- The paper introduces SimpleVLA-RL, an outcome-based reinforcement learning framework that boosts long-horizon planning and data efficiency in VLA models.
- It employs Group Relative Policy Optimization with dynamic sampling and extended PPO clipping to improve performance by up to 80% across benchmarks.
- The framework demonstrates robust sim-to-real transfer and emergent behaviors like 'pushcut', underscoring its potential for autonomous robotics.
SimpleVLA-RL: Reinforcement Learning for Scalable Vision-Language-Action Model Training
Introduction
SimpleVLA-RL introduces a reinforcement learning (RL) framework specifically designed for Vision-Language-Action (VLA) models, addressing two central challenges in the field: the scarcity of large-scale, high-quality demonstration data and the limited generalization of VLA models to out-of-distribution tasks. By leveraging outcome-based RL and scalable infrastructure, SimpleVLA-RL demonstrates substantial improvements in long-horizon planning, data efficiency, and sim-to-real transfer, outperforming supervised fine-tuning (SFT) and state-of-the-art (SoTA) baselines across multiple benchmarks.
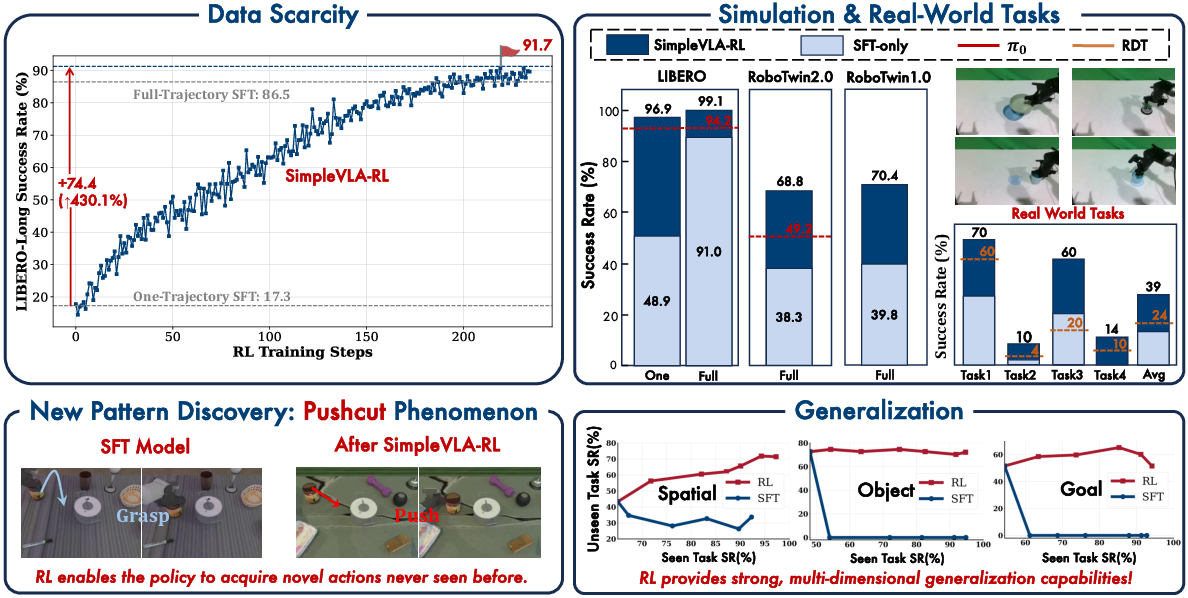
Figure 1: Overview of SimpleVLA-RL. The framework improves long-horizon planning under data scarcity, outperforms SFT in simulation and real-world tasks, and reveals emergent behaviors such as "pushcut".
Methodology
SimpleVLA-RL adapts the RL paradigm to the VLA setting, where the state comprises multimodal observations (visual, proprioceptive, and language), and the action space consists of robot control commands (e.g., end-effector deltas or joint targets). The environment provides binary outcome rewards (success/failure), and the policy is updated using Group Relative Policy Optimization (GRPO), which normalizes advantages within trajectory groups and employs PPO-style clipping.
VLA-Specific Trajectory Sampling
Unlike LLMs, VLA models require closed-loop interaction with the environment, as each action alters the state and subsequent observations. SimpleVLA-RL implements parallelized, environment-synchronous rollout, generating diverse trajectories via action token sampling. This is critical for efficient exploration and stable policy updates.
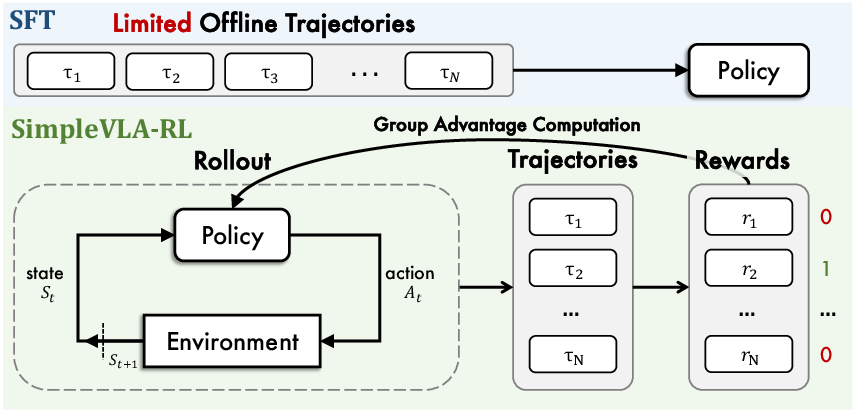
Figure 2: Overview of SimpleVLA-RL. The system integrates parallel environment rendering, VLA-specific rollout, and optimized loss computation for scalable RL.
Outcome Reward Modeling
The framework employs a simple, scalable binary reward: a trajectory receives a reward of 1 if the task is completed successfully, and 0 otherwise. This outcome-level reward is propagated uniformly to all action tokens in the trajectory, avoiding the need for dense, hand-crafted process rewards and enabling broad applicability across tasks and environments.
Exploration Enhancements
To address the challenge of vanishing gradients in critic-free RL (e.g., GRPO) when all sampled trajectories share identical rewards, SimpleVLA-RL introduces three key exploration strategies:
- Dynamic Sampling: Only trajectory groups with mixed outcomes (both successes and failures) are used for policy updates, ensuring non-zero advantage estimates and stable gradients.
- Clip Higher: The PPO/GRPO clipping range is extended (e.g., [0.8, 1.28]) to allow greater probability increases for low-likelihood actions, promoting exploration.
- Higher Rollout Temperature: The action sampling temperature is increased (e.g., from 1.0 to 1.6) to generate more diverse trajectories during rollout.
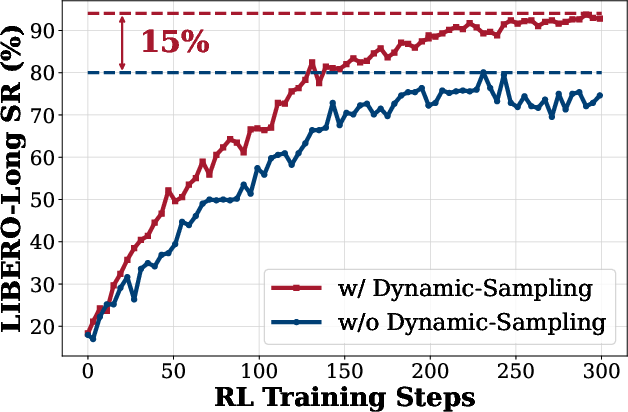
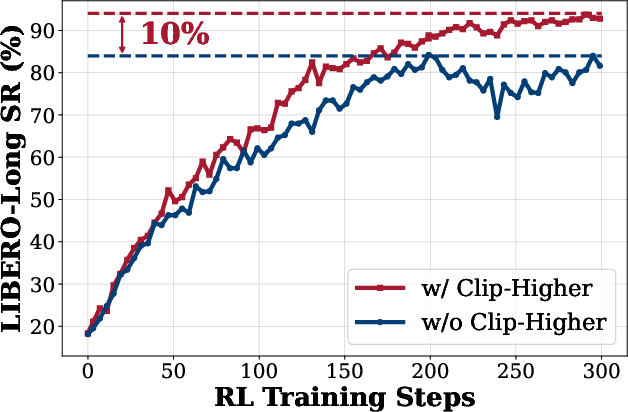
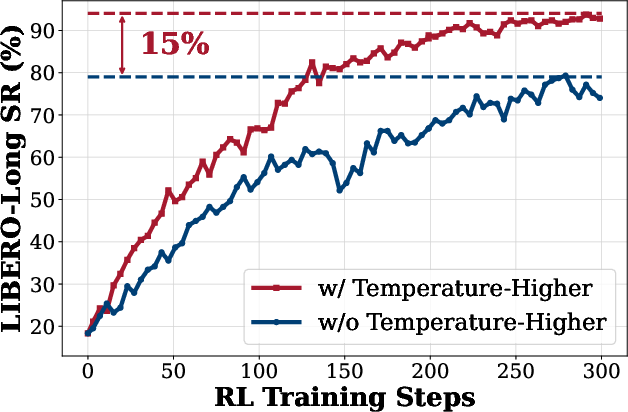
Figure 3: Dynamic Sampling. Only groups with mixed outcomes are retained, ensuring stable advantage estimation and effective exploration.
Training Objective
The policy is optimized using a modified GRPO objective, with KL regularization removed to further encourage exploration and reduce computational overhead. The loss is computed over groups of trajectories, with normalized advantages and clipped importance sampling ratios.
Experimental Results
Benchmarks and Setup
SimpleVLA-RL is evaluated on LIBERO, RoboTwin1.0, and RoboTwin2.0—benchmarks covering a wide range of manipulation tasks, object types, and planning horizons. The backbone is OpenVLA-OFT, an auto-regressive VLA model with LLaMA2-7B as the language component. Training is performed on 8×NVIDIA A800 80GB GPUs, with extensive domain randomization and parallel environment rollout.
Across all benchmarks, SimpleVLA-RL consistently outperforms SFT and SoTA baselines:
- LIBERO: Average success rate increases from 91% (SFT) to 99.1% (SimpleVLA-RL), with a 12% absolute gain on long-horizon tasks.
- RoboTwin1.0: 30.6% improvement over SFT baseline.
- RoboTwin2.0: 80% relative improvement, with gains across all planning horizons, including extra-long-horizon tasks.
Data Efficiency
SimpleVLA-RL demonstrates strong data efficiency. With only a single demonstration per task (One-Trajectory SFT), RL boosts LIBERO-Long success rates from 17.3% to 91.7%, surpassing even the full-trajectory SFT baseline. The performance gap between One-Trajectory SFT+RL and Full-Trajectory SFT+RL is minimal (2.2%), indicating that RL can compensate for limited demonstration data.
Generalization
Generalization analysis reveals that SFT suffers from overfitting and catastrophic forgetting on unseen tasks, while SimpleVLA-RL maintains or improves performance on out-of-distribution tasks across spatial, object, and goal dimensions.
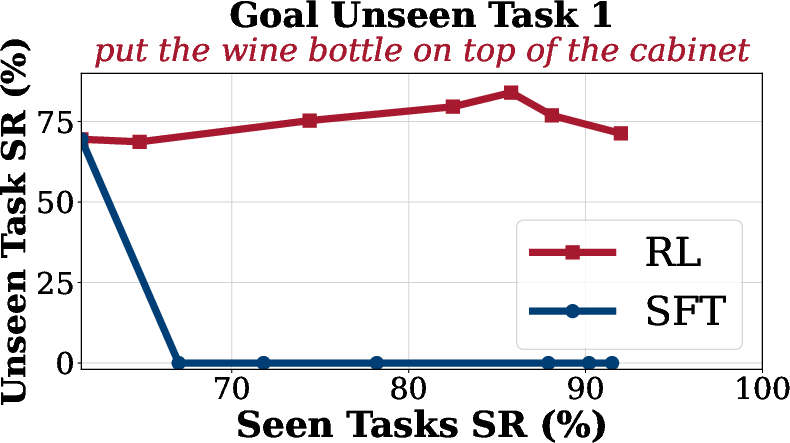
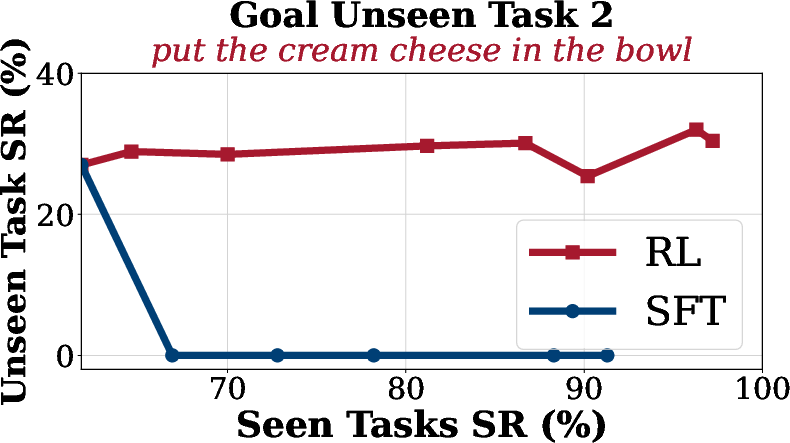
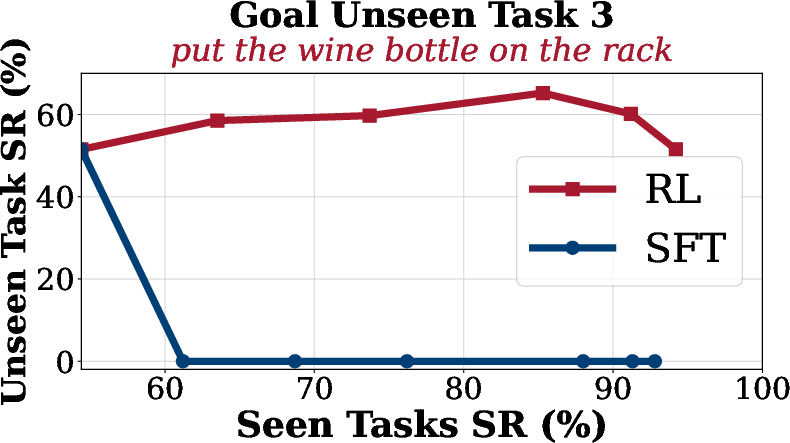
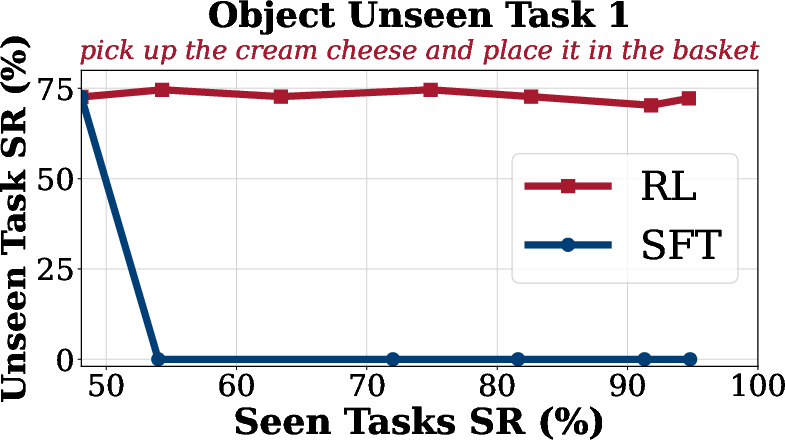
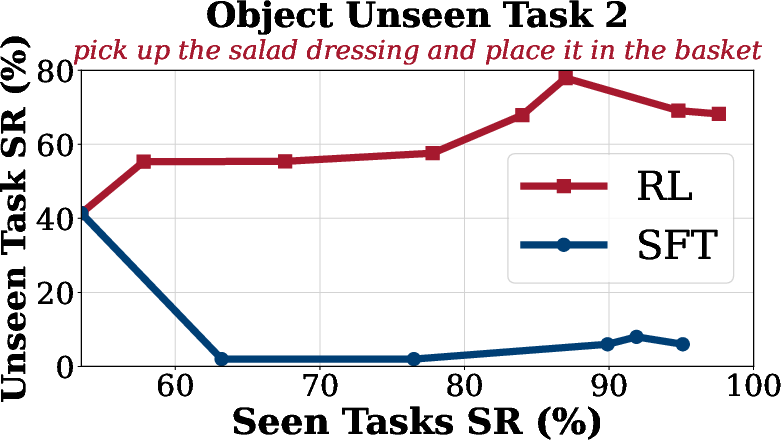
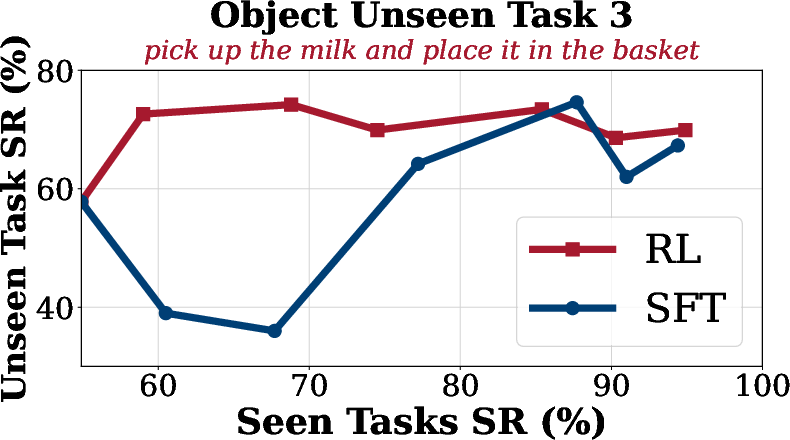
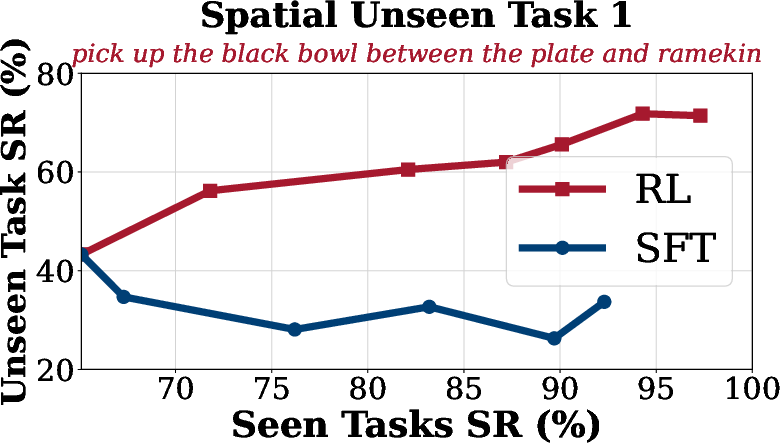
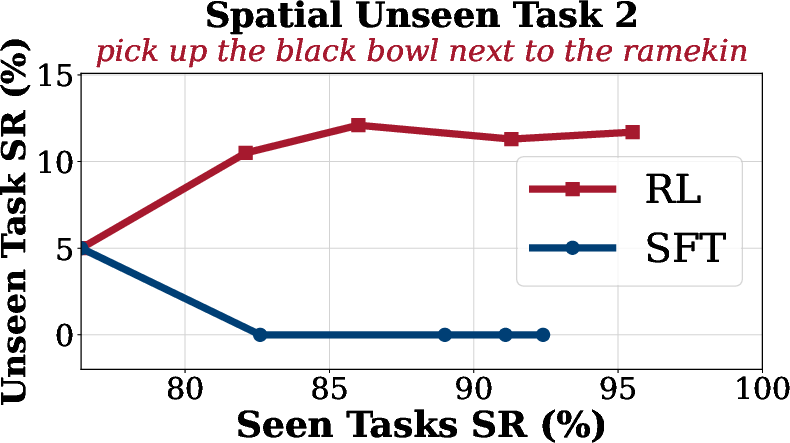
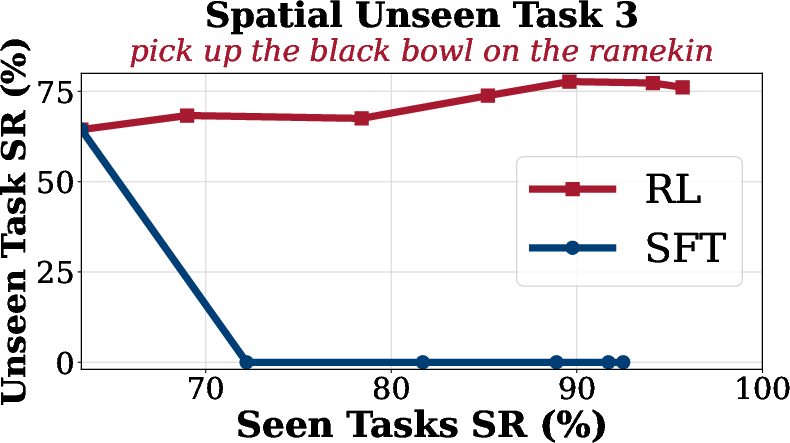
Figure 4: Generalization Analysis on LIBERO. SimpleVLA-RL consistently improves performance on unseen goal, object, and spatial tasks compared to SFT.
Sim-to-Real Transfer
In real-world experiments on RoboTwin2.0, SimpleVLA-RL-trained policies (using only simulation data) achieve substantial improvements in real-world success rates, e.g., from 17.5% (SFT) to 38.5% (RL), with notable gains on tasks requiring high action precision.
Emergent Behaviors: "Pushcut"
A notable emergent phenomenon, termed "pushcut", is observed during RL training. The policy discovers novel strategies absent from the demonstration data, such as pushing objects directly to the goal instead of the demonstrated grasp-move-place routine. This highlights the capacity of outcome-based RL to foster creative, efficient behaviors beyond imitation.
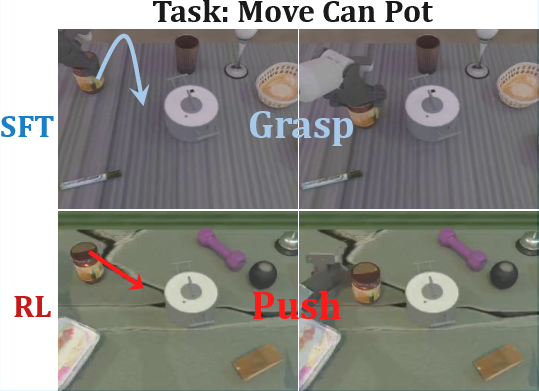
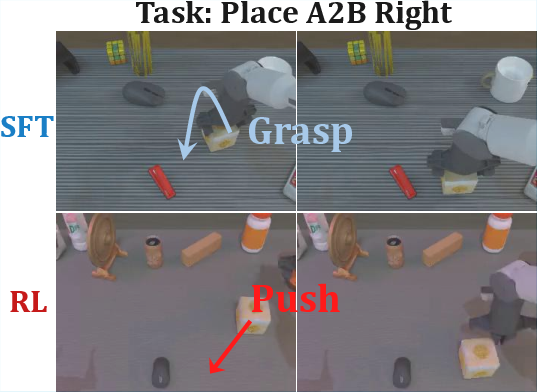
Figure 5: Illustration of "pushcut". The RL-trained policy discovers efficient pushing strategies not present in the demonstration data.
Failure Modes and Limitations
The effectiveness of SimpleVLA-RL is contingent on the initial competence of the base model. RL fails to improve performance when the base model has zero task ability, as no successful trajectories are generated and all rewards are zero. There exists a threshold of initial capability below which RL yields negligible gains. This underscores the importance of sufficient pretraining or SFT to bootstrap RL.
Implications and Future Directions
SimpleVLA-RL demonstrates that outcome-based RL can substantially improve the scalability, data efficiency, and generalization of VLA models. The framework's ability to discover novel behaviors and transfer policies from simulation to real-world settings has significant implications for autonomous robotics. Future research may explore:
- Integration of richer reward signals (e.g., learned or process-based) to further enhance exploration.
- Curriculum learning and adaptive exploration schedules for more challenging tasks.
- Extension to multi-agent and hierarchical VLA settings.
- Automated assessment and mitigation of failure modes in low-data regimes.
Conclusion
SimpleVLA-RL establishes a robust, scalable RL framework for VLA models, enabling significant advances in long-horizon planning, data efficiency, and generalization. By leveraging outcome-based rewards, scalable infrastructure, and targeted exploration strategies, SimpleVLA-RL sets a new standard for RL in embodied AI, with strong empirical results and emergent behaviors that highlight the potential of RL-driven policy discovery in robotics.

