Solving Spatial Supersensing Without Spatial Supersensing
Abstract: Cambrian-S aims to take the first steps towards improving video world models with spatial supersensing by introducing (i) two benchmarks, VSI-Super-Recall (VSR) and VSI-Super-Counting (VSC), and (ii) bespoke predictive sensing inference strategies tailored to each benchmark. In this work, we conduct a critical analysis of Cambrian-S across both these fronts. First, we introduce a simple baseline, NoSense, which discards almost all temporal structure and uses only a bag-of-words SigLIP model, yet near-perfectly solves VSR, achieving 95% accuracy even on 4-hour videos. This shows benchmarks like VSR can be nearly solved without spatial cognition, world modeling or spatial supersensing. Second, we hypothesize that the tailored inference methods proposed by Cambrian-S likely exploit shortcut heuristics in the benchmark. We illustrate this with a simple sanity check on the VSC benchmark, called VSC-Repeat: We concatenate each video with itself 1-5 times, which does not change the number of unique objects. However, this simple perturbation entirely collapses the mean relative accuracy of Cambrian-S from 42% to 0%. A system that performs spatial supersensing and integrates information across experiences should recognize views of the same scene and keep object-count predictions unchanged; instead, Cambrian-S inference algorithm relies largely on a shortcut in the VSC benchmark that rooms are never revisited. Taken together, our findings suggest that (i) current VSI-Super benchmarks do not yet reliably measure spatial supersensing, and (ii) predictive-sensing inference recipes used by Cambrian-S improve performance by inadvertently exploiting shortcuts rather than from robust spatial supersensing. We include the response from the Cambrian-S authors (in Appendix A) to provide a balanced perspective alongside our claims. We release our code at: https://github.com/bethgelab/supersanity

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how we test AI systems that watch long videos and try to build a “world model” — a mental map of places, objects, and events over time. The authors ask whether current tests really force AIs to use deep spatial understanding, or if AIs can get high scores by using simple shortcuts. They focus on a recent set of benchmarks called VSI-Super and a model/inference setup called Cambrian-S, both meant to measure “spatial supersensing” — the ability to form accurate, predictive maps of the world from video.
The Main Questions
The authors investigate two simple, big questions:
- Can the “VSI-Super-Recall” (VSR) task be solved almost perfectly without any real spatial reasoning, just by picking a few useful frames?
- Does the “VSI-Super-Counting” (VSC) task reward models that use shortcuts (like assuming rooms never repeat) rather than true spatial memory across revisits?
How They Tested Their Ideas
The paper uses two straightforward tests that you can think of like stress checks for the benchmarks.
Test 1: VSR with a very simple method (“NoSense”)
- What VSR asks: Given a long video, figure out the order in which a target object appears next to four different things (like a teddy bear beside a bed, then a bathtub, sink, floor).
- The authors’ method (“NoSense”): Instead of tracking the whole video or building a 3D map, they:
- Scan the video frame by frame at 1 frame per second.
- Keep only the top four frames that best match the target object (like finding the few frames where the teddy bear is most clearly visible).
- Compare those frames to text descriptions of the four “auxiliary” things (bed, bathtub, etc.), and pick the answer option with the best overall match.
Think of it like using a “find” function in a document: you jump to the most relevant spots and ignore the rest. This method uses a vision–LLM called SigLIP/CLIP to measure similarity between images and text but does not do any time-based reasoning, object tracking, or 3D modeling. That’s why they call it “NoSense” — no spatial supersensing.
Test 2: VSC with a repeat trick (“VSC-Repeat”)
What VSC asks: Count how many unique objects (like chairs) appear across a long video. Crucially, you should not double-count the same chair if you see it again later.
- What Cambrian-S does: It segments the video whenever it feels “surprised” (when a prediction model’s error spikes), treats each segment as a new room or scene, counts objects within each segment, and adds them up. This assumes scenes don’t repeat.
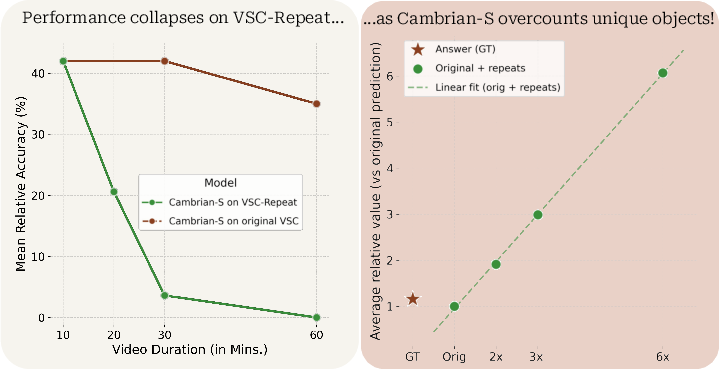
- The authors’ sanity check: They take each video and paste it to itself multiple times (2 to 5 repeats). The rooms and objects don’t change — you just see them again. A model with real spatial memory should keep the count the same. If it overcounts, it’s probably relying on the shortcut “new segment = new room = new objects.”
Key Results and Why They Matter
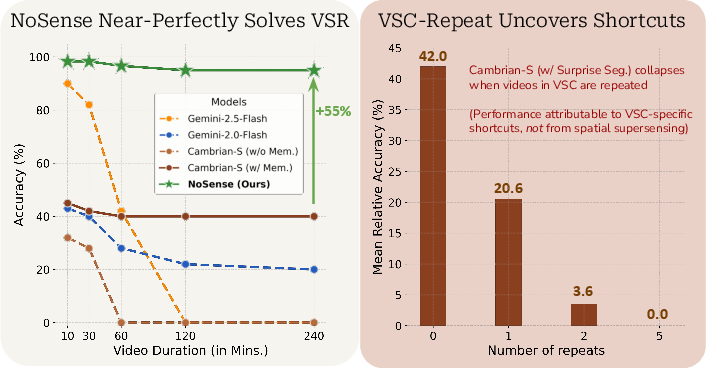
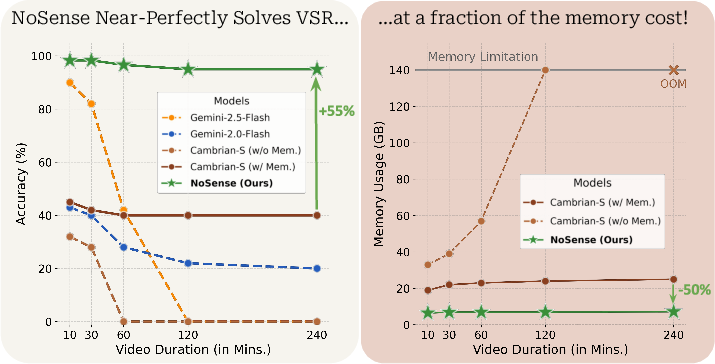
- NoSense nearly solves VSR without spatial supersensing:
- It reaches about 98% accuracy on 10-minute videos and about 95% accuracy on 2–4 hour videos.
- This beats Cambrian-S by a large margin, showing that VSR can be solved by picking a few informative frames and matching text, not by building a long-term spatial model.
- Cambrian-S collapses on VSC when videos are repeated:
- Accuracy drops from around 42% to nearly 0% after five repeats.
- Predicted counts rise with each repeat, as if the model assumes every segment is a brand-new room. This shows the counting strategy depends on a shortcut in the benchmark: “rooms don’t repeat.”
Why this matters: If a benchmark lets models win by shortcuts, high scores may not mean real progress in “world modeling.” We might be measuring frame matching or segment counting, not true spatial memory across time.
What This Means for the Future
The authors suggest simple, practical ways to make benchmarks better:
- Build “invariance checks” into tests: Apply harmless changes that should not affect the correct answer, like repeating scenes, revisiting rooms after long gaps, changing playback speed, or shuffling segments with the same layout. If performance drops, the model likely uses shortcuts.
- Use more natural, truly long videos: Real-world videos often revisit places and loop around. Benchmarks should include revisits and non-obvious scene changes, so models can’t rely on “surprise = new room.”
- Keep tasks open-ended and realistic: Avoid turning rich tasks into narrow multiple-choice questions only. Test whether each modality (like vision alone) really contributes meaningfully.
- Make “meta-evaluation” routine: Stress-test both benchmarks and models, not just models. Always ask: What’s the simplest baseline that exploits obvious patterns? Which assumptions should hold, and do they?
Balanced Perspective and Limitations
- The Cambrian-S authors responded that VSR is like a “needle-in-a-haystack” test for long videos and that their goal is to push long-context handling, not to encourage tool-like solutions. They also acknowledged VSC’s limitation on repeated scenes and plan to improve future datasets and models.
- The paper’s own limits: It analyzes one benchmark family (VSI-Super) and one main method (Cambrian-S). Results may not generalize to other datasets or algorithms. It diagnoses issues and suggests principles but does not propose a complete replacement benchmark.
Simple Takeaway
The paper shows that two popular long-video tests can be beaten by simple strategies that don’t use real spatial understanding:
- For VSR, picking a few key frames and matching text is enough.
- For VSC, assuming “new segment = new room” breaks when rooms repeat.
This means we should be careful when claiming that high scores prove strong “world models.” Better tests should include revisits, invariance checks, and more natural long videos, so success truly reflects spatial supersensing rather than clever shortcuts.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on them.
- Generalization beyond VSI-Super and Cambrian-S is untested: evaluate NoSense and the paper’s claims on diverse long-form, continuous, revisiting video datasets (egocentric traversals, street/building walkthroughs, synthetic worlds with loops) and across multiple methods beyond Cambrian-S.
- Query-blind streaming remains unexamined: measure VSR performance when the target query is revealed only after video processing (as intended by Cambrian-S authors), and design query-agnostic memory summarization that can later support retrieval.
- Limited invariance stress testing: VSC-Repeat exposes one shortcut, but broader invariance checks (revisits after long delays, shuffled segments with identical layouts, speed changes, decoy insertions, occlusions, camera re-entries) are not implemented or quantified for VSR/VSC.
- Lack of an operational definition and metrics for “spatial supersensing”: formalize required capabilities (identity persistence, revisit invariance, global map consistency), and propose validated metrics beyond accuracy/MRA (e.g., state-consistency under perturbations, revisit-invariance scores).
- No robust alternative inference for counting is proposed: design and evaluate VSC methods that avoid re-counting on revisits (e.g., cross-segment identity tracking, SLAM-like scene maps, set-based deduplication with persistent object IDs, buffer policies that do not reset identity memory at surprise boundaries).
- NoSense is not evaluated on VSC: test whether simple retrieval-with-dedup baselines can succeed or fail on unique-object counting, to delineate which tasks genuinely require long-horizon identity tracking vs. frame-level semantics.
- Missing component-level causal analysis of Cambrian-S failures: ablate the surprise segmentation thresholds, buffer reset policy, segment aggregation, and dedup logic to isolate which design choices drive the VSC-Repeat collapse.
- VSR robustness is underexplored: stress test NoSense and Cambrian-S with distractor frames, altered number of insertions (≠4), ambiguous or noisy auxiliary prompts, varied object appearances, and mislocalizations to assess sensitivity and failure modes.
- Scaling and resource dependence are not quantified: characterize how VSR performance varies with VLM size, training corpus, FPS sampling rate, and the number of stored frames (k), including compute/memory/run-time trade-offs and minimal resource thresholds for near-perfect accuracy.
- Black-box large models are not probed for shortcuts: evaluate Gemini and other long-context video LLMs under VSC-Repeat and other invariance checks to determine whether their gains reflect genuine supersensing vs. dataset-specific heuristics.
- Dataset biases and annotation quality are not audited: analyze revisits, segment-boundary reliability, object co-occurrence patterns, and insertion regularities in VSI-Super; publish statistics and checks that ensure counts and temporal orders are not trivially recoverable from spurious cues.
- Counting metric adequacy is unaddressed: validate whether mean relative accuracy captures overcount vs. undercount asymmetries, and consider metrics aligned with identity persistence (e.g., precision/recall of unique object identities, per-identity F1 across revisits).
- Absence of continuous, real-world long videos: the paper recommends but does not introduce or evaluate on truly continuous, unsegmented streams with natural revisits; creating and releasing such datasets is an open, necessary step.
- No standardized stress-testing toolkit: package VSC-Repeat and a broader set of perturbations as a reproducible suite (repeat, shuffle, scramble, speed-change), with documented generation protocols and shared baselines.
- Temporal reasoning disentanglement is missing: run controlled experiments that compare static VLM retrieval, video transformers with recurrence, and explicit memory architectures to quantify the added value of genuine temporal modeling.
- Benchmark protocol ambiguity on query awareness: clarify and test both regimes (query-aware vs. query-blind streaming) to ensure conclusions about VSR difficulty are valid under the benchmark’s intended rules.
- Cross-modal supersensing is unexplored: examine whether audio or other modalities improve revisit-invariant identity tracking and map coherence, and whether multimodality introduces new shortcuts.
- Human baseline and cognitive alignment are absent: collect human performance and memory protocol comparisons (e.g., recall after delayed query, revisit consistency), to calibrate task design and set realistic targets for supersensing capabilities.
- Viewpoint, lighting, and occlusion robustness in revisits is not tested: create revisit scenarios with substantial viewpoint changes and environmental variation to evaluate identity persistence beyond simple repetition.
- Reproducibility details are incomplete: provide end-to-end scripts and hyperparameters for VSC-Repeat construction, SigLIP/CLIP selection, prompt templates, and evaluation pipelines to facilitate independent replication and extension.
Practical Applications
Immediate Applications
The following list summarizes concrete, deployable use cases that leverage the paper’s findings and tools, along with sector links and key assumptions.
- Benchmark sanity-testing toolkit for long-video AI
- Sector: academia, industry (ML research/QA)
- Application: Integrate NoSense (SigLIP-based frame retrieval) and VSC-Repeat (video concatenation perturbation) into evaluation pipelines to audit whether “spatial supersensing” claims reflect shortcuts (e.g., reliance on non-repeating rooms).
- Tools/workflows: Use the authors’ GitHub (“supersanity”) to run NoSense on VSR; auto-generate invariance-preserving perturbations (repeat, shuffle, playback-speed changes) and report performance deltas.
- Assumptions/dependencies: Access to contrastive VLMs (CLIP/SigLIP) and the benchmark videos; organizational willingness to adopt meta-evaluation as standard practice.
- Low-cost video QA/search systems using contrastive retrieval
- Sector: software, media/entertainment, edtech
- Application: Deploy CLIP/SigLIP-based “needle-in-video” retrieval for tasks that only require finding a few discriminative frames (e.g., lecture indexing, broadcast compliance checks, content moderation triage, sports highlight detection).
- Tools/workflows: Stream frames at low FPS; maintain a small top-k buffer per query; score answer options via cosine similarity with text prompts.
- Assumptions/dependencies: Tasks resemble VSR (semantic recall from few frames); users accept that these systems do not perform true spatial reasoning.
- Quality assurance for counting systems (avoid repeat-driven overcounting)
- Sector: retail (inventory video), facility management, security analytics
- Application: Add “revisit invariance” tests akin to VSC-Repeat to ensure object-counting systems don’t inflate counts when environments are revisited or segments repeat.
- Tools/workflows: Concatenate identical video segments and check that unique-object counts remain stable; instrument surprise/segmentation modules to prevent buffer resets from triggering re-counting.
- Assumptions/dependencies: Ability to simulate revisits or gather repeated traversals; access to model internals or post-processing hooks.
- Robotics evaluation protocols with loop-closure sanity checks
- Sector: robotics (SLAM, navigation, embodied AI)
- Application: Extend evaluation suites to include repeated-route traversals and environment revisits to verify persistent object identity and map consistency (loop closure).
- Tools/workflows: Insert planned revisits into navigation datasets; measure whether predicted maps/object sets remain stable across revisits.
- Assumptions/dependencies: Logging infrastructure and environments that permit controlled revisits; models that expose map/state for inspection.
- Procurement and grant-review checklists for benchmark governance
- Sector: policy, public funding, enterprise IT procurement
- Application: Require invariance-based stress tests (e.g., VSC-Repeat, shuffled segments) and disclosure of shortcut susceptibility in claims of “world modeling.”
- Tools/workflows: Standardized evaluation addenda in RFPs and grant proposals; audit summaries showing performance under perturbations.
- Assumptions/dependencies: Governance bodies willing to enforce evaluation transparency; availability of neutral auditors.
- MLOps dashboards reporting performance under invariance perturbations
- Sector: software (MLOps), AIOps
- Application: Track and alert on metric changes when videos are perturbed (repeat/shuffle/speed), surfacing shortcut reliance before release.
- Tools/workflows: Integrate perturbation runners with MLflow/Weights & Biases; add “invariance scorecards” to CI/CD.
- Assumptions/dependencies: CI/CD access to evaluation datasets; budget for automated testing in pipelines.
- Curriculum and lab assignments on shortcut learning in video AI
- Sector: education (CS/AI courses), professional training
- Application: Teach benchmark pitfalls via hands-on replication of NoSense and VSC-Repeat; design assignments that probe invariances and revisits.
- Tools/workflows: Provide starter notebooks using SigLIP/CLIP; include benchmark perturbation scripts.
- Assumptions/dependencies: Availability of pretrained models and datasets; institutional approval for dataset use.
- Model selection guidance for enterprise video analytics
- Sector: enterprise software
- Application: Match task requirements to retrieval-based baselines when spatial reasoning is not needed (e.g., time-ordered recall questions), reducing cost/complexity.
- Tools/workflows: Decision matrices that flag when CLIP/SigLIP-style solutions suffice; pilot evaluations using NoSense-like pipelines.
- Assumptions/dependencies: Clear task scoping; acceptance that simpler models may generalize less when conditions shift (e.g., revisits).
- Benchmark authoring aids with built-in invariance checks
- Sector: academia, open-source dataset communities
- Application: Include repeat/loop/shuffle perturbations and report invariant metrics alongside primary scores in new benchmark releases.
- Tools/workflows: Template scripts for generating invariance-preserving variants; documentation of assumptions (e.g., “rooms never repeat”) and their tests.
- Assumptions/dependencies: Community norms favoring meta-evaluation; computational resources for perturbation evaluation.
Long-Term Applications
The following items require further research, scaling, or ecosystem development to become broadly deployable.
- Robust spatial supersensing benchmarks with natural revisits
- Sector: academia, industry (AI evaluation)
- Application: Build continuous, egocentric long-form datasets featuring loops, revisits, and ambiguous boundaries so surprise signals don’t trivially imply environment changes.
- Tools/workflows: Data collection in buildings/streets; synthetic world generators (Habitat/Gibson), explicit revisit schedules; metrics for identity persistence and map stability.
- Assumptions/dependencies: Funding and privacy-conscious data collection; consensus on new metrics; broad community adoption.
- Persistent identity and map memory architectures
- Sector: robotics, software (video understanding), AR
- Application: Develop models that maintain a durable set/map of unique objects across time and revisits (revisit-invariant counting, layout reconstruction).
- Tools/workflows: Object-centric memory modules, long-horizon temporal reasoning, loop-closure detection; benchmarks that penalize re-counting on revisits.
- Assumptions/dependencies: Scalable memory designs and training regimes; efficient retrieval and identity resolution at long horizons.
- Certification for “world-modeling” claims in video AI
- Sector: policy/regulatory, standards (ISO/IEEE)
- Application: Third-party certification that models pass invariance checks (repeat/shuffle/revisit) and maintain persistent state, with standardized reporting.
- Tools/workflows: Accredited test suites; reference datasets; certification audits and public scorecards.
- Assumptions/dependencies: Regulatory buy-in; trusted evaluation bodies; liability frameworks for misclaims.
- Evaluation-as-a-service platforms for invariance testing
- Sector: software/SaaS, MLOps
- Application: Offer automated adversarial perturbations and invariance scorecards across diverse video tasks to detect shortcut reliance pre-deployment.
- Tools/workflows: APIs for dataset ingestion; perturbation generators; dashboards with longitudinal tracking across versions.
- Assumptions/dependencies: Customer integration; standardized dataset formats; cost-effective compute.
- Healthcare video analytics with revisit-invariant counting
- Sector: healthcare
- Application: Endoscopy/OR monitoring systems that avoid double-counting lesions/instruments when scenes revisit; long-horizon patient monitoring with persistent identity.
- Tools/workflows: Clinical data pipelines with controlled revisits; identity tracking modules; compliance audits under perturbations.
- Assumptions/dependencies: Rigorous clinical validation; HIPAA/GDPR compliance; cross-institutional datasets.
- Smart home and security assistants with stable long-term environmental memory
- Sector: consumer IoT, security
- Application: Assistants that maintain a map of the home/building, track unique assets, and remain robust to repeated patrols or camera loops.
- Tools/workflows: On-device memory modules; privacy-preserving map storage; revisit detection.
- Assumptions/dependencies: Efficient on-device compute; user consent and privacy controls; robust sensor calibration.
- Financial due diligence frameworks for AI vendors
- Sector: finance (risk/audit)
- Application: Incorporate invariance benchmarks in vendor evaluation to quantify overfitting to dataset quirks; adjust risk ratings and SLAs accordingly.
- Tools/workflows: Audit checklists; standardized reporting of invariance performance; contractual penalties for shortcut reliance.
- Assumptions/dependencies: Access to vendor models/metrics; industry consensus on evaluation standards.
- Open-source libraries for invariance transformations and metrics
- Sector: software (open-source), academia
- Application: Provide composable video perturbation operators (repeat, shuffle, speed, revisit synthesis) and revisit-invariance scores for integration into eval suites.
- Tools/workflows: Python libraries integrated with Hugging Face/Weights & Biases; example configs for common benchmarks.
- Assumptions/dependencies: Maintainer community; interoperability with diverse datasets and model APIs.
- Standardized model cards that include invariance and revisit metrics
- Sector: policy, academia, industry
- Application: Expand model documentation to report performance under invariance-preserving perturbations, detailing assumptions (e.g., “rooms never repeat”) and known failure modes.
- Tools/workflows: Model card templates; automated generation from evaluation pipelines; governance guidelines for disclosure.
- Assumptions/dependencies: Community agreement on required fields; willingness to disclose limitations and shortcut risks.
Glossary
- Ablation studies: Controlled experiments that remove or vary components to assess their contribution to performance. "We view this kind of meta-evaluation as analogous to ablation studies for models and believe it should be standard for benchmarks."
- Bag-of-words: A representation treating text as an unordered set of words, ignoring syntax and word order. "uses only a bag-of-words SigLIP model"
- Cambrian-S: A benchmark and model suite proposing tailored inference for spatial supersensing tasks. "A recent work, Cambrian-S~\citep{cambrian-s} proposes to address these issues."
- CLIP: A pretrained contrastive vision–LLM aligning images and text embeddings. "NoSense is a simple streaming method that uses only a CLIP/SigLIP model~\citep{radford2021learning,zhai2023sigmoid},"
- Contrastive vision–LLM (VLM): A model trained to bring related image–text pairs closer in embedding space and push unrelated ones apart. "The primary and only main design choice for NoSense is the contrastive VLM used for text and image embeddings."
- Cosine similarity: A similarity measure between vectors based on the cosine of the angle between them. "it scores answer options by aggregating cosine similarities to auxiliary object prompts"
- Egocentric traversals: First-person video sequences capturing continuous movement through environments. "e.g., egocentric traversals of buildings, streets, or synthetic worlds with natural revisits and loops"
- Event buffer: A temporary storage of frame-level features within a detected segment used to summarize information. "Within each segment, the model accumulates frame features in an event buffer."
- Event segmentation: Partitioning a continuous video stream into coherent segments based on change signals (e.g., surprise). "Cambrian-S introduces a surprise-based event segmentation approach to improve performance on VSC."
- Inductive bias: Built-in assumptions or constraints in a model that guide learning and inference. "NoSense uses no more inductive bias than Cambrian-S for this task,"
- Latent frame-prediction model: A model that predicts future frame features and uses prediction errors as signals (e.g., surprise). "It uses a latent frame-prediction model to compute a \"surprise\" signal (prediction error)"
- Mean relative accuracy (MRA): An evaluation metric measuring accuracy relative to ground-truth counts across videos. "drastically reduces the mean relative accuracy (MRA) of the Cambrian-S inference pipeline from to ;"
- Multimodal LLM: A LLM that processes and reasons over multiple modalities (e.g., vision and text). "but with a multimodal LLM."
- Needle-In-A-Haystack (NIAH): A long-context evaluation paradigm where a small target (“needle”) must be found in a large input (“haystack”). "VSR is like a \"Needle-In-A-Haystack\" (NIAH) task for video."
- NoSense: A simple baseline that uses frame-level retrieval with a contrastive VLM and no temporal reasoning to solve VSR. "We call the resulting baseline NoSense, short for No Supersensing."
- Predictive memory: A mechanism that maintains and updates representations to anticipate future inputs in long videos. "similar in magnitude to Cambrian‑S model with predictive memory on the same split"
- Predictive sensing: Inference strategies that use prediction signals (e.g., surprise) to drive segmentation and aggregation. "bespoke predictive sensing inference strategies tailored to each benchmark."
- Prompt ensembling: Using multiple text prompts/templates to improve robustness and quality of text embeddings. "removing prompt ensembling and using a single basic template for all text encodings."
- Query-guided retrieval: Selecting and scoring frames based on their relevance to a given query (object and auxiliaries). "query-guided retrieval mechanism."
- Shortcut learning: Exploiting spurious correlations or dataset-specific quirks that allow high performance without genuine capability. "This is known as shortcut learning~\citep{geirhos2020shortcut}."
- SigLIP: A CLIP-like vision–LLM that uses a sigmoid-based loss for contrastive alignment. "We take SigLIP-2, select the four frames most relevant to the object mentioned in the question,"
- Spatial cognition: The ability to understand, represent, and reason about spatial relationships and environments. "strong performance on these benchmarks should require genuine spatial cognition and memory."
- Spatial supersensing: Forming predictive, coherent world models from raw long video streams through spatial and temporal integration. "Taken together, our findings suggest that (i) current VSI-Super benchmarks do not yet reliably measure spatial supersensing,"
- Streaming frame encoding: Processing frames sequentially as they arrive, typically at fixed FPS, to produce embeddings. "streaming frame encoding, a compact memory of salient frames, and query‑guided retrieval"
- Surprise-based segmentation: Detecting segment boundaries using spikes in prediction error (“surprise”) from a predictive model. "indicating that its surprise-based segmentation inference method relies on VSC-specific shortcuts rather than genuine spatial cognition."
- Surprise signal: A prediction-error magnitude used to indicate unexpected changes that may mark segment boundaries. "compute a \"surprise\" signal (prediction error)"
- Top‑k: Selecting the k highest-scoring items (e.g., frames) according to a retrieval similarity metric. "top- frames for NoSense"
- VSI-Super-Counting (VSC): A benchmark requiring models to count unique objects across long video streams. "VSI-Super-Counting (VSC)"
- VSI-Super-Recall (VSR): A benchmark requiring models to recover the appearance order of an object co-located with auxiliaries. "VSI-Super-Recall (VSR)"
- World model: An internal representation that supports prediction and reasoning about entities and dynamics over time. "video \"world models\""
Collections
Sign up for free to add this paper to one or more collections.