HunyuanVideo 1.5 Technical Report
Abstract: We present HunyuanVideo 1.5, a lightweight yet powerful open-source video generation model that achieves state-of-the-art visual quality and motion coherence with only 8.3 billion parameters, enabling efficient inference on consumer-grade GPUs. This achievement is built upon several key components, including meticulous data curation, an advanced DiT architecture featuring selective and sliding tile attention (SSTA), enhanced bilingual understanding through glyph-aware text encoding, progressive pre-training and post-training, and an efficient video super-resolution network. Leveraging these designs, we developed a unified framework capable of high-quality text-to-video and image-to-video generation across multiple durations and resolutions. Extensive experiments demonstrate that this compact and proficient model establishes a new state-of-the-art among open-source video generation models. By releasing the code and model weights, we provide the community with a high-performance foundation that lowers the barrier to video creation and research, making advanced video generation accessible to a broader audience. All open-source assets are publicly available at https://github.com/Tencent-Hunyuan/HunyuanVideo-1.5.
First 10 authors:



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces HunyuanVideo 1.5, an open-source AI model that can create high-quality videos from text or from a single image. It’s designed to be powerful but also efficient, so it can run on regular gaming GPUs, not just super expensive servers.
What questions is the paper trying to answer?
The researchers set out to solve a simple problem: can we make a video-making AI that is both really good and doesn’t need huge computers to run?
To do that, they focus on:
- Making the model small enough to run fast, but still produce high-quality videos.
- Ensuring the videos look smooth and consistent from frame to frame.
- Understanding prompts in both English and Chinese, including generating text that appears correctly inside the video (like signs).
- Supporting different tasks: text-to-video and image-to-video.
- Allowing longer, higher-resolution videos without slowing down too much.
How does the model work? (Simple explanations)
Think of the whole system like a movie studio:
- The “Director” is a Diffusion Transformer (DiT). It turns text or an image into a first version of the video by slowly transforming noise into meaningful frames, step by step—like polishing a rough sketch into a finished scene.
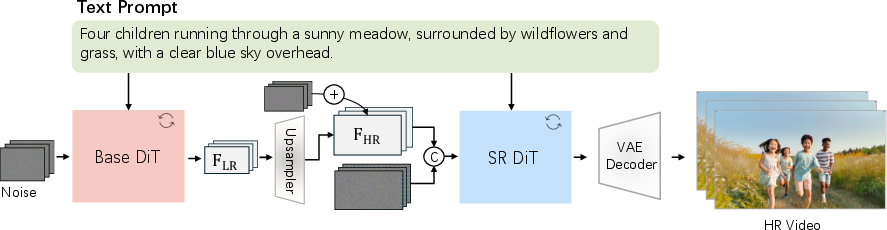
- The “Editor” is a Video Super-Resolution model. It takes the first video (which is lower resolution) and sharpens it up to 1080p, adding crisp details.
- The “Translator” is a set of text encoders that understand prompts. One encoder understands general language and visuals; another specializes in how characters and glyphs look, so text rendered in the video (like Chinese or English signs) is accurate.
- The “Storage Manager” is a 3D VAE (Variational Autoencoder). It compresses videos into smaller pieces, kind of like zipping a file, which makes the model faster and cheaper to run.
- The “Focus System” is SSTA (Selective and Sliding Tile Attention). Instead of the model looking at every single part of every frame all the time, it smartly focuses on the most important areas and nearby regions—like paying attention to the actors and the action, not the empty background. This saves time and memory and speeds up video generation.
They also trained the model in phases, like school:
- First it learns text-to-image (understanding prompts well and drawing great pictures).
- Then it learns text-to-video and image-to-video at increasing resolutions and frame rates (from shorter, smaller clips to longer, bigger ones).
- Finally, they fine-tune it using human feedback and extra training to fix mistakes (like weird motion or artifacts).
What data and training did they use?
They collected a huge amount of data:
- Billions of images for learning strong text-to-image skills.
- Hundreds of millions of short, clean video clips for learning motion and scenes.
- Carefully cleaned and filtered data—removing low-quality clips, watermarks, and boring static scenes.
- Detailed captions that describe not only what’s in a video, but also camera moves (like zooms or pans) and visual style.
They also improved captions using reinforcement learning to reduce “hallucinations” (incorrect details) while keeping descriptions rich and helpful.
What did they find?
Here are the main results, explained simply:
- High visual quality and stable motion: The videos look good and don’t “fall apart” over time.
- Efficient and fast: With the smart attention trick (SSTA) and other optimizations, it generates 10-second 720p videos much faster than standard methods.
- Runs on consumer GPUs: It can generate 720p videos with around 13.6 GB of GPU memory, which fits on an RTX 4090.
- Strong understanding of prompts: It follows instructions well, works in both English and Chinese, and can accurately render text inside the video.
- Competitive performance: Among open-source models, it sets a new standard. It’s also competitive with some closed, commercial systems in several tests.
- Flexible: Works for text-to-video and image-to-video, supports multiple lengths and resolutions, and can be upscaled to 1080p sharply.
Why is this important?
- Accessibility: Because it’s open-source and runs on consumer hardware, more people—students, creators, and researchers—can use and improve it.
- Quality AND efficiency: It proves you don’t need massive, expensive models to make great videos.
- Better control: With strong captioning and camera motion understanding, you can guide the AI more precisely.
- Multilingual support: It helps global users create content in multiple languages and render text correctly in videos.
What could this mean for the future?
This research could:
- Lower the barrier to entry for video creation, making professional-looking videos more accessible to small studios, creators, educators, and indie filmmakers.
- Speed up research in video generation by giving the community a strong, open foundation to build on.
- Inspire more efficient designs that balance speed, quality, and cost.
- Enable new creative tools for storytelling, animation, advertising, and education, especially where precise control and multilingual text are needed.
In short, HunyuanVideo 1.5 shows that smart design, good data, and careful training can make video AI both powerful and practical.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- SSTA hyperparameters and sensitivity: The “parameter-free” claim conflicts with the presence of λ, β, window sizes (WS), tile sizes, and Top‑k in Algorithm 1; the paper does not report how these values are chosen or their sensitivity on quality/speed across resolutions, frame lengths, and heads.
- Sparse attention quality trade-offs: There is no quantitative analysis of how SSTA impacts video quality (e.g., motion coherence, fine details, text rendering) relative to full attention or alternative sparse schemes, especially for long sequences (e.g., 241+ frames).
- Distillation details for sparse attention: The paper states that sparse training is incorporated during the distillation phase but omits the teacher-student setup, loss formulation, and whether distillation introduces artifacts or limits generalization.
- Ablations for I2V conditioning pathways: The dual-path conditioning (VAE latent concatenation vs. SigLip features) lacks ablation studies to quantify their individual and combined contributions to semantic alignment, detail fidelity, and motion stability.
- VAE architecture transparency and evaluation: The causal 3D VAE design (with 16× spatial and 4× temporal compression, 32 channels) is not described architecturally (layers, receptive fields), nor evaluated for rate–distortion, temporal consistency, or reconstruction artifacts versus other 3D VAEs.
- Compression–quality trade-offs in VAE: No systematic study of how varying spatial/temporal compression ratios affect motion blur, temporal flicker, detail loss, and text readability; practical guidance to tune compression is missing.
- Super-resolution model objective and ablations: The latent-space VSR architecture, training objective(s), loss functions, and ablations (e.g., latent vs. pixel SR, different upsample blocks) are not reported; temporal consistency gains are only shown qualitatively.
- SR quantitative metrics: No PSNR/SSIM/LPIPS/VMAF/temporal consistency metrics are provided for VSR; the impact on text legibility and fine textures is not quantitatively evaluated.
- Long-duration and high-FPS generation: Quality and stability beyond 10 seconds and at higher frame rates (e.g., 30/60 fps) are not evaluated; the method’s scalability to longer narratives and faster motion remains unclear.
- Camera movement control: While camera motion is recognized and captioned, there is no evaluation of user-controllable camera moves during generation (interface, consistency, precision) or how reliably the model follows explicit camera directives.
- Multilingual text rendering and evaluation: Despite a “multilingual Glyph-ByT5” encoder, results and metrics are only discussed for Chinese–English; coverage and accuracy for other scripts (Arabic, Devanagari, Cyrillic, etc.), diacritics, and complex ligatures are not tested.
- Instruction-following and text alignment metrics: The paper relies on ratings and GSB but lacks standardized automatic metrics (e.g., CLIP-based alignment, specialized text-rendering metrics) and error taxonomies (e.g., missed entities, wrong attributes, motion misalignment).
- High “Equally Bad” rates without failure analysis: GSB shows substantial “Equally Bad” outcomes; the paper does not categorize failure modes (e.g., motion artifacts, structural drift, text errors), nor propose remedies or diagnostic tools.
- RLHF/reward model specifics and robustness: The VLM-based reward models’ architectures, training data, validation procedures, and bias/sensitivity analyses are missing; the offline DPO stage lacks details on pair construction, preference noise, and generalization across domains.
- Training compute, costs, and reproducibility: The paper omits compute budgets (GPU-days), batch sizes, token counts, wall-clock times, and energy usage across stages; guidance to reproduce the training pipeline is incomplete.
- Progressive training schedules: The “shift scheduling strategies” for flow matching are not specified; there is no ablation showing sensitivity to token length changes, stage transitions, or task ratios (1:6:3) in mixed training.
- Optimizer choice ablation: Muon is claimed to converge faster than AdamW, but there are no video-specific ablations (e.g., motion stability, long-range coherence) or analysis across pre-training and post-training phases; optimizer hyperparameters beyond weight decay are not detailed.
- Safety, content moderation, and ethical data use: The paper does not address dataset licensing, content filtering (e.g., harmful/NSFW/biased material), bias audits, or safeguards; watermark/logo cropping risks and potential data provenance issues remain unexplored.
- Domain-wise performance breakdown: There is no stratified evaluation across key domains (humans, animals, text-heavy scenes, fast camera motion, low light), making it hard to target improvements for specific failure-prone categories.
- Generalization to consumer hardware: While memory figures are reported (13.6 GB peak with offloading for 720p/121 frames), end-to-end latency, throughput, and quality on common single-GPU setups (e.g., RTX 3080/4080/4090) without heavy offloading are not benchmarked.
- Real-time or streaming generation: The pipeline’s feasibility for streaming/online generation (incremental decoding, chunked attention, pipelined SR) is not explored; scheduling strategies for low-latency generation are absent.
- Integration with audio: The model focuses on silent video; synchronized audio generation, alignment, and evaluation are not discussed, limiting end-to-end content creation use cases.
- Open-source completeness: Although code and weights are released, it is unclear whether all components (captioners, reward models, SSTA toolkit, data filters, segmentation pipeline) are fully available and reproducible; missing assets hinder independent validation.
- Controllability beyond prompts: The paper does not investigate fine-grained controls (subject paths, pose, depth, segmentation masks, 3D camera paths), nor provide interfaces/APIs that enable compositional control and repeatability across seeds.
- Evaluation against standardized benchmarks: The method is not compared on common open benchmarks (e.g., UCF-101, Kinetics-derived evaluation sets for generative models), making cross-paper comparisons difficult.
- Effect of CFG distillation: The CFG-distilled inference model is used for speed tests, but the distillation procedure, quality impact versus non-distilled sampling, and interactions with feature caching are not analyzed.
- Robustness to prompt ambiguity and adversarial inputs: There is no study on robustness to underspecified/ambiguous prompts, adversarial phrasing, or conflicting instructions; behavior under edge cases remains unknown.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now using the released code and weights, anchored to specific components and findings in the paper. Each item names relevant sectors, highlights likely tools/workflows, and notes feasibility assumptions or dependencies.
- Content ideation and short-form video production
- Sector: Media/entertainment, marketing/advertising, social platforms, SMBs
- What: Generate 5–10s 720p videos (upscale to 1080p via the VSR module) for teasers, explainer clips, social ads, channel bumpers, or in-app backgrounds using T2V; animate style frames/storyboards using I2V.
- Tools/workflows: “Storyboard-to-animatic” pipeline (I2V with instructional captions), batch generation for A/B testing creatives, plugin-style integration into NLEs (e.g., Premiere Pro via a local or server-hosted CLI wrapper).
- Dependencies/assumptions: Consumer-grade GPU (e.g., RTX 4090 with ~13.6 GB peak using offloading) or access to hosted GPU; current model optimally targets 5–10s, 480–720p base; brand safety and content moderation must be layered on top.
- E-commerce and product marketing videos
- Sector: E-commerce, retail, branding
- What: Create short product spins, lifestyle snippets, and logo/packaging animations; leverage bilingual prompts and glyph-aware text rendering (Glyph-ByT5) to keep on-video text (signage, slogans) legible in Chinese/English.
- Tools/workflows: I2V with reference product images, text overlay baked into generations; automated variant generation to match campaign locales.
- Dependencies/assumptions: Accurate text rendering is strongest for Chinese/English; rights to trademarks/artwork required; add QC for text fidelity and brand compliance.
- Previsualization for film, TV, and game cinematics
- Sector: Media/entertainment, gaming
- What: Rapid animatics from concept art or stills (I2V), controllable camera motion via structured captions and camera-motion annotations; iterate quickly on shot ideas before full production.
- Tools/workflows: “Previz workbench” using I2V + camera-motion descriptors integrated into prompts; VSR for screening-quality 1080p previews.
- Dependencies/assumptions: Motion coherence is strong but not perfect; longer scenes require stitching or batch planning; add pipeline hooks for asset continuity and color management.
- Educational micro-lessons and animated diagrams
- Sector: Education, knowledge platforms
- What: Animate static diagrams or slides (I2V) to create short concept demonstrations and bilingual explainers.
- Tools/workflows: Slide-to-clip automation using the unified model; bilingual prompting for dual-language content.
- Dependencies/assumptions: Human review for factual accuracy; prefer use where motion aids comprehension rather than precise scientific simulation.
- Synthetic dataset creation for perception and vision research
- Sector: Robotics, autonomous systems, computer vision, academia
- What: Generate diverse, labeled short clips using the structured video captioning and camera-movement descriptors to pretrain or augment data for detection, tracking, and action recognition.
- Tools/workflows: “Synthetic video factory” combining T2V/I2V with caption exports; camera-motion control to vary panning/tilting/dolly patterns.
- Dependencies/assumptions: Domain gap vs real-world; require careful validation; add scenario taxonomies and bias audits.
- Video super-resolution and archival enhancement (to 1080p)
- Sector: Media archives, broadcast, post-production, education
- What: Use the cascaded latent-space VSR to upscale lower-res material and improve sharpness/temporal coherence on short clips.
- Tools/workflows: Microservice wrapping the VSR model to batch-upscale 480p/720p content to 1080p; QC tool to surface artifacts.
- Dependencies/assumptions: Best for short clips; re-encoding/licensing constraints for archival content; verify temporal stability on fast motion.
- Bilingual video captioning and indexing at scale
- Sector: Media platforms, search, MAM/DAM, academia
- What: Apply the paper’s structured video captioning pipeline (with RL to reduce hallucinations) for video indexing/search, content discovery, and dataset documentation.
- Tools/workflows: Captioning microservice producing multi-level narratives plus cinematic/aesthetic properties; feed results into search indices and content taxonomies.
- Dependencies/assumptions: High-quality captions depend on the provided RL-hardened models and training data; implement confidence thresholds and human-in-the-loop review for critical archives.
- Efficient attention and inference research baselines
- Sector: Academia, ML tooling, systems research
- What: Adopt SSTA (Selective and Sliding Tile Attention) and the flex_block_attention implementation (ThunderKittens) as baselines for long-context spatiotemporal transformers; replicate speedups (e.g., 1.87× on 10s 720p) and extend to other domains.
- Tools/workflows: Drop-in attention backends (SSTA, SageAttention) for ablations; PyTorch torch.compile for kernel fusion; feature caching strategies during sampling.
- Dependencies/assumptions: Engineering differences across hardware stacks; preserve quality by matching distillation and mask scheduling.
- Faster training of diffusion models with Muon
- Sector: Academia, foundation model labs, startups
- What: Reduce time-to-quality vs AdamW by adopting Muon for diffusion pretraining/post-training; replicate the paper’s convergence improvements.
- Tools/workflows: Swap optimizer in training recipes; track loss and FID/temporal metrics to confirm gains.
- Dependencies/assumptions: Stability tuned via weight decay (0.01 in paper); hyperparameters may need retuning for other datasets/models.
- Cloud/API productization on consumer hardware
- Sector: Software, creative SaaS, developer platforms
- What: Offer T2V/I2V APIs that can be hosted on single 24 GB-class GPUs for 720p 121-frame jobs using offloading and tiling; expose billing per step/clip.
- Tools/workflows: Containerized inference with context parallelism, SSTA toggles, and VSR stage; job queue with quality/speed presets.
- Dependencies/assumptions: Throughput limited by latency per clip; implement rate limiting, caching, and retry logic; content safety filters are required for public endpoints.
- Evaluation and procurement benchmarking
- Sector: Policy, standards bodies, enterprise IT
- What: Apply the paper’s Rating and GSB protocols to benchmark vendor T2V/I2V systems for procurement or safety audits.
- Tools/workflows: Balanced prompt/image testbeds; blinded multi-rater evaluation across text alignment, visual quality, stability, motion.
- Dependencies/assumptions: Requires trained assessors; harmonize rater rubrics; extend with safety and bias criteria.
Long-Term Applications
These rely on further research, scaling, longer durations, or broader ecosystem development. Each item states the sector, potential product/workflow, and major dependencies.
- Longer, higher-fidelity sequences (≥30–60s, 4K)
- Sector: Media/entertainment, broadcast, gaming
- What: End-to-end cinematic scenes with consistent subjects and locations, 4K 24–60 fps.
- Tools/workflows: Extended VAE/VSR cascades and memory-efficient attention; stitching-aware training; color and asset continuity pipelines.
- Dependencies/assumptions: Larger context windows; memory-efficient kernels; more compute and curated long-form training data.
- Real-time or near-real-time video generation
- Sector: Live entertainment, interactive apps, VTubing
- What: Streamed T2V avatars/backgrounds and reactive scenes.
- Tools/workflows: Aggressive sparse attention, distilled samplers (few-step), specialized kernels, and hardware-aware schedulers.
- Dependencies/assumptions: Further latency reductions; quality-preserving distillation to sub-10 steps; tailored hardware (e.g., next-gen GPUs/NPUs).
- Fine-grained, programmatic camera and motion control
- Sector: Film/game tools, virtual production, robotics simulation
- What: Shot planning via explicit pan/tilt/dolly/zoom paths and physically plausible subject motion.
- Tools/workflows: API-level controls informed by the paper’s camera-movement recognition; supervised training with control signals; timeline editors for motion curves.
- Dependencies/assumptions: Additional conditioning channels and supervised data; improved reward models for motion quality.
- Multilingual on-video typography beyond Chinese/English
- Sector: Global marketing, education, localization
- What: Accurate glyph rendering across more scripts (e.g., Arabic, Devanagari, Thai).
- Tools/workflows: Extend Glyph-ByT5 to more languages; script-specific evaluation and datasets.
- Dependencies/assumptions: High-quality multilingual text rendering datasets; typography-specific RL objectives.
- Text-guided video editing and consistency-preserving edits
- Sector: Post-production, creative tooling, consumer apps
- What: Edit existing footage (object/style/motion edits) with temporal consistency constraints.
- Tools/workflows: Edit-instruction conditioning, mask tracking, optical-flow–aware diffusion.
- Dependencies/assumptions: Additional training for edit operations and identity consistency; new safety layers to prevent malicious deep edits.
- Integrated safety, provenance, and compliance features
- Sector: Policy, enterprise, platforms
- What: Standardized provenance (e.g., C2PA), watermarking, and content classification embedded into generation workflows.
- Tools/workflows: Provenance signing post-decoder; watermarking in latent space; audit logs for prompts, seeds, and CFG.
- Dependencies/assumptions: Community consensus on standards; negligible quality impact; regulatory alignment across jurisdictions.
- Simulation-to-real pipelines for robotics and AVs
- Sector: Robotics, autonomous driving, industrial inspection
- What: Scenario generators producing diverse camera motions and edge cases to train policies/perception.
- Tools/workflows: Domain randomization schedulers; curriculum learning with camera/motion controls; feedback loops from real-world failure modes.
- Dependencies/assumptions: Improved physical realism and controllability; validated transfer gains; liability and safety governance.
- Model-as-a-service in low-resource/edge environments
- Sector: Mobile, AR/VR, embedded
- What: On-device or edge inference for short clips and effects.
- Tools/workflows: Quantization/pruning, tiled VAEs, sparse attention, and memory offloading tailored to NPUs/WebGPU.
- Dependencies/assumptions: More aggressive compression without unacceptable quality loss; battery/thermal constraints.
- Cross-domain adoption of SSTA-style attention
- Sector: Software, healthcare imaging, geospatial, speech/video analytics
- What: Apply block-sparse SSTA to long-sequence transformers (e.g., video QA, 3D medical time series, satellite stacks).
- Tools/workflows: Domain-specific block partitioning and importance metrics; ThunderKittens kernels generalized to new modalities.
- Dependencies/assumptions: Careful mask design to preserve task accuracy; domain-tuned redundancy scoring.
- Enterprise creative operating systems
- Sector: Enterprise software, martech
- What: Orchestrate multi-stage creative workflows (brief → T2V drafts → review → I2V refinements → VSR → compliance checks) with human-in-the-loop and RLHF-driven preference alignment.
- Tools/workflows: Prompt libraries, review dashboards, automated GSB/Rating reports, compliance and brand-safety gates.
- Dependencies/assumptions: Preference models tuned to brand/style; integration with DAM/MAM; governance guardrails.
- Personalized video tutors and courseware
- Sector: Education, corporate training
- What: Adaptive, bilingual explainer videos generated per learner profile and assessment results.
- Tools/workflows: LLM planner + T2V/I2V renderer; knowledge grounding; iterative refinement with RL from learner feedback.
- Dependencies/assumptions: Strong guardrails for factuality; content review loops; privacy-preserving data use.
- Broadcast-scale restoration and 4K VSR
- Sector: Media archives, streaming
- What: Multi-stage latent VSR for 4K catalog remastering with temporal stability.
- Tools/workflows: Cascaded VSR training on studio-grade datasets; artifact triage; color-space-aware decoding.
- Dependencies/assumptions: Larger, more diverse high-res training sets; stability under heavy compression artifacts.
Notes on Key Assumptions and Dependencies (cross-cutting)
- Compute and latency: While the model can run on a single RTX 4090 with offloading for 720p/121 frames, many production scenarios will prefer multi-GPU or cloud deployments. Real-time use cases require further optimization (fewer steps, more sparsity, kernel engineering).
- Clip length and resolution: The released pipeline targets 5–10s at 480–720p base with 1080p upscaling; longer or 4K outputs need additional research and compute.
- Text rendering: Glyph-ByT5 currently emphasizes Chinese/English; other scripts require extension and evaluation.
- Data rights and moderation: Any commercial deployment must add content safety filters, copyright/trademark checks, and usage policies. The paper’s data curation pipeline offers a blueprint for quality filtering but does not replace legal/compliance review.
- Reward models and RLHF: Motion and quality improvements depend on reward model coverage and reliability; domain shifts may require re-training or calibration.
- Integration effort: To reach “buttoned-up” workflows (plugins, APIs, dashboards), engineering around the open-source core is required (job orchestration, monitoring, caching, provenance).
Glossary
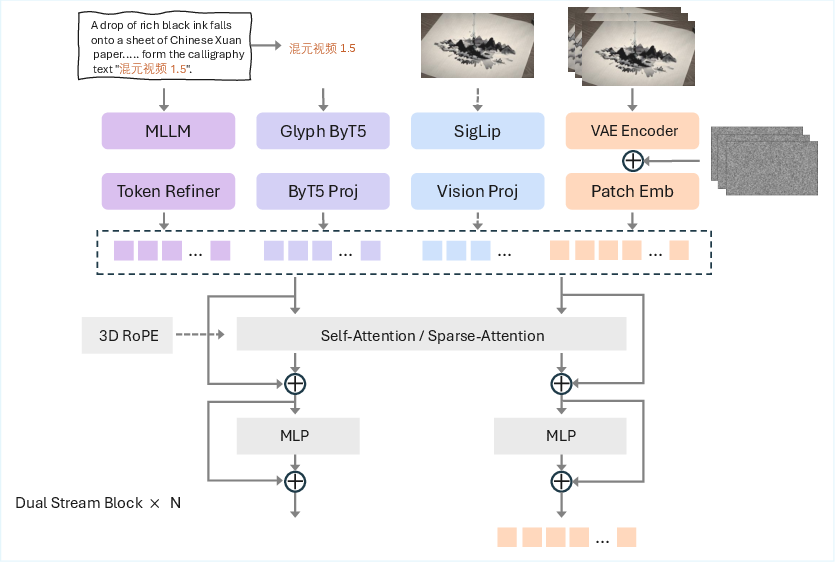
- 3D causal VAE: A variational autoencoder with a causal 3D transformer backbone for joint image-video encoding and strong spatiotemporal compression. "We propose an efficient architecture that integrates an 8.3B-parameter Diffusion Transformer (DiT) with a 3D causal VAE, achieving compression ratios of 16× in spatial dimensions and 4× along the temporal axis."
- 3D VAE: A three-dimensional variational autoencoder used to compress spatiotemporal video data into compact latents. "a high-compression 3D VAE to reduce memory footprint"
- Aesthetic scoring operator: An automated evaluator that scores visual aesthetics to filter low-quality data. "We applied an aesthetic scoring operator based on~\cite{dover} to evaluate the aesthetic quality of the videos, filtering out those with low aesthetic scores."
- Block-Sparse Attention: An attention computation that restricts interactions to selected blocks, reducing complexity for long sequences. "Perform Block-Sparse Attention"
- ByT5: A byte-level text encoder used to improve robustness and text rendering, especially for multilingual glyphs. "combined with ByT5 for dedicated glyph encoding to enhance text generation accuracy in videos."
- Classifier-Free Guidance (CFG): A sampling technique for conditional generative models that trades off fidelity and diversity via guidance scaling. "All speed measurements are conducted on the classifier-free guidance (CFG) distilled model using 8 NVIDIA H800 GPUs with context parallelism enabled across all devices."
- Context parallelism: A distributed inference/training strategy that splits sequence context across devices to scale attention. "with context parallelism enabled across all devices."
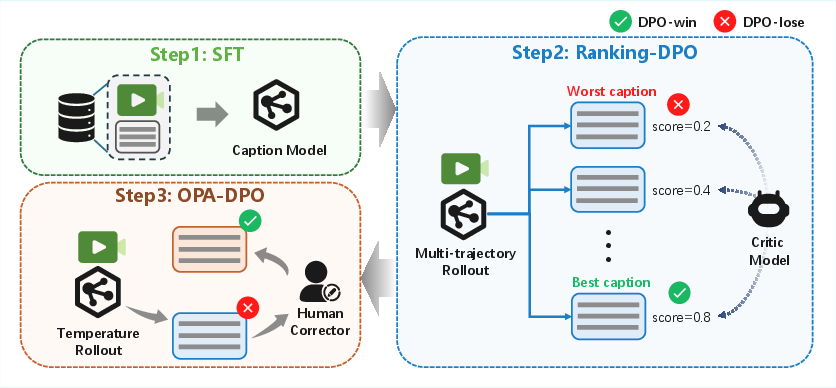
- Continuing Training (CT): A post-pretraining stage where the model is further trained on curated data to refine capabilities. "This multi-stage process consists of continuing training (CT), supervised fine-tuning (SFT), and human feedback alignment (RLHF), applied separately for text-to-video (T2V) and image-to-video (I2V) tasks."
- Direct Preference Optimization (DPO): A preference-based optimization method that aligns model outputs with ranked human or synthetic comparisons without explicit rewards. "Applying Direct Preference Optimization (DPO)~\cite{wallace2024diffusion} to this high-quality paired data significantly reduces motion artifacts and establishes a superior policy starting point."
- Diffusion Transformer (DiT): A transformer-based diffusion model architecture for image/video generation. "we employ a diffusion transformer (DiT) model with 8.3 billion parameters, designed for multi-task learning."
- Distillation: A training transfer process that compresses or adapts a model or mechanism (e.g., sparse attention) while preserving output quality. "sparse training is incorporated during the distillation phase, which more effectively preserves output quality while maintaining high computational efficiency."
- Feature caching: Reusing intermediate activations during sampling to avoid redundant computation. "a feature caching mechanism is implemented during diffusion sampling to reuse cached intermediate features for non-critical steps, reducing redundant computations."
- FlashAttention-3: A highly optimized attention kernel that reduces memory traffic and accelerates attention. "achieving an end-to-end speedup of 1.87 × in 10-second 720p video synthesis compared to FlashAttention-3 \cite{shah2024flashattention3fastaccurateattention}."
- flex_block_attention: An engineered block-sparse attention kernel used to accelerate sparse attention patterns. "to efficiently implement the flex_block_attention algorithm."
- Flow matching: A generative training paradigm that learns a continuous-time flow between data and noise distributions. "flow matching-based training is particularly sensitive to the shift hyper-parameter when video token lengths vary across stages."
- Glyph-ByT5: A multilingual, glyph-aware variant of ByT5 specialized for accurate text rendering in images/videos. "the incorporation of a multilingual Glyph-ByT5 \cite{liu2024glyphbyt5customizedtextencoder} text encoder further strengthens the model’s ability to render text accurately across various languages."
- Good/Same/Bad (GSB): A relative evaluation protocol comparing two models’ outputs by categorical judgments. "The GSB approach is widely used to evaluate the relative performance of two models based on overall video perception quality."
- Group offloading: A memory management technique that offloads groups of model states/activations to host memory to fit larger workloads on a single GPU. "When pipeline offloading, group offloading, and VAE tiling are enabled, the entire pipeline can complete end-to-end inference for 720p 121-frame T2V/I2V generation with a peak memory of 13.6 GB"
- Kernel fusion: Combining multiple GPU operations into fused kernels to reduce overhead and improve throughput. "the DiT is compiled using PyTorch's torch.compile to enable kernel fusion and operator optimization"
- Mixture of Experts (MoE): An architecture that routes tokens to specialized expert sub-networks to increase capacity efficiently. "Wan2.2 \cite{wan2025} employs a hybrid Mixture of Experts (MoE) architecture that leverages two 14-billion-parameter expert models to enhance video quality."
- MixGRPO: A hybrid ODE–SDE solver and optimization approach for reinforcement learning on diffusion/flow models. "and adopt a hybrid ODE–SDE solver (MixGRPO~\cite{li2025mixgrpounlockingflowbasedgrpo}) to enrich exploration while maintaining sampling quality."
- Muon optimizer: An optimizer reported to converge faster than AdamW for large-scale generative training. "The Muon optimizer \cite{kimiteam2025kimik2openagentic} is used in this work to achieve faster convergence."
- OPA-DPO: A reinforcement learning method that integrates Offline Preference Alignment with Direct Preference Optimization to reduce hallucinations. "we integrate Reinforcement Learning (RL), specifically OPA-DPO \cite{yang2025mitigating}, into our caption model post-training pipeline"
- Pipeline offloading: Offloading segments of the model/pipeline to CPU or other devices to reduce GPU peak memory. "When pipeline offloading, group offloading, and VAE tiling are enabled, the entire pipeline can complete end-to-end inference ..."
- PySceneDetect: A tool/library for automatic shot/scene boundary detection in videos. "we utilized PySceneDetect~\cite{PySceneDetect} combined with a custom segmentation operator to detect scene boundaries."
- Qwen2.5-VL: A multimodal vision-language encoder used for strong scene, action, and instruction understanding. "a visual-language multimodal encoder Qwen2.5-VL \cite{bai2025qwen25vltechnicalreport} to achieve a deeper understanding of scene descriptions, character actions, and specific requirements."
- Reinforcement Learning from Human Feedback (RLHF): An alignment approach that uses human (or proxy) feedback to optimize generative models. "This multi-stage process consists of continuing training (CT), supervised fine-tuning (SFT), and human feedback alignment (RLHF)"
- SageAttention: An efficient attention implementation to reduce memory and accelerate transformer inference/training. "SageAttention~\cite{zhang2024sageattention2} is adopted for attention operations to reduce memory complexity and improve computational efficiency"
- Selective and Sliding Tile Attention (SSTA): A parameter-free sparse attention mechanism combining dynamic selection with local sliding windows for videos. "we propose a novel sparse attention method termed SSTA (Selective and Sliding Tile Attention)."
- SigLip: A Sigmoid-loss variant of CLIP used for robust visual-semantic feature extraction. "SigLip-based feature extraction, where semantic embeddings are concatenated sequentially to enhance semantic alignment"
- Sliding Tile Attention (STA): A local-window attention scheme that computes attention within sliding spatiotemporal tiles. "(3) STA (Sliding Tile Attention) Mask Generation"
- Supervised Fine-Tuning (SFT): A post-training stage that refines the model on high-quality labeled data for target tasks. "During SFT, we utilize rigorously selected clips per task, filtered strictly considering aesthetic appeal, clarity, and motion smoothness."
- ThunderKittens: A high-performance GPU kernel framework used to implement custom attention operators. "utilizing the ThunderKittens \cite{spector2024thunderkittenssimplefastadorable} framework to efficiently implement the flex_block_attention algorithm."
- torch.compile: PyTorch’s compilation facility that accelerates models via graph capture, kernel fusion, and operator optimization. "the DiT is compiled using PyTorch's torch.compile to enable kernel fusion and operator optimization"
- VAE: Variational Autoencoder, used to encode/decode video/image latents with strong spatiotemporal compression. "VAE-based encoding, where the image latent is concatenated with the noisy latent along the channel dimension"
- VAE tiling: Splitting VAE encoding/decoding into tiles to reduce memory for high-resolution videos. "When pipeline offloading, group offloading, and VAE tiling are enabled"
- Video Super-Resolution (VSR): A model that upscales and enhances generated videos (e.g., 480p/720p to 1080p) with improved detail and stability. "we introduce a cascaded Video Super-Resolution (VSR) model that enhances fine-grained visual details and textures in videos"
- Vision-LLM (VLM): A multimodal model that jointly processes visual and textual inputs, often used as a reward/evaluation or captioning component. "Candidate prompts are first generated via a vision-LLM (VLM), then manually verified to ensure strict text-image consistency."
Collections
Sign up for free to add this paper to one or more collections.