- The paper shows that VL models exhibit a significant struggle with spatial reasoning, often scoring only slightly above random chance.
- The study introduces three benchmarks (COCO-spatial, GQA-spatial, and What's 'Up') to isolate spatial reasoning challenges.
- Evaluations reveal that ambiguous spatial prepositions in training data hinder model understanding, prompting exploration of alternative fine-tuning strategies.
Investigating Vision-LLMs' Struggle with Spatial Reasoning
Recent advances in neural networks, especially in vision-language (VL) models, have demonstrated impressive performance on numerous complex tasks. However, spatial reasoning—a fundamental cognitive skill—continues to be an elusive area for these models. This paper investigates the limitations of VL models regarding their spatial reasoning capabilities, emphasizes the gap between human and machine performance in this domain, and explores potential solutions to enhance VL models.
Introduction to Spatial Reasoning Challenges
VL models are pre-trained on extensive datasets to generalize tasks such as visual question answering (VQAv2) and captioning but struggle with fundamental spatial reasoning tasks. The ability to discern simple spatial arrangements like "left of" or "right of" is crucial for sophisticated visual understanding, yet recent evaluations show notable deficiencies in VL models' proficiency in this area.
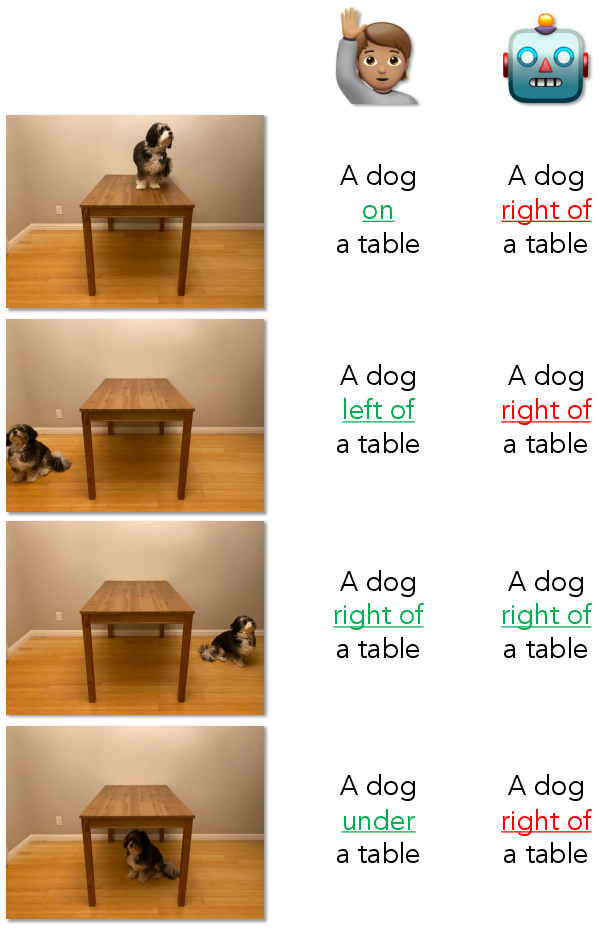
Figure 1: We propose three tightly controlled benchmarks to assess model capacity for fine-grained spatial reasoning, showing that popular vision-LLMs fall far behind human performance when asked to select the correct spatial relation between two objects in an image (real examples shown).
Benchmarking Spatial Reasoning
The paper introduces three novel benchmarks—derived from COCO, GQA, and a newly constructed dataset called What's "Up"—to isolate spatial reasoning tasks from other forms of visual interpretation. These benchmarks require models to identify correct spatial prepositions between objects, a task humans perform almost perfectly yet remains challenging for models.

Figure 2: Examples from our three proposed benchmarks. Each image is paired with four text options in COCO-spatial and two text options in GQA-spatial and What's "Up". Given a single image and the corresponding text options, a VL model must select the correct option.
Evaluation of Vision-LLMs
Evaluations of 18 diverse VL models, including architectures like CLIP, BLIP, and CoCa, show consistently poor performance across all benchmarks. Models often score slightly above random chance, highlighting their limited spatial reasoning capabilities even when scaled up or fine-tuned on relevant datasets.
Analysis of Pre-training Data
Investigations into the LAION-2B dataset reveal sparse and ambiguous use of spatial prepositions, contributing to models' struggles in spatial reasoning. These prepositions are often extraneous or inconsistently defined, hindering the models' ability to develop a robust understanding of spatial relations between objects.

Figure 3: Examples of ambiguity in spatial prepositions used in LAION captions, alongside discussions thereof.
Strategies for Improvement
Various strategies are explored, including re-normalizing caption probabilities, employing alternative prompts, and finetuning on spatial-specific datasets. While these methods yield slight improvements, they fail to bridge the significant gap between human and model performance.
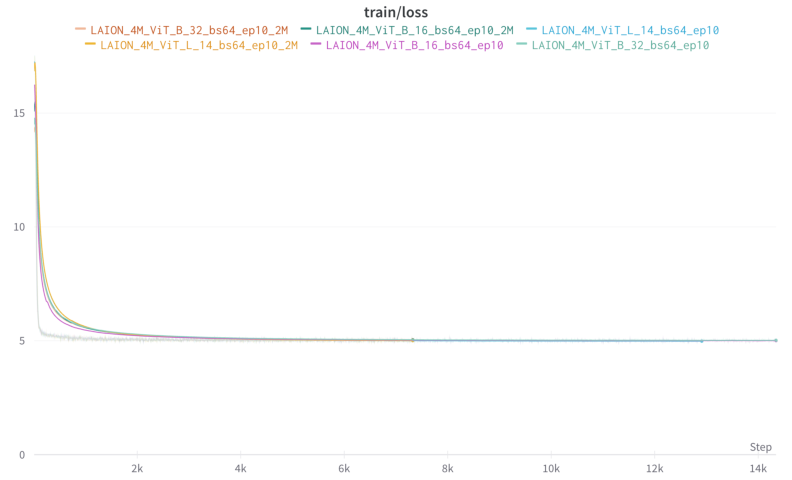
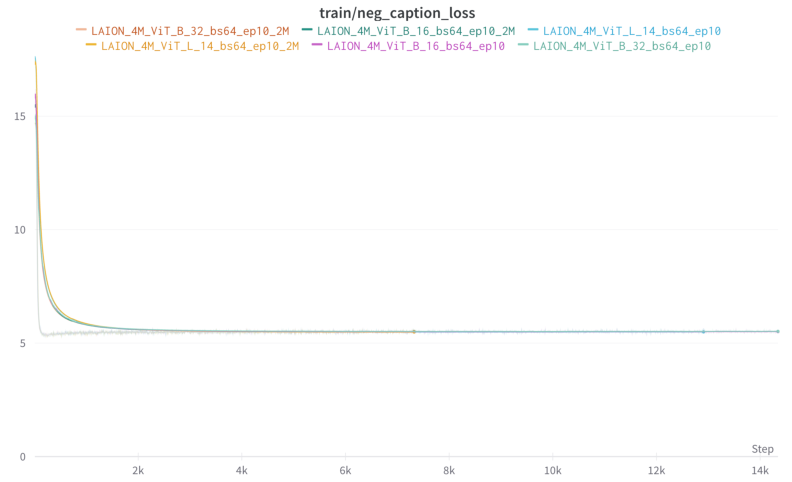
Figure 4: Train loss (left) and negative caption loss (right) when finetuning variants of CLIP on LAION-4M-prep with hard negatives targeting prepositions, on either the full dataset or half of the dataset (suffix _2M).
Implications and Future Directions
Findings from this study suggest a need for more focused pre-training data that genuinely represents spatial interactions in real-world contexts. Future research could explore data generation methods that emphasize spatial dynamics or enhance VL architectures to embed spatial relation understanding deeply.
Conclusion
Despite breakthroughs in many areas of artificial intelligence, VL models demonstrate a profound gap in spatial reasoning compared to human expertise. This paper's benchmarks provide critical insight into these models' limitations and direct future research to overcome these challenges. Ensuring vision-LLMs can automatically understand spatial relations is essential for advancing AI's capacity for real-world visual tasks.

