- The paper introduces a unified autoregressive framework that integrates spatial and temporal dependencies via a discrete spacetime pyramid for efficient image and video generation.
- It employs innovations such as knowledge inheritance, stochastic quantizer depth, and semantic scale repetition to enhance reconstruction quality and motion stability.
- The model achieves state-of-the-art results by generating 5s 720p videos 10× faster than diffusion methods, while also supporting interactive long video synthesis.
InfinityStar: Unified Spacetime AutoRegressive Modeling for Visual Generation
Introduction and Motivation
InfinityStar presents a unified autoregressive framework for high-resolution image and video synthesis, leveraging a discrete spacetime pyramid modeling paradigm. The approach is motivated by the limitations of both diffusion-based and autoregressive models in visual generation. Diffusion models, while achieving high fidelity, are computationally expensive and inflexible for extrapolation tasks. Traditional autoregressive models, though efficient in streaming generation, suffer from latency and suboptimal visual quality due to the large number of inference steps. InfinityStar addresses these issues by integrating spatial and temporal dependencies within a single discrete architecture, enabling efficient and high-quality generation across text-to-image (T2I), text-to-video (T2V), image-to-video (I2V), and video extrapolation tasks.
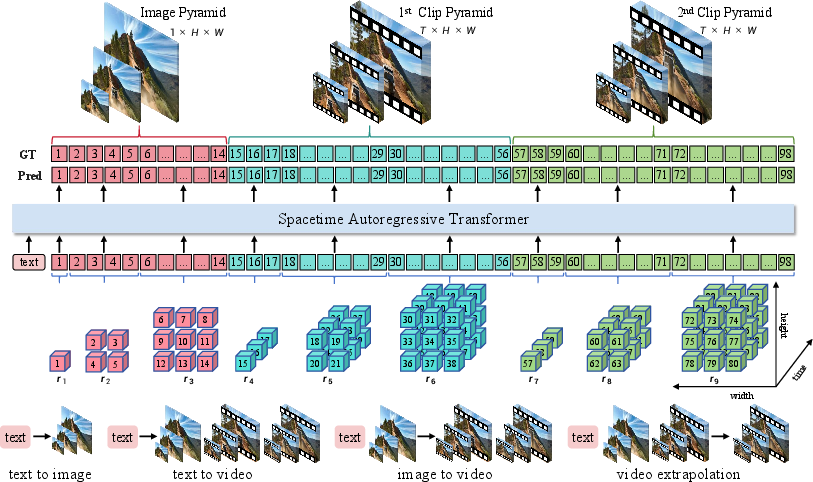
Figure 1: Spacetime pyramid modeling of InfinityStar. Built with an unified autoregressive pipeline, InfinityStar is capable of performing text-to-image, text-to-video, image-to-video, video extrapolation tasks all in one model.
Spacetime Pyramid Modeling
InfinityStar extends the next-scale prediction paradigm from images to videos by introducing a spacetime pyramid. Each video is decomposed into sequential clips, with the first frame encoding static appearance and subsequent clips capturing dynamic motion. Each clip is represented as a 3D volume pyramid, where scales grow spatially but not temporally. This design decouples appearance and motion, facilitating knowledge transfer from T2I to T2V and I2V tasks, and improving the model's ability to fit both static and dynamic aspects of video data.
The autoregressive likelihood for a video is factorized over clips and scales, allowing for theoretically infinite video generation via sequential clip prediction. This unified modeling supports diverse generation tasks without architectural changes.
Discrete Video Tokenizer: Knowledge Inheritance and Stochastic Quantizer Depth
Training discrete video tokenizers is challenging due to computational cost and imbalanced information distribution across scales. InfinityStar introduces two key innovations:
- Knowledge Inheritance: The discrete tokenizer inherits architecture and weights from a pretrained continuous video VAE. A parameter-free quantizer (binary spherical quantization) is inserted between the encoder and decoder, retaining the VAE's knowledge and accelerating convergence.

Figure 2: Influence of pretrained weights on reconstruction and convergence. Loading weights of continuous video tokenizer achieves the best results and faster convergence.
- Stochastic Quantizer Depth (SQD): To address the concentration of information in the last scales, SQD randomly discards some of the last scales during training, forcing the tokenizer to encode more information in early scales. This regularization improves the representation quality of semantic scales and facilitates VAR Transformer training.

Figure 3: The influence of stochastic quantizer depth. SQD significantly improves the reconstruction quality of early scales, which correspond to global semantics.
InfinityStar's transformer incorporates several architectural enhancements:
- Semantic Scale Repetition (SSR): Early semantic scales are repeated multiple times during generation, refining semantic representations and improving structural stability and motion quality, especially in complex scenarios.

Figure 4: Semantic Scale Repetition (SSR) greatly improves structure stability and motion quality.
- Spacetime Sparse Attention: To reduce computational overhead, attention is restricted to the largest scale of the preceding clip, maintaining temporal consistency while enabling efficient long video generation. This approach outperforms full attention in both speed and quality, especially as resolution and duration increase.
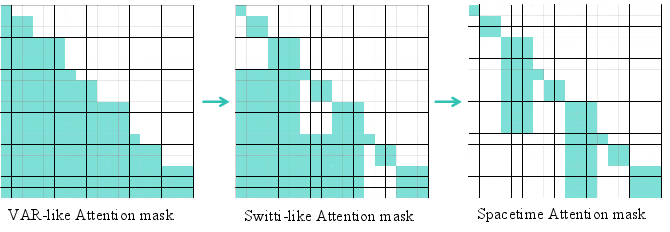
Figure 5: Illustration of three causal attention variants. Spacetime sparse attention achieves efficient context modeling for long videos.
- Spacetime RoPE: Rotary position embeddings are decomposed into scale, time, height, and width components, enhancing positional encoding for complex spatiotemporal structures and supporting extrapolation.

Figure 6: An illustration of Spacetime RoPE. Decomposition into four components enables robust modeling of positional information.
Experimental Results
InfinityStar is trained on large-scale curated datasets, including 130M images and 16M videos, with progressive resolution scaling up to 720p. The model achieves state-of-the-art results among autoregressive video generators, with a VBench score of 83.74, surpassing HunyuanVideo (83.24) and other diffusion-based competitors. Notably, InfinityStar generates 5s 720p videos approximately 10× faster than leading diffusion models, demonstrating a significant efficiency advantage.
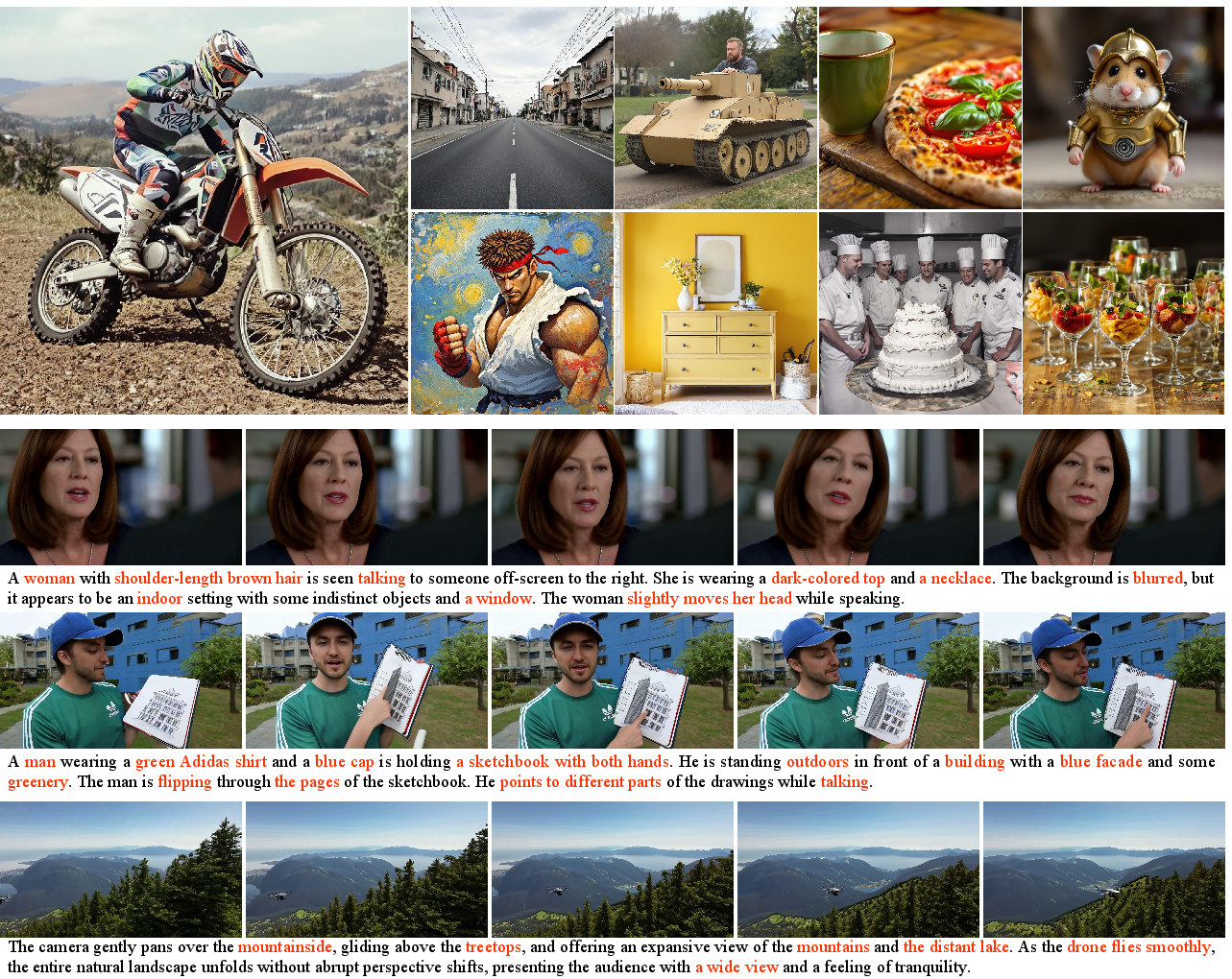
Figure 7: Text to image and text to video examples.
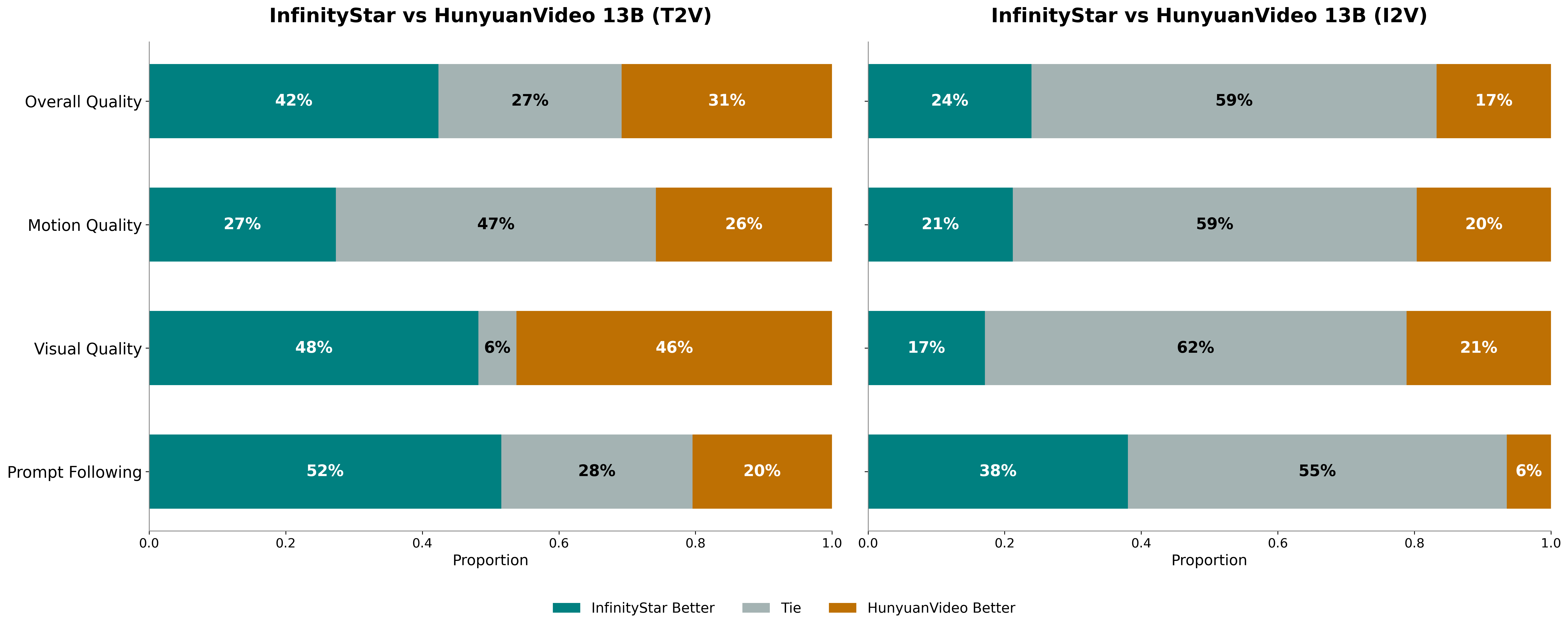
Figure 8: Human evaluation results comparing InfinityStar with HunyuanVideo 13B, showing consistent preference for InfinityStar outputs.
Zero-shot capabilities are demonstrated in both video extrapolation and image-to-video tasks, with strong temporal and semantic coherence observed in generated samples.

Figure 9: Zero-shot video extrapolation examples. InfinityStar can extrapolate videos using a reference video as historical without any fine-tuning.

Figure 10: Zero-shot image to video examples. Synthesized videos exhibit strong temporal and semantic coherence.
Ablation studies confirm the effectiveness of the spacetime pyramid, SSR, SQD, and sparse attention mechanisms. The spacetime pyramid yields richer details and higher motion compared to pseudo-spacetime designs.

Figure 11: Comparison between Pseudo-Spacetime Pyramid and Spacetime Pyramid. Spacetime Pyramid generates videos with richer details and higher motion.
Long Interactive Video Generation: InfinityStar-Interact
InfinityStar is extended to support long interactive video generation via a sliding window approach and novel semantic-detail conditioning. Semantic features are extracted by downsampling detail features from preceding clips, ensuring both semantic and visual consistency across multi-round user interactions. This design compresses condition token length and mitigates drift in long sequences.
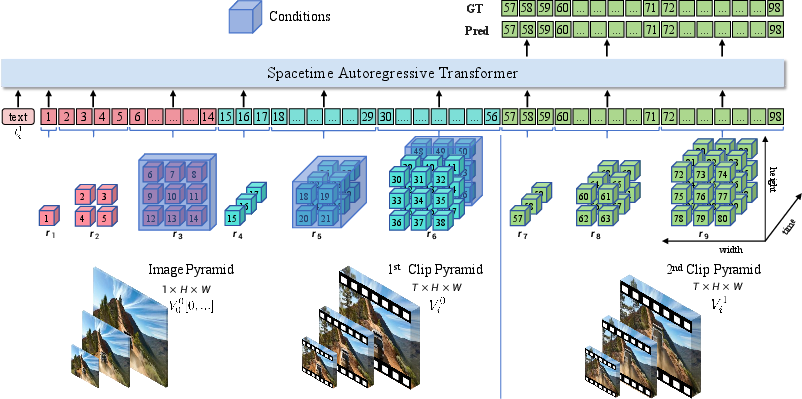
Figure 12: Framework of InfinityStar-Interact. Semantic-Detail conditions enable controlled, consistent interactive video synthesis.
Empirical results show that baseline conditioning on the last few frames is insufficient for semantic consistency, while the proposed semantic-detail conditions maintain identity and continuity over multiple rounds.

Figure 13: Conditioning solely on the last few frames of preceding clip is inadequate for preserving semantic consistency. Proposed conditions deliver better capability.

Figure 14: Interactive Generation Results. InfinityStar-Interact generates consistent videos through multi-round collaboration with users.
Limitations and Future Directions
InfinityStar exhibits a trade-off between image quality and motion fidelity in high-motion scenes, with occasional degradation of fine-grained details. Model scaling is constrained by computational resources, and further optimization of the inference pipeline is needed. In long interactive video generation, cumulative errors can degrade quality over extended interactions, indicating a need for improved error correction and consistency mechanisms.
Conclusion
InfinityStar establishes a unified, efficient, and high-quality autoregressive framework for visual generation, integrating spatial and temporal modeling in a discrete architecture. The model achieves state-of-the-art performance in both image and video synthesis, with substantial efficiency gains over diffusion-based methods. The spacetime pyramid, knowledge inheritance, SQD, SSR, and sparse attention collectively enable scalable, versatile, and interactive visual generation. InfinityStar's design and empirical results suggest promising directions for future research in rapid, long-duration video synthesis and unified multimodal generative modeling.

