Cambrian-S: Towards Spatial Supersensing in Video
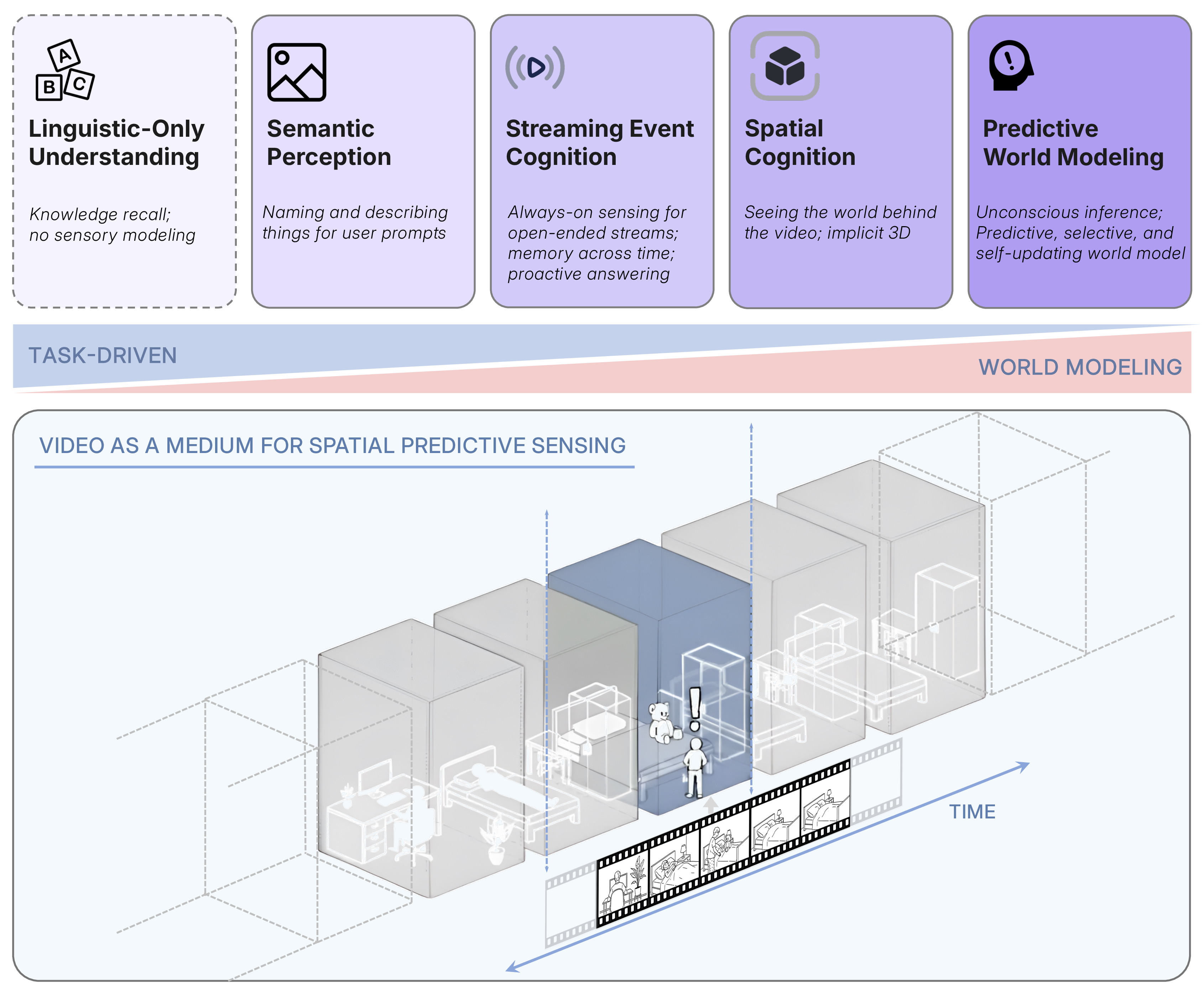
Abstract: We argue that progress in true multimodal intelligence calls for a shift from reactive, task-driven systems and brute-force long context towards a broader paradigm of supersensing. We frame spatial supersensing as four stages beyond linguistic-only understanding: semantic perception (naming what is seen), streaming event cognition (maintaining memory across continuous experiences), implicit 3D spatial cognition (inferring the world behind pixels), and predictive world modeling (creating internal models that filter and organize information). Current benchmarks largely test only the early stages, offering narrow coverage of spatial cognition and rarely challenging models in ways that require true world modeling. To drive progress in spatial supersensing, we present VSI-SUPER, a two-part benchmark: VSR (long-horizon visual spatial recall) and VSC (continual visual spatial counting). These tasks require arbitrarily long video inputs yet are resistant to brute-force context expansion. We then test data scaling limits by curating VSI-590K and training Cambrian-S, achieving +30% absolute improvement on VSI-Bench without sacrificing general capabilities. Yet performance on VSI-SUPER remains limited, indicating that scale alone is insufficient for spatial supersensing. We propose predictive sensing as a path forward, presenting a proof-of-concept in which a self-supervised next-latent-frame predictor leverages surprise (prediction error) to drive memory and event segmentation. On VSI-SUPER, this approach substantially outperforms leading proprietary baselines, showing that spatial supersensing requires models that not only see but also anticipate, select, and organize experience.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Cambrian-S: Towards Spatial Supersensing in Video” for a 14-year-old
Overview
This paper is about teaching AI to understand videos more like humans do. Instead of just recognizing objects or answering simple questions, the authors want AI to:
- see what’s happening in a video,
- remember important events over time,
- understand the 3D world behind the pixels, and
- predict what might happen next.
They call this bigger goal “spatial supersensing.” To push progress, they created new tests (called VSI-Super), built a giant training dataset (VSI-590K), trained new models (called S), and tried a new idea called “predictive sensing” that uses surprise to help the AI decide what to remember.
Key Objectives and Questions
The paper asks clear, practical questions:
- What skills should video AI have beyond just recognizing things in an image?
- How can we test whether an AI truly understands long, complex videos?
- Will giving the AI more data fix the problem?
- Can we design AI that pays attention to surprising moments and organizes its memory intelligently?
Methods and Approach
The authors used four main steps. Here’s what they did, explained with everyday language and analogies:
1) Checking what current benchmarks truly measure
A “benchmark” is a test to see how good an AI is. Many video tests today ask questions that can often be answered by reading captions or looking at a single frame. To investigate this, the authors compared performance under different inputs:
- Multiple frames from a video,
- Just one middle frame,
- Only text captions of frames,
- No visual input at all (“blind”), and
- Random guessing (chance).
If models do well using only captions, the test might not require deep “seeing”—it’s more about reading. They found many popular benchmarks rely heavily on language understanding rather than true video-based spatial reasoning.
2) Creating VSI-Super: two harder, long-video tasks
To better test spatial supersensing, they introduced two new challenges:
- VSR (VSI-Super Recall): Imagine watching a long house-tour video where a surprising object (like a teddy bear) is inserted in different rooms at different times. The AI must remember where it saw that object and recall the locations in the correct order. This is like the “needle-in-a-haystack,” but in realistic video, and you must remember multiple needles over time. Videos can be very long (10, 30, 60, 120, or 240 minutes).
- VSC (VSI-Super Count): The AI watches several room-tour videos stitched together and must count how many target objects appear across all rooms. The count should update as the video continues, like a scoreboard. This tests whether the AI can keep a running tally even as the camera moves, rooms change, and objects repeat.
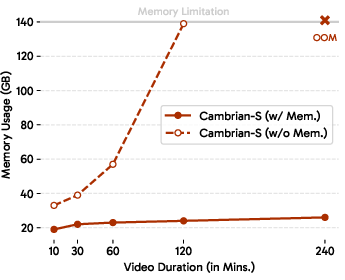
These tasks are designed so that simply giving the model a bigger “context window” (more tokens or frames) won’t solve the problem. The AI must be selective and organized, not just remember everything.
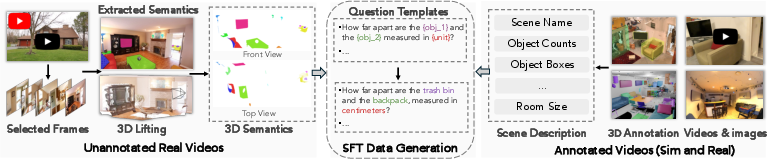
3) Building a big, spatially focused training dataset (VSI-590K)
They collected and generated 590,667 question–answer pairs about spatial reasoning using:
- Annotated real videos (e.g., ScanNet, ARKitScenes) with 3D info,
- Simulated scenes (ProcTHOR, Hypersim),
- Web videos and robot videos with “pseudo”-annotations (labels created by detection, segmentation, and reconstruction tools).
This mix helps the AI learn about 3D spaces, sizes, distances, directions, counts, and event order from many sources. They found annotated real videos help the most, then simulated data, then pseudo-annotated images.
4) Training new models (S) and trying predictive sensing
They trained a family of models called S (with different sizes) using a staged recipe:
- First, learn strong image understanding (semantic perception),
- Then train on video tasks,
- Then fine-tune on spatially focused data (VSI-590K),
- Finally, test on hard long-video tasks (VSI-Super).
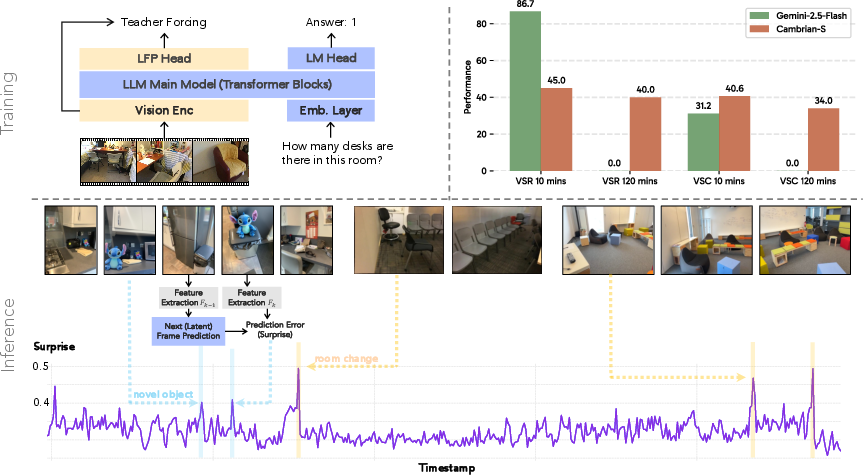
Even after big improvements on regular spatial tests (VSI-Bench showed over +30% absolute gain), models still struggled on VSI-Super. So they tried “predictive sensing”:
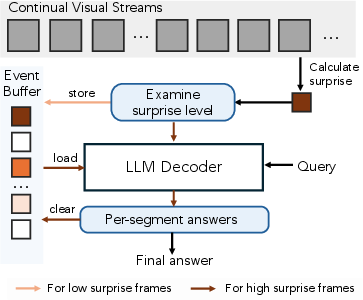
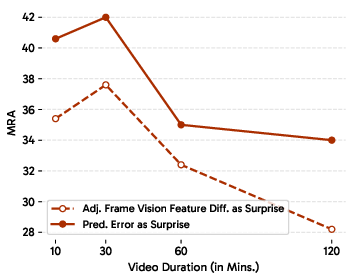
- The AI predicts the next “latent frame” (an internal summary of what comes next).
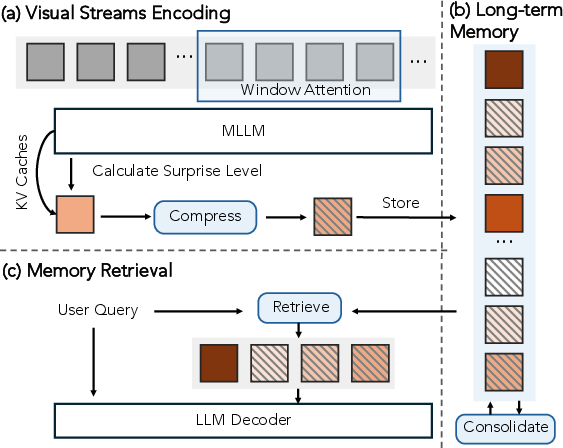
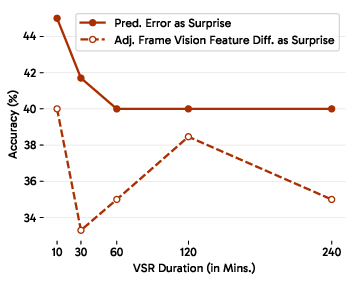
- If reality doesn’t match the prediction, that “surprise” signal helps the AI decide what to remember and where to cut the video into meaningful events (event segmentation). This is like how you pay attention in real life: unexpected things make you focus and remember.
Main Findings and Why They Matter
Here are the core results, explained simply:
- Many existing video tests are more about language than deep visual reasoning. A model can do well by reading captions instead of truly “seeing.”
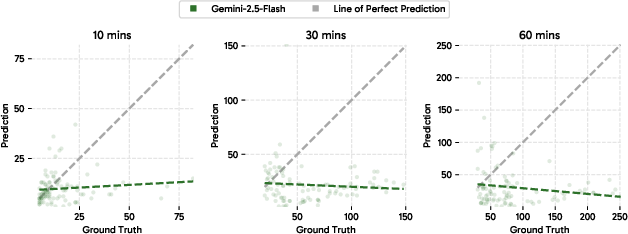
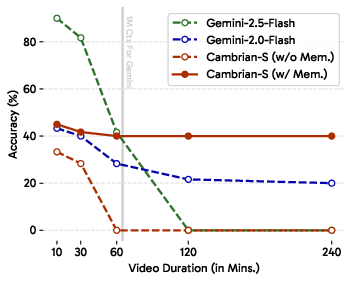
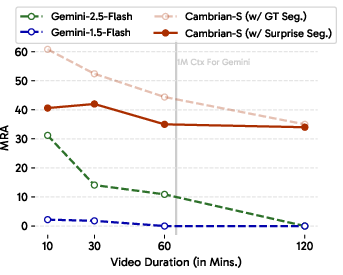
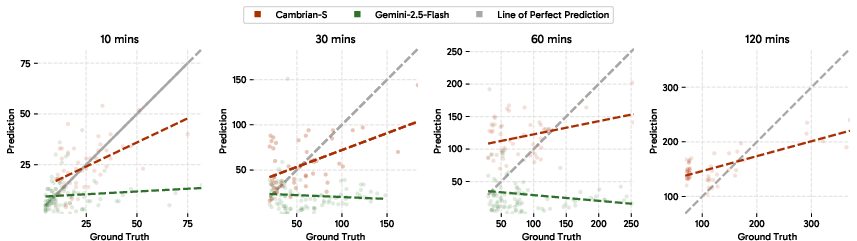
- Long-video understanding is hard. Even top models like Gemini-2.5-Flash, with a huge context limit (over 1 million tokens), struggle:
- On 60-minute videos, Gemini scored about 41.5 on recall (VSR) and 10.9 on counting (VSC).
- On longer videos (e.g., 120 minutes), it hit “out of context” limits.
- Its counts tended to stick at small constant values instead of scaling with longer videos or more objects.
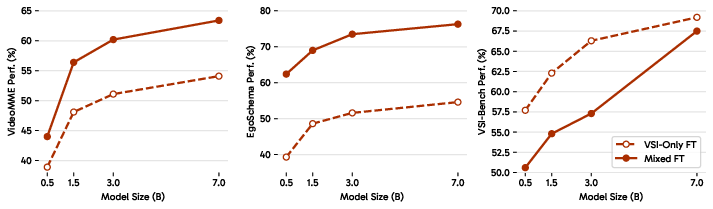
- More and better data helps a lot, but not enough. The S models trained on VSI-590K became very strong on standard spatial benchmarks (VSI-Bench), yet still fell short on VSI-Super’s long, streaming challenges.
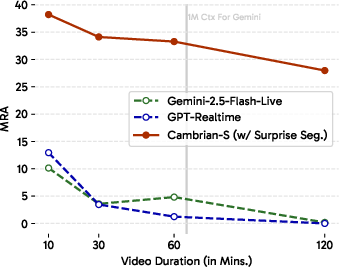
- Predictive sensing made a real difference. Using “surprise” to guide memory and event segmentation substantially beat strong long-context baselines on VSI-Super. This suggests that anticipating and organizing experience is key—not just stuffing more frames into the context.
Implications and Impact
This research points toward a new way of building video AI:
- Scaling alone (more data, bigger models, longer context) is not enough for long, real-world video understanding.
- Future AI needs an internal “world model” that predicts what comes next and uses surprise to focus, remember, and break videos into meaningful events.
- With these skills, AI could:
- Monitor long security footage and remember truly important moments,
- Help robots navigate homes by understanding room layouts and object locations,
- Assist people by watching long tasks and keeping accurate running counts or summaries,
- Learn continuously from everyday experiences, like we do.
In short, the paper argues that the path to human-level video understanding is to build models that don’t just see frames—they anticipate, select, and organize what they see, forming a mental model of the world behind the pixels.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper.
- Operationalizing “spatial supersensing”
- The proposed hierarchy (semantic perception → streaming event cognition → implicit 3D spatial cognition → predictive world modeling) is not formalized into measurable capabilities or consistent metrics; clear task definitions, score functions, and standardized evaluation protocols for each stage are needed.
- Predictive world modeling is framed conceptually (surprise-driven inference) but lacks formal objectives (e.g., predictive likelihood, epistemic vs. aleatoric uncertainty), benchmarks for model-based planning, and quantitative measures of “world-model quality.”
- Scope and realism of VSI-Super
- VSR relies on synthetic edits (inserted “surprising” objects) in indoor walkthroughs; there is no evaluation of edit realism, visual artifacts, or whether models exploit edit-specific cues rather than genuine spatial memory.
- Both VSR and VSC are confined to indoor, static environments (room tours); generalization to outdoor scenes, dynamic crowded spaces, egocentric activities, robotics, and multi-room navigation with loops and re-entries remains untested.
- The sequential recall in VSR uses four insertions; the scalability to higher event cardinality, richer event types (moving objects, occlusions, appearance/disappearance), and variable temporal spacing is not explored.
- VSC concatenates scenes but does not explicitly control for confounders (near-duplicates, distractor classes, occlusions, revisits, loop closures); robustness to these common long-horizon challenges is unknown.
- No human-performance baseline is reported for VSI-Super to establish difficulty and upper bounds; inter-annotator consistency and task reliability are not quantified.
- Benchmark design and measurement
- VSC uses mean relative accuracy without streaming error decomposition; time-resolved metrics (e.g., MAE/SMAPE over time, drift, lag, reset errors) and error taxonomies (over-/under-count, false merges/splits) would reveal failure modes more precisely.
- The resistance to “brute-force context expansion” is argued qualitatively; empirical studies varying context windows, summarization strategies, sampling rates, and memory budgets are missing to substantiate the claim.
- Blind and caption-only baselines are analyzed for existing benchmarks, but analogous baselines and ablations for VSI-Super (e.g., captioned streams, blind recall, language priors) are not provided.
- Data curation gaps in VSI-590K
- Pseudo-annotations are generated at the image level, discarding temporal continuity and multi-view geometry; the impact of video-level pseudo-annotations (SLAM, multi-view consistency, 3D tracks) on spatial cognition is untested.
- Template-generated QA may induce linguistic regularities and shortcut learning; the need for human-authored, adversarially diverse prompts (multi-lingual, colloquial, compositional variants) is not addressed.
- Dataset diversity is biased toward indoor, well-lit scenes; evaluation on long-tail geographies, clutter, motion blur, low light, and handheld jitter remains open.
- Annotation quality, noise profiles (detector/segmenter/reconstruction errors), and their downstream effects are not quantified; calibration methods (confidence filtering, consensus, denoising) are not explored.
- Model architecture and training uncertainties
- The S models’ video architecture is not clearly specified (frame-stacking with image encoders vs. native spatiotemporal encoders); the relative importance of temporal modeling choices (3D Conv, ViViT, TimeSformer) is unexamined.
- There is no ablation on visual encoder choice, connector capacity, or temporal/module-level designs (e.g., memory tokens, recurrent state, hierarchical pooling) that could directly target long-horizon spatial reasoning.
- Curriculum design and data mixing schedules (image→video, general→spatial) are only partially explored; optimal strategies for preventing catastrophic forgetting while maximizing spatial gains remain an open tuning problem.
- Compute budgets, training stability, and scaling laws (data vs. parameters vs. video length) for spatial supersensing are not analyzed; guidance on cost-effective scaling is missing.
- Predictive sensing proof-of-concept limitations
- The next-latent-frame predictor is described but lacks details on architecture, training objective, latent space, and integration with the MLLM; reproducibility and the cost-benefit trade-off are unclear.
- Surprise-driven memory allocation and event segmentation are proposed without quantitative comparisons to alternative mechanisms (e.g., learned saliency, reinforcement learning-based gating, compressive memory, novelty/curiosity formulations).
- The approach is evaluated only on VSI-Super; generalization to other long-horizon video tasks (tracking, physical reasoning, forecasting, navigation) and cross-domain robustness (egocentric, outdoor, multi-camera) is untested.
- Interaction with the LLM (interfaces, alignment between latent prediction errors and token-level memory, joint training vs. modular) is not specified; how surprise signals propagate to reasoning remains an open integration question.
- Evaluation breadth and baselines
- S models are said to “fall short on VSI-Super,” but detailed scores, per-duration breakdowns, and comparisons to other open-source baselines are missing; statistical significance and variance across seeds are not reported.
- Gemini-2.5 results illustrate counting saturation but do not include broader baselines (other proprietary/open models, tool-augmented agents, retrieval methods); conclusions about paradigm limits would benefit from a more comprehensive baseline suite.
- The analysis of language priors in benchmarks uses Gemini captions; data/edit leakage, caption quality variance, and potential bias introduced by the captioner are not controlled.
- From perception to action and multimodality
- The paper focuses on perception and recall/counting but does not study how predictive spatial world models support downstream tasks (planning, navigation, manipulation) or decision-making under uncertainty.
- Audio and other modalities (IMU, depth, event cameras) are absent; whether multimodal signals improve event segmentation, 3D inference, and memory is an open research direction.
- Robustness, safety, and ethics
- Robustness to adversarial edits, spurious correlations, and domain shifts in long streams is not evaluated; stress tests (occlusion bursts, camera jitter, lighting changes) could reveal brittleness.
- Use of web-sourced room tours raises potential licensing and privacy concerns; dataset documentation (provenance, consent, deduplication, train/test leakage checks) is not detailed.
- Theory and foundations
- The relation of surprise-driven predictive sensing to established frameworks (predictive coding, free-energy minimization, Bayesian filtering) is not formalized; a mathematically grounded theory linking error signals to memory and segmentation decisions is needed.
- Clear definitions of “events” and “latent states” in video, and how they map to symbolic reasoning, are missing; formal semantics for event boundaries and state abstraction would enable rigorous evaluation and training.
Practical Applications
Practical Applications of “Cambrian-S: Towards Spatial Supersensing in Video”
Below are concrete, real-world applications derived from the paper’s findings, methods, and innovations (VSI-Super, VSI-590K, Cambrian-S models, and predictive sensing via “surprise”). Applications are grouped by deployability, with sector tags, example tools/workflows, and assumptions or dependencies.
Immediate Applications
- Spatial-sensing evaluation suite for MLOps and R&D
- Sectors: software/AI vendors, academia, enterprise AI
- What: Integrate VSI-Super (VSR/VSC) into continuous evaluation to stress-test long-horizon spatial cognition and detect overreliance on text priors. Use the diagnostic protocol (multi-frame vs single-frame vs captions) to audit benchmark validity and task design.
- Tools/workflows: Add VSR/VSC runs to CI/CD; model audits using “caption-only baseline” checks; internal leaderboards segmented by spatial tasks.
- Assumptions/dependencies: Access to long-form video pipelines; dataset licensing; compute for multi-hour sequences.
- Targeted spatial instruction-tuning to boost existing video models
- Sectors: software/AI vendors, robotics labs, academia
- What: Use VSI-590K to fine-tune existing MLLMs for measurable gains on spatial tasks (counting, relative/absolute direction and distance, room/object sizes).
- Tools/workflows: SFT recipes from the paper; staged training (image IT → video IT → spatial SFT); curriculum mixing general video data to avoid generalization loss.
- Assumptions/dependencies: Domain shift management; data quality controls; modest GPU budget; adherence to the paper’s mixing ratios.
- Surprise-driven event segmentation to compress streaming video analytics
- Sectors: cloud video analytics, security/surveillance, media platforms
- What: Add a lightweight next-latent-frame predictor to compute “surprise” (prediction error) and gate memory allocation and segmentation, reducing token/context load and improving retrieval.
- Tools/workflows: A “surprise-gate” middleware between frame ingest and LLM; retention policies for “high-surprise” segments; long-stream summarization by events.
- Assumptions/dependencies: Calibrating surprise thresholds; model drift monitoring; privacy-by-design storage of selected segments.
- Retail shelf and warehouse inventory counting across multi-room walkthroughs
- Sectors: retail, logistics, supply chain
- What: Deploy VSC-like continual counting for audits over long tours (stores, DC aisles). Track re-entries and scene changes while maintaining cumulative counts.
- Tools/workflows: Mobile video walkthrough app; continual counter with deduplication; dashboards showing count evolution over time.
- Assumptions/dependencies: Camera coverage and occlusions; SKU detection reliability; store layout variability; domain adaptation from indoor datasets.
- Streaming anomaly detection via “surprise” for security and operations
- Sectors: security/surveillance, facilities ops, manufacturing
- What: Flag unusual insertions or out-of-place objects/events in continuous streams (akin to VSR needle edits). Prioritize alerts and storage based on surprise.
- Tools/workflows: On-prem agent that ranks clips by surprise; human-in-the-loop triage; integration with VMS.
- Assumptions/dependencies: False-positive control; context for “normality” in specific sites; privacy and retention policies.
- Sports and broadcast analytics: continual counting and highlight extraction
- Sectors: sports tech, media
- What: Count events across long broadcasts (e.g., passes, shots, corner kicks) and segment surprising plays for highlight reels using predictive error spikes.
- Tools/workflows: Long-horizon counting service; “surprise highlight” extractor; automated summaries aligned with editing tools.
- Assumptions/dependencies: Model adaptation to sport-specific appearance/motion; rights management for broadcast content.
- Robotics research data pipelines with spatial QA generation
- Sectors: robotics, embodied AI, academia
- What: Use the pseudo-annotation pipeline to convert unannotated robot egocentric video into spatial QA pairs (counts, directions, distances) for SFT.
- Tools/workflows: Batch pipeline using detection/segmentation/3D recon; quality filters; downstream QA templating.
- Assumptions/dependencies: Noise tolerance of pseudo labels; sim-to-real transfer; accuracy of monocular 3D recon under domain shift.
- Long-video summarization for lifelogging and ops review
- Sectors: consumer apps, enterprise compliance
- What: Summarize hours-long footage into event-structured storyboards with counts and spatial metadata (where/when/what changed).
- Tools/workflows: Surprise-driven segmenter; queryable memory index; keyword + spatial Q&A interface.
- Assumptions/dependencies: On-device or edge compute; PII redaction; user consent and storage limits.
- Benchmark governance and dataset design audits
- Sectors: academia, policy groups, AI ethics teams
- What: Apply the paper’s diagnostic methodology to assess whether “video benchmarks” genuinely require visual sensing vs language priors; recalibrate benchmark suites accordingly.
- Tools/workflows: Public scorecards showing “multi-frame vs caption-only” gaps; benchmark curation checklists; replication kits.
- Assumptions/dependencies: Community buy-in; standardization groups adopting test protocols.
- Upgrading base models for spatial cognition without losing generality
- Sectors: foundation model teams, integrators
- What: Follow the staged recipe (A1→A4) to get strong video understanding, then spatial SFT; mix in general video IT to preserve general capabilities while improving VSI-Bench performance.
- Tools/workflows: Training curricula; checkpoint selection by both general and spatial metrics; inference-time memory policies.
- Assumptions/dependencies: Balanced data mixing; robust early stopping; multi-metric evaluation in CI.
Long-Term Applications
- Supersensing home robots with predictive world models
- Sectors: robotics, smart home
- What: Agents that anticipate, select, and organize experience—tracking objects across rooms, remembering placements, and predicting future states to plan actions.
- Tools/workflows: Surprise-driven memory managers; implicit 3D world-model backends; task policies conditioned on predicted latent states.
- Assumptions/dependencies: Reliable 3D spatial cognition across clutter; safety and certification; robust on-device compute.
- AR glasses with spatial memory (“Where did I leave my keys?”)
- Sectors: consumer electronics, wearables
- What: Always-on spatial memory, event-segmented lifelogging, and retrieval via predictive sensing—recalling object placements across days.
- Tools/workflows: On-device event detection; privacy-preserving “memory vault”; natural-language spatial queries with visual grounding.
- Assumptions/dependencies: Battery/thermal constraints; privacy/regulatory compliance; multi-user disambiguation.
- Predictive perception for autonomous driving and mobile autonomy
- Sectors: automotive, drones, delivery robots
- What: Anticipate latent future frames/states to guide attention and planning (e.g., occluded pedestrian emergence, traffic flow changes).
- Tools/workflows: Surprise-gated sensor fusion; uncertainty-aware planners; event-structured map memory.
- Assumptions/dependencies: Multi-sensor fusion (LiDAR/radar/cameras); safety-critical validation; ODD generalization.
- Smart-city analytics at scale with continual counting and anomalies
- Sectors: public sector, transportation, urban planning
- What: City-scale flow counting and anomaly detection over multi-camera, multi-hour streams; resource allocation based on event priors.
- Tools/workflows: Federated surprise indices; privacy-preserving aggregation; policy dashboards for mobility and safety.
- Assumptions/dependencies: Privacy/PII governance; cross-camera re-identification; lawful basis for processing.
- Clinical and eldercare monitoring with anticipatory alerts
- Sectors: healthcare
- What: Long-horizon monitoring for falls, wandering, equipment misplacement; predictive alerts triggered by surprise and spatial context.
- Tools/workflows: On-prem hospital agent; clinician-facing timeline with event summaries; integration with EHR.
- Assumptions/dependencies: Clinical trials, bias and safety audits; HIPAA/GDPR compliance; edge compute and uptime.
- Industrial process oversight and predictive maintenance
- Sectors: manufacturing, energy
- What: Monitor assembly lines or substations; detect “out-of-place” states, count parts across stages, predict deviations before faults.
- Tools/workflows: Event logs aligned with PLC/SCADA; root-cause triage using event chains; maintenance scheduling.
- Assumptions/dependencies: Camera placement and calibration; integration with MES; domain-specific retraining.
- Education and training: real-time procedural guidance with spatial understanding
- Sectors: education, workforce training
- What: Lab or shop-floor assistants that track multi-step procedures across time and space, prompting when steps are missed or out of order.
- Tools/workflows: Procedure graphs tied to event segments; step counters and spatial checks; retrospective performance feedback.
- Assumptions/dependencies: Reliable recognition of equipment and gestures; varied lighting and occlusion handling; teacher/admin consent and privacy.
- Standard-setting for long-horizon AI evaluation in procurement and regulation
- Sectors: policy, standards bodies, public procurement
- What: Require VSI-Super–style tests for long-context, spatial, and predictive competencies in AI tenders; publish “surprise sensitivity” and scaling behavior.
- Tools/workflows: Conformance test suites; scored public registries; independent lab certifications.
- Assumptions/dependencies: Multi-stakeholder consensus; dataset transparency; mechanisms to prevent benchmark gaming.
- Multi-modal predictive sensing (beyond RGB) for critical infrastructure
- Sectors: utilities, transportation, mining
- What: Fuse thermal, acoustic, and vibration with video; use surprise across modalities to focus memory and inspection.
- Tools/workflows: Cross-modal latent prediction; unified event timelines; human-in-the-loop remediation.
- Assumptions/dependencies: Sensor sync and calibration; ruggedized hardware; domain labeling for rare events.
- Personal lifelogging and retrieval with strong privacy guarantees
- Sectors: consumer software
- What: Organize lifelong video into meaningful, retrievable events (who/what/where) with spatial queries and counts, e.g., “How many times did I use the drill this month?”
- Tools/workflows: On-device predictive segmenter; encrypted event index; local LLM for query answering.
- Assumptions/dependencies: Differential privacy; user controls and data minimization; efficient on-device inference.
Cross-Cutting Assumptions and Dependencies
- Robustness and generalization: Many applications require domain adaptation from indoor scans to outdoor, industrial, or sports settings; handling occlusions, lighting, and motion blur is critical.
- Privacy, security, and compliance: Long-horizon video memory raises non-trivial consent, retention, and PII challenges; policy-compliant storage and on-device processing will be pivotal.
- Compute and efficiency: Surprise-driven memory can reduce token/context costs, but next-latent prediction still needs efficient architectures and calibration.
- Data quality: VSI-590K shows the value of annotated real and simulated data; pseudo-annotations are useful but require quality gating to avoid training on noise.
- Evaluation culture: Adoption of VSI-Super–style tests and the paper’s diagnostic methodology is essential to avoid illusory progress from language priors or brute-force context scaling.
Glossary
The following alphabetical list collects advanced domain-specific terms from the paper, each with a concise definition and a verbatim usage example from the text.
- 3D instance-level annotations: Detailed labels for individual object instances in 3D scenes, enabling precise spatial reasoning and supervision. "provide 3D instance-level annotations"
- 3D reconstruction model: A model that infers 3D structure from 2D images or video. "and 3D reconstruction model~\cite{wang2025vggt} to generate pseudo-annotated images"
- Context window: The maximum amount of input (tokens/frames) a model can attend to at once. "exceed any fixed context window."
- Continual counting: Counting objects cumulatively across time, scenes, and viewpoints in a continuous stream. "continual counting across changing viewpoints and scenes."
- Continual sensing: Always-on processing of streaming inputs with memory and proactive interpretation. "through continual sensing, memory architectures, and proactive answering"
- Embodied simulators: Interactive simulation environments used to generate agent-centric trajectories and data. "we utilize embodied simulators to procedurally generate spatially grounded video trajectories"
- Event segmentation: Partitioning continuous input into meaningful temporal units or events. "event segmentation, breaking unbounded streams into meaningful chunks."
- Implicit 3D spatial cognition: Inferring the underlying 3D world from 2D video without explicit geometry. "Implicit 3D spatial cognition: understanding video as projections of a 3D world."
- Instruction-tuning: Supervised fine-tuning on instruction–response examples to align model behavior. "a spatially focused instruction-tuning corpus"
- Long-context: Using very large context lengths (e.g., hundreds of thousands of tokens) to process extended inputs. "brute-force long context"
- Long-horizon: Requiring reasoning over extended temporal durations or many events. "targets long-horizon spatial observation and recall."
- Mean Relative Accuracy (MRA): An evaluation metric normalizing accuracy relative to ground-truth magnitude. "we report results using the mean relative accuracy () metric"
- Multi-hop reasoning: Reasoning that chains multiple inference steps to reach an answer. "effectively a multi-hop reasoning task"
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities, such as text and images/video. "multimodal LLMs (MLLMs) have advanced rapidly"
- Needle-in-a-haystack (NIAH): A stress test requiring retrieval of small, specific information from very long context. "parallels the needle-in-a-haystack (NIAH) test"
- Next-latent-frame prediction: Predicting the next video frame in a latent (compressed) representation space. "built upon self-supervised next-latent-frame prediction."
- Post-training: Fine-tuning or alignment steps applied after pretraining to adapt capabilities. "without any video post-training"
- Predictive sensing: Using predictions and their errors to guide what to attend to, remember, and segment in streams. "we propose predictive sensing as a first step toward a new paradigm."
- Predictive world modeling: Building internal models that anticipate future states and organize perception. "Predictive world modeling: the brain makes unconscious inferences"
- Procedural generation: Algorithmically producing content or data via rules rather than manual creation. "procedurally generate spatially grounded video trajectories"
- Pseudo-annotated images: Images labeled automatically by models (e.g., detection/reconstruction), not by humans. "generate pseudo-annotated images"
- Self-supervised learning: Learning from intrinsic structure (e.g., predicting future frames) without explicit labels. "self-supervised next-latent-frame prediction."
- Spatial supersensing: The capability to perceive, model, and predict the 3D world from continual sensory input. "spatial supersensing requires models that not only see but also anticipate, select, and organize experience."
- Spatially grounded: Explicitly tied to the geometry and layout of the physical environment. "a family of spatially-grounded video MLLMs."
- Spatiotemporal: Involving both spatial and temporal dimensions. "arbitrarily long spatiotemporal videos"
- Streaming event cognition: Maintaining memory and reasoning over continuous input streams to interpret events. "Streaming event cognition: processing live, unbounded streams while proactively interpreting and responding to ongoing events."
- Surprise (prediction error): The discrepancy between predicted and observed inputs used to drive memory and learning. "leverages surprise (prediction error) to drive memory and event segmentation."
- Tokenization: Converting raw inputs (e.g., frames) into discrete tokens for model processing. "frame-by-frame tokenization and processing are unlikely to be computationally viable as a long-term solution."
- Vision-language connector: The module that maps visual features into the LLM’s embedding space. "For the vision-language connector, we adopt a simple two-layer MLP"
- Visual-spatial intelligence (VSI): The ability to understand visual scenes, spatial relations, and geometry. "VSI (VSI stands for visual-spatial intelligence)"
Collections
Sign up for free to add this paper to one or more collections.