- The paper presents URDF-Anything, a framework integrating 3D multimodal language models for simultaneous geometric segmentation and kinematic prediction.
- It leverages multi-view point clouds and a dynamic [SEG] token to achieve a 17% improvement in segmentation accuracy and reduced errors in joint parameter predictions.
- The framework converts point cloud data into executable URDF files, enabling robust robotic simulation in environments like MuJoCo and SAPIENS.
URDF-Anything: Constructing Articulated Objects with 3D Multimodal LLM
Introduction
The paper addresses the challenge of automating the construction of high-fidelity digital twins of articulated objects using a novel approach involving 3D multimodal LLMs. Traditional methods for creating digital twins, crucial for robotic simulation and AI world modeling, often require manual modeling or complex, multi-stage pipelines. The proposed URDF-Anything framework integrates point cloud data with structured language instructions in a 3D Multimodal LLM (MLLM), enabling simultaneous geometric segmentation and kinematic parameter prediction. Experiments demonstrate substantial improvements over existing methods in segmentation accuracy, parameter prediction, and simulation executability.
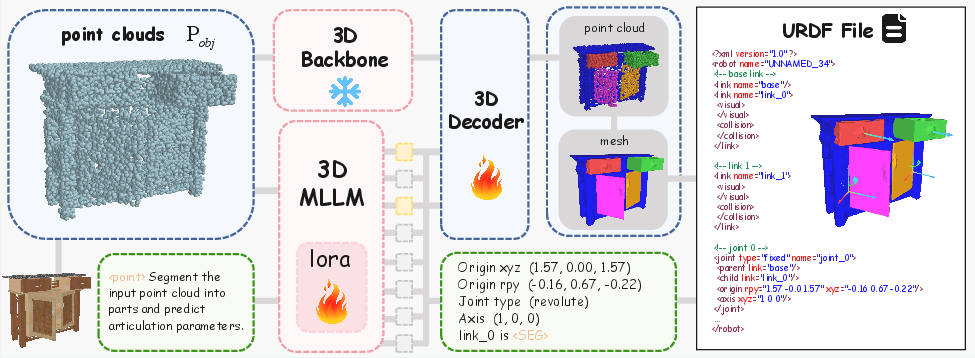
Figure 1: Overview of the URDF-Anything Framework. The pipeline integrates 3D MLLM-generated symbolic and geometric outputs into a functional URDF file.
Methodology
The URDF-Anything framework consists of three main stages outlined below:
The initial stage involves transforming visual data into a 3D point cloud representation. For multi-view inputs, DUSt3R is utilized, whereas LGM handles single-view cases by generating synthetic multi-view images through a diffusion model. The outcome is a dense point cloud capturing the object's geometry.
Multimodal Articulation Parsing
The core of the framework leverages ShapeLLM, combining geometric and text features to predict URDF components. The 3D MLLM integrates a dynamic [SEG] token mechanism, allowing fine-grained segmentation and precise kinematic prediction. This joint prediction ensures consistency between symbolic kinematic descriptions and geometric reconstructions.

Figure 2: Qualitative Comparison of Articulated Object Reconstruction Results. Baseline methods often mispredict object types and exhibit geometric inconsistencies.
Mesh Conversion
Following segmentation, point clouds are converted into meshes for simulation. The structured JSON output from the MLLM provides kinematic parameters that are integrated into URDF XML files. This enables seamless importation into physics simulators like MuJoCo and SAPIENS, ensuring executability in a virtual environment.
Experiments
Extensive evaluation on the PartNet-Mobility dataset revealed significant improvements over baseline methods:
Ablation Study
The study validates several design choices, highlighting the crucial role of joint geometric and kinematic prediction. Decoupled approaches suffered from increased errors, underscoring the synergy of simultaneous prediction tasks. Context fusion for segmentation using the [SEG] token further enhances accuracy.

Figure 4: Point Cloud Generation via Multi-view Synthesis using DUSt3R.
Conclusion
URDF-Anything offers a pioneering solution for automated articulated object reconstruction from visual observations, leveraging advanced 3D MLLM capabilities for improved segmentation and kinematic parameter prediction. By addressing both geometry and kinematic reasoning within an integrated framework, this approach significantly advances the construction of digital twins for robotic applications.
Limitations: The framework's inability to generate certain URDF properties and reliance on external mesh conversion modules are noted, suggesting avenues for future improvements.
This work substantially contributes to the field of automated digital twin creation, enhancing the sim-to-real transfer capabilities of robotic simulations.

Figure 5: Multi-view Point Cloud Generation using DUSt3R.
