- The paper demonstrates the integration of static program analysis with LLM-driven semantic reasoning to automatically detect AI features in Android apps.
- It reports high precision (98.05%) and recall (93.31%), proving the framework outperforms traditional rule-based approaches.
- It provides practical AI service summarization to enhance code auditing and regulatory compliance in mobile software ecosystems.
LLMAID: Semantics-Driven Discovery of AI Services in Android Apps Using LLMs
Introduction
The rapid proliferation of AI capabilities within mobile software applications has escalated both user and regulator demand for actionable transparency regarding AI service presence and characterization. Existing identification approaches—largely manual and rule-driven—exhibit notable scalability, granularity, and generalizability limitations. The paper "LLMAID: Identifying AI Capabilities in Android Apps with LLMs" (2511.19059) formulates a semantics-driven framework, LLMAID, that leverages LLMs to automate fine-grained detection and functional summarization of AI-related features in Android applications. Notably, LLMAID integrates static program analysis with LLM-powered interpretation, optimizing discovery and reporting of AI capabilities across heterogeneous software artifacts.
Framework Architecture and Workflow
LLMAID is operationalized through a multi-stage pipeline, combining static code analysis and LLM semantic reasoning to yield high-fidelity identification and summarization of app-level AI services. The critical stages include:
- Candidate Extraction: Systematic extraction of potentially AI-related components (packages, APIs, model files, HTTP requests) from decompiled APKs using Soot and ancillary binary analysis tools.
- Knowledge Base Interaction: Dual knowledge base caching and filtering to eliminate noise and accelerate inference, operating in tandem with rule-based broad exclusions and manually curated AI/non-AI caches.
- AI Capability Analysis and Detection: Prompted LLM reasoning over implementation components to distinguish AI functions, employing chain-of-thought style analysis followed by classification.
- AI Service Summarization: Prompted synthesis of functional AI summaries targeted to developers, auditors, and regulators.
The workflow is model-agnostic and accommodates recent commercial and open-source LLMs.
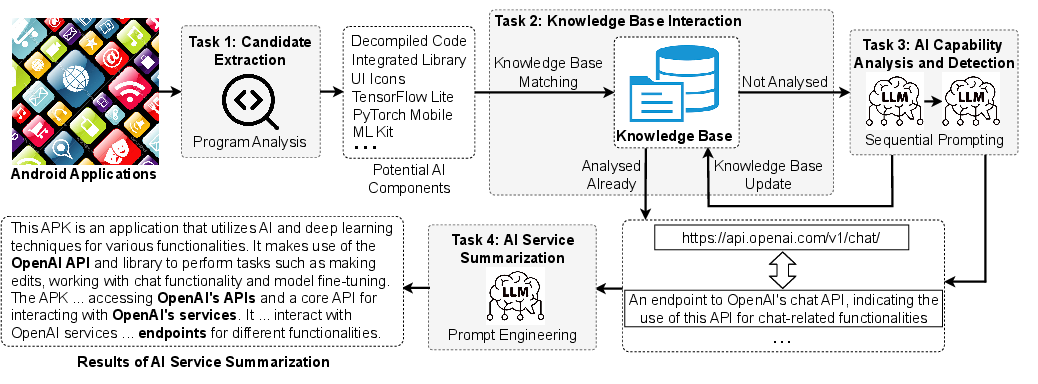
Figure 1: Overview of LLMAID's static analysis and LLM-based semantic reasoning workflow for AI service discovery in Android apps.
Experimental Evaluation and Numerical Results
Detection Reliability
Validation over a stratified sample of previously identified AI apps yields LLMAID precision and recall rates of 98.05% and 93.31%, respectively. The inter-annotator agreement (Cohen’s kappa = 0.82) corroborates robust human-LM consensus on component identification. At the app level, LLMAID achieves a 99.0% accuracy rate for AI app identification, missing only applications lacking semantically clear AI evidence in code artifacts.
Comparative Analysis with Rule-Based Approaches
On a dataset of 3,819 recent Android apps, LLMAID identifies 1,366 AI apps, representing a 242% increase over the SOTA AI Discriminator tool’s detection count. Manual validation attributes missed cases in rule-based approaches to their inability to process implementation-level service invocation, particularly for cloud AI via native or indirect API usage.
Summarization Utility
A user study involving expert developers demonstrates that LLMAID-generated AI service reports systematically outperform native store descriptions. Ratings on accuracy, completeness, and consistency are, on average, over two points higher (e.g., accuracy mean: 8.67 vs 6.35), establishing LLMAID’s report generation as preferable for code auditing and developer insight.

Figure 2: Example of an app's original description and its corresponding machine-generated AI service summary produced by LLMAID.
Empirical Characteristics of AI Service Distribution
Analysis of 11,081 fine-grained AI components across determined apps indicates that computer vision dominates (54.80%), followed by data analysis (26.85%) and NLP (13.38%). At the task level, object detection (25.19%), data processing (23.17%), and text/face recognition dominate distributions. Most AI artifacts are concentrated in package-level APIs, with fewer on-device models and cloud-requested services.
Methodological Innovations
LLMAID’s contributions derive from the fusion of rigorous static analysis (APK disassembly, deobfuscation, binary introspection) with semantic interpretation capabilities of LLMs. The use of few-shot prompting, knowledge base caching, and batch component analysis collectively mitigate issues of output inconsistency, hallucination, and rate-limiting inherent in commercial LLM APIs. The framework accommodates both local/on-device and cloud-based AI integration scenarios, broadening applicability for future enhancements.
Implications and Prospects
Theoretical Implications
LLMAID substantiates the feasibility of using LLMs for semantic code audit, AI service transparency, and static analysis augmentation in large-scale software repositories. The observed performance supports wider adoption of LLM-powered semantic reasoning for security vulnerability detection, model protection validation, and cross-language summary generation. LLMAID's adaptability to new LLMs and its open-world discovery model position it for integration with prompt engineering advances and automated compliance toolchains.
Practical Implications and Future Directions
The increased recall and report informativeness achieved by LLMAID offer immediate utility to developers, regulators, and end-users demanding explainability in mobile AI deployments. Extensions to dynamic analysis, integration with CVE databases for vulnerability discovery, and support for cross-platform frameworks are indicated. Addressing obfuscation and partial code delivery (Android App Bundles) remains a challenge—future work should incorporate dynamic instrumentation and developer dialogues for comprehensive artifact harvest. Augmented reality and advanced multimodal services are expected to comprise rising minor shares as application scenarios expand.
Conclusion
LLMAID establishes a robust and scalable pipeline for programmatic, semantics-driven discovery and summarization of AI services within Android applications. Evidence from both quantitative and qualitative evaluations demonstrates LLMAID’s superiority over rule-based methods in both coverage and interpretability. The methodology’s generality and extensibility invite further research in LLM-assisted artifact audit, vulnerability detection, and multi-lingual semantic summarization, contributing valuable paradigms for reliable and secure AI adoption in mobile software ecosystems.