depth and shape.
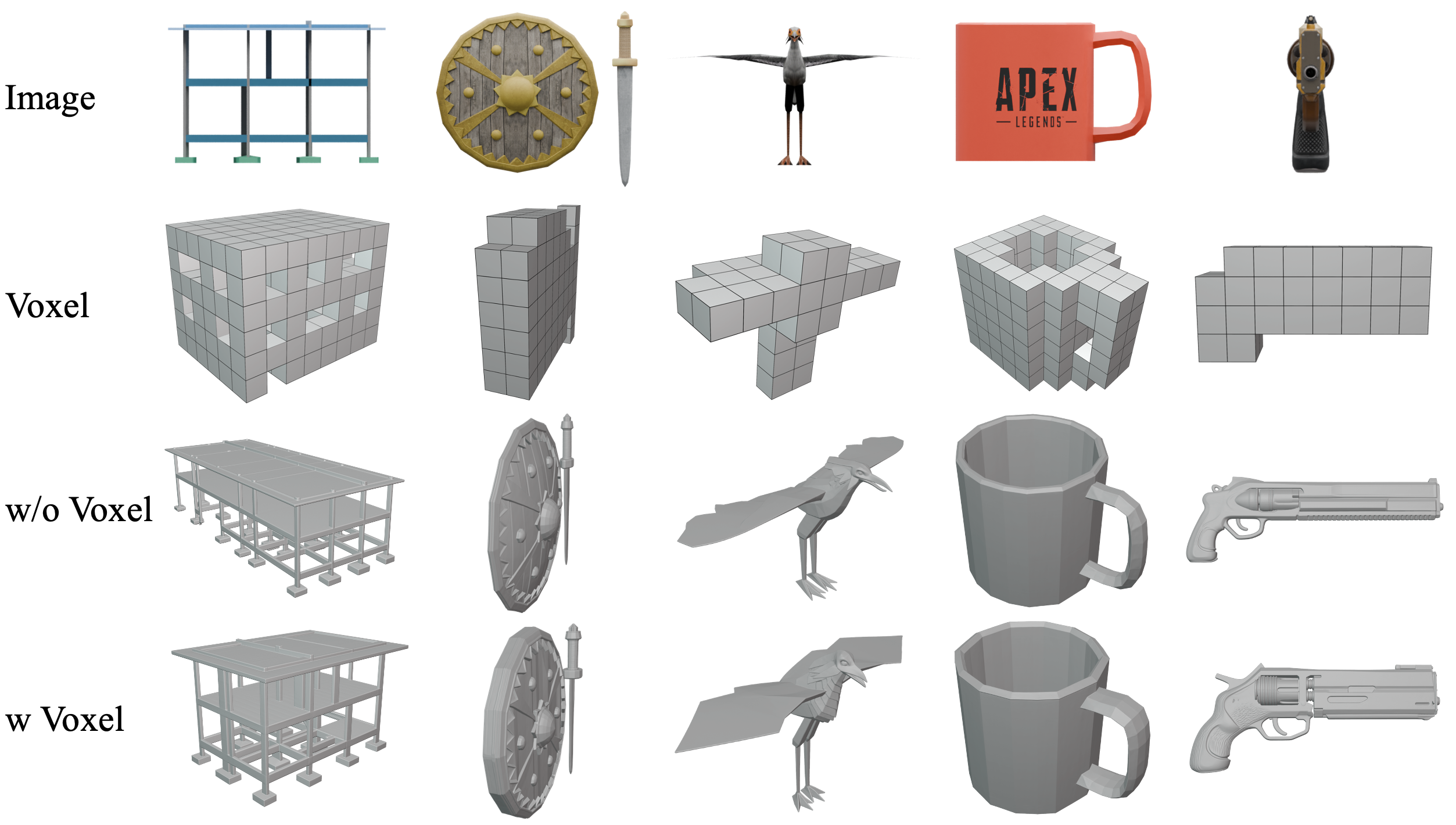
- Voxels: 3D pixels, like tiny cubes in a Minecraft world. They describe volume and structure.
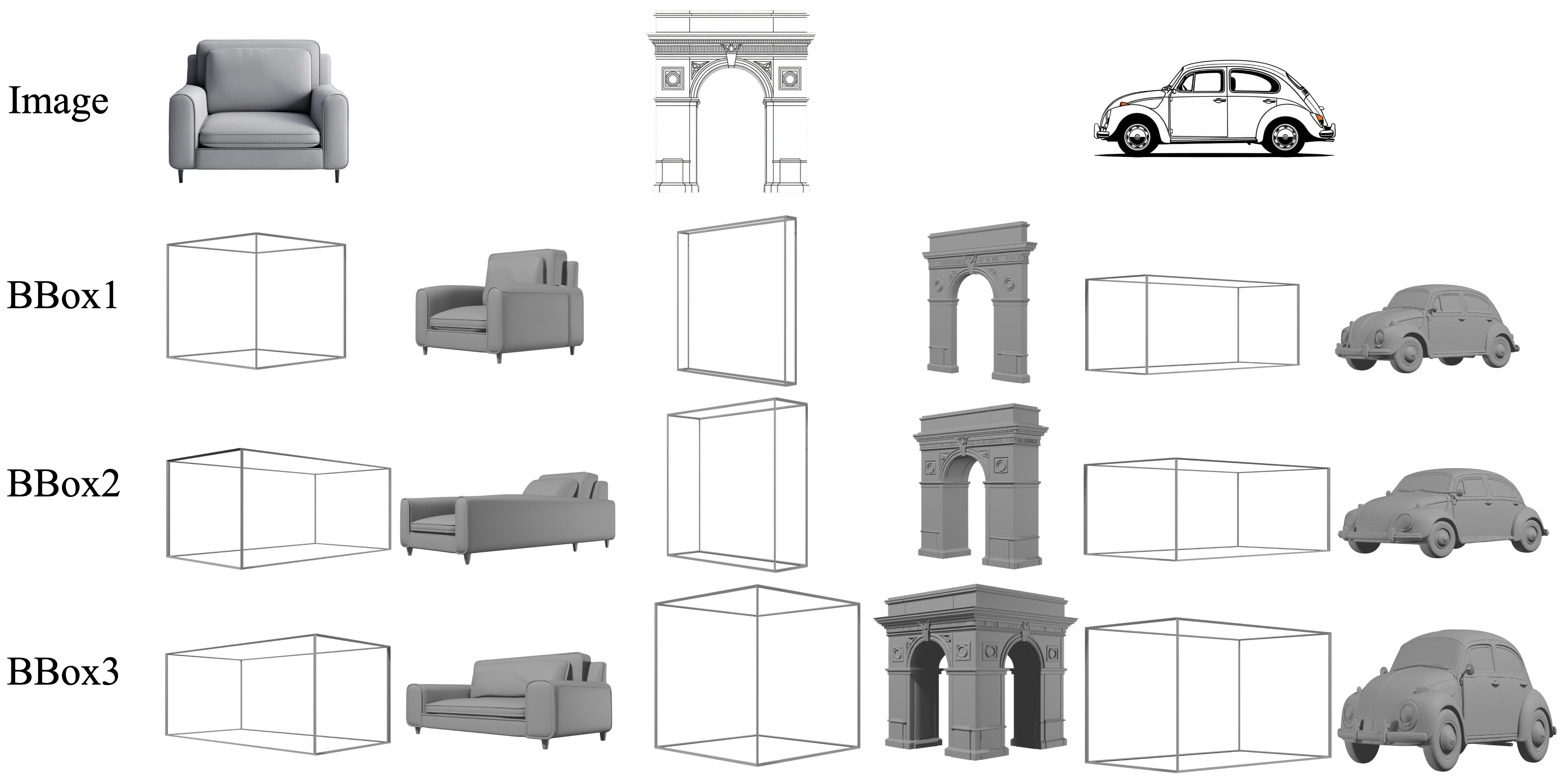
- Bounding boxes: A 3D measuring box around the object. It tells the AI the general size and proportions (length, width, height).
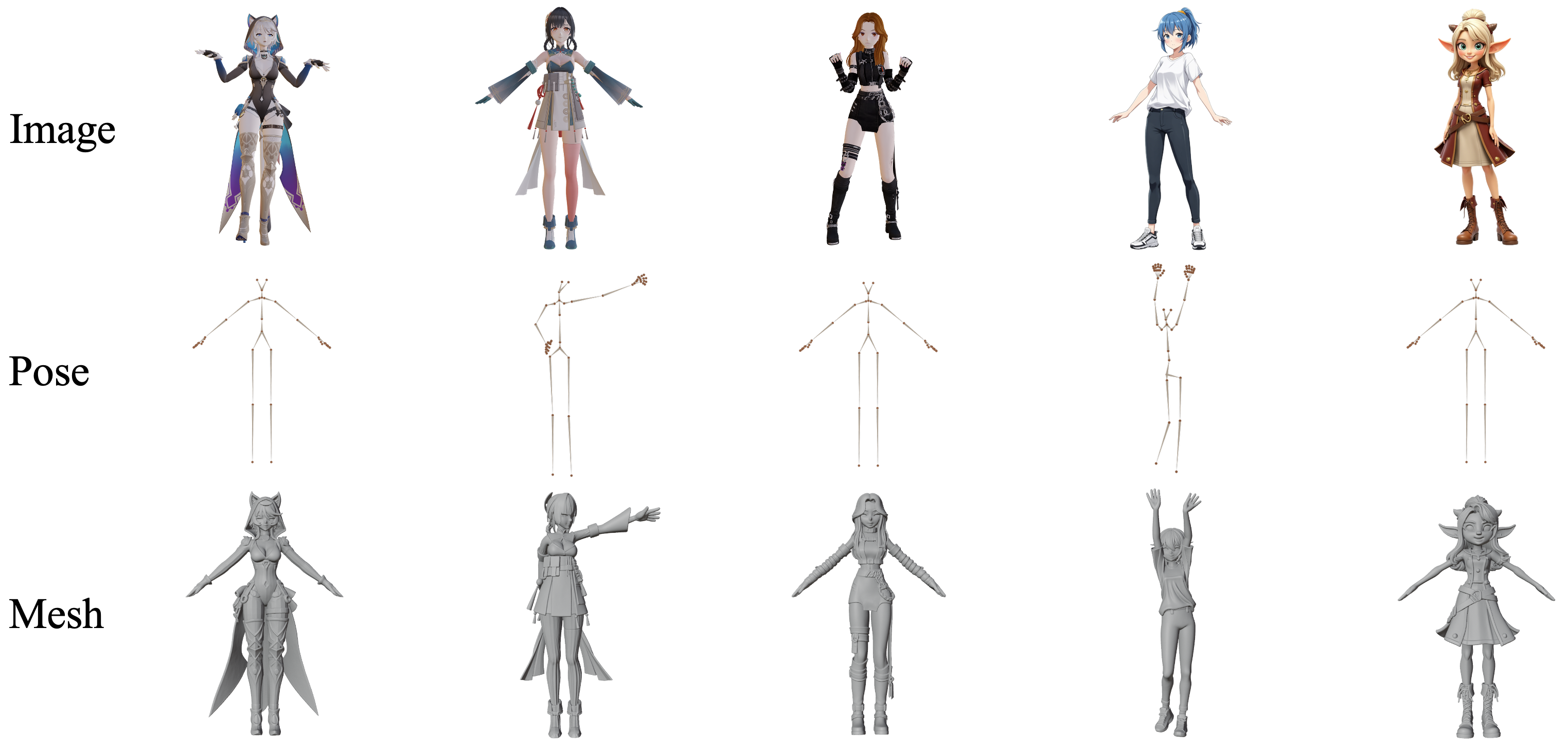
- Skeletons: A stick-figure pose for characters. This tells the AI exactly how the character should stand, bend, or raise its arms.
- Unified control encoder: Instead of building separate tools for each hint type, the authors designed one “translator” that makes all hints look like a kind of point cloud to the model. This encoder:
- Converts each hint into features the model understands.
- Adds a small “label” (an embedding) so the model knows which hint type it’s seeing (e.g., skeleton vs. voxels).
- Combines these hint features with image features (from an image encoder called DINOv2, which acts like a skilled note-taker that highlights useful parts of the picture).
- Smart training schedule: During training, each example uses only one hint type at a time, but the model rotates through all hint types. It practices harder hints (like skeleton pose) more often and easier hints (like point clouds) less often. This helps the model learn to handle every hint type well, and also cope if some hints are missing.
Main Findings and Why They Matter
The experiments show clear benefits:
- Better accuracy: Using extra hints (point clouds or voxels) produces shapes that match the real object more closely. This helps fix problems that happen when you only have one photo, like missing details or wrong thickness.
- Pose control: With skeleton input, the AI can reliably make characters match the target pose (A-pose, arms up, etc.) while keeping fine details. That’s valuable for animation and figure design.
- Size and proportion control: Bounding boxes let creators stretch or shrink objects in believable ways (e.g., lengthening a sofa and adding appropriate legs), rather than just “stretching” unrealistically.
- Robustness: The model can handle noisy or partial data (like incomplete scans from a depth camera) and still produce well-aligned geometry.
- Unified design: One model supports all control types, simplifying production pipelines and reducing training costs compared to maintaining multiple separate models.
In short, the system makes 3D generation more controllable, more accurate, and more practical for real projects.
Implications and Impact
Hunyuan3D-Omni could speed up and improve how 3D assets are made for:
- Games and VR: Designers can quickly shape and pose characters or objects that fit the exact scene.
- Movies and animation: Precise pose control and accurate geometry help animators and modelers work faster with fewer fixes.
- 3D printing and product design: Reliable proportions and details make models ready for physical production.
- Everyday creative tools: Bringing multiple hint types into one model means artists can mix and match inputs (photo + skeleton + bounding box) for predictable, high-quality results.
Overall, this research shows an important step toward “controllable” 3D generation: creators can guide the AI with simple, powerful hints to get the exact 3D assets they need, more quickly and with fewer mistakes.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Lack of quantitative evaluation: no Chamfer-L1/Chamfer-L2, F-Score, normal consistency, mesh watertightness/manifoldness, SDF IoU, or pose error (e.g., MPJPE) are reported for any control modality.
- No baseline comparisons: missing head-to-head quantitative studies against CLAY, PoseMaster, or image-only/native 3D baselines under identical data and prompts.
- Ablation studies are absent: no analysis of the impact of each control type, the unified control encoder design, concatenation vs cross-attention conditioning, or the contribution of the “difficulty-aware” sampling schedule.
- “Difficulty-aware” sampling is under-specified: the progression, probabilities, and schedule are not detailed; no evidence it improves convergence, robustness, or final quality.
- Single-condition training only: the model is trained with one control per example; the ability to ingest and reconcile multiple simultaneous controls (e.g., skeleton + point cloud + bounding box) is untested and undefined.
- Control conflict resolution is unspecified: how the model should prioritize or reconcile contradictory control signals (e.g., skeleton incompatible with point cloud) is not addressed.
- Missing control strength knob: no mechanism or experiments for tuning control influence vs image fidelity (e.g., a scalar weight, conditioning dropout) during inference.
- Bounding-box compliance is not verified: the extent to which generated meshes satisfy the input box ratios (e.g., scale error in //) is neither measured nor enforced.
- Pose fidelity and identity preservation are unmeasured: no metrics or analysis of how closely the output follows target skeletons and whether identity/shape/style is preserved across pose edits.
- Skeleton encoding ignores structure: bones are encoded as point pairs () but connectivity/topology is unused; graph-based encoders or kinematic constraints are unexplored.
- Voxel resolution is fixed and coarse (16³): scalability to higher/lower voxel resolutions, continuous occupancy values, or sparse voxel structures (e.g., octrees) is not evaluated.
- Point cloud noise modeling is simplistic: only additive noise and random drops are simulated; real sensor patterns (quantization, depth holes, multi-path, rolling shutter) and cross-device generalization remain open.
- Coordinate-frame alignment is underexplored: assumptions about canonical space and alignment between image and control inputs at inference time are unclear; robustness to miscalibration/misalignment is untested.
- Domain coverage and data curation are not specified: training data scale, category distribution, style diversity, licensing, and potential biases are unclear; OOD generalization (e.g., non-humanoid, thin structures) is not studied.
- Texture and material generation is not addressed: the method focuses on geometry; how controls affect texture/UV/materials and multi-modal texturing remains open.
- Refinement with Hunyuan3D 2.5 is unquantified: the impact of the second-stage refiner on geometry fidelity and control faithfulness (e.g., does refinement drift from constraints?) is not analyzed.
- Absent failure mode analysis: no systematic characterization of when controls fail (e.g., extreme poses, sparse/noisy scans, degenerate boxes) or how the system degrades.
- Efficiency and scalability are unclear: batch size is 1; training compute, memory footprint, inference latency, and throughput under different control sizes/resolutions are not reported.
- Generality to scenes and multi-object setups is untested: the framework targets single objects; extension to scene-level composition, multi-instance bounding boxes, or multi-character skeletons remains open.
- Camera modeling is unspecified: how camera intrinsics/extrinsics are handled when aligning image cues with 3D controls (and the effect of mismatch) is not discussed.
- Constraint satisfaction mechanisms are absent: no architectural or decoding constraints (e.g., differentiable penalties) ensure hard adherence to boxes, skeleton joint limits, or physical plausibility.
- Training with partial/missing/invalid controls is not evaluated: robustness to missing joints, corrupted voxels, or extremely sparse point clouds (and strategies like conditioning dropout) remains open.
- Control-type embedding design is ad hoc: the effect of the type-embedding projection, repeat factor r, and positional encoding choices on disentanglement and leakage between control intents is not ablated.
- Alternative fusion strategies are unexplored: concatenation with DINO features is chosen; comparisons with cross-attention, FiLM/adapter layers, or gated residual conditioning are missing.
- Topology preservation under pose control is unverified: whether the generated mesh maintains consistent topology across pose changes (avoiding self-intersections or non-manifold artifacts) is unknown.
- Comparison with separate specialized heads/adapters is missing: the cost-quality trade-off of a unified model vs modality-specific heads (parameter count, finetune cost, control fidelity) is not quantified.
- Multi-view and text conditioning are not integrated: extension to multi-image inputs or text prompts in combination with geometric controls (and their interplay) is not examined.
- Reproducibility details are incomplete: hyperparameters, dataset splits, exact sampling probabilities, and training curriculum specifics are insufficient for replication.
- Safety and responsible use are not discussed: potential misuse, content-policy constraints, or bias amplification from training data are unaddressed.
Practical Applications
Immediate Applications
The following applications can be deployed with the methods, controls, and workflows demonstrated in Hunyuan3D-Omni. Each item names relevant sectors, potential tools/products, and key assumptions or dependencies.
- Gaming, Film/Animation, XR: controllable single-image-to-3D asset creation
- What: Turn concept art or a single reference image into a 3D mesh with precise geometry control using additional inputs (point clouds, voxels, bounding boxes, skeletons).
- Tools/workflows: “Omni” plug-ins for Blender/Maya/Unreal/Unity; studio pipeline nodes for “image + control signals → mesh,” with optional Hunyuan3D 2.5 refinement.
- Assumptions/dependencies: Access to Hunyuan3D 2.1/2.5 weights; DINO-v2 features; availability/quality of control signals; post-processes for UVs/materials/retopology if required for production.
- Character authoring with explicit pose control
- What: Generate rigged character meshes that match a specified skeleton (A-pose, dynamic poses, fine hand articulation).
- Sector: Games, film, VTubing/avatars, 3D printing (figurines).
- Tools/workflows: “Pose-to-Character” tool where a creator provides an image + target skeleton; batch pose normalization for asset libraries.
- Assumptions/dependencies: Skeleton schema alignment (body + hand bones); quality of skeletal extraction tools (e.g., PoseMaster-like pipelines) if derived from images; rigging/skin weights may still need manual/auto post-processing.
- Product digitization with dimensional fidelity via bounding boxes
- What: Avoid “thin/sheet-like” meshes and enforce correct proportions by providing canonical-space bounding boxes with length–width–height control.
- Sector: E-commerce, retail AR, furniture/interior design.
- Tools/workflows: “SKU-to-3D” service where sellers upload a product photo + measured bbox; catalog-wide aspect ratio standardization; geometry rescaling without naive stretching.
- Assumptions/dependencies: Accurate bbox measurement or estimation; canonical-space conventions; downstream UV/material assignment.
- Scan-to-asset alignment and completion from partial depth/LiDAR
- What: Use partial RGBD/LiDAR scans or reconstructed point clouds to resolve single-image ambiguities and recover occluded geometry.
- Sector: Robotics simulation (assets), AR/VR, digital twins.
- Tools/workflows: “Scan+Image → Mesh” microservice; handheld phone depth capture to improve fidelity; QA step in digitization lines to fix mis-scaled misaligned models.
- Assumptions/dependencies: Sensor noise handling; coordinate system alignment; privacy/compliance for captured scans; point cloud quality strongly affects outputs.
- Fast geometry-aware editing (proportion changes, stylization)
- What: Edit length/width/height, enforce silhouettes, and preserve pose or transform pose while keeping style and geometry fidelity.
- Sector: Digital content creation (DCC), advertising, design ideation.
- Tools/workflows: “BBox Proportions Tweaker,” “Pose Retarget + Regenerate,” stylization-guided 3D regeneration from image inputs.
- Assumptions/dependencies: Clean separation of edit intents through correct control type; may require iterative user feedback or refinement.
- Asset quality control and auto-fix in production pipelines
- What: Automatically detect and correct common pathologies (overly thin geometry, flatness, missing details) by re-generating with appropriate control signals (bbox/voxel/points).
- Sector: Game/film asset pipelines, 3D marketplaces.
- Tools/workflows: Automated “regenerate-with-control” pipeline step; batch standardization of shape scale across large repositories.
- Assumptions/dependencies: Access to original reference images or scans; policies for automatic replacement vs. human approval.
- Synthetic data generation for vision research and robotics
- What: Generate consistent 3D assets with controlled poses and dimensions to populate simulators or multi-view renderers.
- Sector: Academia (CV/graphics), robotics (perception), simulation tools.
- Tools/workflows: Scripts to sample skeletons/bboxes/voxels to generate diverse, labeled asset sets; improve domain coverage for detectors/pose estimators.
- Assumptions/dependencies: Not guaranteed physically accurate materials/physics; additional rendering and annotation layers required.
- Education and maker communities: pose-to-print and scan-to-print
- What: Hobbyists create 3D-printable figurines by supplying an image and a target pose or partial phone scan.
- Sector: Education, consumer 3D printing, maker spaces.
- Tools/workflows: Simple GUI: “Upload image + choose pose/bbox → generate STL/OBJ,” with one-click mesh watertightness checks.
- Assumptions/dependencies: Legal rights to images; mesh cleanup for printability; scale calibration.
- MLOps simplification: one unified controllable model
- What: Replace multiple modality-specific models with one unified control encoder and model, reducing maintenance and inference orchestration.
- Sector: AI platform teams in media tech, 3D SaaS providers.
- Tools/workflows: Unified inference service accepting image + control JSON; progressive difficulty-aware sampling strategy for continued training.
- Assumptions/dependencies: Availability of training data for all control types; monitoring to detect control-type confusion; capacity planning for DiT-based models.
Long-Term Applications
These applications are plausible extensions that need further research, scaling, evaluation, or integration beyond what’s demonstrated.
- Scene-level controllable 3D generation with multi-object composition
- What: Extend from single objects to full scenes where bounding boxes and voxel/point controls define multiple assets and spatial relations.
- Sector: Games, film previz, digital twins for retail/layout.
- Tools/workflows: “Scene Graph + Multi-bbox/voxels → Scene Meshes,” interactive scene editing with constraints.
- Assumptions/dependencies: Scalable datasets with scene annotations; inter-object contact/physics reasoning; memory-efficient multi-object DiT.
- CAD/CAM and manufacturing-grade models with metric accuracy
- What: Turn photos and sparse scans into dimensionally precise assets suitable for fabrication, with tolerances and parametric controls.
- Sector: Manufacturing, prototyping, industrial design.
- Tools/workflows: “Image/scan + engineering constraints → CAD-like solids;” parametric bbox mappings; STEP/IGES export.
- Assumptions/dependencies: Hybrid neural–CAD representations; strict metric calibration; compliance with engineering standards.
- End-to-end AR commerce: instant try-out and SKU onboarding on device
- What: On-device or near-real-time generation of 3D product models from seller/customer phones for AR try-on/placement.
- Sector: E-commerce, retail, mobile AR.
- Tools/workflows: “Capture → partial point cloud → Omni → lightweight mesh,” with asset compression and material inference.
- Assumptions/dependencies: Edge acceleration (e.g., distillation/quantization), robust on-device depth; material/UV prediction modules; bandwidth constraints.
- Robotics grasp and manipulation planning from consumer scans
- What: Convert partial scans + imagery into usable 3D meshes for grasp planning, with pose control to simulate varied object orientations.
- Sector: Robotics (warehouse, home robotics).
- Tools/workflows: “Scan2Mesh → sim → grasp synthesis,” using bounding boxes for scale normalization across objects.
- Assumptions/dependencies: Physical properties and mass distribution estimation; mesh-to-physics conversion; safety validation.
- Medical/biomechanical asset generation with pose/shape control
- What: Patient-specific anatomical models or orthotic designs driven by sparse scans and dimensional constraints.
- Sector: Healthcare, medtech, surgical planning.
- Tools/workflows: “Partial scan + constraint → anatomical mesh” for rehearsal or device fitting.
- Assumptions/dependencies: Regulatory approval, clinical validation, guaranteed metric accuracy/biological plausibility; secure handling of PHI.
- Standards and policy for multi-modal 3D control signals
- What: Establish open specifications for skeleton schemas, bbox conventions, voxel encodings, and provenance/watermarking of generated 3D assets.
- Sector: Policy, standards bodies, 3D marketplaces.
- Tools/workflows: Control-signal schema registries; audit tools verifying dimension/pose adherence; content provenance pipelines.
- Assumptions/dependencies: Industry coordination; IP/copyright frameworks for derived 3D assets; privacy rules for scan data.
- Cross-modal editing assistants (language + controls)
- What: Natural-language editing combined with structured controls, e.g., “make the table 15% wider and keep the pose of the character,” with explicit bbox/skeleton updates.
- Sector: DCC, education, design tooling.
- Tools/workflows: LLM-guided 3D editing agent orchestrating control encoders; versioned edit histories and constraint solvers.
- Assumptions/dependencies: Robust language–geometry alignment; conflict resolution across multiple control signals.
- Real-time interactive generation for creative tools
- What: Near-interactive mesh previews as users drag skeletal joints or bbox sliders.
- Sector: Creative software, live production, XR co-creation.
- Tools/workflows: Cached DiT states, token-merging/speed-ups, rectified flow distillations; GPU/edge acceleration.
- Assumptions/dependencies: Significant optimization (distillation, caching), memory constraints; graceful degradation in quality.
- Benchmarking and research on unified 3D controllability
- What: Datasets and metrics to evaluate pose, proportion, and geometry faithfulness under multi-modal controls; study difficulty-aware sampling curricula.
- Sector: Academia, standards bodies.
- Tools/workflows: Public benchmarks covering skeleton/point/voxel/bbox conditions; open-source training scripts for ablations.
- Assumptions/dependencies: Data licensing; reproducibility of base models; community adoption.
Notes on Feasibility and Dependencies Across Applications
- Data and models: Requires access to Hunyuan3D 2.1 (and optionally 2.5 for refinement), DINO-v2 image features, and sufficiently diverse training data per control type.
- Control signal quality: Outputs are strongly dependent on the fidelity and alignment of point clouds/voxels/bboxes/skeletons; noisy or misaligned inputs can propagate errors.
- Pipeline integration: Production deliverables often need UVs, materials, rigging, LODs, and watertight meshes—expect additional post-processing modules.
- Compute and latency: DiT-based generation can be resource-intensive; interactive or mobile use calls for distillation, quantization, or caching accelerations.
- IP/privacy: Scans and images must be lawfully sourced; marketplaces and enterprises may need provenance trails and content safety checks.
- Generalization limits: Current results are object-centric (not full scenes), with qualitative demonstrations; some domains (medical/CAD) require metric guarantees and rigorous validation.
Glossary
- 3D Diffusion: A generative modeling approach that learns to reverse a noise-adding process to generate 3D representations from conditioning inputs. "the 3D diffusion model aims to model the denoising process"
- 3D Variational Autoencoder (VAE): A probabilistic autoencoder that compresses 3D inputs (e.g., point clouds) into a latent space and reconstructs them, often via an SDF field. "Native 3D generation primarily involves two key components: the 3D Variational Autoencoder (VAE) and the 3D latent diffusion model (LDM)."
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient-based update, commonly used for training deep models. "the AdamW optimizer."
- aspect ratio: The proportional relationship between dimensions (e.g., length, width, height) of a 3D object. "defining the aspect ratio of the generated object in canonical space"
- attention structure: The attention mechanism within transformer architectures that scales to combine different feature streams. "Benefiting from the scalability of the attention structure"
- bounding box condition: A conditioning signal that specifies object size/proportions via a 3D bounding box to guide generation. "we propose the bounding box condition to control the aspect ratio."
- canonical space: A normalized, consistent coordinate system used to define object geometry and constraints. "in canonical space"
- ControlNet: A method for 2D controllable diffusion that injects structural conditions (e.g., edges, depth) into image generation. "Methods such as ControlNet~\cite{zhang2023adding}, T2I-Adapter~\cite{mou2024t2i}, and IP-Adapter~\cite{ye2023ip} introduce various structured conditions"
- cross-modal controls: Control signals drawn from different modalities (e.g., images, point clouds, voxels) used to guide generation jointly. "lack fine-grained, cross-modal controls"
- DINO features: Visual features extracted by a self-supervised vision transformer (DINO) used as image conditioning. "concatenate the extracted embeddings with the DINO features of the input image."
- DINO-v2: A self-supervised image encoder used to obtain robust image embeddings for conditioning. "we utilize DINO-v2-Large~\cite{oquab2023dinov2} to extract image features."
- difficulty-aware sampling: A training strategy that biases sampling toward harder conditions to improve robustness. "a progressive, difficulty-aware sampling strategy"
- Diffusion Transformer (DiT): A transformer-based architecture tailored for diffusion models. "Hunyuan3D-Omni leverages a Diffusion Transformer (DiT) and VAE-based decoder"
- EDM: A diffusion modeling formulation referenced as a baseline replaced by flow matching in later works. "replacing EDM with flow matching"
- flow matching: A generative training objective that learns a velocity field to transport noise to data distribution. "For a flow matching model used in Hunyuan3D 2.1"
- ill-posed problem: A problem lacking sufficient information for a unique or stable solution, common in single-view 3D reconstruction. "generating 3D assets from a single image remains an ill-posed problem"
- iso-surface extraction: A technique (e.g., Marching Cubes) to extract a surface mesh from a scalar field like an SDF. "leverage the iso-surface extraction to obtain explicit mesh output."
- latent diffusion model (LDM): A diffusion model operating in a learned latent space rather than pixel/voxel space. "the 3D latent diffusion model (LDM)"
- LiDAR: A sensor modality that measures distances using laser light to produce 3D point clouds. "LiDAR scans, and RGBD sensors."
- LoRA finetuning: A parameter-efficient finetuning method using low-rank adapters to condition or adapt large models. "via LoRA finetuning"
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert subnetworks to improve capacity/efficiency. "incorporating MoE architectures."
- multi-view consistency: The requirement that generated or reconstructed geometry remains consistent across multiple viewpoints. "multi-view consistency issues"
- NeuS: A neural implicit surface method for reconstructing surfaces from images. "NeuS~\cite{wang2021neus}"
- point cloud completion: The task of inferring missing parts of a point cloud to obtain a complete shape. "point cloud completion methods~\cite{yan2022fbnet,yu2021pointr,yan2025symmcompletion}"
- point cloud condition: A conditioning signal consisting of 3D points that guides geometry generation. "we introduce the point cloud condition."
- pose control signals: Conditioning inputs (e.g., skeletons) that determine the pose of generated 3D characters. "PoseMaster~\cite{yan2025posemaster} incorporates pose control signals"
- position embedding: A feature encoding that injects spatial position information into point or token features. "We then apply a position embedding"
- radiance fields: Volumetric scene representations mapping 3D positions and viewing directions to emitted light and density. "radiance fields~\cite{mildenhall2021nerf}"
- RGBD sensors: Sensors that capture aligned color (RGB) and depth (D) information. "RGBD sensors."
- rig and skin: The process of attaching a skeleton (rig) to a mesh and binding (skinning) vertices to bones for animation. "modelers typically rig and skin characters"
- Signed Distance Function (SDF): A scalar field giving the signed distance to the nearest surface; its zero level-set defines the surface. "Signed Distance Function (SDF) field"
- skeleton condition: A conditioning signal composed of skeletal joint/bone coordinates used to control pose. "we introduce the skeleton condition."
- tri-plane radiance field: A compact 3D representation that uses three orthogonal feature planes to define radiance fields. "a tri-plane radiance field"
- unified control encoder: A shared encoder that ingests multiple control modalities (points, voxels, boxes, skeletons) and produces condition features. "we propose a unified control encoder"
- VecSet: A latent vector-set representation of 3D shapes used by VAE/LDM frameworks. "VecSet representation employs a 3D VAE to compress point clouds into a VecSet"
- voxel condition: A conditioning signal representing geometry as occupied voxel centers to guide generation. "the voxel condition provides sparse geometric cues"
Collections
Sign up for free to add this paper to one or more collections.

