Robot-Powered Data Flywheels: Deploying Robots in the Wild for Continual Data Collection and Foundation Model Adaptation
Abstract: Foundation models (FM) have unlocked powerful zero-shot capabilities in vision and language, yet their reliance on internet pretraining data leaves them brittle in unstructured, real-world settings. The messy, real-world data encountered during deployment (e.g. occluded or multilingual text) remains massively underrepresented in existing corpora. Robots, as embodied agents, are uniquely positioned to close this gap: they can act in physical environments to collect large-scale, real-world data that enriches FM training with precisely the examples current models lack. We introduce the Robot-Powered Data Flywheel, a framework that transforms robots from FM consumers into data generators. By deploying robots equipped with FMs in the wild, we enable a virtuous cycle: robots perform useful tasks while collecting real-world data that improves both domain-specific adaptation and domain-adjacent generalization. We instantiate this framework with Scanford, a mobile manipulator deployed in the East Asia Library for 2 weeks. Scanford autonomously scans shelves, identifies books using a vision-LLM (VLM), and leverages the library catalog to label images without human annotation. This deployment both aids librarians and produces a dataset to finetune the underlying VLM, improving performance on the domain-specific in-the-wild library setting and on domain-adjacent multilingual OCR benchmarks. Using data collected from 2103 shelves, Scanford improves VLM performance on book identification from 32.0% to 71.8% and boosts domain-adjacent multilingual OCR from 24.8% to 46.6% (English) and 30.8% to 38.0% (Chinese), while saving an ~18.7 hrs of human time. These results highlight how robot-powered data flywheels can both reduce human effort in real deployments and unlock new pathways for continually adapting FMs to the messiness of reality. More details are at: https://scanford-robot.github.io


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how robots can help improve big AI models by collecting real, messy, everyday data while doing useful work. The authors built a system called the Library Data Flywheel (LDF) and tested it for two weeks in a university library. The robot scanned shelves to help with inventory and, at the same time, gathered photos and labels that made the AI model better at reading hard-to-see, multilingual book titles. The key idea is a “data flywheel”: the robot uses an AI model to do a job, collects new data from the real world, and that data is used to retrain the model—so next time the robot does the job even better.
The main questions the paper asks
- Can robots collect the kind of real-world data that big AI models are missing (like blurry or covered text in multiple languages)?
- If robots gather this data during normal work (like scanning library shelves), can it improve the AI model both for that specific task and for similar tasks elsewhere?
- Does this approach save human time and effort while making the AI stronger over time?
How did they do it?
The robot in the library
- The team used a mobile robot with a robotic arm and a camera. It drove down aisles, raised and lowered its arm to each shelf level, and took photos of the books.
- It also had a laser sensor (LiDAR) to keep itself centered in the aisle. Think of LiDAR like a bat’s echolocation but with light: it measures distances by sending out laser pulses and reading the reflections.
Understanding the books with an AI model
- The robot used a vision-LLM (VLM). That’s an AI that can look at pictures and read or talk about what it sees. Here, it tried to read book titles and call numbers (the codes that identify books).
- OCR (optical character recognition) is the part that “reads” text from images. This is tough in the real world because text can be small, worn-out, tilted, covered by other books, or in different languages.
- To avoid guessing random book names, they used a trick called retrieval-augmented generation (RAG). Imagine giving the AI a cheat sheet: the library’s catalog for that shelf. The AI then picks labels from that real list of possible books.
Getting good labels without humans
- The robot’s AI made its best guesses about which books were in each photo.
- A curation step then checked those guesses against the library database:
- It compared the strings (titles and call numbers) for similarity (kind of like a smart spell-check and matching).
- It checked if the books were in the right order on the shelf.
- If the guesses looked correct, those image–label pairs were kept. If not, they were thrown out. This made a clean dataset without people having to hand-label everything.
Teaching the model with the new data
- The team fine-tuned (retrained) the vision-LLM using the newly collected, curated photos and labels.
- “Fine-tuning” is like giving the AI extra practice on the exact kind of problems it struggled with before—here, real library shelves with multilingual and messy text.
What did they find?
Here are the key results the team reported:
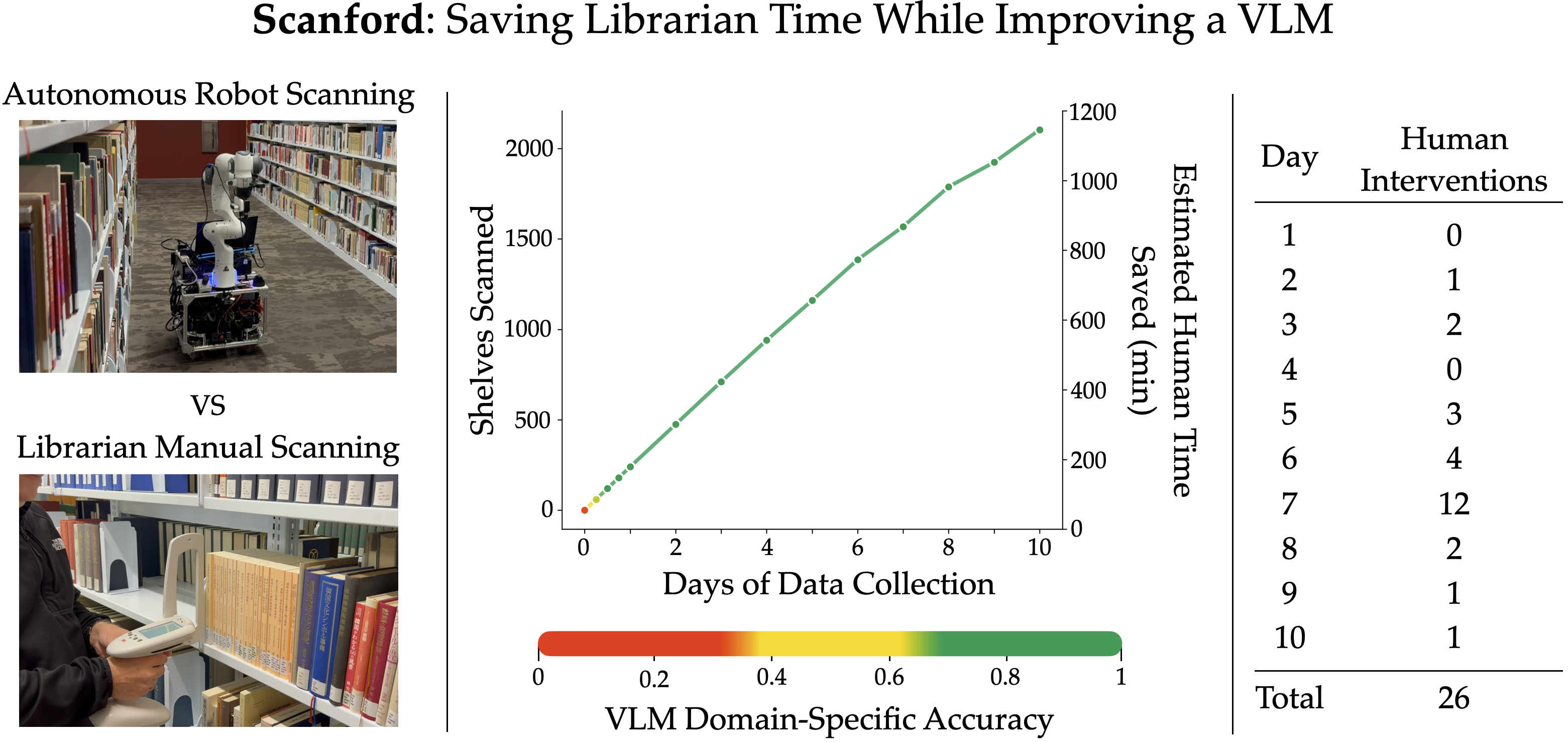
- The robot scanned 2,103 shelves over two weeks, saving an estimated 18.7 hours of human labor.
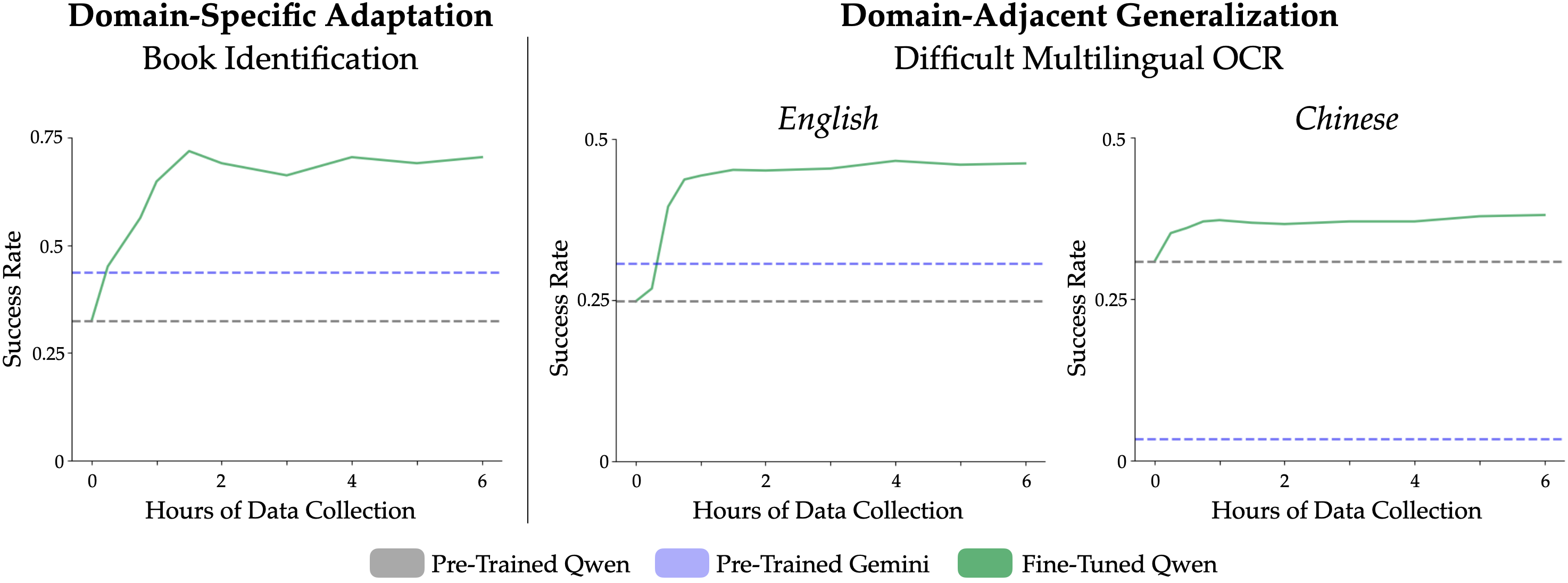
- Using the collected data, the AI’s accuracy on identifying books in the library improved from about 32% to 71.8%.
- The same data also helped the AI read hard text outside the library task (domain-adjacent OCR):
- English OCR accuracy improved from 24.8% to 46.6%.
- Chinese OCR accuracy improved from 30.8% to 38.0%.
- The deployment was smooth: only 26 human interventions were needed over 10 days, each under 5 minutes (mainly to re-center the robot in the aisle).
Why is this important? It shows that real-world data collected by robots can quickly and meaningfully boost AI performance on both the specific job (library inventory) and related skills (reading tough text in images).
Why it matters
- Real-world environments are messy and often underrepresented in the clean, internet data used to train big AI models. That’s why AI can stumble on things like faded labels, small fonts, occlusions, or non-English text.
- Robots can fill this gap by gathering exactly the “hard” examples AI needs to improve.
- The “data flywheel” creates a loop: 1) Robot does a useful task using an AI model. 2) Robot collects real-world data while working. 3) Data is used to fine-tune the model. 4) The next time the robot works, it performs better—and gathers even better data.
- This approach reduces human workload and makes AI more robust in the real world.
Big picture impact
- Libraries are just one example. The same idea could help in grocery stores (reading occluded packaging), hospitals (reading handwritten notes or labels), and warehouses (identifying worn barcodes or labels).
- Over time, robot-powered data flywheels could help build stronger, more reliable AI that’s trained on what actually happens “in the wild,” not just clean internet content.
- While the system isn’t perfect yet and still needs occasional help, it points toward a future where robots steadily improve the AI they rely on—making themselves more capable and useful with each deployment.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains uncertain, missing, or unexplored in the paper, phrased as actionable items for future research.
- External validity beyond one site: Evaluate whether the flywheel transfers to other libraries and non-library environments (e.g., retail, healthcare) with different shelf geometries, lighting, and signage conventions.
- Language coverage gaps: Measure performance on Japanese and Korean (explicitly present in the deployment setting) and other scripts (e.g., Arabic, Devanagari), not just English and Chinese.
- Task-level outcomes vs. perception metrics: Quantify end-to-end inventory accuracy (e.g., precision/recall for mis-shelved, missing, or duplicate items), not only per-image recognition accuracy.
- Small and potentially unrepresentative test set: Expand the held-out human-labeled evaluation beyond 71 images/10 shelves; report confidence intervals and statistical significance.
- Catastrophic forgetting and broader capability retention: Assess whether fine-tuning for OCR/book identification degrades performance on other VLM abilities (captioning, VQA, reasoning) via standard multi-task suites.
- True iterative “flywheel” validation: Demonstrate multiple full deploy–curate–adapt cycles in situ, showing on-robot improvements across iterations (not only one or few posthoc fine-tunes).
- Self-training error amplification: Quantify how using model predictions to generate training labels (even with curation) affects error propagation across iterations; provide audits of label noise before/after curation.
- Curation bias and thresholds: Analyze how string-similarity thresholds and ordering checks skew the dataset toward “easy” cases; perform ablations on thresholds and matching strategies, and report false accept/reject rates.
- Catalog quality dependence: Measure library catalog inaccuracies (checked-out items, offsite storage, mis-entries) and their impact on curation precision/recall and downstream model performance.
- RAG design ablations: Study the effect of candidate set size, retrieval precision/recall, and prompt formatting on labeling accuracy, latency, and data yield.
- Active data collection policies: Explore uncertainty- or failure-driven view planning (e.g., re-scans, pose/lighting changes) to maximize informative samples and reduce occlusions, blur, and glare.
- Plateau analysis: Investigate why performance saturates after ~1.5 hours (~1,352 images); characterize what additional data diversity (angles, lighting, typography, damage modes) breaks the plateau.
- Cross-model generality: Repeat adaptation with other open VLMs (e.g., LLaVA, IDEFICS) and OCR-specific models (e.g., TrOCR, PaddleOCR) to test whether gains are model-agnostic and to establish stronger baselines.
- Comparison to domain-specific OCR pipelines: Benchmark against engineered OCR stacks (detection + recognition pipelines) tuned for multilingual text, including vertical and curved scripts.
- Sequence-level evaluation: Specify and evaluate sequence-level metrics for multi-book images (e.g., ordered-list accuracy, edit distance across the full shelf segment) rather than single-item accuracy alone.
- Negative transfer risks: Check if OCR fine-tuning harms multilingual generalization to unseen fonts/layouts or to non-text perception tasks; include OOD stress tests.
- Real-time/on-robot adaptation feasibility: Assess compute, thermal, and energy constraints for on-robot fine-tuning or lightweight parameter-efficient updates vs. offline training.
- Data governance and privacy: Address policies for capturing patrons/background content, PII suppression, and secure storage/sharing; document compliance and redaction pipelines.
- Safety and human–robot interaction: Quantify safe navigation near patrons, collision risk in narrow aisles, and response to dynamic obstacles; report near-miss incidents and mitigation strategies.
- Operational cost-benefit: Provide a full accounting of operator time (setup, supervision, interventions), compute cost for training, amortized hardware cost, and compare to alternatives (e.g., RFID, handheld scanners).
- Intervention root-cause analysis: Systematically categorize the 26 interventions (e.g., drift sources, short-shelf geometry) and evaluate how algorithmic fixes (better SLAM, sensor fusion) reduce them.
- Localization robustness: Compare the heuristic LiDAR plane-fitting approach against modern aisle-aware SLAM, visual–inertial fusion, and learning-based localization under repetitive geometry.
- Lighting and environmental variability: Quantify performance under different times of day, glare, reflections (glass covers), and seasonal changes in ambient light; propose adaptive exposure/flash strategies.
- Handling extreme edge cases: Evaluate books with missing/handwritten labels, spine text on wraparound covers, vertical/curved/stylized typography, and mixed-language titles/call numbers.
- Generalization without structured catalogs: Test the approach where no reliable database exists; study weak supervision via noisy web metadata, self-consistency checks, or cross-view constraints.
- Label granularity and ambiguity: Disentangle title recognition vs. call-number parsing performance; report separate metrics and error breakdowns (OCR vs. ordering vs. association errors).
- Data and code release: Clarify public release plans for the curated dataset, prompts, curation code, and hyperparameters to enable replication and benchmarking.
- Prompting and pre/post-processing transparency: Document exact VLM prompts, tokenization, image pre-processing (cropping/resizing), and post-processing used in both labeling and evaluation.
- Evaluation fairness for OCR baselines: Ensure standard OCR protocols (e.g., case sensitivity, punctuation handling, normalization of CJK variants) are applied consistently; report character-level vs. word-level scores.
- Continual learning strategy: Compare fine-tuning-from-base each iteration vs. incremental updates (LoRA/adapters); study forgetting, stability–plasticity trade-offs, and data replay.
- Data selection strategies: Explore curriculum learning, diversity-aware sampling, and de-duplication to optimize limited training budgets and avoid over-representation of near-duplicate frames.
- Flywheel objectives and stopping criteria: Define principled criteria (e.g., marginal utility of new data, target confidence thresholds) to decide when to stop collecting or shift to new domains.
- Impact on domain-adjacent tasks beyond OCR: Evaluate benefits to other perception tasks encountered in libraries (symbol/icon reading, layout understanding, barcode/QR decoding).
- Human factors and workflow integration: Study librarian trust, error tolerance, UI for reviewing discrepancies, and how robot outputs integrate with existing catalog systems and policies.
- Long-horizon autonomy and maintenance: Report battery life, docking reliability, thermal throttling, and wear-and-tear over months; quantify degradation and required maintenance schedules.
- Ethical considerations of feedback loops: Analyze risks of reinforcing catalog biases (e.g., underrepresented languages/scripts) via curation rules that preferentially accept “typical” items.
Practical Applications
Practical, Real-World Applications of Robot-Powered Data Flywheels (RPDF) and the Library Data Flywheel (LDF)
The paper demonstrates a closed-loop framework where robots deployed in the wild both perform useful work and collect domain-representative data to continually adapt foundation models. Below are actionable applications stemming from the paper’s findings, methods, and innovations, organized by deployment readiness.
Immediate Applications
- Library shelf inventory automation (Education; Libraries)
- Deploy LDF-style mobile manipulators to scan shelves, identify titles/call numbers using VLMs, and generate “shelf-read” discrepancy reports that librarians can act on today. Integrate with ILS (e.g., Alma/Sierra) via retrieval-augmented prompts and string similarity/order validation.
- Potential tools/products/workflows: “ShelfScan-LDF” turnkey solution; ROS nodes for aisle centering and vertical scan routines; RAG labeler tied to catalog; weekly fine-tune pipeline; report generator for missing/mis-shelved books.
- Dependencies/assumptions: Aisle widths ≥ 36 inches (ADA), reliable catalog metadata, basic staff training for occasional interventions, privacy signage for patrons, power/network availability, institutional buy-in.
- Multilingual OCR enhancement service for degraded text (Software; Archives; Government records; Education)
- Fine-tune open VLMs (e.g., Qwen2.5-VL) using on-site, messy text imagery to boost OCR for multilingual, low-resolution, occluded, curved, or vertical text scenarios in libraries, archives, and digitization projects.
- Potential tools/products/workflows: “OCR Booster” pipeline; domain-specific data capture scripts; curated evaluation suites; weekly adaptation schedule.
- Dependencies/assumptions: Rights to capture and use data, GPU access (on-prem/cloud), legal/licensing compliance for model finetuning, basic data curation standards.
- Retrieval-augmented auto-labeling for vision datasets (Retail; Warehousing; Manufacturing; Education)
- Generalize the paper’s RAG + string-similarity + local ordering checks to auto-label images using structured domain databases (SKU catalogs, WMS, part registries, library catalogs).
- Potential tools/products/workflows: “RAG Labeler” library; configurable string similarity (e.g., Ratcliff/Metzener); ordering verification modules; dataset acceptance thresholds.
- Dependencies/assumptions: Access to accurate, structured domain databases; stable ordering convention; tolerance for semi-automatic label acceptance (discarding low-confidence images).
- ROS LiDAR aisle-centering and drift correction for narrow, repetitive environments (Robotics; Retail; Warehousing)
- Apply the paper’s plane-fitting heuristic to maintain robot alignment in visually homogeneous aisles where SLAM struggles.
- Potential tools/products/workflows: “Aisle-Centering” ROS node for Unitree L2 or similar; calibration procedures; monitoring UI.
- Dependencies/assumptions: LiDAR availability, consistent shelf geometry, reflective surfaces within sensor specs, minimal dynamic obstacles.
- Rapid data-to-finetune MLOps loop for embodied AI (Software; Robotics)
- Stand up an end-to-end pipeline that ingests deployment data, curates labels automatically, fine-tunes VLMs, and redeploys within days. Use plateau-aware scheduling (e.g., stop after ~1.5h of useful data if gains saturate).
- Potential tools/products/workflows: Airflow/Prefect orchestration; DVC/W&B for data/model tracking; “Flywheel Controller” with auto-curation gates; rollback safeguards.
- Dependencies/assumptions: Reliable data ingestion, compute availability, versioned catalogs/prompts, monitoring for overfitting/drift.
- Patron-facing assistance in libraries (Education; Public services)
- Provide cart-mounted cameras or kiosks that capture shelf segments and return probable matches from the catalog, aiding book discovery without full automation of navigation/manipulation.
- Potential tools/products/workflows: “Find-My-Book” kiosk; shelf snapshot search; RAG prompt templates; multilingual UI.
- Dependencies/assumptions: Privacy considerations, signage and opt-out mechanisms, smooth integration with existing catalog systems.
- Maintenance and label quality auditing (Education; Facilities)
- Use scanned images to flag damaged, faded, or occluded labels and trigger relabeling workflows that improve future OCR and patron usability.
- Potential tools/products/workflows: Label-quality scoring; auto-generated maintenance tickets; bulk print queues for replacement labels.
- Dependencies/assumptions: Thresholds for label degradation, staff processes for repairs/relabeling, alignment with catalog updates.
- Home pantry and small-business inventory scanning (Daily life; SMB Retail)
- Adapt the LDF workflow to consumer-grade devices (robot vacuums with cameras or smartphones) to maintain household or small shop inventory using a user-supplied item list (RAG candidates).
- Potential tools/products/workflows: “PantryScan” mobile app; home SKU list; lightweight on-device OCR fine-tuning; weekly scan routines.
- Dependencies/assumptions: Adequate lighting and image quality, user consent and data ownership, simplified curation rules for non-expert use.
- Policy pilots in public libraries (Policy; Public sector)
- Launch short-term pilots to measure labor savings, accuracy improvements, and community impact; set governance for data retention, signage, and accessibility; align with ADA and public procurement rules.
- Potential tools/products/workflows: Pilot charters; privacy impact assessments; ROI dashboards combining hours saved and model-quality metrics; stakeholder engagement plans.
- Dependencies/assumptions: Institutional approvals, union/worker council input, ethical review, sustainability of funding.
Long-Term Applications
- Cross-institution robotic data flywheel consortium (Academia; Public sector; Software)
- Build a federated network of robots in libraries, retailers, hospitals, and archives to continuously collect underrepresented, messy data that augments pretraining mixtures for robust, multilingual, real-world perception.
- Potential tools/products/workflows: Federated learning infrastructure; standardized schemas; shared benchmarks; shared pretraining corpora; governance boards.
- Dependencies/assumptions: Legal/data-sharing frameworks, interoperable standards, funding, cross-institution trust and audits.
- Hospital medication and expiry verification robots (Healthcare)
- Deploy mobile manipulators that read multilingual labels, dosage instructions, handwritten notes, and expiry dates across pharmacies and wards; surface discrepancies to staff.
- Potential tools/products/workflows: “MedLabel Audit” system; EMR integration; safety-grade OCR/VLM; alert triage workflows.
- Dependencies/assumptions: HIPAA compliance, clinical safety thresholds, extremely low false negatives/positives, human-in-the-loop validation.
- Grocery/retail shelf auditing and planogram compliance (Retail)
- Robots that read price tags, promotions, shelf labels, and SKU identifiers even when occluded or misaligned; report out-of-stock/misplacements.
- Potential tools/products/workflows: “RetailFlywheel” platform; planogram diff tools; store operations dashboards; nightly fine-tunes.
- Dependencies/assumptions: Store access during off-hours, robustness to crowding and dynamic layouts, coordination with staff and unions.
- Industrial inspection: meters, gauges, and safety signage in harsh environments (Energy; Manufacturing; Utilities)
- Use ruggedized robots to read analog/digital gauges, multilingual safety signs, and maintenance logs in low-light/occluded conditions to improve preventive maintenance schedules.
- Potential tools/products/workflows: “OCR-Inspector” with intrinsic calibration for gauge reading; anomaly detection; integration with CMMS.
- Dependencies/assumptions: Hazard certifications (ATEX/IECEx), reliability under dust/heat/vibration, secure data pipelines, site-specific training.
- VLAs that learn manipulation and perception jointly from in-the-wild data (Robotics; Software)
- Extend the flywheel to vision-language-action models so robots not only read labels but also learn to grasp, sort, and re-shelve items, reducing task-specific engineering.
- Potential tools/products/workflows: VLA fine-tuning loops; embodied datasets; policy evaluation suites; safety shields for physical interaction.
- Dependencies/assumptions: Larger-scale embodied data, safe exploration/learning, robust sim-to-real or in-situ learning, safety certification.
- City-scale asset digitization (Policy; Municipal services; Transportation)
- Municipal robots/carts that read street signs, parking plaques, utility markers, and public facility notices, improving asset inventories and compliance monitoring.
- Potential tools/products/workflows: “CityScan” programs; open datasets; periodic flywheels to keep assets current; multilingual public signage maps.
- Dependencies/assumptions: Public consent and transparency, data privacy protections, budget allocations, adherence to local regulations.
- Assistive home robots for elder care and accessibility (Healthcare; Daily life)
- Robust reading of medication bottles, food labels, instructions, and appliance indicators in cluttered homes; paired with reminders and guidance.
- Potential tools/products/workflows: “HomeRead” assistant; multimodal reminders; caregiver dashboards; safety guardrails.
- Dependencies/assumptions: Cost, reliability, human acceptance, privacy-by-design, clinical oversight where applicable.
- Pretraining mixture augmentation with embodied hard examples (Academia; Software)
- Systematically incorporate flywheel-collected, low-quality/occluded/multilingual text data into next-gen VLM/VLA pretraining to improve real-world robustness across languages and settings.
- Potential tools/products/workflows: Data dedup/cleaning pipelines; compute-optimal mixture design; legal review for public release; evaluation on challenging OCR subsets.
- Dependencies/assumptions: Scalable storage/compute, rigorous data governance, alignment with model licensing, community benchmarks.
- Standards and regulatory guidance for robotic data collection (Policy)
- Create norms around on-premises robotic data collection: consent notices, retention limits, risk assessments, accessibility and safety requirements, and language coverage fairness.
- Potential tools/products/workflows: Sector-specific standards; audit templates; compliance attestations aligned with AI regulations (e.g., EU AI Act).
- Dependencies/assumptions: Multi-stakeholder collaboration, regulatory harmonization, enforceability, clear liability frameworks.
- Edge/on-device adaptation for faster local improvement (Robotics; Software)
- On-robot fine-tuning within power/thermal constraints to capture local domain shifts (lighting, signage changes) without cloud dependency; ephemeral updates that roll back if performance degrades.
- Potential tools/products/workflows: Lightweight training stacks (bfloat16, LoRA/PEFT), thermal-aware schedulers, differential privacy for sensitive environments.
- Dependencies/assumptions: Sufficient edge compute, robust update verification, battery impact management, secure model lifecycle.
Each application relies on the paper’s demonstrated loop—deploy robots to do useful work, auto-curate realistic data with domain knowledge, and continually fine-tune foundation models—yielding immediate utility and compounding improvements in robustness and generalization.
Glossary
- AdamW optimizer: A variant of the Adam optimization algorithm that decouples weight decay from gradient-based parameter updates to improve training stability and generalization. "Fine-tuning is performed using the AdamW optimizer with a learning rate of ."
- bfloat16: A 16-bit floating-point format with a larger exponent range than FP16, enabling more stable mixed-precision training on modern accelerators. "Mixed-precision training with bfloat16 is employed, along with weight decay of 0.01 and a cosine learning rate scheduler with a 3\% warmup ratio."
- cosine learning rate scheduler: A schedule that reduces the learning rate following a cosine curve, often improving convergence and generalization. "a cosine learning rate scheduler with a 3\% warmup ratio."
- domain-adjacent: Refers to tasks or settings closely related to, but not identical with, the primary deployment domain; improvements can transfer across these nearby domains. "domain-adjacent multilingual OCR"
- downstream adaptation: Post-pretraining tuning or conditioning of a foundation model for specific tasks or domains to improve performance. "these models can substantially benefit from downstream adaptation"
- fine-tuning: Continuing training of a pretrained model on a task-specific dataset to adapt it to new domains or objectives. "We fine-tune the pretrained model for 5 epochs on each dataset using a single Nvidia H200 GPU"
- foundation model: A large model trained on broad data (often internet-scale) that can be adapted to many tasks through prompting or fine-tuning. "Foundation models have unlocked powerful zero-shot capabilities in vision and language"
- gradient accumulation: Technique that accumulates gradients over multiple mini-batches before updating weights to simulate a larger effective batch size. "We use a per-device batch size of 4 with gradient accumulation of 4 steps, resulting in an effective batch size of 16."
- in-context learning: Adapting model behavior at inference time using examples or instructions in the prompt, without updating weights. "Such adaptation, often achieved through in-context learning or task-specific finetuning"
- LiDAR: A sensor that measures distances using laser pulses to produce 3D spatial data for navigation and mapping. "a base-mounted Unitree L2 LiDAR for navigation and localization"
- mobile manipulator: A robot combining a mobile base with a robotic arm to perform tasks requiring both mobility and manipulation. "LDF uses a mobile manipulator to collect pictures of bookshelves"
- odometry: Estimation of a robot’s position and orientation based on motion sensors (e.g., wheel encoders), which can drift over time. "In practice, odometry alone is unreliable due to wheel drift."
- optical character recognition (OCR): Automated extraction of text from images, enabling reading of signs, labels, and documents. "from optical character recognition (OCR) to image captioning"
- point cloud: A set of 3D points representing the geometry of a scene, typically produced by depth sensors like LiDAR. "To address this, we leverage raw LiDAR point cloud data for heuristic drift correction."
- reset-free reinforcement learning: RL approach where the environment does not require manual resets between episodes, enabling scalable data collection. "reset-free reinforcement learning"
- retrieval-augmented generation (RAG): A method that retrieves relevant external information and conditions a generative model on it to improve accuracy. "a retrieval-augmented generation (RAG)-based approach"
- RGB-D camera: A camera that captures both color (RGB) and depth (D) information, useful for perception and manipulation. "a wrist-mounted Intel RealSense D435 RGB-D camera for capturing shelf images"
- self-supervised learning: Learning from the structure of unlabeled data by creating auxiliary tasks, reducing reliance on manual labels. "and self-supervised learning"
- Simultaneous Localization and Mapping (SLAM): Algorithms that let a robot build a map of an unknown environment while estimating its own pose within it. "Traditional SLAM methods fail in the narrow, visually homogeneous environment of book aisles"
- vision-language-action model (VLA): A model that integrates visual, linguistic, and action modalities to enable embodied reasoning and control. "vision-language-action models (VLAs)"
- vision-LLM (VLM): A model that jointly processes images and text to perform tasks like captioning, VQA, and OCR. "uses a vision-LLM (VLM) to identify the books"
- warmup ratio: The fraction of training steps used to gradually increase the learning rate from zero to its target value. "a cosine learning rate scheduler with a 3\% warmup ratio."
- weight decay: A regularization technique that penalizes large weights to reduce overfitting during training. "weight decay of 0.01"
- zero-shot: Performing a task without task-specific training by leveraging generalization from pretraining. "zero-shot capabilities"
Collections
Sign up for free to add this paper to one or more collections.

