- The paper introduces PEFT-Bench, a novel benchmark evaluating parameter-efficient fine-tuning methods with diverse datasets and standardized evaluation metrics.
- It presents PEFT-Factory, enabling streamlined integration of new methods alongside the innovative PSCP metric that assesses model performance, speed, and memory usage.
- Experimental results highlight LoRA’s superior performance and reveal stability trade-offs, emphasizing the need for meticulous hyperparameter tuning.
A Parameter-Efficient Fine-Tuning Methods Benchmark: PEFT-Bench
Introduction
The paper "PEFT-Bench: A Parameter-Efficient Fine-Tuning Methods Benchmark" (2511.21285) introduces PEFT-Bench, a robust benchmark designed specifically for evaluating Parameter-Efficient Fine-Tuning (PEFT) methods applied to autoregressive LLMs. The primary goal is to address the challenges posed by the massive scale and computational demands of these models. PEFT methods provide a practical alternative by reducing the number of trainable parameters, thereby lowering computational costs while preserving model performance on downstream tasks.
Methodology
PEFT-Bench establishes a comprehensive framework comprising three components: diverse datasets, a variety of PEFT methods, and standardized evaluation metrics. Among the unique contributions is the introduction of PEFT-Factory, a framework built upon the LLaMa-Factory backbone, enabling streamlined integration of newly developed PEFT methods.
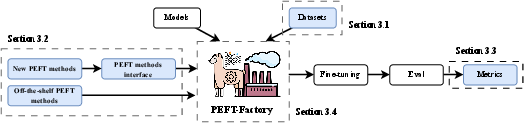
Figure 1: Diagram describing the methodology of PEFT-Bench. Blue components represent our contributions.
PEFT-Bench employs 27 NLP datasets segmented into three categories—NLU and Reasoning, Math, and Code Generation—ensuring extensive coverage and versatility in task representation. This dataset diversity is pivotal for evaluating the generalizability and robustness of PEFT methods across various domains.
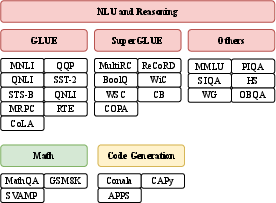
Figure 2: A diagram showing the overview and categorizations of datasets used in PEFT-Bench, totaling 27 datasets categorized into 3 main groups -- NLU and Reasoning, Math, and Code Generation.
PEFT Methods
The paper categorizes PEFT methods into additive, reparametrized, and selective types, meticulously choosing representative methods such as IA3, Prompt Tuning, Prefix Tuning, P-Tuning, LoRA, and LNTuning. This selection ensures coverage of significant techniques popular in contemporary NLP research.
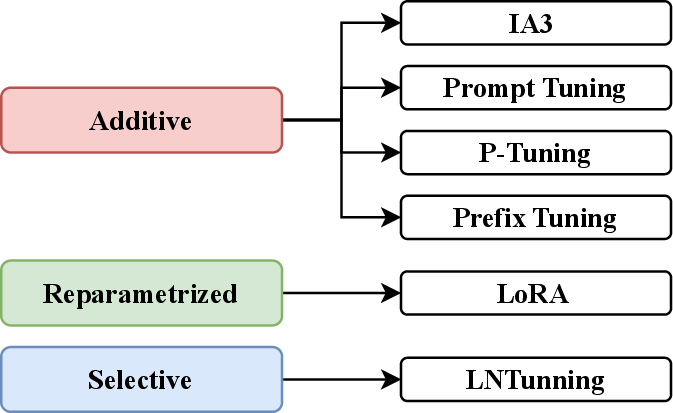
Figure 3: We evaluate methods from additive, reparametrized, and selective PEFT categories. The diagram shows the categorization of each method.
Evaluation Metrics
For a comprehensive evaluation, PEFT-Bench introduces the PEFT Soft Score Penalties (PSCP) metric, which uniquely integrates trainable parameters, inference speed, and training memory usage. This metric addresses practical constraints crucial for deploying models under real-world conditions.
Experimental Results
The benchmark results highlight LoRA's superior performance across many tasks, albeit LNTuning shows increased efficiency with fewer parameters, as indicated by the PSCP metric. Notably, soft prompt-based methods proved challenging to train effectively, suggesting a need for intensive hyperparameter tuning for robust task performance.
In stability tests, IA3 exhibited the most consistent results, whereas LoRA demonstrated variability, particularly with resource-constrained datasets. P-Tuning struggled with stability, reinforcing the importance of optimized hyperparameters for reliable performance.
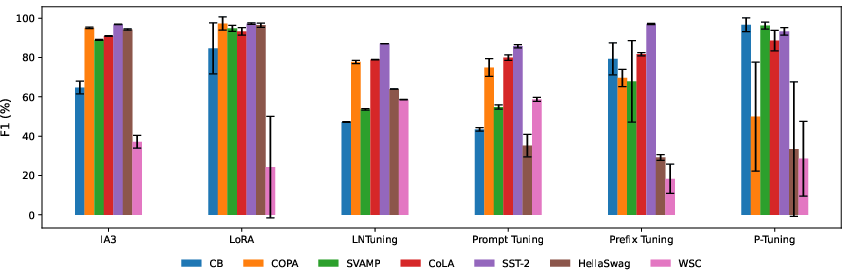
Figure 4: Bar chart showing the stability of different PEFT methods on 4 low-resource datasets. IA3 achieves the lowest standard deviation on average across all datasets, and LoRA is less stable than other methods with CB datasets, while also achieving a better average score.
Conclusion
PEFT-Bench stands as the first holistic benchmark specifically targeting PEFT methods in NLP, accompanied by PEFT-Factory to facilitate efficient implementation. The introduction of the PSCP metric opens avenues for balanced evaluations highlighting efficiency alongside performance. Future advancements include extending the benchmark with new PEFT methods and deploying a web interface for result visualization, further fostering research and development in parameter-efficient model adaptation.
