HEDGE: Hallucination Estimation via Dense Geometric Entropy for VQA with Vision-Language Models
Abstract: Vision-LLMs (VLMs) enable open-ended visual question answering but remain prone to hallucinations. We present HEDGE, a unified framework for hallucination detection that combines controlled visual perturbations, semantic clustering, and robust uncertainty metrics. HEDGE integrates sampling, distortion synthesis, clustering (entailment- and embedding-based), and metric computation into a reproducible pipeline applicable across multimodal architectures. Evaluations on VQA-RAD and KvasirVQA-x1 with three representative VLMs (LLaVA-Med, Med-Gemma, Qwen2.5-VL) reveal clear architecture- and prompt-dependent trends. Hallucination detectability is highest for unified-fusion models with dense visual tokenization (Qwen2.5-VL) and lowest for architectures with restricted tokenization (Med-Gemma). Embedding-based clustering often yields stronger separation when applied directly to the generated answers, whereas NLI-based clustering remains advantageous for LLaVA-Med and for longer, sentence-level responses. Across configurations, the VASE metric consistently provides the most robust hallucination signal, especially when paired with embedding clustering and a moderate sampling budget (n ~ 10-15). Prompt design also matters: concise, label-style outputs offer clearer semantic structure than syntactically constrained one-sentence responses. By framing hallucination detection as a geometric robustness problem shaped jointly by sampling scale, prompt structure, model architecture, and clustering strategy, HEDGE provides a principled, compute-aware foundation for evaluating multimodal reliability. The hedge-bench PyPI library enables reproducible and extensible benchmarking, with full code and experimental resources available at https://github.com/Simula/HEDGE .
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
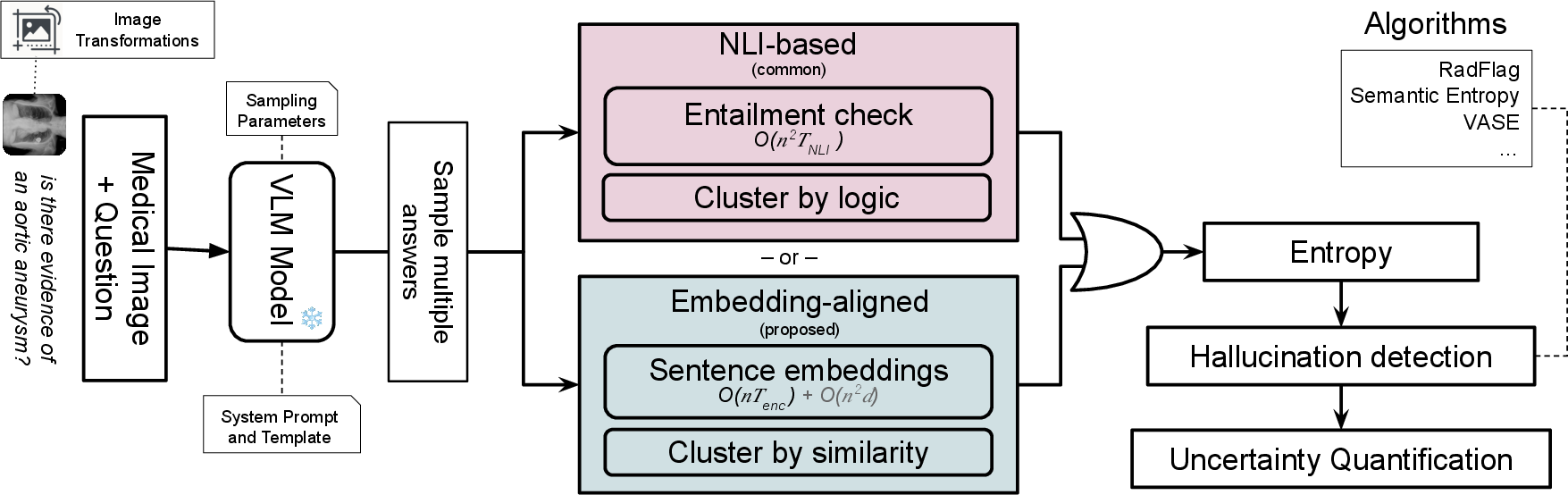
This paper introduces HEDGE, a new way to spot when vision–LLMs (VLMs) “hallucinate.” A hallucination is when an AI confidently says something that isn’t supported by the picture or the question. HEDGE doesn’t try to fix the models. Instead, it measures how reliable they are by testing how their answers change under small, controlled tweaks to the image and by checking how stable the meanings of those answers are.
What questions did the researchers ask?
They focused on simple, practical questions:
- How can we tell, in a reliable and fair way, when a VLM is likely hallucinating?
- Do different model designs make hallucinations easier or harder to detect?
- Which way of grouping similar answers works better: logical comparison (do answers support each other?) or meaning-based comparison (are answers close in meaning)?
- Which uncertainty metric is most dependable?
- How do prompts (short labels vs one-sentence answers) and the number of sampled answers affect detection?
How did they do the study?
To make the ideas easy to picture, imagine answers as dots on a map of meanings. If the image changes just a little (like adding blur or tiny rotations) and the dots (answers) suddenly scatter all over the map, that’s a sign the model is unstable and might hallucinate.
Here’s the approach, step by step:
1) Make small changes to the image
They applied gentle “visual perturbations” to each image (tiny rotations, slight color shifts, a bit of noise or blur). Think of it like nudging a photo to see if the model’s answers wobble or stay steady.
2) Ask the model many times
For each image–question pair, they:
- Got one low-randomness baseline answer (the model’s “most confident” response).
- Sampled multiple high-randomness answers from the original (clean) image.
- Sampled multiple high-randomness answers from the perturbed (noisy) versions.
This gives two piles of answers: clean and noisy. The number of samples (like 10–15) is called the “sampling budget.”
3) Group similar answers (“clustering”)
They grouped answers that mean the same thing in two different ways:
- NLI-based clustering: Use a LLM “referee” that checks whether one answer logically supports another (entails), contradicts it, or is unrelated. Answers that mutually support each other get grouped.
- Embedding-based clustering: Turn each answer into a meaning-vector (a list of numbers that capture its meaning). Answers whose vectors are close together get grouped.
Both methods try to form clusters of “answers that basically say the same thing.”
4) Measure stability and uncertainty (“metrics”)
They tested three metrics that score hallucination risk:
- Semantic Entropy (SE): Measures how spread out the answer clusters are for the clean image. If answers jump between different meanings, SE goes up (riskier).
- RadFlag: Counts how often the sampled answers disagree with the baseline answer’s cluster (more disagreement = riskier).
- VASE: Compares clean vs noisy behavior. If adding small image changes makes the answer clusters wobble more, VASE goes up (riskier). VASE is like a “stability gap” measure.
5) Where did they test it?
They evaluated on medical visual question answering (VQA) datasets:
- VQA-RAD (radiology images)
- KvasirVQA-x1 (endoscopy images)
Medical data is useful here because answers are typically short and clear, making it easier to judge consistency. They tested three popular VLMs:
- LLaVA-Med
- Med-Gemma
- Qwen2.5-VL
They also tried different prompt styles (like “just a short label” vs “exactly one sentence”) to see how wording changes detection.
What did they find?
These are the most important takeaways:
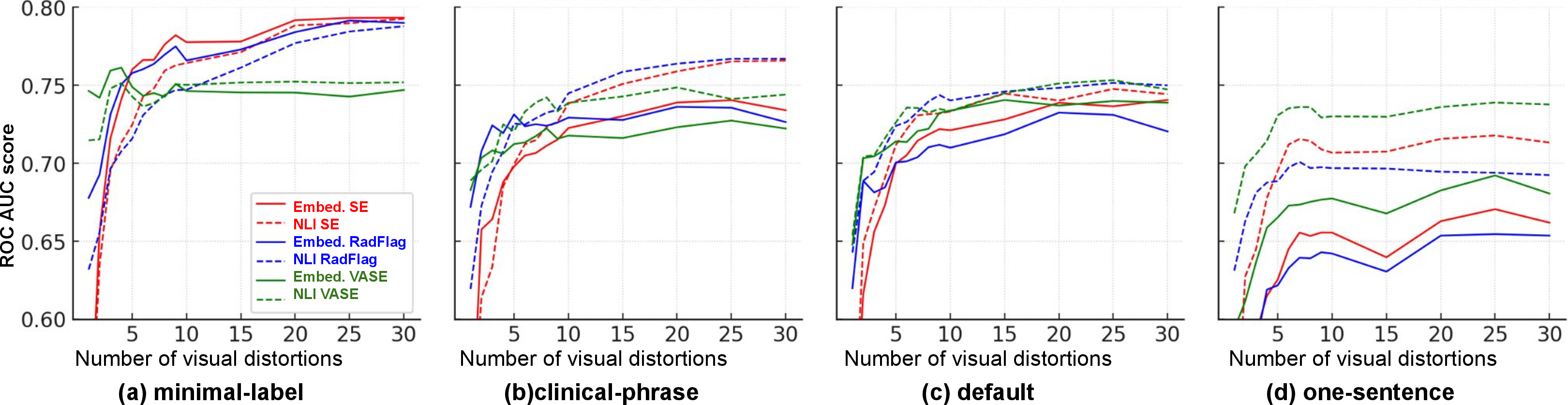
- Model design matters: Models that keep more visual detail as tokens (Qwen2.5-VL) make hallucinations easier to detect. Models that squeeze the image into fewer tokens (Med-Gemma) make detection harder.
- Clustering choice depends on the situation:
- Embedding-based clustering often worked best for short, label-like answers.
- NLI-based clustering was especially helpful for longer, sentence-style answers and for some models like LLaVA-Med.
- VASE is the most reliable metric overall: It consistently gave the strongest signal of hallucination risk, especially when combined with embedding-based clustering and a moderate sampling budget (about 10–15 samples).
- Prompts matter:
- Short, label-style answers usually make the meaning clearer and easier to group, which helps detection.
- Forcing “exactly one sentence” often made detection worse, likely because it constrains the wording and blurs meaningful differences.
- Including the question text can help when answers are very short (like “yes/no” or a single label), because it adds context. For longer answers, including the question can sometimes get in the way of grouping.
Why does this matter?
- Safer AI in high-stakes areas: In fields like medicine, we need to know when a model might be making things up. HEDGE offers a careful, fair way to measure that risk.
- Works across different models and tasks: HEDGE is “domain-agnostic.” It doesn’t require special medical rules; it can be used for other images and questions too.
- Practical guidance: The paper shows how to choose prompts, pick the right clustering method, and set a reasonable number of samples to get strong, stable detection.
- Better evaluation tools: Their open-source “hedge-bench” library lets researchers and developers run these tests consistently, compare models, and improve reliability over time.
In short, HEDGE treats hallucination detection as a stability problem: if small changes to the image or the sampling process cause big flips in meaning, the model is at higher risk of hallucinating. Measuring that stability gives us a clear, practical way to judge and improve how trustworthy vision–LLMs are.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Generalization beyond medical VQA remains untested: how HEDGE performs on non-medical domains (e.g., everyday VQA, captioning, referring expressions, OCR, chart QA), multi-image tasks, or video remains unknown.
- Dependence on access to token log-probabilities: many closed-source VLM APIs do not expose logits; alternatives (e.g., proxy confidence, internal state probes, verifier heads) are not investigated.
- “Geometric” framing is not instantiated on the model’s internal multimodal representations: clustering and entropy operate over text outputs, not over the VLM’s joint embeddings or cross-attention manifolds; the value of using internal representation distances under perturbations is left open.
- Embedding and NLI backends are text-only and general-domain: medical or domain-adapted sentence encoders and clinical NLI models are not compared; the effect of domain mismatch on clustering errors and metric reliability is unclear.
- Limited perturbation suite and realism: distortions are small, generic (affine, color jitter, Gaussian/Poisson noise); the impact of clinically realistic artifacts (motion, compression, endoscope-specific glare/smoke, occlusions, cropping of key anatomy), adversarial/targeted occlusions, or counterfactual edits is not assessed.
- No systematic severity calibration of distortions: how metric performance varies with perturbation magnitude/type—and whether HEDGE can detect non-monotonic sensitivity—is not quantified.
- Ground-truth hallucination labels rely solely on an LLM adjudicator (Qwen3-30B-A3B): there is no human expert validation, inter-rater agreement, bias analysis, or robustness checks (e.g., adjudicator consistency across paraphrases), and potential family bias exists when judging Qwen2.5-VL outputs.
- Embedding-threshold tuning (τ) uses label-informed optimization: the method’s “unsupervised” claim is weakened; label-free or self-calibrating threshold selection (e.g., density-based or stability criteria) is not explored.
- Sensitivity of VASE to its scaling parameter α and semantic distribution construction is untested: α is fixed at 1; alternative formulations or calibrations of the semantic distribution (and the double-exponential aggregation used) are not justified or ablated for numerical stability and interpretability.
- Temperature dependence is not ablated: only T=0.1 and T=1.0 are used; how different decoding temperatures/top-k/top-p settings impact clustering quality and metric reliability is unknown.
- Prompt design is only length-constrained: richer prompt controls (metamorphic prompting, explicit grounding instructions, uncertainty elicitation, chain-of-thought suppression/encouragement) and their impact on hallucination detectability are not studied.
- Automatic policy to choose Answer+Question vs Answer-only is missing: simple heuristics are described, but no algorithmic selector (e.g., based on answer length, entropy, cluster stability) is proposed or validated.
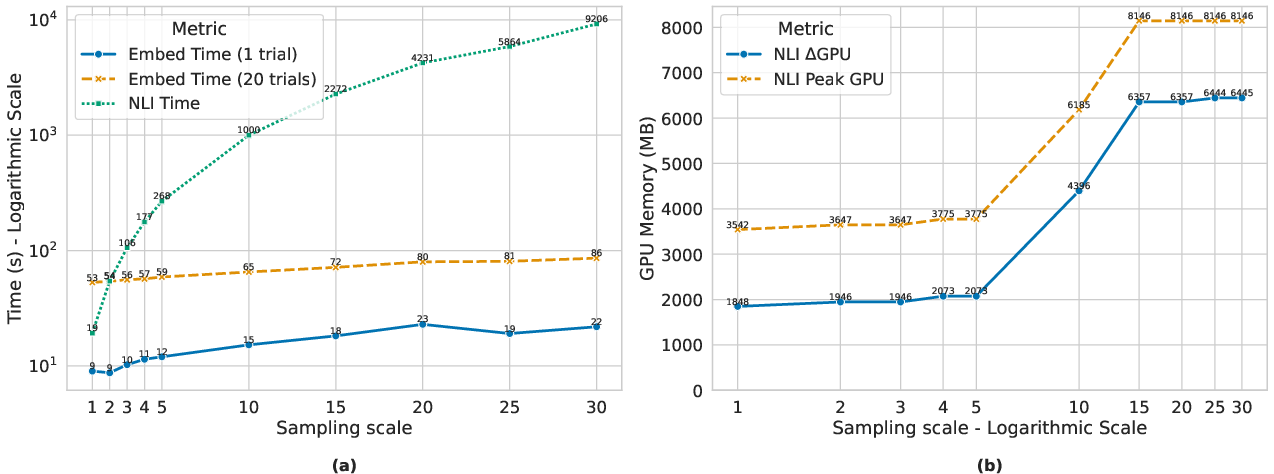
- Compute–performance trade-offs are underexplored: only n up to 30 is tested; the marginal gains vs runtime for larger n, approximate NLI (e.g., pruning or hashing), or ANN-based embedding clustering are not quantified.
- The causal role of visual tokenization density and fusion topology is hypothesized but not tested: controlled ablations (varying input resolution, visual token counts, fusion depth/architecture within the same family) to confirm causality are absent.
- Per-question-type error analysis is missing: which question categories (yes/no, modality, anatomy, findings, counts) drive false positives/negatives and whether HEDGE can be adapted by type is not reported.
- Beyond detection, mitigation and integration pathways are not evaluated: how HEDGE scores can gate outputs, trigger abstention, re-query, or reranking—and their safety impact—remains an open design question.
- Statistical significance and robustness are not established: confidence intervals, seed sensitivity, and bootstrapped variance for ROC-AUC estimates (especially where differences are 0.01–0.02) are not provided.
- Language robustness is not tested: stability under paraphrased questions, synonym substitutions, or multilingual settings is not evaluated; HEDGE’s language-side perturbation sensitivity remains unknown.
- Applicability to closed or API-only VLMs is uncertain: requirements for logits, batching, and repeated sampling may preclude many production models; a reduced-information variant of HEDGE is not proposed.
- Choice of encoder for embeddings is fixed: the effect of different sentence encoders (domain-specific, multilingual, instruction-tuned) or multimodal embedding models (e.g., CLIP, SigLIP text heads) on clustering quality is not studied.
- Clustering algorithm variations are not explored: alternatives like HDBSCAN, spectral clustering, or graph community detection (with automatic cluster-count selection) could improve stability but are untested.
- Real-world acquisition variability is not modeled: device differences, protocols, and dataset shift are not included; cross-domain robustness and OOD generalization of HEDGE are unassessed.
- Calibration to operational thresholds is missing: ROC-AUC summarizes ranking, but practical cutoffs for safe deployment (precision–recall trade-offs, cost-sensitive decisions) are not derived or validated.
- Error taxonomy is absent: representative false positives/negatives (by model, dataset, prompt, clustering mode) and root-cause analyses that would guide method revisions are not provided.
- Single-shot or tiny-budget regimes need study: HEDGE’s reliance on multiple generations limits real-time use; performance with n≤3, or with only clean outputs (SE-only variants), is not characterized.
- Interaction with internal-state probes is only noted conceptually: combining HEDGE with attention/activation probes or verifier heads to improve early detection is an open integration path.
- Extension beyond images is unclear: multimodal scenarios with text+image+tables, audio, or temporal signals are not evaluated; perturbation design and clustering become more complex and remain open.
Practical Applications
Immediate Applications
Below are concrete, deployable uses of the paper’s HEDGE framework, its metrics (SE, RadFlag, VASE), clustering strategies (NLI-based and embedding-based), perturbation protocol, and prompt-design findings. Each item notes relevant sectors and practical tools/workflows, along with key dependencies that affect feasibility.
- MLOps/VLMOps guardrails for multimodal systems
- Sector: software, healthcare, robotics
- What to do: Integrate the hedge-bench PyPI library into CI/CD to run HEDGE as a post-generation checker. Compute VASE (preferably with embedding-based clustering) over n≈10–15 samples to flag likely hallucinations and route risky outputs to human review.
- Tools/workflows: hedge-bench; Optuna threshold calibration; dashboards showing SE/RadFlag/VASE over time; per-prompt policies (prefer clinical-phrase/minimal-label over one-sentence).
- Assumptions/dependencies: Access to token log-probabilities and multi-sample generation; GPU budget for sampling and perturbations; suitable visual perturbation parameters for the deployment domain.
- Pre-deployment model evaluation for medical VQA
- Sector: healthcare (radiology, endoscopy, pathology), medical AI startups
- What to do: Use HEDGE to compare candidate VLMs (e.g., Qwen2.5-VL vs LLaVA-Med vs Med-Gemma) with consistent prompting and perturbations; select architectures with dense visual tokenization and unified fusion for more robust detectability and higher AUC (Qwen2.5-VL trends strongest).
- Tools/workflows: Standardized evaluation harness via hedge-bench; VASE as the primary signal; concise label/clinical-phrase prompts; A+Q clustering for minimal-label regimes.
- Assumptions/dependencies: Domain-specific perturbations (affine, noise, color jitter) must reflect clinical imaging; adjudicator or ground truth available for periodic audits (not required for detection, but useful for validation).
- Real-time safety gating in clinician-facing tools
- Sector: healthcare software
- What to do: When the system must produce a short answer (yes/no/anatomical label), use minimal-label prompts and A+Q clustering; block or defer outputs with high VASE and/or RadFlag, or fall back to a safer prompt configuration.
- Tools/workflows: Inference middleware that computes robustness scores on-the-fly and escalates uncertain cases.
- Assumptions/dependencies: Acceptable latency overhead from multi-sample generation; clinician-approved fallback policies.
- Prompt engineering guidelines and policies
- Sector: software, education, healthcare
- What to do: Prefer concise, semantically expressive prompts (default or clinical-phrase) and avoid rigid one-sentence constraints that degrade detectability; include question text in clustering for short answers (A+Q) and use Answer Only for verbose answers to preserve contrast.
- Tools/workflows: Prompt libraries; per-use-case prompt selection matrices.
- Assumptions/dependencies: End-user tolerance for shorter answers; prompt changes don’t violate task requirements.
- Risk scoring and auditing for procurement/compliance
- Sector: policy, healthcare compliance, enterprise governance
- What to do: Add HEDGE-derived scores (e.g., VASE@n≈10–15) to model cards and supplier evaluations; track model performance across datasets (easier-to-detect hallucinations on KvasirVQA-x1 vs VQA-RAD).
- Tools/workflows: Audit reports including ROC-AUC with chosen clustering strategy and prompt regimes; periodic re-evaluation under version updates.
- Assumptions/dependencies: Stakeholder-agreed thresholds; acceptance of robustness-based scores in governance processes.
- Dataset quality control and curation
- Sector: academia, data engineering
- What to do: Identify samples where semantic clusters disperse under small perturbations; flag items that induce instability across models for targeted review or augmentation.
- Tools/workflows: Batch HEDGE runs over datasets; per-item robustness annotations.
- Assumptions/dependencies: Compute capacity for repeated sampling; clear curation criteria.
- Reliability labels in consumer-facing multimodal apps
- Sector: consumer software, education
- What to do: Display a lightweight “robustness indicator” (based on VASE/SE) next to answers in photo-based assistants or study tools; offer a “verify” action that triggers extra sampling and robustness checks.
- Tools/workflows: UX components; tiered verification pipelines.
- Assumptions/dependencies: Acceptable latency; user comprehension of confidence signals.
- Robotics and autonomous systems pre-flight tests
- Sector: robotics, autonomous inspection
- What to do: Use HEDGE in offline test harnesses to probe VLM-based perception/QA modules with domain-appropriate perturbations; set gate criteria (e.g., VASE threshold) for deployment readiness.
- Tools/workflows: Perturbation suites matched to operational environments; failure-mode dashboards.
- Assumptions/dependencies: Domain-specific distortion design; availability of answerable QA tasks for the target visual scenarios.
- Academic benchmarking and reproducibility
- Sector: academia
- What to do: Adopt hedge-bench to produce standardized SE/RadFlag/VASE comparisons across models, prompts, and clustering strategies; publish per-config ROC-AUC and share artifacts for replication.
- Tools/workflows: Open repositories; consistent perturbation and sampling protocols.
- Assumptions/dependencies: Access to models’ logits and sampling; community buy-in on reporting conventions.
- Architecture-aware model selection and fine-tuning decisions
- Sector: model development, enterprise AI
- What to do: Favor architectures with dense, variable-length visual tokenization and unified fusion (detectability trends better); use HEDGE to quantify reliability impact of architectural changes.
- Tools/workflows: Ablation studies; internal benchmarks tracking geometric stability.
- Assumptions/dependencies: Availability of comparable model variants; controlled training/inference setups.
Long-Term Applications
These uses need further research, scaling, optimization, or broader ecosystem adoption before practical deployment.
- Low-latency, on-device hallucination suppression
- Sector: mobile health, wearables, robotics
- Vision: Approximate HEDGE signals (e.g., via SEP-style probes) without multi-sample generation to enable real-time gating on edge devices.
- Dependencies: Fast proxies for SE/VASE; efficient perturbation-free stability estimators; hardware constraints.
- Training-time regularization with geometric entropy
- Sector: model R&D
- Vision: Incorporate geometric entropy/stability objectives (minimize VASE gap under synthetic perturbations) during training to produce reliability-optimized VLMs.
- Dependencies: Differentiable approximations of clustering/entropy; curriculum design for perturbations; scalability to large multimodal models.
- Certified evaluation standards for multimodal reliability
- Sector: policy, standards bodies (e.g., ISO/IEC), healthcare regulators
- Vision: Use HEDGE as part of a formal certification suite (standard perturbations, sampling budgets, prompt regimes) for regulatory approval and post-market surveillance.
- Dependencies: Consensus on protocols; regulatory acceptance; reference implementations.
- Adaptive, closed-loop orchestration guided by HEDGE
- Sector: software, healthcare, customer support
- Vision: Runtime controllers that adjust prompts, increase sampling, or trigger clarifying questions when robustness dips; dynamic switch to minimal-label modes in high-risk contexts.
- Dependencies: Orchestration frameworks; user experience design; policy rules for escalation.
- Multi-model consensus augmented by geometric stability
- Sector: enterprise AI, safety-critical systems
- Vision: Combine cross-model agreement methods (e.g., SelfCheckGPT-like) with HEDGE’s geometric signals for stronger ensemble-level safety checks.
- Dependencies: Access to diverse models; cost management; consensus aggregation logic.
- Architecture co-design for reliability
- Sector: foundational model development
- Vision: Design encoders/fusion mechanisms that retain variable-length, dense visual tokenization to enhance stability and detectability; optimize tokenization for robustness under perturbations.
- Dependencies: Large-scale experiments; new training data; evaluation at scale.
- Domain transfer to non-medical sectors
- Sector: manufacturing QA, geospatial analysis, document understanding (KYC/AML visual checks)
- Vision: Tailor perturbations, prompt regimes, and clustering strategies to sector-specific images and tasks; deploy HEDGE for reliability auditing in these domains.
- Dependencies: Domain datasets; perturbation relevance; sector benchmarks and ground-truth creation.
- Multimodal RAG with HEDGE-aware gating
- Sector: enterprise search, customer support
- Vision: Align HEDGE signals with retrieval attribution (e.g., RAGAS-like metrics) to gate or re-query when visual grounding appears unstable.
- Dependencies: Integrated retrieval stack; joint scoring strategies; latency trade-offs.
- Standardized reporting in model cards and SLAs
- Sector: policy, procurement, vendor management
- Vision: Require HEDGE metrics (with specified sampling n and prompt regimes) in model documentation and service-level agreements.
- Dependencies: Industry alignment; templates for reporting; periodic revalidation pipelines.
- Educational curricula and labs on multimodal reliability
- Sector: education
- Vision: Use HEDGE to teach geometric stability concepts in VLMs and hands-on perturbation studies; create course modules and interactive notebooks.
- Dependencies: Simplified tooling; accessible datasets; institutional adoption.
Glossary
- Ablation studies: Controlled experiments that systematically vary components to isolate their effects on performance. "Ablations vary the sampling scale and perturbation budget, the inclusion of question text during clustering, the prompt configuration length, and the embedding similarity threshold to reveal how each factor influences performance."
- Albumentations: An image augmentation library providing fast, composable transformations for computer vision. "implemented via the Albumentations library~\cite{Buslaev2018Sep}."
- Answer+Question mode: An input configuration where the question text is prepended to the answer during clustering. "In the Answer+Question mode, the question text is prepended to each answer only during clustering, while log-prob arrays remain aligned with their respective responses."
- BF16 precision: A floating-point format (bfloat16) that reduces memory and compute while maintaining model accuracy. "All experiments are run on a single NVIDIA A100 GPU (80~GB) in BF16 precision."
- CLIP: Contrastive Language–Image Pretraining; a multimodal encoder aligning image and text embeddings. "LLaVA-Med~\cite{LLaVAmed} adopts a \gls{clip} ViT-L/14 vision tower with images normalized to 336\,px and a dual-tower alignment module;"
- cross-modal transformer: A transformer architecture that jointly processes and fuses signals from multiple modalities (e.g., vision and language). "a unified cross-modal transformer that preserves variable-length visual-token sequences"
- DeBERTa: A transformer model using disentangled attention, often fine-tuned for NLI tasks. "whereas \gls{nli}-based clustering relies on a DeBERTa model (\href{https://huggingface.co/microsoft/deberta-v2-xlarge-mnli}{deberta-v2-xlarge-mnli}) fine-tuned on \gls{mnli} entailment predictions~\cite{DeBERTaHe2020Jun} with contradiction filtering and transitive merging."
- dense geometric entropy: A measure of instability in the model’s representation manifold under perturbations, capturing how semantic structure deforms. "dense geometric entropy: measuring how the topology of the modelâs representation space deforms under controlled variation."
- directed entailment graph: A graph where edges represent directional logical entailment between statements. "A directed entailment graph $G_{\text{ent}$ is built with edges $E_{\text{ent}=\{(i,j)|y_{ij}=\text{entails}\}$."
- embedding-based clustering: Grouping responses by geometric similarity of their vector embeddings rather than explicit logical relations. "Embedding-based clustering often yields stronger separation when applied directly to the generated answers, whereas NLI-based clustering remains advantageous for LLaVA-Med and for longer, sentence-level responses."
- fusion topology: The structural design of how visual and textual features are combined inside a model. "it exposes how architectural choices, visual tokenization density, and fusion topology govern a modelâs susceptibility to hallucination"
- Gaussian noise: Random noise with a normal distribution added to images to test robustness. "additive Gaussian () and Poisson (scale ) noise implemented via the Albumentations library"
- hedge-bench: A PyPI package providing reproducible tooling for the HEDGE framework’s benchmarking. "The hedge-bench PyPI library enables reproducible and extensible benchmarking"
- HEDGE: A domain-agnostic framework that detects hallucinations via representation stability and geometric entropy. "We introduce \gls{hedge}, a domain-agnostic framework for hallucination detection based on representation stability."
- kNN (k-nearest neighbors): A similarity rule connecting each item to its k most similar neighbors in a graph for clustering. ""
- LLaVA-Med: A medical adaptation of LLaVA for vision–language tasks, using a CLIP-based vision tower. "LLaVA-Med~\cite{LLaVAmed} adopts a \gls{clip} ViT-L/14 vision tower with images normalized to 336\,px and a dual-tower alignment module;"
- MNLI (Multi-Genre Natural Language Inference): A benchmark and model family for entailment, contradiction, and neutrality across diverse text genres. "a \gls{mnli} model~\cite{MNLI2018} predicts "
- mutual entailment closure: A clustering rule that groups statements if they entail each other, extended via transitive merging. "Clusters are derived via mutual entailment closure: $i \sim j \iff (i,j)\in E_{\text{ent} \wedge (j,i)\in E_{\text{ent},$"
- Natural Language Inference (NLI): The task of determining whether a hypothesis is entailed by, contradicts, or is neutral with respect to a premise. "NLI-based clustering, which measures entailment consistency among answers~\cite{MNLI2018,DeBERTaHe2020Jun};"
- Optuna: A hyperparameter optimization framework that automates search over parameter spaces. "Embedding-based clustering uses SentenceTransformer embeddings~\cite{reimers2019sentence} with threshold optimized by Optuna~\cite{Akiba2019Jul} to maximize \gls{rocauc},"
- Poisson noise: Signal-dependent noise following a Poisson distribution, used for realistic image perturbations. "additive Gaussian () and Poisson (scale ) noise implemented via the Albumentations library"
- Qwen2.5-VL: A unified-fusion vision–LLM that preserves variable-length visual token sequences. "Qwen2.5-VL~\cite{Qwen25vl} processes images at dynamically selected resolutions using a unified cross-modal transformer that preserves variable-length visual-token sequences"
- RadFlag: A hallucination detection metric that flags semantic inconsistency or contradictions in generated responses. "RadFlag~\cite{RadFlag2024} introduces a hallucination flagger for medical \glspl{vlm} based on contradiction frequency."
- ROC-AUC: Area under the Receiver Operating Characteristic curve; a threshold-independent measure of detection performance. "We report \gls{rocauc} against the binary hallucination labels as the main quantitative measure~\cite{fabian2011scikit}."
- Semantic Entropy (SE): An uncertainty metric that aggregates token log-likelihoods across semantically clustered responses. "Semantic Entropy (SE) reduces this sensitivity by modeling dispersion across semantically grouped samples~\cite{SE2024},"
- SentenceTransformer: A library and model family for generating sentence-level embeddings for semantic similarity and clustering. "Embedding-based clustering uses SentenceTransformer embeddings~\cite{reimers2019sentence} with threshold optimized by Optuna"
- SigLIP: A vision-language encoder trained with a sigmoid-based contrastive objective, used in Med-Gemma. "Med-Gemma~\cite{MedGemma} employs a SigLIP-based encoder operating on 896896\,px crops, which are compressed into a fixed 256-token visual bottleneck;"
- softmax: A normalization function turning scores into probabilities over categories. "\operatorname{softmax}!\left( \mathbf{s}{\text{clean} + \alpha(\mathbf{s}{\text{clean} - \mathbf{s}_{\text{noisy}) \right)"
- t-SNE: A dimensionality reduction technique for visualizing high-dimensional embeddings. "with visualization tools such as t-SNE~\cite{vandermaaten2008visualizing}."
- union–find: A disjoint-set data structure supporting efficient component merging and queries. "followed by unionâfind transitive merging."
- ViT-L/14: A Vision Transformer variant with large capacity and 14×14 patching, often used as a vision backbone. "adopts a \gls{clip} ViT-L/14 vision tower"
- Vision–LLM (VLM): A model that jointly processes images and text for tasks like VQA and captioning. "Large \glspl{vlm} have rapidly advanced multimodal reasoning, enabling free-form question answering and grounded dialogue across complex visual scenes."
- visual bottleneck: A constrained representation limiting the number of visual tokens passed into the LLM. "compressed into a fixed 256-token visual bottleneck;"
- visual perturbations: Controlled modifications to images (e.g., noise, occlusion) used to probe robustness and grounding. "Visual perturbations such as noise, cropping, occlusion, and blur expose grounding fragility~\cite{VASE2025}."
- visual tokenization density: The granularity and number of visual tokens used to represent an image in a VLM. "architectural choices, visual tokenization density, and fusion topology govern a modelâs susceptibility to hallucination"
- VASE: A robustness-oriented hallucination metric contrasting semantic entropy under clean versus perturbed visual inputs. "\Gls{vase} extends \gls{se} by contrasting entropy distributions under clean versus perturbed visual inputs, offering robustness-oriented evaluation."
- VQA-RAD: A medical visual question answering benchmark focused on radiology. "The VQA-RAD dataset~\cite{lau2018vqarad} contains radiology images paired with 451 free-text clinical questions"
- Zero-shot: Evaluation without task-specific fine-tuning or labeled training data. "All models are evaluated zero-shot without any fine-tuning."
Collections
Sign up for free to add this paper to one or more collections.