- The paper demonstrates that sequential fine-tuning with pose estimation loss after U-Net segmentation pretraining significantly reduces RMSE, outperforming baseline models by 1.5–8.8%.
- The methodology integrates a differentiable 2D/3D registration loss with heatmap prediction to impose geometric consistency and penalize misalignments in 3D space.
- Improved landmark detection enhances intraoperative guidance, navigation accuracy, and postoperative assessment in challenging pelvic fluoroscopic imaging scenarios.
Enhanced Landmark Detection in Pelvic Fluoroscopy via Pose-aware 2D/3D Registration Loss
Introduction
Automated anatomical landmark detection in medical imaging has direct implications for intraoperative guidance, navigation, and postoperative assessment. In the context of orthopedic pelvic interventions, precise landmark localization is fundamental due to the complex geometry, high intersubject variability, and the inherent projectional ambiguity of 2D fluoroscopic images relative to 3D anatomy. Traditional approaches utilize fully convolutional networks—commonly U-Nets—trained with segmentation-based losses to predict anatomical probability heatmaps, extracting landmark positions via soft-argmax or argmax mechanisms. However, conventional pixel-wise losses such as cross-entropy fail to encode geometric constraints relevant to the physical task, particularly in scenarios of variable patient pose and imaging orientation.
The presented work introduces a hybrid learning framework for pelvic landmark detection, explicitly coupling 2D heatmap prediction with a 2D/3D geometric registration protocol during training. By incorporating a pose estimation loss (PEL) via a differentiable 2D/3D registration, the framework aims to enhance spatial correspondence by penalizing mislocalization in 3D geometric terms. This approach is motivated by the observation that accurate 2D landmark detection and camera pose recovery are not independent: subpixel deviations in image coordinates can result in amplified misalignment in the registration space, especially across diverse, non-standard views. The method employs three regimes of supervision: standard segmentation loss, composite loss (segmentation plus pose estimation), and sequential fine-tuning with pose estimation loss.
Methodology
The core architecture leverages a U-Net for landmark heatmap generation, producing location probability distributions for eight pelvic landmarks. The soft-argmax operation extracts differentiable coordinate estimates from each heatmap. Pose estimation loss is formulated by solving a 2D/3D registration problem between predicted 2D landmarks and ground truth 3D CT-space landmark positions. Rigid pose parameters (θ∈SE(3)) are estimated by minimizing the squared distance between projected 3D landmarks (under candidate pose θ) and detected 2D landmarks, with optimization performed via L-BFGS or Adam in a differentiable PyTorch loop.
Training paradigms compared include: (1) standard segmentation-only (baseline), (2) joint training with composite loss (segmentation and weighted pose loss), and (3) sequential: segmentation pretraining followed by fine-tuning with pose estimation loss alone.
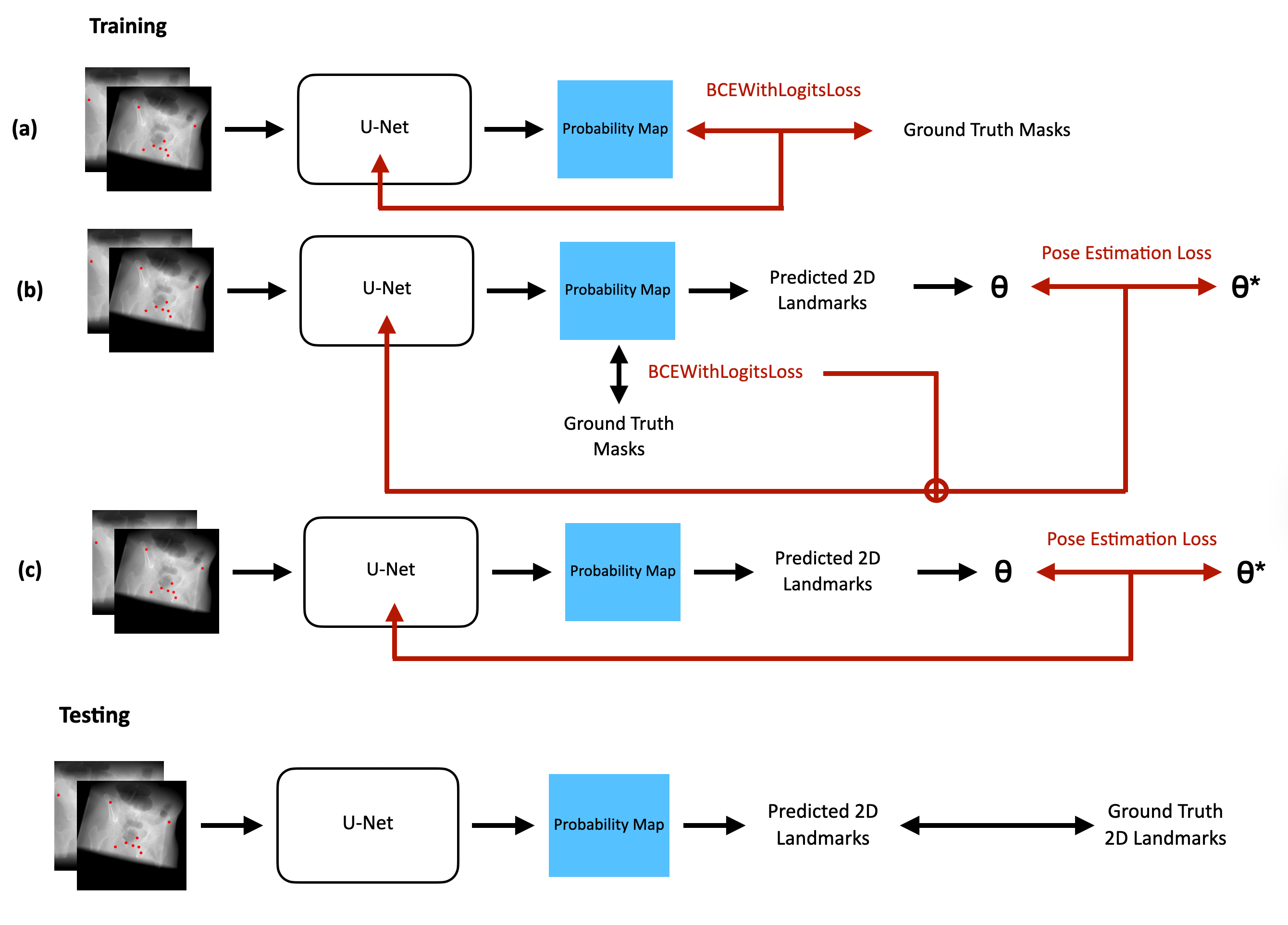
Figure 1: Model pipeline diagram for (a) Baseline U-Net, (b) composite loss U-Net, and (c) fine-tuned U-Net with pose estimation loss (θ denotes estimated pose, θ∗ ground truth).
Landmark placement follows standard anatomical conventions as visualized below.
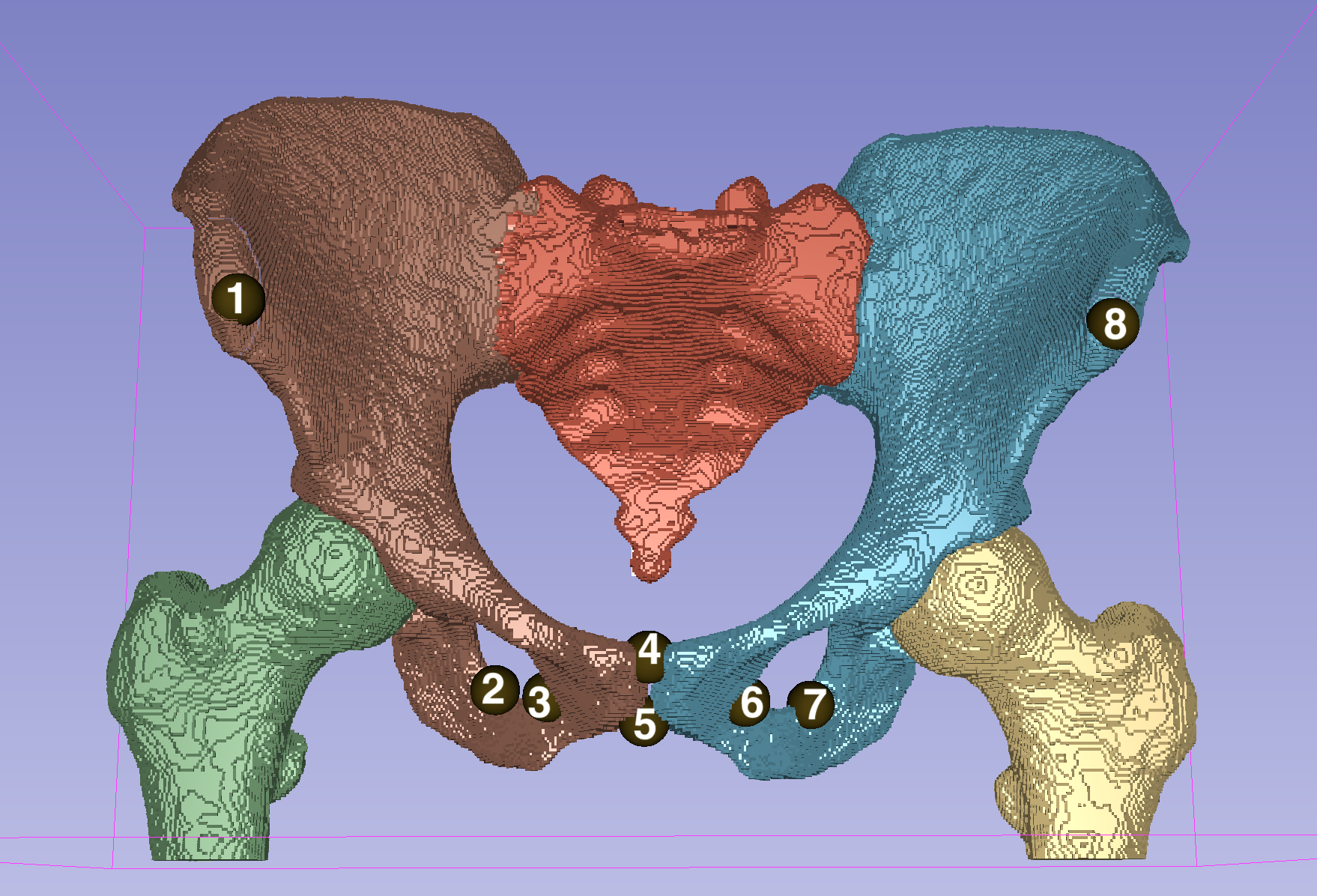
Figure 2: Placement of eight target landmarks on the pelvic bone, annotated for explicit reference.
For training and evaluation, the study utilizes 90 annotated CT pelvis scans, each rendered via a differentiable DRR engine (DiffDRR) to synthesize multiple 2D X-rays under randomly sampled out-of-plane rotations (rx,ry,rz) and translations (tx,ty,tz), thus explicitly modeling intraoperative variability in view.
Experimental Results
Model performance is quantitatively assessed via RMSE (pixels) between predicted and ground truth 2D landmark positions, computed on (1) “Novel View” partitions (withheld imaging poses) and (2) “Novel Subject” partitions (unseen CT subjects). Three models are compared:
- Baseline U-Net: segmentation loss only
- U-Net, composite loss: segmentation + pose estimation loss
- U-Net, fine-tuned: segmentation pretrain, then pose estimation loss
The fine-tuned U-Net demonstrates the lowest mean RMSE across both evaluation settings (8.45/5.09 pixels, internal/external), outperforming the baseline by 1.5% and 8.8%, respectively. Notably, joint optimization with composite or exclusive PEL substantially degrades convergence and accuracy, with pose-only models experiencing outright divergence. The composite loss model exhibits a 2.4x (internal) and 2.1x (external) increase in error over the baseline, indicating counterproductive loss interference.
This suggests that pose estimation loss aids performance only when supplied as a second-stage, targeted regularizer after the network has already learned plausible spatial representations through segmentation supervision. End-to-end optimization with pose loss destabilizes feature learning due to nonconvexity and lack of intermediate spatial signals required for effective 2D/3D supervision.
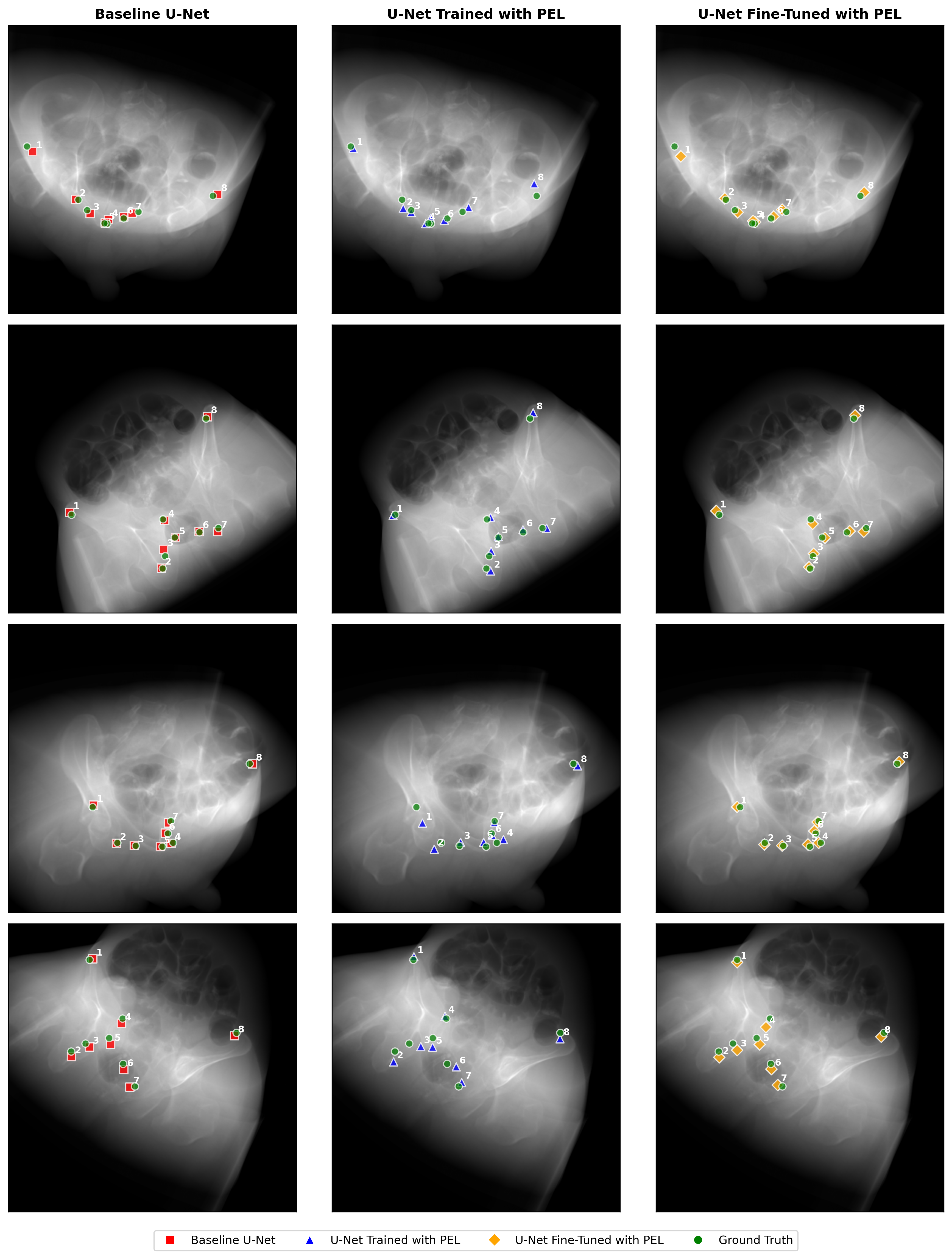
Figure 3: Repeated visualization of the three model pipelines for ease of cross-referencing with results.
Theoretical and Practical Implications
This work establishes that leveraging differentiable 2D/3D registration as a loss function imparts geometric consistency to a landmark detection network, but only under an appropriately staged curriculum. The findings imply that standard segmentation pretraining provides necessary spatial priors, after which geometric supervision can correct for view-dependent misidentification—yielding more robust detectors in non-canonical orientations, as routinely encountered during surgery.
The marked failure of composite and PEL-only regimes underscores inherent limitation of direct pose supervision in the weak-feature regime; when features are not spatially grounded, pose gradients can be uninformative or misleading. This suggests that future extensions must consider adaptive or curriculum-based optimization schedules, possibly invoking loss weighting schedules or conditional gating.
From a clinical perspective, improved detection translates into enhanced localization for navigation, reduced annotation variance, and more reliable downstream registration in CAI pipelines. The framework’s reliance on differentiable DRR further enables its integration with simulation-based training, domain adaptation, or temporal filtering for fluoroscopic video, providing a foundation for future reinforcement learning or probabilistic inference strategies in intraoperative tracking.
Limitations and Future Directions
The reliance on synthetic DRRs (as opposed to clinical acquisition) limits direct generalizability, as real intraoperative data contain SNR degradations, hardware artifacts, and anatomical aberrations not captured in simulation. Additionally, landmark set size, bone coverage, and L-BFGS optimization cost represent further bottlenecks for scaling or real-time implementation. Future research should evaluate clinical effectiveness on true fluoroscopy, experiment with differentiable or learned pose solvers for efficiency, adaptively tune loss schedules, and extend the framework to dense or temporal landmarking tasks.
Conclusion
Integrating pose estimation loss derived from rigid 2D/3D landmark registration into the training pipeline demonstrably improves the accuracy of pelvic anatomical landmark detection in fluoroscopic images, provided sequential fine-tuning is employed. Direct composite or exclusive pose loss regimes are suboptimal due to conflicting optimization signals. These findings advance the coupling of geometric and deep feature learning for medical image analysis, and motivate further exploration of geometric supervision as a modular enhancement for clinical AI systems.
Reference: "Enhanced Landmark Detection Model in Pelvic Fluoroscopy using 2D/3D Registration Loss" (2511.21575)