- The paper introduces a systematic approach to detect and mitigate hallucinations by monitoring low-confidence tokens and validating them with external knowledge.
- Experiments show that using this method, hallucinations in GPT-3.5 were reduced from 47.5% to 14.5%, highlighting its effectiveness.
- The real-time mitigation strategy repairs faulty outputs immediately, preventing error propagation and enhancing overall LLM reliability.
Detecting and Mitigating Hallucinations in LLMs
The paper "A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation" introduces a novel approach to address the hallucination problem in LLMs, focusing on enhancing their reliability in real-world applications. This paper emphasizes the active detection and mitigation of hallucinations during the text generation process.
Introduction
LLMs such as GPT-3 and Vicuna have demonstrated exceptional performance in generating coherent and fluid text across various tasks. However, they often produce hallucinations—outputs that, while grammatically correct, are factually inaccurate or nonsensical. This phenomenon undermines the reliability of LLMs and hinders their broader acceptance in practical applications. The paper proposes a systematic method to tackle this issue by integrating detection and correction measures throughout the text generation procedure, rather than post-generation, to prevent the propagation of errors.
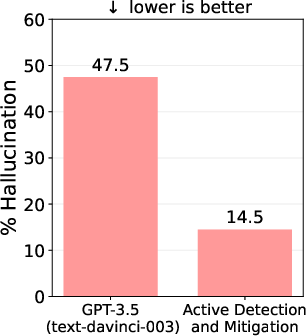
Figure 1: Comparing percentage of hallucinations (on the `article generation task') in the output of GPT-3.5 (text-davinci-003) and our proposed active detection and mitigation approach.
Methodology
The methodology is articulated around two key stages: Detection and Mitigation.
Hallucination Detection
Detection begins with identifying potential hallucination candidates based on model-generated logits. These logits offer a measure of uncertainty regarding specific concepts within generated sentences. The steps include:
- Concept Identification: Extracting key concepts from the text that may be prone to hallucinations. This is achieved through entity and keyword extraction models, or by instructing the model directly to identify important phrases.
- Uncertainty Assessment: Computing a probability score for each concept by examining the token-level probabilities derived from the model's logits. The most effective technique identified is using the minimum probability across tokens, which highlights the model's uncertainty more accurately compared to averaging or normalized products.
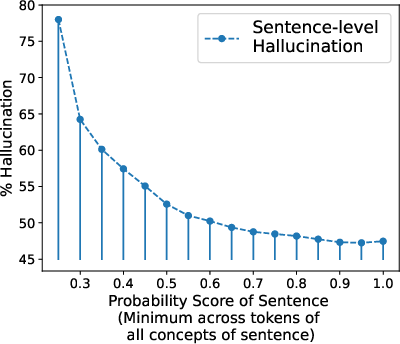
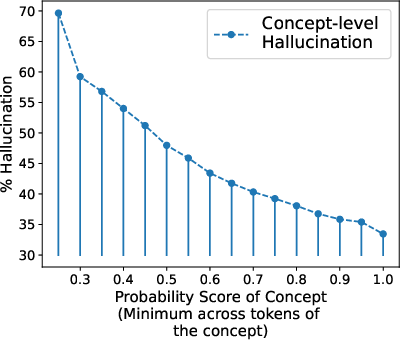
Figure 2: Trend of hallucination with the calculated probability score (Minimum technique) at both sentence and concept level. As the probability increases, the model's tendency to hallucinate decreases.
- Validation Question Formulation: Creating targeted yes/no questions that assess the factuality of each concept. These questions are then validated using external knowledge sources, primarily web search, to provide context.
- Knowledge Retrieval and Validation: Actively retrieving web-based knowledge to substantiate the information concerning the identified concepts, followed by validation to confirm accuracy.
Hallucination Mitigation
When a concept fails the validation, mitigation ensues, where the sentence is repaired leveraging the retrieved knowledge. This involves removing or substituting hallucinated parts with verified information, and subsequently continuing the generation process. This methodology not only rescues the current sentence from hallucinations but also prevents error propagation in future generations.
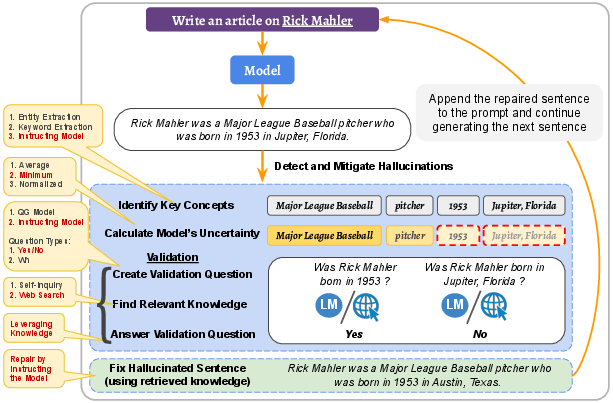
Figure 3: Illustration of our proposed approach for addressing LLMs' hallucination problem, showcasing the iterative generation, detection, and mitigation process.
Experiments and Results
The paper reports extensive experiments using GPT-3.5 on article generation tasks, showcasing significant reductions in hallucinations from 47.5% to 14.5% (Figure 1). It applies similar methodologies to Vicuna-13B and multi-hop and false premise questions, with the approach consistently reducing hallucinations across different scenarios and model types, reaffirming its effectiveness and adaptability.
(Figure 4 and Figure 5)
Figure 4: Comparing % of hallucination on Multi-hop Questions for various models and our approach.
Figure 5: Comparing % of hallucination on `False Premise Questions' with several model configurations, showing our approach's superior performance.
Implications and Future Work
The approach detailed in this paper has critical implications for enhancing the trustworthiness of LLMs in real-world applications, particularly in domains requiring high factual accuracy. By actively detecting and mitigating hallucinations, LLMs not only become more reliable but also more adaptable across different tasks and model architectures. Future work could involve further refinement of detection algorithms, exploration of additional use cases such as summarization and claim verification, and improvements in computational efficiency.
Conclusion
This paper addresses a significant challenge in the deployment of LLMs in practical settings by introducing a robust method for detecting and mitigating hallucinations. The promising results suggest potential for widespread application, inviting further research into refining and implementing such techniques to improve AI trustworthiness and functionality in diverse environments.

