- The paper introduces Reward Forcing, combining EMA-Sink and Rewarded Distribution Matching Distillation to overcome motion stagnation and improve temporal coherence in video generation.
- EMA-Sink compresses the full generation history with constant memory, efficiently preserving global context and mitigating issues of frame copying.
- Rewarded Distribution Matching Distillation leverages a reward model to bias training towards dynamic sequences, achieving over 80% improvement in motion scores and real-time performance at 23.1 FPS.
Reward Forcing: Efficient Streaming Video Generation with Rewarded Distribution Matching Distillation
Introduction
Efficient streaming video generation with dynamic and interactive content is a pressing challenge, especially as models transition from high-fidelity but slow bidirectional diffusion frameworks to real-time deployable systems. The paper "Reward Forcing: Efficient Streaming Video Generation with Rewarded Distribution Matching Distillation" (2512.04678) introduces a method that addresses persistent issues in long-horizon, autoregressive video generation, particularly the loss of motion dynamics and temporal consistency when conventional sliding window or static attention sink mechanisms are employed. The proposed framework integrates two principal technical innovations: the Exponential Moving Average Sink (EMA-Sink) state packaging mechanism, and Rewarded Distribution Matching Distillation (Re-DMD) which synergistically enable both high visual fidelity and dynamic scene evolution in real-time video generation.
Technical Innovations
EMA-Sink: State Packaging for Long Videos
Conventional autoregressive models with sliding window attention optimize inference speed by limiting the attention context to most recent frames, but this induces a historical information bottleneck, degrading global coherence and enabling undesirable phenomena such as "frame copying"—an over-reliance on initial frames for context generation. The addition of static attention sinks, which persistently cache initial tokens, partially mitigates drift but exacerbates motion stagnation.
The EMA-Sink module resolves both issues by compressing the entire generation history into a fixed-size representation via exponential moving average updates. When a frame token is evicted from the sliding window, its key-value embeddings are fused into the sink state using a tunable momentum α. This mechanism preserves both long-term global context and recent dynamics in a compact, differentiable form, maintaining O(1) eviction/merge cost and constant memory with respect to sequence length. This allows window attention to operate efficiently while enabling queries to attend to both local detail and evolutive global history, thus breaking the historical bottleneck endemic to streaming models.
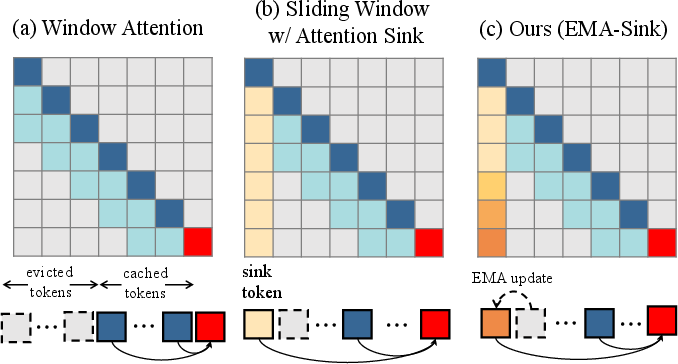
Figure 1: EMA Sink mechanism comparison. Window attention and static attention sink methods are contrasted with EMA Sink’s full-history compression approach which avoids both context truncation and initial-frame overdependence.
Rewarded Distribution Matching Distillation (Re-DMD)
Distribution Matching Distillation (DMD) is a standard approach for distilling multi-step diffusion teacher models into few-step autoregressive generators by minimizing divergence between teacher and student output distributions. However, DMD’s indiscriminate treatment of all samples leads to poor differentiation between high-fidelity, dynamic sequences and stagnated outputs. The proposed Rewarded DMD (Re-DMD) introduces a reward-weighted objective, leveraging a pretrained vision-LLM to score motion quality. These reward signals modulate the contribution of each sample to the distillation loss. The gradient of the student is thus biased towards regions exhibiting higher reward (greater dynamics), accelerating convergence to motion-rich, temporally consistent generations without introducing instability typical of RL objectives.
The EM-based implementation of Re-DMD operates with the reward as a static weight on the loss, avoiding gradient flow back through the reward model. This detaches reward estimation from generator update, ensuring robustness and computational efficiency.
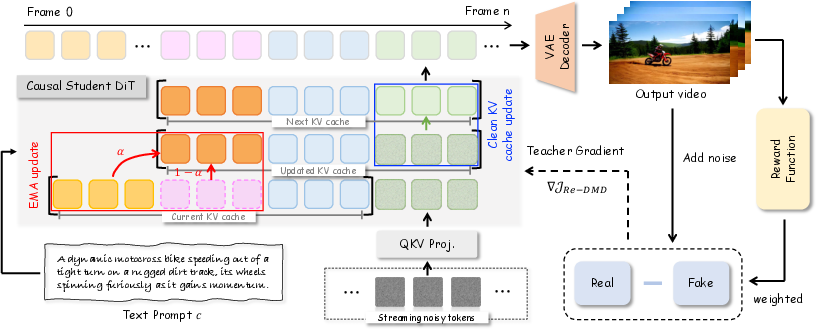
Figure 2: Reward Forcing pipeline. Noisy tokens generate KV pairs for attention; evicted tokens feed EMA Sink; decoded samples are scored by a reward model for weighted gradients in distribution matching.
Experimental Evaluation
Short and Long Video Generation
Reward Forcing was benchmarked on the 1.3B parameter Wan2.1-T2V backbone, using both extended VBench and MovieGen test suites for short and long video generation. Quantitative results demonstrate that the method achieves a total VBench score of 84.13 in the short video setting and 81.41 for long (60s+) video generation, outperforming state-of-the-art baselines by nontrivial margins—notably, its dynamic amplitude (motion score) is improved by over 80% relative to LongLive, with drift reduced concurrently, indicating successful mitigation of motion stagnation and visual inconsistency observed in prior methods.
Ablation reveals EMA-Sink and Re-DMD are both critical: omitting Re-DMD induces a ~30% reduction in dynamic scores, while removal of EMA-Sink leads to severe frame copying and qualitative degradation. Hyperparameter sweeps on α (EMA weight) and β (reward influence) further clarify tradeoffs between dynamism, temporal consistency, and image integrity.

Figure 3: Qualitative comparison in dynamic complexity. Reward Forcing generates sequences with both high text alignment and motion, outperforming baselines with clearly diminished dynamics.

Figure 4: Temporal consistency over long horizons. Reward Forcing preserves coherence beyond 1 minute, while baselines manifest drift, jitter, and context loss.
Real-Time and Interactive Capabilities
Owing to the fixed-size history compression and sliding window attention, Reward Forcing operates at 23.1 FPS on a single H100 GPU, supporting online, interactive video generation. Prompt-alteration during generation is feasible without quality degradation, enabled by dynamic cross-attention cache management and the inherent robustness of EMA-Sink for blending context following prompt switches.

Figure 5: Interactive video generation example. Seamless transition between prompts and stable content adaptation are observed due to EMA-Sink.
Ablation and Efficiency Analysis
Exhaustive ablations validate the individual and joint impact of each module. The EMA coefficient α controls the memory/compression trade-off, with values near 0.99 best balancing context preservation and drift control. Reward influence parameter β tunes selectivity: lower values prioritize dynamics at the risk of reduced fidelity. Crucially, the O(1) compression and window-based attention decouple compute and memory from total sequence length, allowing orders-of-magnitude improvements in inference throughput compared to prior bidirectional diffusion systems.

Figure 6: Left: Qualitative improvement as modules are added. Right: Dynamic score increases steadily during training, and FPS increases as window size is reduced.
Theoretical and Practical Implications
The combination of EMA-Sink and Re-DMD presents a significant architectural advance: EMA-Sink enables indefinite streaming generation without sacrificing either global coherence or computational efficiency, a bottleneck in all prior dense-attention or static sink token strategies. Re-DMD establishes a reward-aligned distillation paradigm, permitting diffusion student models to internalize complex, subjective desiderata—here, dynamic motion—without end-to-end RL overhead. These advances indicate reward-weighted distributional training is an effective proxy for RL in the video domain, especially where reward annotation is expensive or policy gradients are unstable.
Practically, the resulting pipeline is robust, modifiable, and can be readily transplanted into contemporary video diffusion architectures. The real-time interactive demo demonstrates fluid adaptability to user interventions, a core requirement for synthetic virtual world simulation, digital entertainment, and advanced human-computer interaction.
Outlook and Future Directions
While Reward Forcing excels in dynamic consistency and long-horizon fidelity, perfect alignment between reward models and human perception remains unsolved, as reward predictors typically lack discrimination for nuanced aspects like subtle motion artifacts or high-level narrative coherence. Further improvements in reward modeling, especially those utilizing hierarchical, multitask, or feedback-looped (human-in-the-loop) paradigms, will likely amplify the efficacy of Re-DMD-type approaches. Additionally, the O(1) EMA-Sink history mechanism introduces new directions for memory-efficient, context-rich generative models across modalities.
Conclusion
Reward Forcing effectively addresses key limitations in streaming video generation via the EMA-Sink state packaging mechanism and Rewarded Distribution Matching Distillation. It achieves both high inference throughput and state-of-the-art quality, notably boosting motion dynamics and reducing quality drift over minute-scale generations. These contributions enable scalable and interactive video synthesis, providing a foundation for both research exploration and real-world deployment in virtual world simulation and interactive digital content creation.

