SIMS-V: Simulated Instruction-Tuning for Spatial Video Understanding
Abstract: Despite impressive high-level video comprehension, multimodal LLMs struggle with spatial reasoning across time and space. While current spatial training approaches rely on real-world video data, obtaining diverse footage with precise spatial annotations remains a bottleneck. To alleviate this bottleneck, we present SIMS-V -- a systematic data-generation framework that leverages the privileged information of 3D simulators to create spatially-rich video training data for multimodal LLMs. Using this framework, we investigate which properties of simulated data drive effective real-world transfer through systematic ablations of question types, mixes, and scales. We identify a minimal set of three question categories (metric measurement, perspective-dependent reasoning, and temporal tracking) that prove most effective for developing transferable spatial intelligence, outperforming comprehensive coverage despite using fewer question types. These insights enable highly efficient training: our 7B-parameter video LLM fine-tuned on just 25K simulated examples outperforms the larger 72B baseline and achieves competitive performance with proprietary models on rigorous real-world spatial reasoning benchmarks. Our approach demonstrates robust generalization, maintaining performance on general video understanding while showing substantial improvements on embodied and real-world spatial tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SIMS-V — Simulated Instruction‑Tuning for Spatial Video Understanding (Explained for a 14‑year‑old)
Overview: What is this paper about?
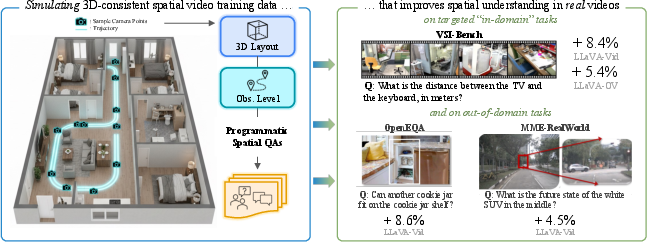
This paper is about teaching AI systems to understand where things are in videos and how they move and change over time. The authors built a way to create lots of “practice videos” inside 3D computer simulations (think high‑quality video games) and asked smart questions about those videos. Training on this simulated data helped the AI do better at real‑world spatial reasoning—like judging distances, figuring out left/right from different viewpoints, and remembering the order in which objects appear.
Goals: What were the researchers trying to find out?
The paper focuses on simple but important questions:
- Can we use simulated 3D worlds to teach an AI strong spatial skills for real videos?
- What kinds of questions should we train the AI on to get the best real‑world results?
- How much simulated data is actually needed to make the AI good at spatial reasoning?
Methods: How did they do it?
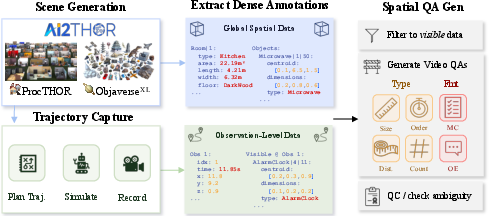
The team built a data‑generation system called SIMS‑V. Here’s how it works, explained with everyday ideas:
- Using 3D simulators: They used tools that create realistic indoor scenes (like kitchens and bedrooms) with many objects. In these “virtual worlds,” the computer knows exactly where every object is, how big it is, and where the camera is moving. This “privileged information” is like having the map and coordinates for everything in the room.
- Making videos: A virtual “agent” walks around these rooms, turning to look around, and records video clips—just like someone wearing a camera exploring a house.
- Collecting perfect facts: Because it’s a simulator, they can record precise details for each video frame—what objects are visible, their positions, distances, and directions.
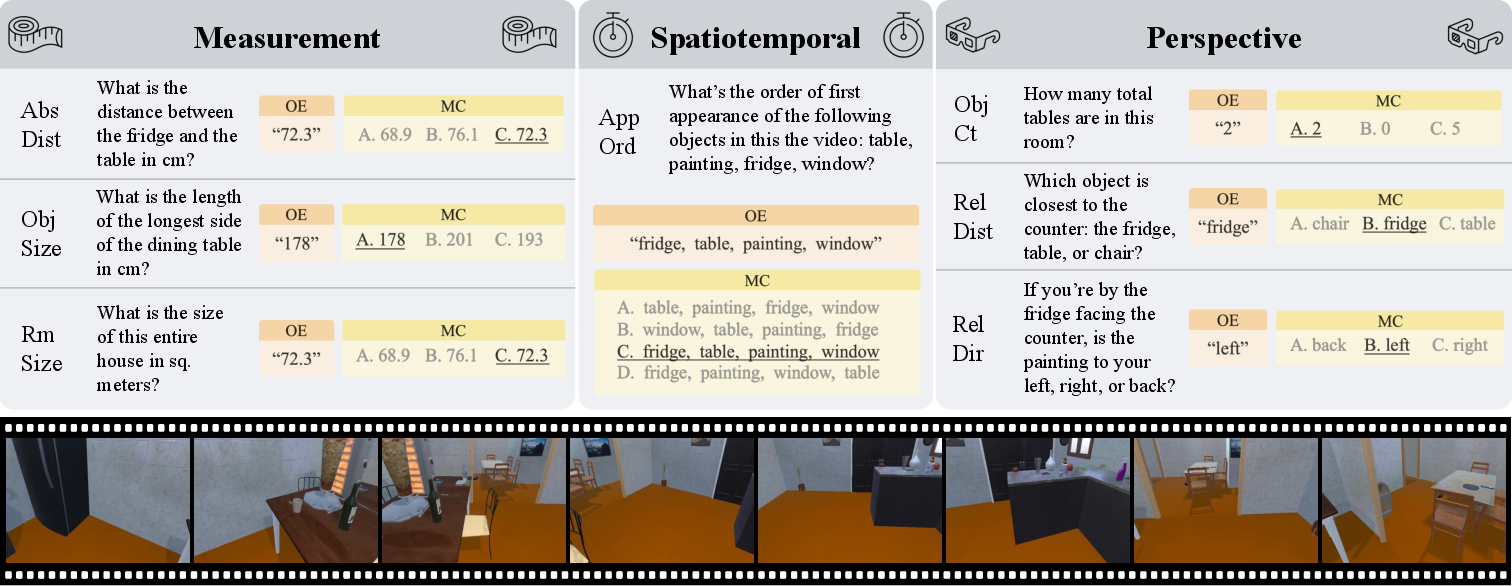
- Auto‑writing questions and answers: The system then automatically creates many question‑answer pairs about these videos. For example:
- Metric measurement: “How many meters between the chair and the table?”
- Perspective‑dependent reasoning: “If you stand by the sofa facing the TV, is the lamp to your left or right?”
- Temporal tracking: “Which object appears first in the video: the fridge, the sink, the toaster, or the microwave?”
These questions are made in both open‑ended style (you write the answer) and multiple‑choice (you pick from A, B, C, D). The system checks that each question is clear and answerable from the video.
- Training the AI: They fine‑tuned a video‑understanding AI model (a “multimodal LLM,” meaning it can read text and watch videos) on these simulated questions so it learns to reason about space and time.
Main Findings: What did they discover and why does it matter?
The authors found several big results:
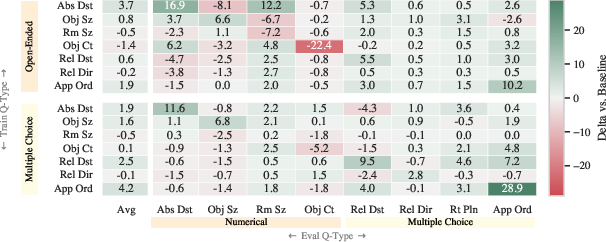
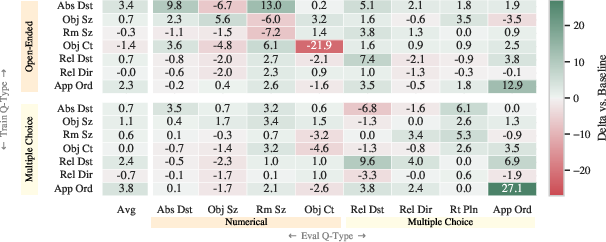
- A small set of question types is enough: Training mainly on three kinds of questions—metric distance, perspective (left/right/front/back from a viewpoint), and appearance order—was better than training on a big mix of many question types. In other words, focusing on core spatial skills beats trying to cover everything.
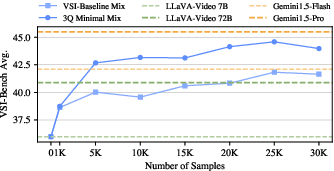
- It’s very data‑efficient: With only about 5,000 simulated examples, the AI already got strong improvements. With 25,000 examples, a 7‑billion‑parameter model (medium‑sized) beat a much larger 72‑billion baseline and came close to the performance of some top proprietary models on tough real‑world tests.
- It works on debiased tests: The improvements also held on a “debiased” version of the benchmark designed to prevent shortcut guessing. This shows the AI was truly using visual and spatial reasoning, not just patterns in the text.
- Generalization stays strong: The AI kept its general video understanding ability and even improved on tasks involving navigation and real‑world scenes, suggesting that learning spatial skills helps across different situations.
Implications: Why is this important and what could happen next?
- Better AI that understands space and time: This approach helps build AI that can handle practical tasks—like home robots navigating rooms, AR/VR systems understanding your space, or video assistants that can analyze where things are and how they change.
- Cheaper, scalable training: Instead of trying to collect and label tons of real videos with exact 3D measurements (which is very hard and expensive), we can generate high‑quality training data in simulations.
- Focused training is key: Carefully chosen question types (distance, perspective, order) teach core spatial skills efficiently. Future systems can use this recipe to get strong results faster.
- Next steps: Mix simulated training with general instruction data to avoid forgetting other skills, design simulations that match how models sample frames, and test across more model architectures. This could make spatially smart AI more reliable in everyday real‑world use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or left unexplored in the paper, formulated as concrete, actionable items for future research:
- Sim-to-real coverage: Training and generation are confined to simulated indoor scenes; evaluate transfer to outdoor, industrial, clinical, and mixed indoor–outdoor environments.
- Rendering fidelity: Quantify how photorealism, lighting models, texture variety, shadows, and material properties in the simulator affect real-world transfer; add controlled domain randomization ablations.
- Sensor realism: Introduce and test robustness to motion blur, noise, compression artifacts, rolling shutter, and exposure changes typical in real videos.
- Dynamic scenes: Extend beyond static-object environments to include moving agents/objects, non-rigid motion, occlusions, and interactions; measure impacts on temporal tracking and perspective reasoning.
- Camera diversity: Systematically vary camera intrinsics (FOV, focal length), height, lens distortion, and trajectory patterns (handheld jitter, fast pans) and quantify transfer sensitivity.
- Unknown scale: Absolute distance tasks benefit from known simulator scale; evaluate under unknown or ambiguous real-world scale and camera calibration, and add training signals that promote monocular scale reasoning.
- Multi-camera settings: Assess generalization to multi-view videos (e.g., security cameras, multi-angle recordings) and cross-view spatial reasoning.
- Route planning: Implement and evaluate the route planning category (currently omitted), including action sequencing and navigation in cluttered, dynamic environments.
- Object/scene diversity: Audit and expand object categories and room types; analyze performance across categories (e.g., rare objects, small items, reflective surfaces), and quantify coverage gaps.
- Question-format effects: Systematically compare open-ended vs multiple-choice formats (including distractor difficulty and bias) and their influence on transfer and calibration.
- Minimal mix generality: Validate whether the 3Q minimal mix (metric measurement, perspective-dependent reasoning, temporal tracking) remains optimal across other spatial benchmarks beyond VSI-Bench/Debiased and different video domains.
- Scaling laws: Extend data-scaling experiments beyond 25K examples to characterize saturation, diminishing returns, and optimal data budgets for spatial transfer.
- Architecture breadth: Test generalization across diverse VLM architectures (e.g., different vision encoders, language backbones, video tokenization strategies) and model sizes; derive architecture-specific recommendations.
- Catastrophic forgetting: Develop and evaluate curricula or data-mixing strategies that prevent forgetting of general video understanding while maximizing spatial gains; report trade-offs and metrics.
- Frame sampling co-design: Empirically study how different temporal sampling strategies (stride, segment coverage) affect learning and inference; implement training-time constraints to ensure question answerability under subsampling.
- Failure mode analysis: Provide systematic error taxonomies (e.g., quadrant confusions, left–right flips, near-equal distances, occlusion-induced mistakes) and targeted interventions per failure class.
- Long-horizon memory: Test longer videos (>3 minutes), cross-episode memory, and temporal reorientation (e.g., revisiting rooms) to probe persistent spatial memory and drift.
- Real-world fine-tuning: Compare pure simulation training against small-scale real-video fine-tuning or hybrid sim+real curricula; quantify gains and domain adaptation benefits.
- Robustness metrics: Evaluate calibration, confidence, abstention, and adversarial robustness in spatial QAs; add metrics beyond accuracy (e.g., expected calibration error).
- Human verification: Include human audits to confirm that generated questions are unambiguous and resolvable from the video content alone (especially for borderline visibility/occlusion cases).
- Physical reasoning: Incorporate and evaluate support, contact, collision, and affordance relations (e.g., “is the vase stably placed?”), moving toward physics-aware spatiotemporal understanding.
- Compositional relations: Add topological and relational categories (containment, adjacency, connectivity, path feasibility) not covered by the current question types.
- Multilingual generalization: Test whether spatial reasoning transfers across languages and whether training in multiple languages affects performance or template robustness.
- Prompt sensitivity: Measure sensitivity to paraphrases and alternative phrasings of spatial questions; assess brittleness to minor linguistic variations.
- Downstream robotics: Evaluate whether SIMS-V training improves embodied tasks requiring spatial cognition (navigation, manipulation) in real robots, not only QA benchmarks.
- Compute/reporting: Provide detailed compute, time, and energy costs for data generation and fine-tuning to inform practical adoption and scaling decisions.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging the paper’s findings on data-efficient simulated instruction-tuning (SIMS-V), the SIMS-VSI dataset, and the minimal 3-question training recipe (metric measurement, perspective-dependent reasoning, temporal tracking).
- Spatial video Q&A features for vision AI platforms (software)
- What you can deploy: Add spatial reasoning endpoints to existing video analytics products (e.g., “measure distance between two items,” “track first appearance order,” “is object A to the user’s back-left?”).
- Tools/products/workflows: Fine-tune a 7B video-LLM with the SIMS-VSI 3Q minimal mix (~25K examples); expose a REST API for spatial queries; validate with VSI-Bench-Debiased.
- Assumptions/dependencies: Enough GPU for fine-tuning (8×A100/H100 feasible), access to simulator assets for additional domain-specific data, camera frame sampling alignment with model constraints (e.g., 32–64 frames).
- CCTV analytics with proximity alerts and perspective-aware situational reports (security/public safety)
- What you can deploy: Automated alerts when people or objects are within unsafe distances of restricted areas; directional descriptions relative to fixed landmarks (e.g., “intruder is behind the loading bay door, front-right from the camera viewpoint”).
- Tools/products/workflows: Integrate fine-tuned 7B model in VMS (Video Management Systems); use a calibration module to map pixel-to-meter conversion; deploy dashboards with temporal tracking widgets.
- Assumptions/dependencies: Basic camera calibration or reference scaling, consistent viewpoints, clear visibility under varied lighting, policies for alert thresholds and false positive handling.
- Warehouse and facility operations copilots (robotics/industrial)
- What you can deploy: Operator-assist tools that answer spatial questions about pallets, racks, lanes; quick route hints; estimated distances between stock and pickup points; appearance order for inventory flow.
- Tools/products/workflows: Fine-tune with domain-specific simulated warehouses (ProcTHOR-like environments); add a “spatial QA” pane to teleoperation UIs; periodically test against real footage and VSI-Bench-Debiased.
- Assumptions/dependencies: Domain-relevant simulated assets and layouts, minimal occlusion or multi-camera stitching, risk controls for erroneous spatial outputs.
- Smart home camera assistants for spatial descriptions and object finding (consumer IoT)
- What you can deploy: Voice-driven spatial descriptions (“the cups are to your left of the sink”), distance estimates for DIY tasks, tracking the first appearance of an item during a video search.
- Tools/products/workflows: On-device or private-cloud 7B model with 3Q fine-tuning; edge video sampling; privacy-preserving storage; spatial QA in companion apps.
- Assumptions/dependencies: Privacy compliance, adequate on-device compute or efficient streaming, accuracy under clutter and occlusions.
- AR measuring and guidance for indoor tasks (AR/VR)
- What you can deploy: Lightweight measurement and directional hints in AR headsets or smartphone AR (“walk 2 meters to the front-left to reach the tool chest”).
- Tools/products/workflows: Pair fine-tuned 7B model with device AR frameworks; use known object sizes or fiducials for scale; present overlays with temporal tracking cues.
- Assumptions/dependencies: Scale estimation or calibration references, stable pose tracking, acceptable latency for live guidance.
- Spatial narration for low-vision accessibility (assistive tech/healthcare)
- What you can deploy: Wearable camera assistant that narrates where items are relative to the user’s perspective and which appeared first.
- Tools/products/workflows: Fine-tuned 7B model running on belt-pack or phone; voice interface; directional templates from SIMS-V question types; evaluate on debiased benchmarks.
- Assumptions/dependencies: Battery and compute constraints, robust narration accuracy in unconstrained environments, consent and privacy safeguards.
- Research and teaching modules for spatial reasoning (academia/education)
- What you can deploy: Course labs that reproduce SIMS-V data generation and ablation studies; student projects on efficient sim-to-real transfer using 3Q minimal mixes.
- Tools/products/workflows: Use AI2-THOR/ProcTHOR/Objaverse, SIMS-VSI dataset, VSI-Bench and VSI-Bench-Debiased; standardized training scripts.
- Assumptions/dependencies: Licensing and asset usage compliance, GPU availability, institutional IRB/privacy policies if mixing with real data.
- Privacy-first synthetic training policy updates (policy/compliance)
- What you can deploy: Organizational guidance to prefer simulation-based spatial training for new features, reducing reliance on sensitive real-world footage.
- Tools/products/workflows: Policy docs citing SIMS-V evidence; audit trails showing synthetic-to-real evaluation with debiased benchmarks; internal model cards.
- Assumptions/dependencies: Regulator acceptance, governance to prevent accidental leakage from real datasets, ongoing validation to ensure comparable performance.
Long-Term Applications
The following use cases require additional research, scaling, domain adaptation, safety validation, or simulator co-design to reach production-grade reliability.
- Autonomy-grade indoor navigation and manipulation using spatial QA as a planning signal (robotics)
- What could emerge: Robots that query a spatial video model for distances, directions, and temporal cues in real time, improving task planning and error recovery.
- Tools/products/workflows: Closed-loop integration of SIMS-V training with robot policies; sim-to-real curriculum learning; co-design with frame-sampling strategies; continual learning pipelines.
- Assumptions/dependencies: Strong real-time performance, rigorous safety cases, domain-specific simulators with physics fidelity, robust sensor fusion.
- Hospital patient monitoring and clinical workflow analytics (healthcare)
- What could emerge: Systems that understand patient-room layouts, detect unsafe proximities, and track equipment appearance/order during procedures.
- Tools/products/workflows: HIPAA-compliant deployments; clinical-grade calibration; longitudinal validation with clinical partners; simulator expansions to healthcare environments.
- Assumptions/dependencies: Regulatory approvals, bias and error mitigation in life-critical settings, specialist simulation assets, human-in-the-loop oversight.
- Construction, facility management, and digital twin monitoring (construction/energy)
- What could emerge: Spatial video insights for room-size estimation, object placement, route planning and progress tracking across sites.
- Tools/products/workflows: BIM-linked video analytics; simulator-based pretraining with construction assets; AR overlays for foremen; 3D reconstruction integration.
- Assumptions/dependencies: Robust outdoor and large-space generalization (beyond indoor), accurate scaling under wide-angle lenses, integration with CAD/BIM standards.
- Autonomous driving and traffic scene reasoning (transportation)
- What could emerge: Spatiotemporal video models estimating distances, directions, and temporal events in complex traffic scenes to augment perception stacks.
- Tools/products/workflows: Domain-specific simulators (CARLA, etc.) with 3Q-like training; multi-camera fusion; latency-optimized inference; safety validation suites.
- Assumptions/dependencies: High-fidelity simulation assets, extreme reliability thresholds, adversarial/weather robustness, real-time constraints.
- Insurance claims automation via spatial video verification (finance)
- What could emerge: Systems that verify claims by estimating object distances, relative positions, and appearance timelines in submitted videos.
- Tools/products/workflows: Claims triage tools; synthetic pretraining; debiased evaluation; human review escalation paths.
- Assumptions/dependencies: Legal admissibility, fairness and bias controls, stakeholder acceptance, cross-domain generalization to diverse household/industrial scenes.
- Spatial reasoning tutors and curricula at scale (education)
- What could emerge: Interactive AI tutors that guide students through perspective-taking, metric estimation, and temporal reasoning with simulated videos.
- Tools/products/workflows: Curriculum packs leveraging SIMS-V question templates; adaptive assessment using debiased benchmarks; classroom AR integrations.
- Assumptions/dependencies: Pedagogical validation, accessibility, content safety, alignment to educational standards.
- Certification and standards for spatial video AI (policy/standards)
- What could emerge: Sector-wide benchmarks (e.g., VSI-Bench-Debiased variants) used to certify spatial reasoning performance for safety-critical applications.
- Tools/products/workflows: Standardized test suites, reporting requirements, bias audits, conformance programs backed by industry groups.
- Assumptions/dependencies: Community adoption, cross-industry cooperation, maintenance of public debiased benchmarks.
- Simulator-aware data co-design with model internals (software/ML tooling)
- What could emerge: Data generation tools that tailor simulated videos so that critical spatial cues survive model-specific frame sampling and tokenization.
- Tools/products/workflows: Auto-validation that questions remain answerable under target sampling; co-optimized render pipelines; meta-learning for sampling strategies.
- Assumptions/dependencies: Transparent access to model internals, robust tooling across diverse architectures, reproducible protocols.
- On-device spatial assistants for AR glasses/edge cameras (consumer hardware)
- What could emerge: Low-latency spatial guidance, measurements, and temporal tracking fully on device.
- Tools/products/workflows: Model compression/distillation of 7B spatial models; hardware acceleration; multimodal privacy features.
- Assumptions/dependencies: Battery and thermal constraints, private inference requirements, edge optimization for real-world clutter.
- Crowd safety and urban environmental monitoring (public sector)
- What could emerge: Systems that monitor distances and directions among groups, detect dangerous proximities, and track temporal patterns in public venues.
- Tools/products/workflows: Municipal analytics platforms; privacy-preserving aggregation; scenario simulators for public spaces to pretrain spatial models.
- Assumptions/dependencies: Privacy and ethics frameworks, consent and data governance, generalization to diverse outdoor scenes, risk management for false alarms.
Glossary
- Absolute distance: A metric measurement of the direct spatial separation between two objects, typically in meters. "absolute distance yields OE:\ +16.9 and MC:\ +11.6."
- AdamW: An optimizer for training neural networks that decouples weight decay from gradient updates. "Optimizer: AdamW (via DeepSpeed)"
- AI2-THOR: A 3D interactive simulator for embodied AI research used to generate realistic indoor environments. "We leverage the AI2-THOR simulator"
- Appearance order: The sequence in which objects first become visible over time in a video. "appearance order yields MC:\ +28.9 and OE:\ +10.2"
- BF16: Brain floating point 16-bit precision format that accelerates training while preserving numerical stability. "Precision: Mixed precision (BF16)"
- Cartesian plane: A coordinate system defining directions and quadrants used for perspective-dependent spatial questions. "The directions refer to the quadrants of a Cartesian plane (if I am standing at the origin and facing along the positive y-axis)."
- Cosine scheduler: A learning rate schedule that follows a cosine curve, often with an initial warmup phase. "Scheduler: Cosine with 3\% warmup"
- DeepSpeed: A deep learning optimization library enabling efficient training of large-scale models. "Optimizer: AdamW (via DeepSpeed)"
- Ego-position: The agent’s spatial location used as a reference point in spatiotemporal distance queries. "closest to the ego-position at the last frame in the video?"
- EgoSchema: A benchmark for long-form egocentric video understanding. "Similarly, EgoSchema~\cite{mangalam2023egoschema}"
- Egocentric: Pertaining to video captured from the actor’s first-person viewpoint. "long-form egocentric video understanding"
- Embodied reasoning: Visual reasoning that involves an agent’s physical presence and interactions within an environment. "diverse spatial tasks including embodied reasoning~\cite{OpenEQA2023}"
- Gradient checkpointing: A memory-saving technique that trades computation for reduced GPU memory by recomputing intermediate activations. "Gradient checkpointing: Enabled"
- Ground truth: Perfect reference annotations provided by simulation for spatial and temporal properties. "perfect ground truth"
- Instance segmentation masks: Per-pixel labels identifying individual object instances in an image. "instance segmentation masks"
- LLaVA-OneVision-7B: A 7B-parameter generalist vision-LLM supporting images and videos. "LLaVA-OneVision-7B"
- LLaVA-Video-7B: A 7B-parameter video-optimized vision-LLM with specialized temporal processing. "LLaVA-Video-7B"
- Mixed precision: Training method using lower-precision arithmetic to accelerate computation and reduce memory. "Precision: Mixed precision (BF16)"
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple data modalities (e.g., text and video). "multimodal LLMs (MLLMs) struggle with understanding spatial reasoning"
- Objaverse: A large-scale dataset of 3D objects used to enrich simulated scenes. "using objects from Objaverse"
- OpenEQA: An embodied question answering benchmark evaluating spatial and navigation reasoning. "OpenEQA~\cite{OpenEQA2023}"
- Perspective-dependent reasoning: Spatial inference that depends on the observer’s viewpoint and orientation. "perspective-dependent reasoning"
- Perspective-taking: Inferring spatial relations by adopting a specific viewpoint within a scene. "perspective-taking"
- ProcTHOR: A tool for procedurally generating diverse 3D indoor environments within AI2-THOR. "ProcTHOR~\cite{deitke2022procthor}"
- Privileged information: Simulator-internal metadata (e.g., exact 3D positions) unavailable in real-world footage. "privileged information available in simulators"
- Qwen2: A transformer-based LLM backbone used in the experiments. "Qwen2~\cite{yang2024qwen2}"
- Relative direction: The directional relationship (e.g., left/right/back) of one object with respect to another from a given viewpoint. "Relative Direction (Hard)"
- Relative distance: A comparative measure of which objects are closer or farther relative to a reference object. "Relative Distance"
- Route planning: Determining a sequence of actions to navigate from a start location to a destination. "We did not implement route planning questions due to its complexity."
- SigLIP-SO400M-patch14-384: A vision encoder architecture used to extract visual features from frames. "SigLIP-SO400M-patch14-384"
- Sim-to-real transfer: The process of training on simulated data and achieving performance on real-world tasks. "sim-to-real transfer remains a fundamental challenge"
- SIMS-VSI: The simulated spatial video dataset of question-answer pairs used for instruction-tuning. "we generate SIMS-VSI, a dataset comprising over 200k spatial question-answer pairs"
- SlowFast-style temporal pooling: A video processing technique that aggregates temporal information across frames with multi-rate pathways. "SlowFast-style temporal pooling"
- Spatial annotations: Labels specifying spatial properties (e.g., positions, distances) used for training and evaluation. "spatial annotations in web-scale image-text pretraining data"
- Spatial reasoning: Understanding and inferring relationships among objects in space, including distances and directions. "multimodal LLMs (MLLMs) struggle with understanding spatial reasoning"
- Spatiotemporal reasoning: Spatial reasoning extended over time, requiring tracking changes across video frames. "spatiotemporal reasoning"
- Temporal token allocation: Model design choice distributing attention or tokens over time to process video sequences. "temporal token allocation"
- Temporal tracking: Following objects’ visibility and positions across time in a video. "temporal tracking of object appearances across minutes-long video trajectories"
- VideoMME: A benchmark for general video understanding across diverse real-world scenarios. "On VideoMME~\cite{fu2025videomme}, a comprehensive benchmark"
- Visual tokens: Discrete feature vectors representing patches or regions extracted from an image/frame. "Each frame encoded into a 12\texttimes{}12 grid of visual tokens"
- VSI-Bench: A real-world benchmark focused on spatial intelligence in videos. "VSI-Bench"
- VSI-Bench-Debiased: A refined version of VSI-Bench designed to reduce non-visual shortcuts in evaluation. "VSI-Bench-Debiased"
Collections
Sign up for free to add this paper to one or more collections.