- The paper presents open-source chiplet architectures (Occamy, Ramora, and Ogopogo) that bridge the gap between openness and high-performance, achieving competitive FPU utilization and energy efficiency.
- It details a transition from crossbar interconnects to mesh-based NoCs, reducing area overhead and boosting bandwidth while ensuring scalability for HPC and AI workloads.
- The study extends openness beyond RTL to encompass simulation, EDA flows, and PDK integration, addressing key barriers for fully transparent silicon design.
Introduction and Motivation
The work presents a progressive roadmap for the realization of open-source chiplet-based RISC-V architectures optimized for high-performance computing (HPC) and AI applications. With the stagnation of traditional scaling, contemporary workloads in HPC and AI exhibit increasing memory and compute demands that exceed the capabilities of monolithic dies. The transition to chiplet-based 2.5D integration architectures is driven by the need for higher yield, scalability, and advanced connectivity, all while upholding the principles of openness, modularity, and design verifiability characteristic of open-source hardware. However, a pronounced tradeoff arises between openness and achievable performance, as system complexity and attainable efficiency tend to decrease at higher degrees of openness.

Figure 1: The openness-performance tradeoff as evidenced by published open-source systems, highlighting the performance gap versus state-of-the-art proprietary silicon.
The authors address these trends by introducing three generations of open-source chiplet-based manycore designs — Occamy, Ramora, and Ogopogo — and exploring the extension of openness across RTL, simulation, EDA tooling, PDK integration, and off-die PHYs.
Occamy: Silicon-Proven Dual-Chiplet RISC-V Manycore
Occamy constitutes the first open-source, silicon-proven dual-chiplet manycore system in a 12nm FinFET process, integrating 432 RV32G compute cores (featuring SIMD FPUs with FP8/FP16/FP64 support and extensive ISA extensions). The cores are organized in clusters with shared scratchpad memory (SPM), L1 caches, and a sophisticated DMA subsystem enabling efficient tiling and double-buffered data movement. Centralized crossbar interconnects couple compute clusters, host domain, and I/O, but pose scalability and area overhead limitations as system size increases.
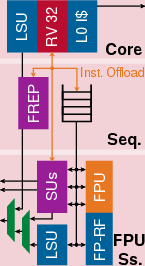
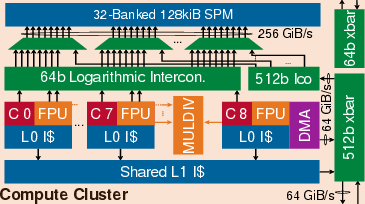

Figure 2: Architectural layout of a worker core, emphasizing SIMD FPU and ISA extensions.
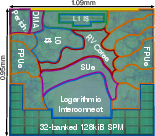

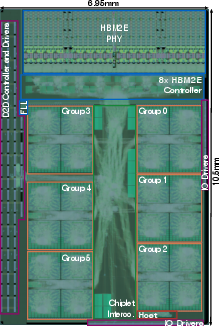
Figure 3: Cluster formation — eight cores plus DMA controller with shared SPM and cache resources.
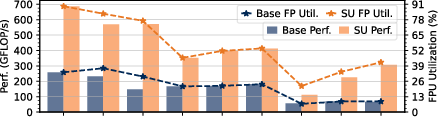
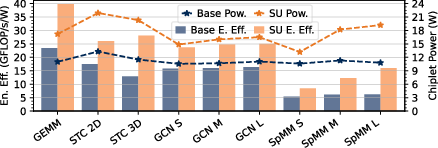
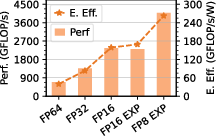
Figure 4: Benchmark results for double-buffered FP64 workloads, demonstrating high FPU utilization and competitive energy efficiency.
Strong numerical results underline Occamy’s architectural efficacy. On dense GEMM, Occamy achieves 89% FPU utilization and 686 GFLOP/s at 39.8 GFLOP/s/W. On sparse workloads (SpMM, GCN layers), SU acceleration yields leading FPU utilization figures (42–83%), with outperformances up to 11x node-normalized area efficiency over commercial competitors.
Despite these strengths, hierarchical crossbar interconnects consume >30% domain area, restrict off-die bandwidth, and impede scaling, motivating exploration of mesh-based NoC solutions.
Ramora: Scalable 2D Mesh NoC Integration
Ramora builds upon Occamy’s cluster architecture but transitions to a wide-link 2D mesh NoC (FlooNoC), drastically reducing interconnect overhead, improving bandwidth, and elevating scalability. Cluster-to-router integration ensures direct tiling into a mesh fabric, which linearly scales with system size and mitigates congestion and area-growth issues typical of crossbar designs.
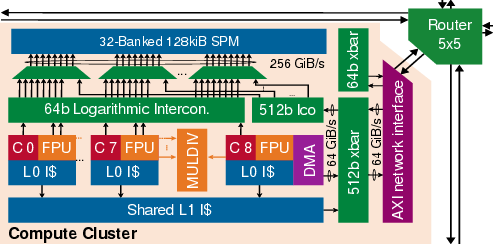

Figure 5: Ramora cluster tile with integrated NoC network interface and router.
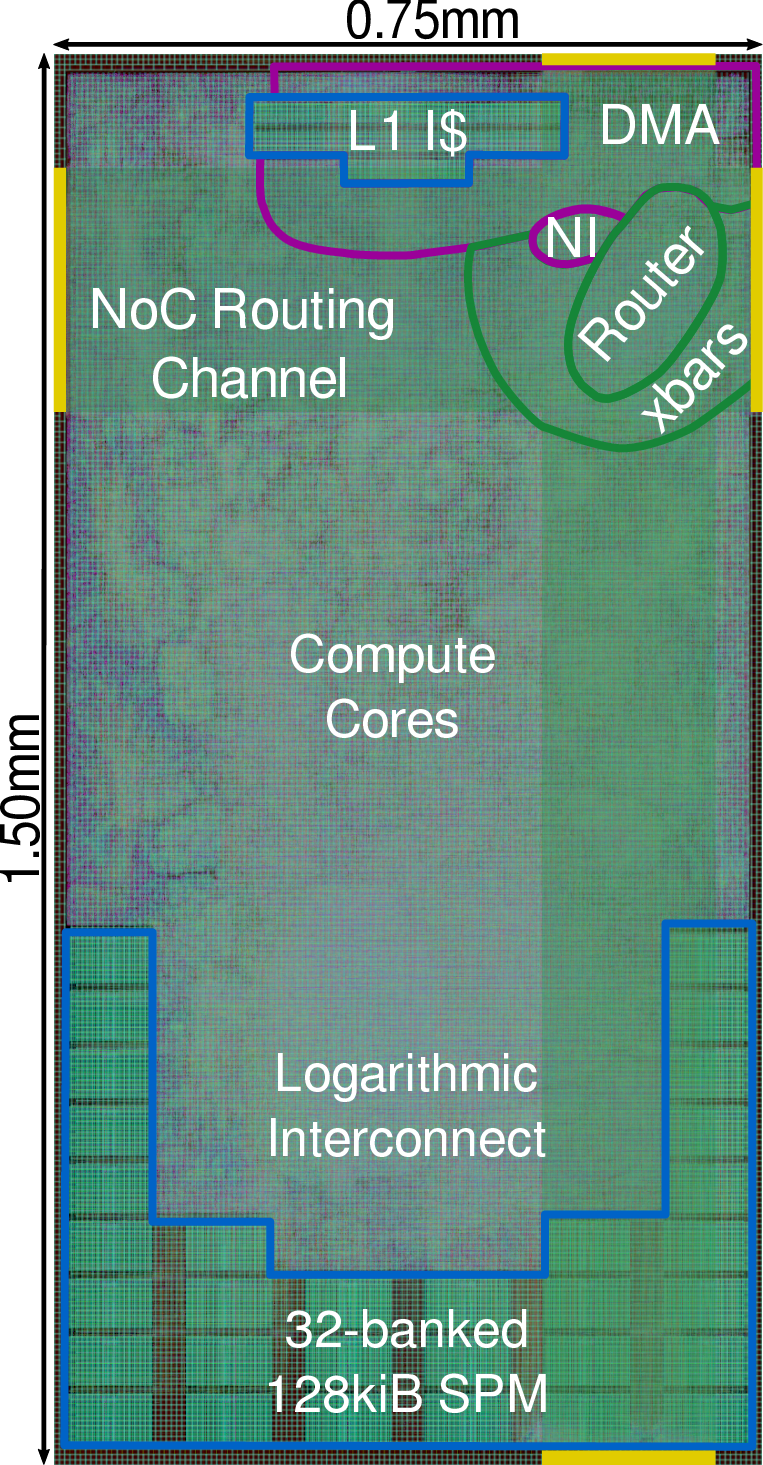
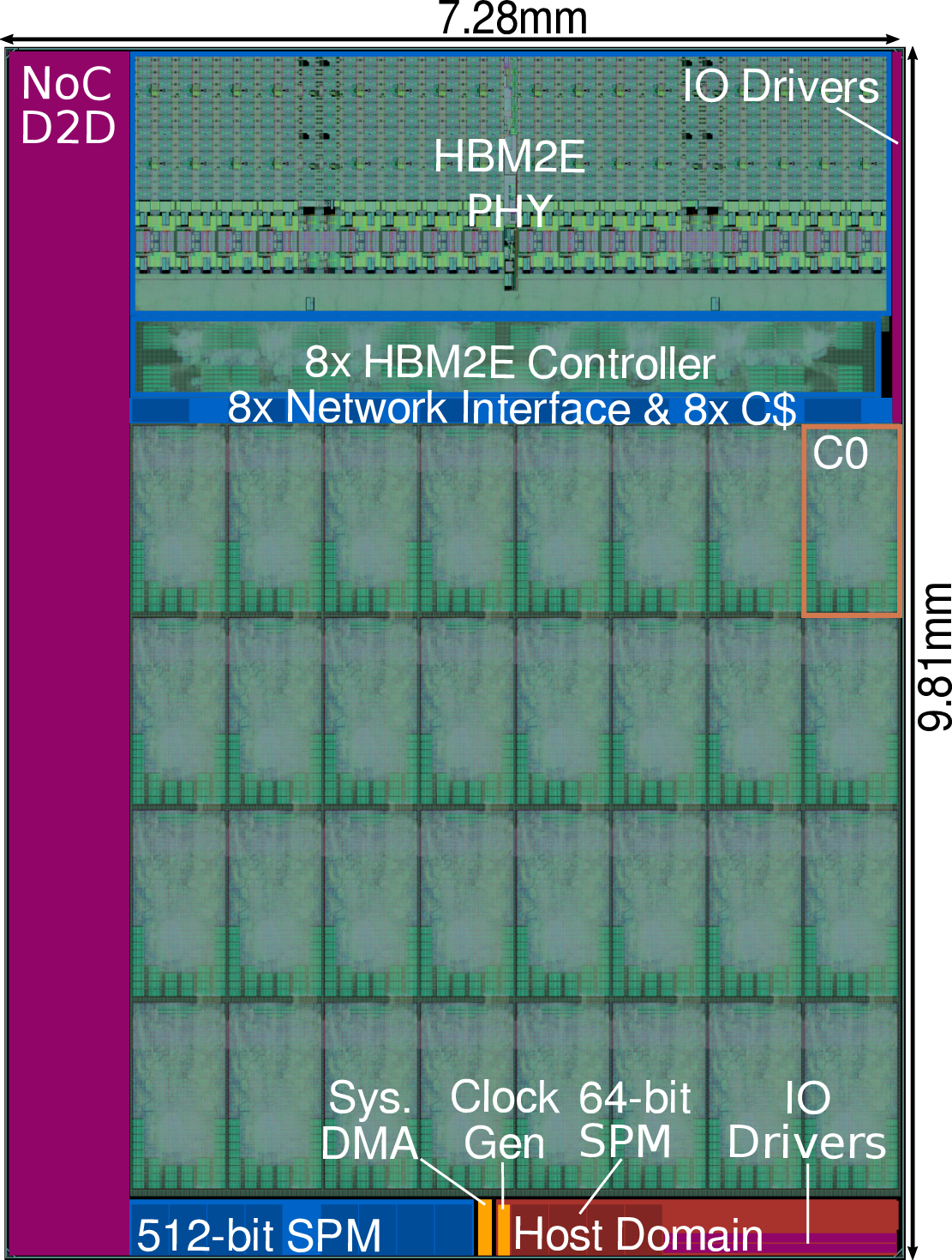
Figure 6: Full cluster tile layout and chiplet integration within Ramora’s mesh topology.
The mesh’s edge bandwidth enables an upgraded D2D link: Ramora achieves a 16× wider D2D bandwidth (1.04 Tb/s) than Occamy while maintaining chiplet area. HBM2E bandwidth utilization peaks at 96.6%, and inter-cluster latency remains competitive with crossbar-centric designs (<8.4% difference under load). Ramora’s 32 clusters operate at 1.26 GHz, providing 1.29 DP-TFLOP/s and 43% greater compute density than Occamy.
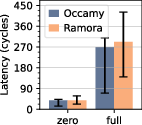
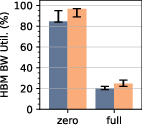
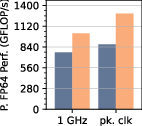
Figure 7: Comparative on-chip latency across mesh and crossbar interconnects, documenting average, minimum, and maximum values.
Ogopogo: Quad-Chiplet Architecture and Data Movement Extensions
Ogopogo extrapolates Ramora’s mesh to a quad-chiplet, quad-HBM3 system in TSMC 7nm, yielding a concept architecture with 10.3 DP-TFLOP/s and compute density (41.1 DP-GFLOP/s/mm²) exceeding Nvidia’s B200 GPU when normalized to process node.
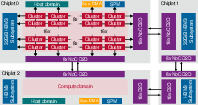
Figure 8: Ogopogo’s quad-chiplet architecture with expanded mesh, HBM3 interfaces, and advanced D2D connectivity.
Ogopogo introduces three notable hardware acceleration extensions:
- In-router collectives: Augments mesh routers with primitives for efficient multicast, broadcast, and barrier implementations, achieving functionality with minimal (<10%) area overhead.
- In-stream DMA operations: Integrates vector units capable of element-wise and reduction operations directly within DMA engines, enabling up to 32× speed-up in scaling and 12× in reductions, with sub-100 kGE area additions.
- Packed irregular streams: Efficient packing/unpacking of indexed data for scatter-gather operations leverages sparsity and improves effective bandwidth (up to 4.8×, dependent on access patterns).
Ogopogo demonstrates that architectural specializations and efficient data movement can combine with open-source design to approach—and in node-normalized terms exceed—state-of-the-art commercial GPU densities.
Openness Beyond RTL: Simulation, EDA, PDKs, and Off-Die PHYs
Current open-source chiplet designs primarily provide synthesizable logic-RTL. Methodological extension into simulation, EDA, PDK, and PHY domains is critical for further transparency and verifiability:
- Simulation: Verilator and Icarus Verilog offer open simulation, but lack SOC-scale SystemVerilog testbench and gate-feature completeness, though improvements are ongoing.
- EDA Flows: Synthesis (Yosys) and place-and-route (OpenROAD) enable open flows at mature nodes; gaps in QoR persist relative to commercial tools but are narrowing. Demonstrated designs in 130nm (Basilisk) and ongoing work in 22nm show promise.
- Open PDKs: Availability at 55–180nm permits demonstrator designs but remains insufficient for high-complexity chiplets; progress depends on advanced foundries open-sourcing PDKs.
- Off-die PHYs: Mixed-signal DRAM/D2D PHYs are bottlenecks for full openness, as they are tied to process and tooling, but digital-only alternatives and analog flows (Efabless) provide limited possibilities.
Remaining challenges in PDK and PHY openness present the principal barriers for end-to-end open-source chiplet designs.
Implications and Future Outlook
The presented roadmap—Occamy, Ramora, and Ogopogo—demonstrates that open-source HPC/AI chiplet designs can closely approach the compute density, energy efficiency, and memory bandwidth of state-of-the-art commercial silicon architectures, particularly when leveraging mesh-based NoCs and targeted hardware accelerators. Quantitative results establish leading regular and irregular workload performance within the open-source domain. Future improvements will be contingent on broader PDK availability, strengthened open EDA and simulation tools, and innovation in open PHY design. The practical implication is a potential paradigm shift toward composable, verifiable, barrier-free HPC/AI system assembly, decoupled from proprietary IP constraints.
Conclusion
This work illustrates the technical and organizational evolution toward high-performance, open-source chiplet-based RISC-V platforms for HPC and AI, systematically advancing from Occamy through Ramora to Ogopogo and addressing the openness-performance gap. Numerical benchmarks indicate competitive FPU utilization (up to 89%), compute density exceeding Nvidia’s B200 GPU by 19% when node-normalized, and bandwidth/configurability advantages attributed to mesh NoC integration and data movement enhancements. The extension of openness beyond logic-RTL remains impeded by proprietary tool and process constraints; overcoming these will profoundly impact trusted, reproducible silicon deployment for scientific and industrial research applications.