- The paper introduces VR-Bench to evaluate video models' spatial reasoning via maze-solving tasks, benchmarking dynamic visual and temporal planning.
- It demonstrates that video models using chain-of-frame reasoning outperform text-based methods in efficiently solving complex maze tasks.
- The study shows scaling effects, as increased inference sampling boosts accuracy and generalization across diverse maze variations.
Reasoning via Video: Evaluation of Video Models through Maze-Solving Tasks
Introduction
The paper "Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks" (2511.15065) investigates the potential of video models to engage in spatial reasoning via video generation. With recent advancements in video models capable of coherent motion dynamics and high-fidelity video generation, this research seeks to explore their reasoning capabilities, akin to LLMs evolving from text generation to reasoning. The paper introduces VR-Bench, a benchmark designed to evaluate video models on maze-solving tasks, offering insights into their spatial planning and dynamic visual reasoning.
Dataset and Benchmark Design
VR-Bench Composition
VR-Bench includes five distinct maze types: Regular Maze, Trapfield, Irregular Maze, Sokoban, and 3D Maze, capturing both 2D and 3D spatial reasoning tasks. These mazes are procedurally generated, spanning diverse visual styles and difficulty levels, totaling 7,920 videos. Each video pairs with a trace reasoning task requiring models to determine optimal paths, challenging their spatial perception and planning abilities.

Figure 1: Variations of difficulty level and maze texture.
Reasoning Paradigm
Unlike traditional reasoning methods expressed in textual formats, video models employ a chain-of-frame (CoF) reasoning paradigm, generating sequential visual frames that encode spatial dynamics and temporal causality. This approach utilizes the inherent continuity of video data, making it a suitable substrate for multimodal reasoning.
Evaluation Metrics
VR-Bench evaluates video models across several metrics:
- Exact Match (EM): Assessing complete trajectory correctness against the optimal path.
- Success Rate (SR): Measuring task completion by reaching designated goals.
- Precision Rate (PR): Quantifying the accuracy of steps along the trajectory.
- Step Deviation (SD): Evaluating path-length efficiency relative to the optimal solution.
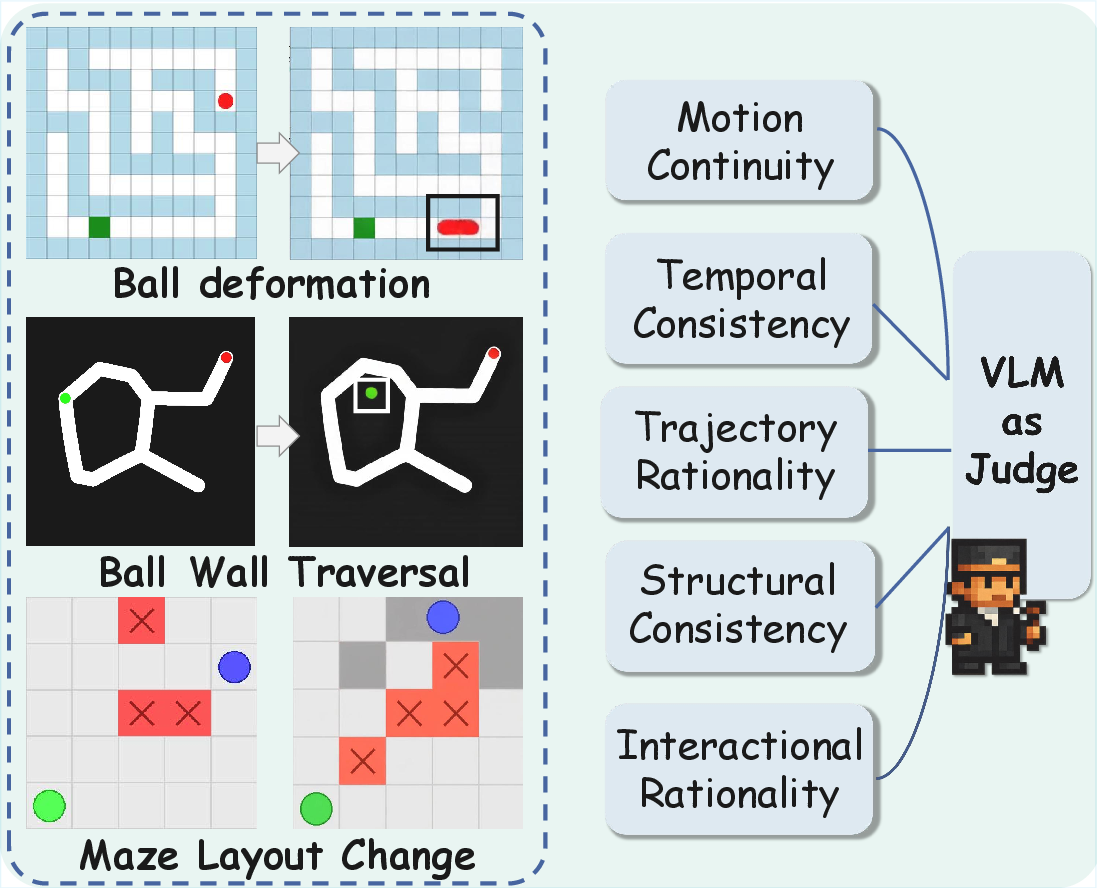
Figure 2: Bad case visualization and VLM-as-judge schematic.
Additionally, rule compliance and structural fidelity are evaluated using VLM-score and Maze Fidelity (MF), examining motion continuity, structural consistency, and interactional rationale.
Experimental Analysis
The paper compares various video models, both proprietary and open-source, against VLMs under VR-Bench tasks. Wan-R1, a fine-tuned video model, demonstrates top-tier performance across nearly all evaluation metrics, achieving significant efficiency and accuracy improvements compared to baseline models.
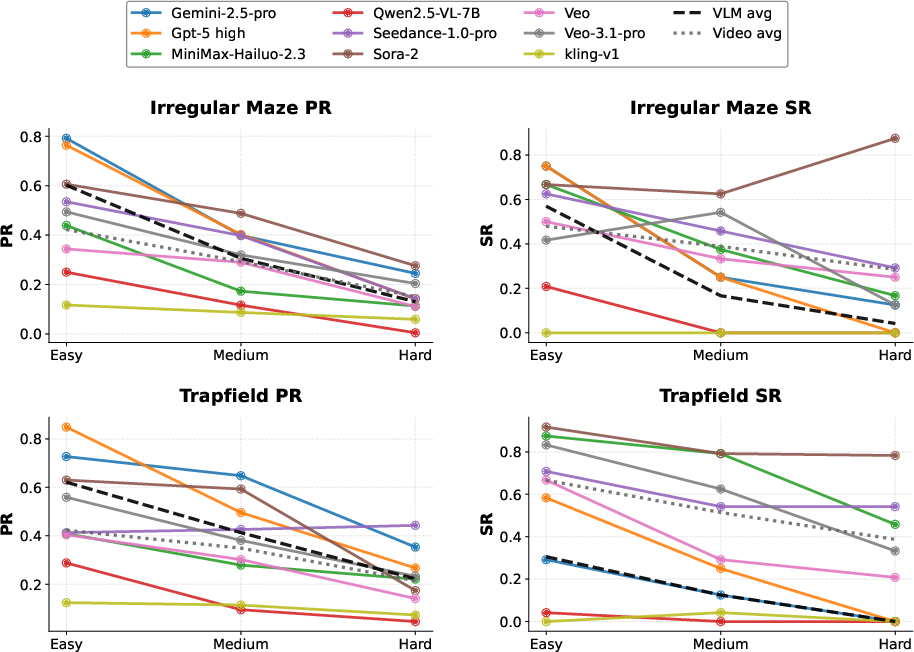
Figure 3: Model performance (PR and SR) on Irregular Maze and Trapfield across difficulty levels. Each curve represents a baseline, while the dashed and dotted lines indicate VLM and Video Model averages.
Reasoning Efficacy
Video models exhibit superior reasoning capabilities under complex task conditions, outperforming text-based reasoning methods. This advantage is attributed to their ability to leverage temporal visual context and spatial continuity, facilitating higher information density and more stable reasoning processes.
Scaling Effects and Generalization
The research highlights the test-time scaling effect, where increased sampling during inference leads to substantial performance gains, akin to self-consistency observed in LLMs. Video models explore diverse reasoning paths, improving reliability and accuracy.
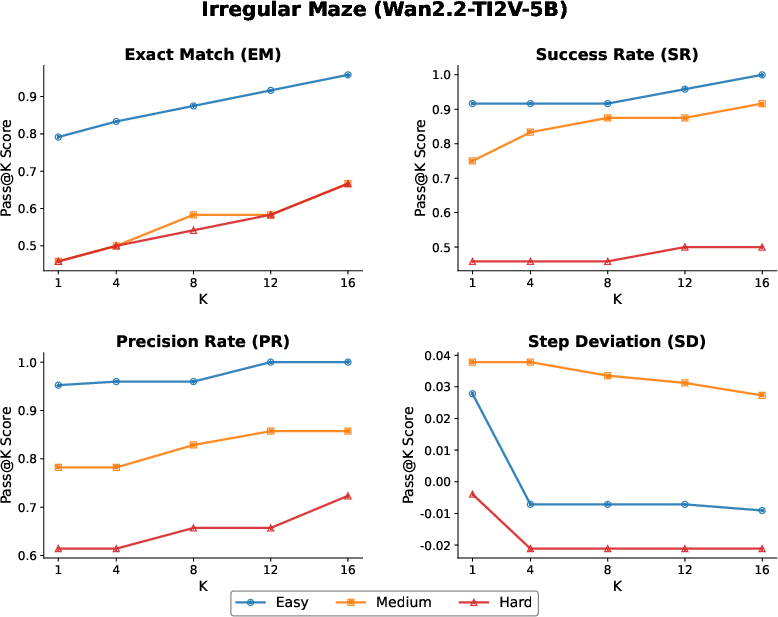
Figure 4: Performance on Irregular Maze using Wan-R1 under test-time scaling. Results are shown across different sampling numbers (K∈1,4,8,12,16) and difficulty levels.
Wan-R1 demonstrates strong difficulty and type generalization, showing robust reasoning abilities across unseen maze variations and textures, emphasizing its scalability in diverse environments.
Conclusion
This paper presents an in-depth evaluation of video models' reasoning abilities through the VR-Bench benchmark, showcasing their potential in spatial reasoning tasks. The findings affirm video models' proficiency in dynamic visual reasoning, outperforming text-based methods, and highlight their scalability through test-time scaling effects and generalization across diverse scenarios.
Future research could extend VR-Bench to broader complex reasoning tasks and explore embodied reasoning settings, enhancing video models' application in interactive environments.
