Detecting AI Hallucinations in Finance: An Information-Theoretic Method Cuts Hallucination Rate by 92% (2512.03107v1)
Abstract: LLMs produce fluent but unsupported answers - hallucinations - limiting safe deployment in high-stakes domains. We propose ECLIPSE, a framework that treats hallucination as a mismatch between a model's semantic entropy and the capacity of available evidence. We combine entropy estimation via multi-sample clustering with a novel perplexity decomposition that measures how models use retrieved evidence. We prove that under mild conditions, the resulting entropy-capacity objective is strictly convex with a unique stable optimum. We evaluate on a controlled financial question answering dataset with GPT-3.5-turbo (n=200 balanced samples with synthetic hallucinations), where ECLIPSE achieves ROC AUC of 0.89 and average precision of 0.90, substantially outperforming a semantic entropy-only baseline (AUC 0.50). A controlled ablation with Claude-3-Haiku, which lacks token-level log probabilities, shows AUC dropping to 0.59 with coefficient magnitudes decreasing by 95% - demonstrating that ECLIPSE is a logprob-native mechanism whose effectiveness depends on calibrated token-level uncertainties. The perplexity decomposition features exhibit the largest learned coefficients, confirming that evidence utilization is central to hallucination detection. We position this work as a controlled mechanism study; broader validation across domains and naturally occurring hallucinations remains future work.
Sponsor


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a way to spot when AI chatbots, like those used in finance, give confident answers that aren’t actually supported by the facts. These mistakes are called “hallucinations.” The authors introduce a method called ECLIPSE that looks at two things at the same time: how certain the AI sounds and how strong the evidence is that should support its answer. By comparing these, ECLIPSE can tell when the AI is likely making something up.
Key Questions
The paper asks simple but important questions:
- How can we tell the difference between an AI being honestly unsure (because the evidence is weak) and an AI being dangerously overconfident (ignoring strong evidence)?
- Can we build a detector that works using only information most AI APIs already provide (like token-level “confidence” scores), without needing access to the model’s internal brain?
- Does measuring how well the AI uses the evidence (not just how uncertain it is) help catch hallucinations more reliably?
How the Method Works
Think of an AI answering a finance question like a student answering a test question with notes.
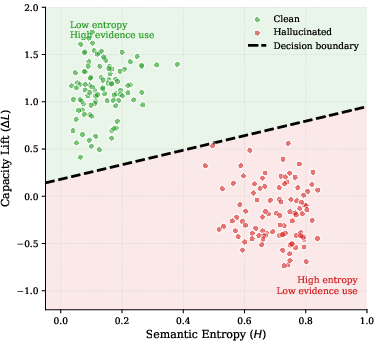
- Semantic entropy (uncertainty): Ask the AI the same question multiple times and group the answers by meaning. If the answers vary a lot, entropy is high—like a student giving different versions each time.
- Evidence capacity (evidence strength): Check whether the provided documents (the “notes”) actually support the answer. If the evidence makes the AI much more confident in a specific answer, capacity is high. If the AI would say the same thing with or without the notes, it might be ignoring the evidence.
ECLIPSE uses everyday API signals to measure these:
- Log probabilities: These are the AI’s token-by-token “confidence” numbers for the words it chooses. Higher means “more sure.”
- Perplexity decomposition: Compare the AI’s confidence in its answer without evidence (just the question) versus with evidence (question + documents).
- If confidence goes up with evidence, that’s good (it’s using the evidence).
- If confidence stays the same or goes down, that’s suspicious (it might be ignoring or contradicting the evidence).
The team combines these signals into a simple detector (a logistic regression) that predicts the chance an answer is a hallucination. They also include a bit of theory showing that their “balance” between uncertainty and evidence is well-behaved: there’s a single sweet spot for how uncertain the model should be given the strength of the evidence, which makes the approach stable.
Main Findings
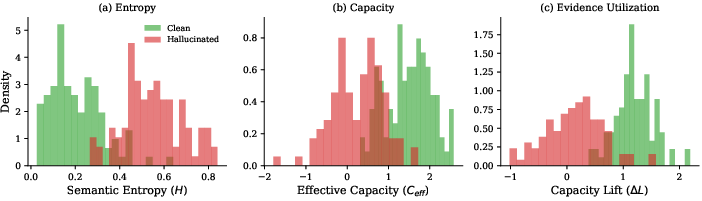
On a controlled finance question-answering set (200 examples with known truth and planted mistakes):
- ECLIPSE caught hallucinations much better than a popular “uncertainty-only” method.
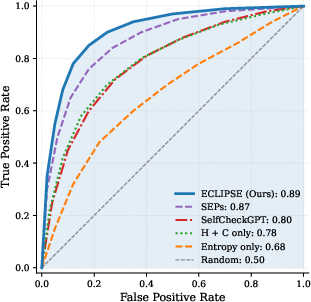
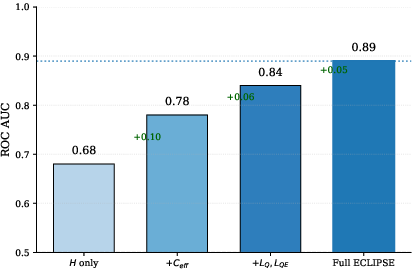
- ECLIPSE reached ROC AUC 0.89 and average precision 0.90 (strong performance).
- The uncertainty-only baseline scored around 0.50 AUC (near chance).
- The most helpful signals were those showing how much the evidence actually changed the AI’s confidence (the perplexity features). In other words, checking evidence use mattered more than just measuring uncertainty.
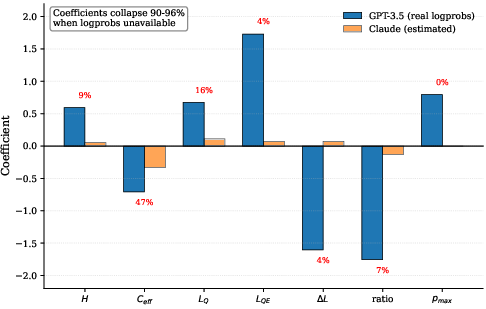
- When they tried ECLIPSE on a model that does not provide real token-level confidence (Claude-3-Haiku), performance dropped a lot (AUC 0.59). This shows ECLIPSE depends on real, calibrated confidence numbers (“log probabilities”) to work well.
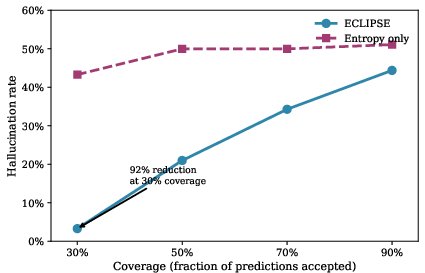
- Coverage test: If a system only accepts the top 30% most trustworthy answers, ECLIPSE reduced the hallucination rate by 92% compared to the uncertainty-only method.
- A surprising pattern: very high token-level confidence sometimes predicted more hallucinations—suggesting that AIs can be “confidently wrong” when they latch onto memorized but irrelevant facts.
Why It Matters
This research suggests a practical way to make AI answers safer in finance (and similar fields) by:
- Looking at the relationship between certainty and evidence, not just one of them.
- Using signals that many AI APIs already expose, without needing insider access to the model’s hidden layers.
- Providing a clear, interpretable detector that can help systems decide when to trust an AI’s answer or abstain.
Implications and Future Impact
If adopted, ECLIPSE could:
- Act as a safety layer for financial, medical, or legal AI tools, flagging answers that look confident but aren’t grounded in the provided documents.
- Encourage API providers to expose token-level confidence numbers, since they enable better hallucination detectors.
- Guide future systems to prefer answers that truly use evidence, improving reliability in retrieval-augmented setups (where the AI looks up documents to help answer).
The authors emphasize this is an early, controlled study in finance with synthetic (constructed) mistakes. To fully trust the approach, it needs testing on larger, more varied, naturally occurring hallucinations across different domains. Still, the central idea—check whether evidence actually changes the model’s confidence—looks promising for building safer AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored, framed to guide concrete follow-up research:
- External validity: Evaluate ECLIPSE on naturally occurring hallucinations (not synthetically perturbed answers) across multiple domains (e.g., medical, legal, open-domain QA), and at larger scale (n ≥ 1000) to assess robustness and tighten confidence intervals.
- Standardized benchmarking: Compare against strong baselines (Semantic Entropy, SelfCheckGPT, SEPs) on shared, widely used benchmarks (e.g., TruthfulQA, HaluEval, BioASQ, FActScore datasets) under identical protocols to establish relative performance.
- Cross-model generality: Test on diverse LLM families with real token-level log probabilities (e.g., GPT-4, Llama/Mistral variants with open-source logprobs) to assess how model architecture and logprob calibration affect detector performance.
- Logprob dependence: Develop and evaluate principled alternatives when token-level log probabilities are unavailable (e.g., approximate logprobs via open models, sequence-level scoring, entailment-based evidence-use proxies), and quantify the performance gap relative to native logprob access.
- Calibration of token-level uncertainties: Measure and improve the calibration of token-level log probabilities (e.g., reliability diagrams, expected calibration error) and study how miscalibration propagates to ECLIPSE’s features and decisions.
- Formal capacity grounding: The “capacity”
C_effis an intuitive log-likelihood difference; rigorously relate it to mutual information (e.g., bound or estimate ), quantify estimation error, and validate whetherΔLconsistently tracks evidence–answer mutual information. - Preferred entropy
H_pref(C, Q): Specify, estimate, or learnH_prefin practice (rather than treating it as conceptual), and study whether explicit modeling ofH_prefimproves detection or enables control. - From theory to control: Implement and evaluate an entropy controller derived from the convex objective (e.g., temperature scheduling, decoding constraints) to test whether maintaining
H ≈ H_pref(C, Q)reduces hallucinations without degrading utility. - Length normalization: Clarify whether
L_Q,L_QE, andΔLare length-normalized; if not, add per-token normalization and evaluate sensitivity to answer length, especially for long-form generation and summarization. - Top-answer reliance: Move beyond scoring only the single realized answer
A*; score alternative candidates or n-best lists to detect evidence-ignoring behavior when the sampled output differs from higher-likelihood, evidence-supported completions. - Semantic entropy estimation: Conduct sensitivity analyses for the number of samples
K, sampling temperature, and clustering heuristics; replace domain-specific fact extraction with more robust semantic coders (e.g., NLI/entailment models) and measure gains. - Contradiction penalty
w_cons: Define, justify, and tunew_consrigorously; quantify its contribution and risk of label leakage (alignment with synthetic contradiction labels), and evaluate on naturally contradictory contexts. - Feature multicollinearity: Diagnose and reduce multicollinearity among
L_Q,L_QE,ΔL, and ratio features (e.g., via orthogonalization or PCA), and assess stability of coefficient signs/magnitudes across datasets and models. - Probability calibration of the detector: Assess and improve the calibration of the logistic regression outputs (e.g., isotonic or temperature scaling) with reliability diagrams, especially under class imbalance typical in real deployments.
- Class imbalance and thresholding: Evaluate detection under realistic, low-prevalence hallucination rates; study threshold selection, coverage–risk trade-offs, and operational metrics (precision at fixed recall/coverage) in imbalanced settings.
- Adversarial and misleading evidence: Test robustness when evidence is coherent but false, irrelevant, or strategically distracting; integrate external fact verification or trust estimation of sources to mitigate high
C_effon misleading contexts. - RAG pipeline variability: Quantify sensitivity to retrieval quality (passage ranking, relevance filtering) and assess whether ECLIPSE maintains performance under noisy, long, or mixed-relevance contexts common in production RAG systems.
- Long-form and multi-turn settings: Extend and evaluate ECLIPSE on multi-sentence answers, summarization, and conversational agents (multi-turn), including segmentation strategies to compute per-claim
ΔLand aggregate risk. - Positive
p_maxcoefficient: Test whether the finding that high token confidence correlates with increased hallucination risk generalizes across domains, tasks, and models; probe causes (memorization, spurious priors) and potential mitigations. - Hyperparameter transparency: Report actual values (or ranges) for parameters in the theoretical logistic risk (e.g.,
a,b,λ,α,c) and study how they influence the existence and location of the optimal entropy in practice. - Computational cost and latency: Optimize the 12-API-call pipeline (K sampling + scoring) for production use (e.g., batched scoring, caching, reduced K via adaptive sampling), and measure latency/throughput trade-offs versus detection quality.
- Open-source replication: Release code, data, and detailed feature computation steps (including how
L_Q,L_QE,ΔL, ratio, andw_consare computed) to enable independent replication and diagnostic studies. - Generalization without explicit evidence: Explore how to define and estimate “capacity” when explicit evidence
Eis absent (e.g., open-domain QA), including using retrieved knowledge bases or internal knowledge priors as proxy evidence. - OOD robustness: Evaluate ECLIPSE when queries and evidence are out-of-distribution relative to the LLM’s training data, and characterize failure modes where entropy or capacity signals become unreliable.
- Joint ablation within a single model: Isolate the effect of logprob unavailability by simulating noisy logprobs within the same model family (holding architecture/training constant) to remove cross-model confounds observed in the Claude ablation.
Glossary
- Ablation study: A controlled experiment that removes or adds components to assess their contribution to performance. "Ablation study showing contribution of each feature group."
- Average precision: The area under the precision–recall curve summarizing ranking quality across thresholds. "achieves ROC AUC of 0.89 and average precision of 0.90"
- Balanced class weights: A training setting that weights classes inversely to their frequency to mitigate class imbalance. "with regularization and balanced class weights."
- Bootstrap confidence interval: A statistical interval estimated by resampling with replacement to quantify metric uncertainty. "Bootstrap confidence intervals (1000 resamples) show ECLIPSE AUC of [0.842, 0.933] compared to entropy-only baseline [0.423, 0.578]."
- Bootstrap test: A resampling-based hypothesis test used to assess statistical significance without distributional assumptions. "For statistical significance, we use a bootstrap test (1000 iterations with replacement) over the full dataset to estimate AUC confidence intervals."
- Capacity lift: The increase in log-likelihood of an answer when evidence is provided, indicating how much the evidence helps. ": Capacity lift (how much evidence helps)"
- Conformal prediction: A method that constructs calibrated uncertainty sets around predictions with distribution-free guarantees. "Lin et al.\ \cite{lin2024generating} extended this with conformal prediction for calibrated uncertainty sets."
- Entailment models: Models that determine whether a hypothesis logically follows from a premise, used here to improve semantic clustering. "more robust semantic coders (e.g., entailment models) would likely improve entropy quality."
- Entropy–Capacity objective: A joint objective balancing uncertainty (entropy) and evidence informativeness (capacity) to model hallucination risk. "We introduce a joint objective over semantic entropy and evidence capacity and prove it is strictly convex under mild conditions (Theorem~\ref{thm:stability}), providing a principled foundation for hallucination risk modeling and, in future work, control."
- Entropy–Capacity trade-off: The relationship between a model’s uncertainty and the quality of evidence, central to assessing hallucination risk. "a framework that makes this entropy--capacity trade-off explicit."
- Evidence capacity: A measure of how informative the provided evidence is about the answer distribution. "Let measure how informative the evidence is about the answer."
- Grey-box: A setting where limited internal signals (e.g., log probabilities) are available via an API, without full model internals. "logprob-native, grey-box detectors can reach strong performance without hidden-state access."
- Jaccard similarity: A set similarity measure defined as intersection over union, used to compare entity sets. "Entity sets overlap by ≥ 50% (Jaccard similarity)."
- L2 regularization: A penalty on the squared magnitude of model parameters to prevent overfitting. "with regularization () and balanced class weights."
- Lipschitz continuous gradients: A smoothness condition on gradients that helps guarantee convergence of gradient descent. "For strictly convex functions with Lipschitz continuous gradients, gradient descent with appropriate step size converges to the unique global minimum from any initialization."
- Log probabilities: The natural logarithm of token probabilities output by a LLM, used to quantify uncertainty. "using only API-accessible log probabilities."
- Log-likelihood: The logarithm of the likelihood of observed data under a model, often used for comparisons and differences. "quantifying mutual information between evidence and answer through log-likelihood differences."
- Logprob-native: A mechanism whose core signal directly depends on token-level log probabilities and degrades when replaced by proxies. "We call a method logprob-native if its core signal relies directly on token-level log probabilities and degrades substantially when those probabilities are replaced by uninformative proxies."
- Multi-sample clustering: Grouping multiple sampled outputs by meaning to estimate semantic entropy. "estimated via multi-sample clustering as described in Section~\ref{sec:estimation}."
- Mutual information: An information-theoretic quantity measuring the dependence between variables, here between evidence and answer. "quantifying mutual information between evidence and answer through log-likelihood differences."
- Named Entity Recognition (NER): An NLP technique to identify entities (e.g., companies, people) in text. "using pattern matching and named entity recognition."
- Perplexity decomposition: Breaking down perplexity-related features to analyze how evidence affects answer likelihood. "We combine entropy estimation via multi-sample clustering with a novel perplexity decomposition that measures how models use retrieved evidence."
- Platt scaling: A post-hoc calibration method that fits a logistic regression to scores to produce calibrated probabilities. "Temperature scaling \cite{guo2017calibration} and Platt scaling \cite{platt1999probabilistic} provide post-hoc calibration."
- Preferred entropy: The task-optimal level of entropy given evidence capacity and query, used to detect misalignment. "Let $H_{\text{pref}(C, Q)$ denote the entropy level that would be optimal for task performance alone, encoding how concentrated the answer distribution should be given capacity ."
- Retrieval-augmented generation: An approach that grounds model outputs in retrieved documents to improve factuality. "This setting captures retrieval-augmented generation, where consists of retrieved documents, as well as grounded QA tasks where is provided context."
- ROC AUC: Area under the receiver operating characteristic curve, summarizing the trade-off between true and false positive rates. "ECLIPSE achieves ROC AUC of 0.89 and average precision of 0.90"
- Semantic entropy: An uncertainty measure over semantically distinct outputs computed by clustering sampled answers. "Existing hallucination detection methods primarily measure model uncertainty through semantic entropy"
- Selective prediction: A framework where models abstain on uncertain inputs to improve reliability at chosen coverage levels. "Selective prediction frameworks enable models to abstain when uncertain."
- Strict convexity: A property of functions ensuring a unique global minimum and stable optimization. "the resulting entropy--capacity objective is strictly convex with a unique stable optimum."
- Stratified 5-fold cross-validation: A validation protocol that preserves class proportions in each fold while splitting data into five parts. "We evaluate using stratified 5-fold cross-validation, ensuring each fold preserves the 50/50 hallucinated/clean split."
- Temperature scaling: A post-hoc calibration technique that rescales logits to adjust prediction confidence. "Temperature scaling \cite{guo2017calibration} and Platt scaling \cite{platt1999probabilistic} provide post-hoc calibration."
- Token-level uncertainties: Fine-grained uncertainty estimates at the level of individual tokens produced by a LLM. "whose effectiveness depends on calibrated token-level uncertainties."
- White-box access: Direct access to a model’s internal states or parameters, enabling specialized probes. "SEPs ... require white-box model access."
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, drawing on the paper’s ECLIPSE framework, empirical findings, and workflows.
- Finance — risk-aware RAG assistants for filings, earnings calls, and research
- Use ECLIPSE as a middleware “Hallucination Risk Score” in financial QA/chat to gate, abstain, or route answers for human review based on coverage–risk trade-offs (e.g., accept only top 30% most trustworthy outputs to cut hallucinations by ~92% vs entropy-only).
- Integrate perplexity decomposition features (L_Q, L_QE, ΔL) to flag evidence-ignoring behavior and highlight unsupported claims.
- Tools/products/workflows: LangChain/LlamaIndex plugin for evidence-utilization scoring; dashboards with coverage vs hallucination curves; acceptance thresholds; automated escalation queues.
- Assumptions/dependencies: token-level log probabilities from the LLM API; RAG pipeline with accessible evidence; modest extra API cost (~12 calls per example); domain-tuned semantic clustering.
- Healthcare — clinical summarization and patient QA safety layer
- Wrap LLM outputs with ECLIPSE to triage summaries, discharge instructions, and patient Q&A grounded in EHR or guidelines; high-risk answers are withheld or require clinician sign-off.
- Tools/products/workflows: risk-gated clinical copilots; “evidence utilization” explanations pointing to the exact passages that increased likelihood (ΔL).
- Assumptions/dependencies: logprob access; domain-specific fact extraction/clustering; governance for human-in-the-loop and audit trails.
- Legal — citation and claim verification for research assistants
- Detect fabricated citations and claims unsupported by provided documents; highlight answer segments with low capacity lift or negative evidence support.
- Tools/products/workflows: “Grounding Guard” for legal RAG; claim-level risk annotations; selective prediction to abstain on ambiguous queries.
- Assumptions/dependencies: logprob access; legal NER/claim extraction; reliable retrieval corpora.
- Education — textbook-grounded tutoring systems
- Verify student-facing answers against course materials; abstain or prompt for clarification when evidence lift is low; expose “supported-by-evidence” badges only when ΔL is positive and strong.
- Tools/products/workflows: LMS plugin for risk-aware tutoring; transparent evidence links.
- Assumptions/dependencies: logprob access; curated curriculum context; simple fact clustering.
- Software engineering — instrumentation and guardrails for LLM features
- Add an “Evidence Utilization Score” to existing LLM features (chat, summarization) to log risk metrics, run A/B tests, and enforce gating policies.
- Use ECLIPSE to curate training/evaluation sets (labeling likely hallucinations without human annotation) and to conduct error analyses (e.g., p_max as an overconfidence risk indicator).
- Tools/products/workflows: microservice exposing risk scores; CI dashboards; SDK integration.
- Assumptions/dependencies: logprob access; sampling for entropy estimation (K≈10); standard observability stack.
- Organizational AI governance — risk reporting and procurement
- Include coverage–hallucination curves in governance reports; adopt selective prediction workflows; make “logprob-native safety signals” a procurement requirement for high-stakes use.
- Tools/products/workflows: risk policy templates; acceptance thresholds; audit artifacts for regulators/compliance.
- Assumptions/dependencies: models exposing logprobs; internal telemetry; defined abstention criteria.
- Daily life — personal research assistants with local/open-source models
- Browser or note-taking extensions that verify summaries against user-provided articles and flag answers that ignore evidence (low ΔL), using open-source LLMs that expose logprobs.
- Tools/products/workflows: local inference to preserve privacy; “trust indicators” for each claim.
- Assumptions/dependencies: local or open-source models with logprob support; modest compute; retrieval setup.
- API providers/platforms — enabling features
- Expose calibrated token-level log probabilities and risk-ready endpoints; provide first-party “evidence-aware guardrails” using ECLIPSE-like features.
- Tools/products/workflows: logprob APIs; server-side risk scoring; policy hooks (coverage gating).
- Assumptions/dependencies: engineering investment; calibration quality; developer education.
- Academia — mechanism study and comparative evaluation
- Use ECLIPSE to study overconfidence (e.g., positive p_max as a risk factor), evidence utilization patterns across LLMs, and to build labeled datasets without manual effort.
- Tools/products/workflows: shared benchmarks with entropy vs capacity plots; coefficient interpretability for model comparisons.
- Assumptions/dependencies: logprob access; reproducible RAG setups; domain-tuned clustering.
Long-Term Applications
These use cases require further research, development, scaling, or standardization before broad deployment.
- Evidence-aware entropy control during decoding
- Implement controllers that adjust temperature/sampling to keep entropy near task-optimal H_pref(C, Q), leveraging the paper’s strict convexity/stability result for reliable convergence.
- Sectors: software safety, healthcare, finance, autonomous systems.
- Assumptions/dependencies: decoding hooks or fine-tuning access; calibration of capacity measures; extensive validation across domains.
- Training-time alignment to reduce evidence-ignoring behavior
- Incorporate entropy–capacity penalties or auxiliary losses in fine-tuning/RLHF to reward evidence utilization (positive ΔL) and penalize overconfidence without support.
- Sectors: model training, enterprise AI.
- Assumptions/dependencies: white-box access; compute budgets; robust proxies for capacity and semantic entropy; careful avoidance of label leakage.
- Retrieval optimization driven by capacity lift
- Use ΔL signals to re-rank, filter, or iterate retrieval (e.g., swap irrelevant passages until evidence raises likelihood); adapt context length dynamically based on evidence support.
- Sectors: search, enterprise knowledge management.
- Assumptions/dependencies: tight RAG integration; latency budgets; handling adversarial or misleading context.
- Multi-agent verification and orchestration
- Embed ECLIPSE in planning/tool-use agents to auto-abstain, request more evidence, or escalate; combine with external fact verification to catch coherent but globally false evidence.
- Sectors: robotics, autonomous decision support, complex workflows.
- Assumptions/dependencies: real-time logprob access; agent frameworks; robust fact-checking tools/knowledge graphs.
- Standardized risk reporting and regulation
- Develop policy frameworks that mandate logprob-native risk signals (entropy–capacity metrics, coverage curves) in regulated domains; certify systems that meet evidence-aware trust thresholds.
- Sectors: public policy, compliance, healthcare/law/finance regulation.
- Assumptions/dependencies: stakeholder consensus; standardized APIs/metrics; third-party audits.
- Cross-domain benchmarking and generalization studies
- Build large, naturally occurring hallucination datasets across domains; standardize evaluation protocols for ECLIPSE vs baselines; quantify generalization beyond synthetic financial cases.
- Sectors: academia, standards bodies.
- Assumptions/dependencies: annotation pipelines; shared tasks; model diversity; community adoption.
- Consumer “trust layer” for AI assistants
- OS/platform-level guardrails that surface evidence-aware trust indicators, abstain on high-risk responses, and provide transparent grounding across apps.
- Sectors: consumer platforms, mobile/desktop OS.
- Assumptions/dependencies: platform integration; privacy; consistent logprob access; UX research.
- Tooling ecosystem: libraries and services
- “Hallucination Firewall” for enterprise; “Evidence-Driven Decoding” libraries; “Risk-based Coverage” orchestrators; “ECLIPSE SDK” with adapters for major LLMs and RAG stacks.
- Sectors: software tooling, enterprise IT.
- Assumptions/dependencies: broad model support; standardized logprob endpoints; sustained maintenance.
- Calibration and estimation improvements
- Better semantic entropy via larger K and entailment-based clustering; conformal prediction for calibrated abstention; improved logprob calibration across APIs.
- Sectors: research, applied ML.
- Assumptions/dependencies: API cost/latency budgets; high-quality entailment models; calibration evaluation suites.
- Adversarial robustness and secure grounding
- Combine ECLIPSE with external verification to detect internally consistent but false contexts; develop defenses against context poisoning in RAG pipelines.
- Sectors: security, regulated AI deployments.
- Assumptions/dependencies: trustworthy knowledge bases; anomaly detection; provenance tracking.
- Edge and privacy-preserving deployments
- Run ECLIPSE with local LLMs (logprob-native) on devices for private document summarization and research assistants.
- Sectors: consumer devices, enterprise endpoints.
- Assumptions/dependencies: efficient local models; hardware acceleration; lightweight retrieval; energy/latency constraints.
General assumptions and dependencies that impact feasibility
- Logprob-native requirement: The method’s effectiveness depends on calibrated token-level log probabilities; performance degrades substantially with proxies (as shown with Claude-3-Haiku).
- RAG/evidence availability: ECLIPSE is most effective when relevant context is supplied; weak or adversarial evidence can mislead capacity measures.
- Domain adaptation: Semantic clustering and fact extraction must be tailored (finance vs healthcare vs law); generalization beyond the synthetic finance dataset needs further validation.
- Cost and latency: Entropy estimation via multi-sampling and double scoring (with vs without evidence) adds API calls and latency; production systems must budget and optimize.
- Calibration quality: Overconfidence (high p_max) can signal risk; however, token probability calibration varies across models/APIs and may require post-hoc scaling.
Collections
Sign up for free to add this paper to one or more collections.