- The paper introduces a zero-shot structure-aware denoising method that enhances synthetic video realism by preserving multi-level structural and semantic fidelity.
- It employs a dual-prompt diffusion framework with DDIM inversion and multi-modal ControlNet conditioning to effectively maintain safety-critical details in simulation videos.
- Quantitative experiments show improved LPIPS scores and object consistency, establishing a new benchmark for sim-to-real video domain adaptation.
Zero-shot Structure-aware Denoising for Enhancing Synthetic Video Realism
Introduction and Motivation
Synthetic video data generated from simulators plays a pivotal role in scaling training pipelines for autonomous vehicles, especially for infrequent edge-case scenarios. However, a persistent domain gap issues between synthetic and real-world data introduces significant biases, impeding robust transfer learning. Traditional GAN-based video-to-video translation approaches have suffered from low resolution, poor object consistency, and temporal artifacts. Recent advances in diffusion models and controllable architectures such as ControlNet have greatly improved photorealism and diversity, but often compromise critical semantic and structural details—particularly for small, safety-relevant elements like traffic lights and road signs—due to reliance on external simulator-generated conditions or prompts without directly encoding video appearance information.
This paper introduces a zero-shot, structure-aware denoising pipeline to robustly enhance the visual realism of simulator-generated videos, centering on the preservation of multi-level structural consistency and semantic fidelity across both spatial and temporal domains, without domain-specific fine-tuning.

Figure 1: Enhanced videos by the proposed structure-aware denoising method, showing strong structural consistency and state-of-the-art photorealism for small, safety-relevant objects in driving scenarios.
Methodological Contributions
The proposed framework builds on Cosmos-Transfer1—a state-of-the-art DiT-based video diffusion model with Video ControlNet extensions for multi-modal conditioning. Crucially, it introduces a DDIM-style deterministic inversion step to map a synthetic input video into a latent code structurally tied to the original spatial and temporal content. This is achieved by:
- Generating dual prompts via a video-LLM: one (‘inversion prompt’) descriptive of the synthetic video, the other (‘positive prompt’) curated for real-domain photorealism.
- Extracting structure-focused spatial conditioning maps (depth, semantic segmentation, Canny edges) via auxiliary perception models, decoupling from simulator dependencies.
- Running a DDIM inversion to implant global spatiotemporal structure into the latent space, followed by a forward guided denoising process that conditions on both the positive (realistic) text prompt and the original spatial maps.
This tightly couples the resulting video to fine-grained appearance, structure, and motion from the source simulation while achieving a realistic visual style representative of natural driving data.
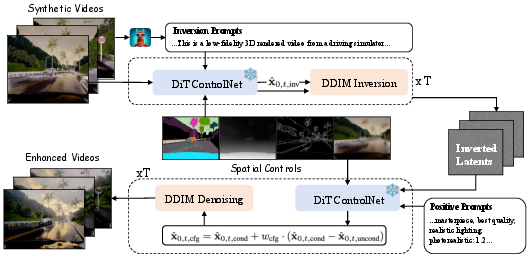
Figure 2: Pipeline overview—DDIM inversion and ControlNet-based conditioning ensure structure-aware, photorealistic synthesis from synthetic videos.
In the denoising phase, classifier-free guidance (CFG) modulates the trade-off between semantic preservation and stylistic realism. The method’s efficacy is rigorously evaluated both qualitatively and quantitatively across image-based perceptual similarity (LPIPS), object-centric feature consistency (using DINOv2/CLIP), and video-level temporal and dynamic metrics (VBench).
Experimental Evaluation
Experiments are conducted on a large CARLA-based synthetic video dataset (900 sequences, diverse weather/lighting), with further generalization demonstrated on GTA V content.
Qualitatively, the method delivers visually superior results for small safety-critical elements—traffic lights retain correct color/appearance throughout a sequence, and roadside signs display both structural integrity and temporal coherence absent in competitive baselines.

Figure 3: Qualitative results—maintaining photorealism and structural consistency under diverse outdoor conditions.

Figure 4: Temporal alignment example—changes in traffic light phases and car shadows are accurately maintained alongside photorealistic refinement.

Figure 5: Additional examples on GTA dataset—robust enhancement across varied outdoor visual scenarios.
Quantitatively, the method outperforms leading baselines (WAN2.1 VACE, Cosmos-Transfer1) on small object alignment (DINO/CLIP), perceptual similarity, and maintains competitive photorealism. Notably, LPIPS is reduced to 0.3683 (lower is better), and object consistency scores are improved, confirming superior semantic and spatial alignment. The ablation studies demonstrate that the synergy between DDIM inversion and multi-modal ControlNet conditioning is essential; omitting structure-aware components or reducing conditions leads to pronounced drops in both realism and object alignment. Moreover, an optimal CFG value (7) is empirically determined to best balance stylistic transfer and source identity retention.
Implications and Future Directions
The framework provides a principled methodology for simulator-to-real video domain adaptation, crucial for downstream autonomous vehicle learning, safety validation, and evaluation. By eliminating the need for simulator-backend modifications or dataset-specific retraining, it enables practical, large-scale photorealistic augmentation of synthetic driving data, greatly improving generalization for perception or planning models trained in a sim2real regime.
Limitations are identified: fixed window sizes due to base model constraints necessitate chunk-based processing for long videos, with possible temporal seams; sensitivity to prompt design may occasionally yield minor artifacts. Future work should seek to (1) extend window length efficiently; (2) further examine downstream benefits for autonomous policy training; and (3) improve robustness to uncontrolled prompt-video mismatches.
Conclusion
This work establishes a novel, zero-shot structure-aware denoising paradigm for synthetic video realism enhancement, bridging the sim-to-real gap with strong semantic and structural fidelity. The methodology proves highly effective for safety-critical object preservation and delivers state-of-the-art perceptual realism—addressing a fundamental barrier in automated driving research and beyond. The proposed evaluation protocol for small object alignment further sets a benchmark for future synthetic video generation and enhancement studies.
Reference: “Zero-shot Synthetic Video Realism Enhancement via Structure-aware Denoising” (2511.14719)