C4D: 4D Made from 3D through Dual Correspondences (2510.14960v1)
Abstract: Recovering 4D from monocular video, which jointly estimates dynamic geometry and camera poses, is an inevitably challenging problem. While recent pointmap-based 3D reconstruction methods (e.g., DUSt3R) have made great progress in reconstructing static scenes, directly applying them to dynamic scenes leads to inaccurate results. This discrepancy arises because moving objects violate multi-view geometric constraints, disrupting the reconstruction. To address this, we introduce C4D, a framework that leverages temporal Correspondences to extend existing 3D reconstruction formulation to 4D. Specifically, apart from predicting pointmaps, C4D captures two types of correspondences: short-term optical flow and long-term point tracking. We train a dynamic-aware point tracker that provides additional mobility information, facilitating the estimation of motion masks to separate moving elements from the static background, thus offering more reliable guidance for dynamic scenes. Furthermore, we introduce a set of dynamic scene optimization objectives to recover per-frame 3D geometry and camera parameters. Simultaneously, the correspondences lift 2D trajectories into smooth 3D trajectories, enabling fully integrated 4D reconstruction. Experiments show that our framework achieves complete 4D recovery and demonstrates strong performance across multiple downstream tasks, including depth estimation, camera pose estimation, and point tracking. Project Page: https://littlepure2333.github.io/C4D




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
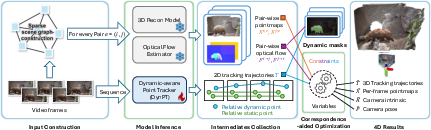
This paper introduces a method called C4D that turns a regular video taken by a single camera (a phone, for example) into a smooth, time-varying 3D scene—what the authors call “4D” (3D + time). It can figure out the scene’s shape every frame, where the camera is and how it moves, which parts of the scene are moving (like people or cars), and even track specific points over time in both 2D and 3D. The big idea is to use two kinds of “correspondences” between frames—short-term motion and long-term point tracking—to handle moving objects that usually break traditional 3D reconstruction methods.
What questions are the researchers trying to answer?
- Can we recover a complete 4D scene (changing 3D shape + camera motion) from a single handheld video?
- How can we tell the difference between motion caused by the camera moving and motion caused by things in the scene moving?
- Can we improve camera pose estimation, depth estimation, and point tracking in dynamic scenes by combining short-term motion and long-term tracking information?
How did they do it? (Approach explained simply)
Think of a video like a flipbook. Each page is a picture. If you want a 3D model that changes over time, you need to know:
- where each pixel moves between frames (short-term motion), and
- where specific points in the scene go over many frames (long-term tracking).
C4D builds on a successful 3D method (DUSt3R), which creates a “pointmap”—a dense 3D point for each pixel—by aligning pairs of images. That works great when the scene is still. But when parts of the scene move, alignment gets confusing because the assumptions used for static scenes no longer hold. C4D fixes this with two key additions:
Two kinds of correspondences
1) Short-term optical flow This is like drawing tiny arrows for each pixel to show how it shifts from one frame to the next. It’s dense and immediate but only looks one step ahead.
2) Long-term point tracking This picks a set of “dots” in the first frame and follows them over many frames, even if they disappear and reappear. The paper introduces a new tracker called DynPT (Dynamic-aware Point Tracker) that does something special: it not only tracks where a point goes and whether it is visible, but also predicts whether the point is moving in the real world. That means it can tell if a dot’s movement is because the object itself moved or because the camera moved.
Motion masks (finding what’s really moving)
C4D combines the “moving/not moving” hints from DynPT with optical flow to estimate a motion mask—an image that highlights the parts of the scene that are truly moving in the world (like a person walking), and separates them from the static background (like a wall). How? In simple terms:
- It uses static points to learn the “rules” of how two frames should relate if only the camera moved (this corresponds to epipolar geometry, but you can think of it like checking if lines of sight from two camera positions agree).
- If some areas don’t follow those rules, they’re marked as dynamic (moving objects).
- It repeats this with nearby frames and combines the results to get a reliable motion mask for each frame.
Optimization that keeps everything consistent and smooth
After figuring out what’s static and what’s moving, C4D improves the 4D reconstruction with three “rules” during optimization:
- Camera Movement Alignment (CMA): In static regions, the camera’s estimated movement should match the optical flow. This keeps camera motion accurate even when there are moving objects elsewhere.
- Camera Trajectory Smoothness (CTS): The camera path shouldn’t have sudden, unrealistic jumps.
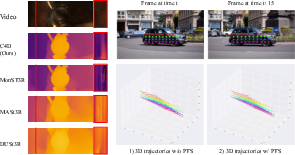
- Point Trajectory Smoothness (PTS): 3D points should move smoothly over time (like smoothing the path of a sticker you’re tracking across the flipbook), while allowing flexibility for real changes.
With these steps, C4D outputs:
- per-frame 3D point clouds (dense 3D points),
- depth maps,
- camera poses (position and orientation) and camera intrinsics (internal camera settings like focal length),
- motion masks,
- 2D and 3D point tracks (following dots in image space and in world 3D space).
What did they find, and why is it important?
The authors tested C4D on several datasets with both synthetic and real scenes. In short, C4D consistently improves results compared to standard 3D-only methods and competes well with specialized systems.
Highlights:
- Camera pose estimation improved a lot in dynamic scenes. For example, on a tough synthetic dataset (Sintel), a baseline had large rotation errors; with C4D this dropped dramatically (from about 18 to under 1 in their reported metric), showing much more reliable camera motion.
- Video depth estimation became more accurate and more temporally smooth, which helps avoid “wobbly” depth over time.
- Point tracking performed competitively with top trackers, and DynPT adds a unique capability: predicting whether a tracked point is truly moving in the real world. That extra information makes motion masks more accurate.
- The method works across different model backbones (like DUSt3R, MASt3R, and MonST3R), and even helps in static scenes, showing it’s a robust improvement rather than a niche trick.
Why it matters:
- Many modern applications need reliable 4D understanding from ordinary videos: AR/VR, robotics, sports analysis, film post-production, and scene editing.
- Separating camera motion from object motion is hard but crucial. C4D’s motion masks and dynamic-aware tracking make downstream tasks more reliable.
- Smoother camera paths and point trajectories make results look and feel more realistic.
What is the potential impact?
By upgrading 3D reconstruction to full 4D using dual correspondences (short-term flow + long-term tracking), C4D makes it possible to:
- build consistent, time-varying 3D models from everyday videos,
- track moving objects in 3D, while accurately estimating the camera,
- integrate with existing 3D methods to handle dynamic scenes without retraining everything from scratch.
This can improve how we analyze, edit, and interact with videos: from stabilizing footage and inserting virtual objects that stick to the scene, to helping robots understand moving environments and enabling richer 3D storytelling in media and games.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future work.
- Dependence on off-the-shelf optical flow: quantify how reconstruction accuracy and camera pose estimation degrade with flow errors (e.g., motion blur, large displacements, repetitive textures), and explore more robust or uncertainty-aware flow integration.
- Motion mask thresholding and fusion: the Sampson-error threshold and union across pairs are not specified or validated; develop adaptive, data-driven thresholds and multi-frame probabilistic fusion to reduce false positives/negatives.
- Reliance on sufficient static correspondences: the fundamental matrix and CMA require enough reliable static points; design fallback strategies for scenes with pervasive dynamics or minimal static background, including static-point discovery or synthetic constraints.
- Domain gap of DynPT mobility prediction: trained on Kubric synthetic data; assess and mitigate generalization to real-world videos (e.g., mobility accuracy on DAVIS/Kinetics), including domain adaptation, fine-tuning, and real mobility annotation collection.
- Binary mobility labels: move beyond static/dynamic classification to continuous mobility, rigidity, or deformation magnitudes to better handle articulated, non-rigid objects and partial motions.
- Occlusion and long-term re-identification in 3D: current PTS uses tracks visible in a local window; develop strategies to lift and stitch 3D trajectories across occlusions and long gaps with identity consistency.
- Camera intrinsics estimation: K is optimized per-frame, which is typically unrealistic; enforce global intrinsics constraints, evaluate intrinsics accuracy against ground truth, and paper failure modes when intrinsics vary improperly.
- Absolute metric scale: results are reported with scale or scale-and-shift alignment; propose mechanisms to recover absolute scale from monocular input (e.g., object-size priors, gravity, IMU, or learned scale) and benchmark metric-scale accuracy.
- Degenerate epipolar cases: investigate robustness under pure rotations, planar scenes, very small baselines, or near-degenerate motion where fundamental matrix estimation is unstable; include detection and alternative formulations (e.g., homographies).
- Rolling-shutter and lens distortion: extend the camera model beyond pinhole with RS and distortion parameters; quantify their effects on CMA, F-estimation, and pose recovery.
- Dynamic-aware global alignment: clarify whether dynamic regions are masked in the GA loss; if not, introduce dynamic-aware GA to prevent collapsing moving objects and measure its impact on accuracy.
- Accuracy of dynamic object reconstruction: beyond smoothing, evaluate per-frame 3D geometry fidelity of moving objects (e.g., instance-level IoU/Chamfer vs. ground truth) and develop object-wise motion models.
- Over-smoothing from PTS: PTS may smear motion boundaries or dampen true dynamics; add edge-aware, piecewise-rigid, or physically grounded priors to preserve sharp motions and object boundaries.
- Uncertainty propagation: incorporate calibrated uncertainties from pointmaps, flow, tracking, and mobility predictions into optimization (e.g., probabilistic weighting) to improve robustness.
- Hyperparameter sensitivity: systematically analyze and provide guidance for loss weights (w_GA, w_CMA, w_CTS, w_PTS), window sizes, and thresholds; explore automatic tuning or meta-learning.
- Runtime and scalability: report computational cost, memory footprint, and throughput; paper scaling to high-resolution, long videos, and streaming/real-time operation with windowed optimization.
- Loop closure and drift: current optimization uses local windows; add global graph optimization and loop closure to reduce long-term drift and improve trajectory consistency.
- Dataset coverage: evaluate on more diverse real-world dynamics (outdoor traffic, crowds, handheld mobile footage), low-light, heavy blur, specular/transparent surfaces, and quantify failure cases.
- Mobility evaluation on real data: mobility is validated only on Kubric; create real-world benchmarks with mobility labels to measure world-motion classification in the wild.
- Multi-object dynamics and instances: move from a single motion mask to instance-level segmentation with per-object trajectories and motion fields; evaluate object-level tracking and 4D reconstruction.
- Representation trade-offs: compare pointmap-based C4D to 3DGS-based 4D methods in accuracy, runtime, and memory; explore hybrid representations.
- End-to-end training: current pipeline relies on pretrained DUSt3R and separate optimization; investigate joint training of pointmaps, correspondences, motion masks, and 4D objectives for better synergy.
- Initialization robustness: paper optimization stability under poor GA or flow/tracking initialization; design robust warm-starts or coarse-to-fine strategies.
- Robust fundamental matrix estimation: evaluate LMedS vs. RANSAC/MLESAC with confidence weighting; integrate track and flow uncertainties into model fitting.
- Temporal alignment: handle variable frame rates or irregular timestamps; incorporate time-aware models (e.g., non-uniform temporal spacing) in CMA/PTS.
- Pose evaluation fairness: for methods requiring intrinsics vs. C4D estimating intrinsics, assess how intrinsics errors affect pose metrics and propose standardized protocols.
- DynPT design ablation: provide and analyze ablations for the 3D-aware ViT encoder, mobility head architecture, number of transformer iterations, and feature fusion choices to justify design decisions.
- Handling specularities/transparency: design semantics-aware masking or robust correspondence strategies where epipolar/flow constraints often fail.
- CTS formulation details: quantify CTS effects on translational scale and rotational smoothness; ensure it does not bias pose toward overly smooth trajectories.
- Reproducibility: provide full optimization schedules, hyperparameters, and training details (e.g., in supplementary/code) to enable consistent replication across datasets and settings.
Practical Applications
Immediate Applications
The paper’s C4D framework enables practical deployments today by producing per-frame dense point clouds, camera poses and intrinsics, motion masks, depth maps, and 2D/3D point trajectories from a single monocular video. The following use cases can leverage these outputs without fundamental research breakthroughs:
- Media and VFX (software/content creation)
- Use case: Robust camera tracking and 4D scene reconstruction from handheld or drone footage without fiducials; object-aware compositing via motion masks; consistent depth-based effects (relighting, defocus, volumetric inserts).
- Tools/workflows: Plugins for Nuke/After Effects/Blender, point cloud export to Unreal/Unity; automated rotoscoping using motion masks; camera solve using C4D’s poses and intrinsics.
- Dependencies/assumptions: Sufficient scene texture and parallax; reliable optical flow; manageable motion blur; adequate compute for optimization; rights to use footage.
- AR content authoring (software/education)
- Use case: Convert short smartphone videos into occlusion-aware 4D scenes for AR filters/effects; depth-aware stickers; scene-aware virtual object placement.
- Tools/workflows: Mobile app or cloud service that uploads footage and returns depth, point cloud, and motion masks; SDK that wraps C4D outputs for ARKit/ARCore.
- Dependencies/assumptions: Good lighting; textured surfaces; offline processing latency acceptable.
- Robotics R&D (robotics)
- Use case: Offline reconstruction and pose estimation from monocular robot logs in dynamic environments; segment moving machinery vs static infrastructure; improved benchmarking of VO/SLAM in dynamics.
- Tools/workflows: Evaluation harness that compares C4D camera trajectories to ground truth; fusion with SLAM pipelines as post-processing to refine trajectories using CMA/CTS/PTS objectives.
- Dependencies/assumptions: Non-real-time acceptable; domain-specific optical flow models may improve results; minimal rolling shutter or compensated in pre-processing.
- Autonomous driving data curation (automotive/software)
- Use case: Post-process dashcam/road videos to generate 4D reconstructions for simulation, dataset augmentation, and trajectory analysis of vehicles/pedestrians; separate dynamic actors using motion masks.
- Tools/workflows: Batch pipeline integrated with video ingestion systems; export dynamic 3D tracks for behavior modeling.
- Dependencies/assumptions: Wide-baseline not required but temporal windowing helps; traffic scenes with sufficient visual features; accurate optical flow in outdoor conditions.
- Sports analytics (media/sports)
- Use case: Reconstruct player/ball 3D trajectories from broadcast footage; segment play dynamics vs crowd/background via DynPT mobility and motion masks; generate tactical heatmaps in 3D.
- Tools/workflows: Cloud analytics service ingesting game clips; dashboards visualizing lifted 3D tracks and camera motion; export to coaching platforms.
- Dependencies/assumptions: Camera intrinsics estimated reliably from footage; broadcast compression and occlusion handled; multi-camera stitching optional but not required.
- Industrial inspection and safety (industry/energy)
- Use case: 4D mapping of factory floors to differentiate static infrastructure from moving assets; detect unsafe motion patterns; reconstruct equipment geometry from walkthrough videos.
- Tools/workflows: Inspection app that processes videos to point clouds and motion masks; integration into digital maintenance logs.
- Dependencies/assumptions: Controlled capture pathways; reflective/specular surfaces may degrade optical flow; privacy compliance for worker footage.
- Retail analytics (retail/software/policy)
- Use case: Store layout 3D reconstruction; customer flow analysis using motion masks and lifted trajectories; planogram validation in 3D.
- Tools/workflows: Video-to-4D analytics service; integration with BI tools; alerts for congestion based on dynamic density fields.
- Dependencies/assumptions: Privacy-preserving pipelines (face/body blur); signage/texture quality; store lighting variability.
- Healthcare video analysis (healthcare/academia)
- Use case: Offline surgical video analysis: instrument/object 3D trajectories, occlusion-aware motion masks; quantification of tool dynamics relative to anatomy.
- Tools/workflows: Research pipelines producing trajectory metrics; export to surgical skill assessment tools.
- Dependencies/assumptions: Domain adaptation for specularities/blood; strict data governance; not for clinical decision-making without validation.
- Forensics and accident reconstruction (public safety/policy)
- Use case: Reconstruct 3D trajectories and camera motion from witness smartphone footage; separate moving actors via motion masks for timeline building.
- Tools/workflows: Evidence processing suite that outputs 4D scene and annotated tracks; court-ready visualization exports.
- Dependencies/assumptions: Chain-of-custody and reproducibility; documented parameter settings; uncertainty quantification for admissibility.
- Real estate and interior design (property/software)
- Use case: Generate object-aware 3D scans from walkthrough videos; remove dynamic clutter (people/pets) via motion masks; depth for staging and measurement.
- Tools/workflows: Mobile capture apps that produce point clouds and poses; integration with CAD/staging tools.
- Dependencies/assumptions: Adequate scene texture; minimal rolling shutter; offline processing latency.
- Academic datasets and benchmarking (academia)
- Use case: Create 4D benchmarks from public videos; analyze VO/SLAM robustness in dynamic scenes; paper optimization objectives (CMA/CTS/PTS) effects.
- Tools/workflows: Open-sourced preprocessing scripts; standardized metrics for dynamic scene reconstruction.
- Dependencies/assumptions: Licensing for dataset creation; consistent evaluation protocols.
Long-Term Applications
The following applications are feasible but require further research, scaling, optimization, or regulatory clearance to deploy widely or in real time:
- Real-time on-device 4D reconstruction for AR navigation (mobile/AR/robotics)
- Use case: Live occlusion-aware AR and pathfinding indoors/outdoors with monocular cameras; robust ego-motion in crowds.
- Tools/workflows: Optimized C4D variants with model compression, hardware acceleration; tight integration with ARKit/ARCore and IMU fusion.
- Dependencies/assumptions: Significant speedups and latency guarantees; energy efficiency; handling rolling shutter and motion blur in real time.
- Autonomous driving perception with monocular-only 4D (automotive/robotics)
- Use case: Replace or complement LiDAR with monocular 4D reconstruction in dynamic urban scenes; robust ego-motion and actor tracking under occlusion.
- Tools/workflows: Safety-critical stacks combining C4D outputs with detection and planning; simulation-in-the-loop.
- Dependencies/assumptions: Extensive validation, redundancy, and certification; extreme robustness to weather/night; failure mode detection.
- Drone-based 4D inspection and mapping (energy/infrastructure)
- Use case: Live reconstruction of facilities (bridges, plants) with dynamic object segmentation; vibration/change detection over time.
- Tools/workflows: Edge inference on drones; cloud post-processing for high fidelity; alignment across missions for digital twins.
- Dependencies/assumptions: Domain-adapted optical flow for specular/textureless surfaces; GPS-denied robustness; safety compliance.
- City-scale digital twins from CCTV (smart cities/policy)
- Use case: Convert large camera networks into privacy-preserving 4D models for planning, traffic optimization, and emergency response simulation.
- Tools/workflows: Distributed processing with privacy-by-design (on-device segmentation and anonymization); federated learning for model updates.
- Dependencies/assumptions: Governance frameworks; compute and storage scalability; strict access control.
- Generative 4D editing and synthesis (media/software)
- Use case: Combine C4D with generative video models to perform physically consistent edits (object insertion/removal, motion retiming) maintaining geometric coherence over time.
- Tools/workflows: Hybrid pipelines that use C4D for geometry/pose constraints and diffusion/transformer models for appearance; artist-in-the-loop tools.
- Dependencies/assumptions: Stable coupling between geometry and generative models; guardrails to prevent artifacts/drift.
- Surgical AR guidance (healthcare)
- Use case: Real-time 4D reconstruction of the surgical field for instrument guidance and anatomy tracking with monocular endoscopes.
- Tools/workflows: Certified devices integrating C4D-like modules with domain-specific priors; latency-bounded pipelines.
- Dependencies/assumptions: Clinical validation, regulatory approval; robustness to fluids/specularities/tissue deformation; fail-safes.
- Free-viewpoint sports and live broadcast from minimal cameras (media/sports)
- Use case: Real-time 4D recon from one or few broadcast cameras to enable virtual replays and viewpoint changes.
- Tools/workflows: On-prem GPU clusters; multi-camera synchronization when available; fast motion mask estimation.
- Dependencies/assumptions: Ultra-low latency; resilience to crowd occlusions; hardware scaling.
- Multi-agent collaborative 4D mapping (robotics)
- Use case: Several robots share monocular video streams to build consistent 4D maps with dynamic segmentation.
- Tools/workflows: SLAM backends augmented with C4D constraints; distributed optimization over temporal windows; robust correspondence sharing.
- Dependencies/assumptions: Communication bandwidth and synchronization; failure recovery; adversarial robustness.
- Industrial process monitoring and predictive maintenance (industry/energy)
- Use case: Long-horizon 4D tracking of machinery, detecting abnormal motion patterns and geometry changes.
- Tools/workflows: Time-series analytics over lifted 3D trajectories; alerts tied to maintenance systems; correlation with sensor data.
- Dependencies/assumptions: Domain adaptation for harsh environments; compatibility with safety standards; calibration drift management.
- Standards and policy frameworks for 4D recon in evidence and privacy (policy)
- Use case: Establish best practices for forensic 4D reconstruction (uncertainty reporting, reproducible pipelines) and privacy-preserving deployment in public spaces.
- Tools/workflows: Auditable software stacks, watermarking of reconstructions, standardized metrics for reliability.
- Dependencies/assumptions: Multi-stakeholder input; legal harmonization; clear data retention policies.
Notes on common assumptions and dependencies across applications:
- Input modality: monocular RGB videos; performance improves with textured scenes, adequate parallax, and stable exposure.
- Model components: quality of optical flow and point tracking (DynPT) is critical; motion mask thresholds and robust fundamental matrix estimation influence segmentation accuracy.
- Optimization: C4D’s correspondence-aided objectives (CMA/CTS/PTS) require sufficient temporal coverage; sliding window strategies balance compute and accuracy.
- Generalization: pretraining on synthetic (Kubric) and static-scene weights (DUSt3R/MASt3R) may require domain adaptation for specialized environments (e.g., surgical, industrial).
- Compute: current pipeline is well-suited to offline/batch processing; real-time applications demand acceleration, model compression, and hardware support.
- Calibration: C4D estimates intrinsics and poses, but extreme rolling shutter, lens distortion, or non-standard optics may necessitate calibration or compensation.
Glossary
- 3DGS (3D Gaussian Splatting): A point/gaussian-based scene representation used for fast, differentiable 3D/4D rendering and optimization. "Building on either 3DGS~\cite{kerbl20233d} or pointmap~\cite{wang2024dust3r} representation"
- Absolute Relative Error (Abs Rel): A scale-invariant depth metric measuring mean absolute relative deviation between predicted and ground-truth depths. "The evaluation metrics for depth estimation are Absolute Relative Error (Abs Rel), Root Mean Squared Error (RMSE), and the percentage of inlier points"
- Absolute Translation Error (ATE): A camera trajectory metric quantifying global drift in translation after alignment to ground truth. "We report the metrics of Absolute Translation Error (ATE), Relative Translation Error (RPE trans), and Relative Rotation Error (RPE rot)."
- Average Jaccard (AJ): A tracking metric measuring overlap between predicted and ground-truth visibility/track segments. "We use the metrics of occlusion accuracy (OA), position accuracy ($\delta_{\text{avg}^x$), and average Jaccard (AJ) to evaluate this benchmark"
- Bundle Adjustment: A joint nonlinear optimization over camera poses and 3D structure to minimize reprojection error. "triangulation, and bundle adjustment~\cite{agarwal2010bundle, triggs2000bundle}"
- Camera Intrinsics: The internal calibration parameters of a camera (e.g., focal length, principal point). "Note that DROID-SLAM, DPVO, and LEAP-VO require ground-truth camera intrinsics as input"
- Camera Movement Alignment (CMA): A loss/objective encouraging estimated ego-motion to match optical flow in static regions. "we introduce the Camera Movement Alignment (CMA) objective"
- Camera Pose: The position and orientation of the camera in the world coordinate system. "camera pose estimation"
- Camera Trajectory Smoothness (CTS): A regularization objective penalizing abrupt changes in camera rotation and translation. "The Camera Trajectory Smoothness (CTS) objective is commonly used in visual odometry"
- Causal Videos: Video setting where predictions for a frame can only use current and past frames (not future). "achieving strong performance on causal videos."
- Correspondence-aided Optimization: Optimization that leverages temporal correspondences (e.g., flow, tracks) to refine geometry/poses. "We introduce correspondence-aided optimization techniques to improve the consistency and smoothness of 4D reconstruction."
- Dynamic-aware Point Tracker (DynPT): A tracker that predicts positions, occlusions, and whether points are dynamic in world coordinates. "We introduce the Dynamic-aware Point Tracker (DynPT), which differentiates between motion caused by the camera and true object dynamics."
- Ego-motion: The motion of the camera itself between frames. "CMA encourages the estimated ego motion to be consistent with optical flow in static regions."
- Ego-motion Field: The pixel displacement field induced by the camera motion given the current 3D estimate. "we compute the ego-motion field "
- Epipolar Constraints: Geometric constraints that corresponding points across two views lie on matching epipolar lines. "violates the epipolar constraints"
- Fourier Encoded Embedding: A positional encoding technique using sinusoidal functions to represent displacements. "represents Fourier Encoded embedding of per-frame displacements."
- Frobenius Norm: A matrix norm equal to the square root of the sum of squares of all entries, used for rotation smoothness. "where denotes the Frobenius norm"
- Fundamental Matrix: A matrix relating corresponding points in two uncalibrated views via the epipolar constraint. "we then estimate the fundamental matrix between the two frames via the Least Median of Squares (LMedS) method"
- Global Alignment (GA): An optimization that aligns locally predicted pointmaps into a single global coordinate frame. "Based on the Global Alignment (GA) objective described in Sec~\ref{sec:3d}"
- Homogeneous Mapping: The transformation using homogeneous coordinates to map between pixel/depth and 3D points. "where is the homogeneous mapping"
- Huber Loss: A robust loss combining L1 and L2 behaviors to reduce sensitivity to outliers. "We use Huber loss to supervise position."
- Least Median of Squares (LMedS): A robust estimator minimizing the median of squared residuals, tolerant to outliers. "via the Least Median of Squares (LMedS) method"
- Monocular Video: A single-camera video sequence without stereo or depth sensors. "Recovering 4D from monocular video"
- Motion Mask: A per-pixel segmentation of dynamic (moving) versus static regions in world coordinates. "we calculate the motion mask of the current frame using adjacent frames"
- Multi-view Geometric Constraints: Constraints linking multiple views based on projective geometry assumptions (e.g., rigidity). "moving objects violate multi-view geometric constraints"
- Occlusion Accuracy (OA): A tracking metric evaluating correctness of predicted occlusion states. "We use the metrics of occlusion accuracy (OA)"
- Optical Flow: Dense per-pixel motion between consecutive frames representing short-term correspondences. "Optical flow represents dense pixel-level motion displacement between consecutive frames"
- Point Cloud: A set of 3D points representing scene geometry. "per-frame dense point cloud"
- Point Trajectory Smoothness (PTS): A regularization encouraging temporally smooth 3D point trajectories. "we propose the Point Trajectory Smoothness (PTS) objective to smooth world coordinate pointmaps over time."
- Pointmap: A dense per-pixel 3D map predicting the 3D point corresponding to each image pixel. "dense 3D pointmaps"
- Relative Rotation Error (RPE rot): A camera pose metric measuring rotational drift between consecutive frames. "Relative Rotation Error (RPE rot)"
- Relative Translation Error (RPE trans): A camera pose metric measuring translational drift between consecutive frames. "Relative Translation Error (RPE trans)"
- Root Mean Squared Error (RMSE): A depth accuracy metric measuring the square root of mean squared error. "Root Mean Squared Error (RMSE)"
- Sampson Error: A first-order approximation of geometric reprojection/epipolar error used for robust evaluation. "we compute the error map using the Sampson error"
- Scene Graph: A graph over frames where edges denote paired images used for pairwise reconstruction. "a scene graph is constructed, where an edge represents a pair of images"
- Structure-from-Motion (SfM): A pipeline to jointly estimate camera poses and 3D structure from images. "Classic methods such as Structure-from-motion (SfM)"
- Temporal Correspondences: Matches of pixels/points across time, including short-term flow and long-term tracks. "predicts dense 3D pointmaps (Sec.~\ref{sec:3d}) and temporal correspondences"
- Triangulation: Recovering 3D point positions from multiple 2D observations and known camera poses. "matching~\cite{wu2013towards, sameer2009building}, triangulation, and bundle adjustment"
- Vision Transformer (ViT): A transformer-based architecture operating on image patches for vision tasks. "A ViT-based network "
- Visual Odometry: Estimating camera motion from video, often without building a dense global map. "learning-based visual odometry methods"
Collections
Sign up for free to add this paper to one or more collections.