- The paper introduces a three-stage pipeline that reconstructs segmented 3D meshes, synthesizes articulation videos, and optimizes joint parameters from a single image.
- It employs mask-guided segmentation and amodal completion techniques to overcome occlusion issues and achieve detailed part decomposition.
- The model demonstrates superior performance for AR/VR and embodied AI applications by producing physically plausible, interactable assets.
DreamArt: Generating Interactable Articulated Objects from a Single Image
Introduction
The paper introduces a novel framework, DreamArt, which focuses on generating interactable articulated 3D assets from single-view images. This task, crucial for applications in Embodied AI and AR/VR, involves challenges such as recovering precise part structures and accurately modeling articulation patterns. Existing image-to-3D methods generally overlook part decomposition and articulation, while neural reconstruction methods require extensive data, limiting scalability.
DreamArt employs a three-stage pipeline to overcome these issues: reconstruction of segmented 3D meshes, synthesis of articulation videos using amodal images and masks, and optimization of joint parameters for realistic articulations.
Methodology
Part-Aware 3D Object Generation
The initial stage involves generating a complete, segmented mesh from a single image, utilizing advanced image-to-3D models combined with mask-prompted segmentation. This process derives complete movable and base part meshes, along with amodal images that provide visibility into occluded parts.
Mask-Guided 3D Segmentation: This step integrates clustering techniques with segmentation masks to overcome granularity ambiguities and occlusions, refining the mesh segmentation into distinct movable and base parts.
Part Amodal Completion: Techniques such as HoloPart are employed to complete the geometrically incomplete segmentations, with inpainting models used to generate amodal images for occluded areas.
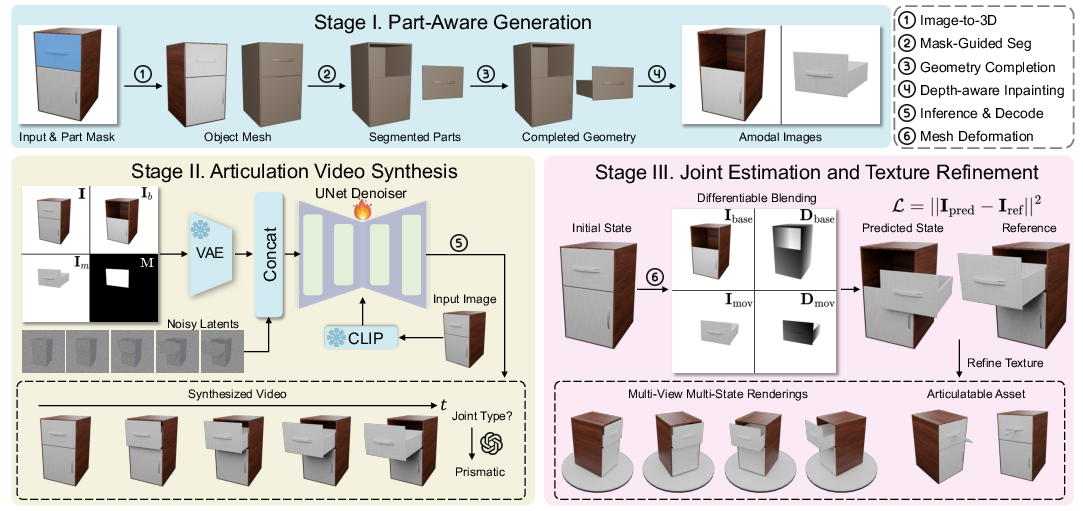
Figure 1: Method Overview. Our three-stage pipeline first reconstructs complete, segmented part meshes from a single image. Next, it synthesizes plausible articulation videos using amodal images and part masks as prompts. Finally, it optimizes joint parameters and refines texture maps for enhanced realism.
Articulation Video Synthesis
A key component of DreamArt is its approach to learning articulation patterns. By fine-tuning a video diffusion model, it synthesizes videos depicting articulation, utilizing movable part masks and amodal images as prompts to guide plausible movement synthesis. This strategy mitigates the limitations of manually defined motion cues and addresses occlusions effectively.
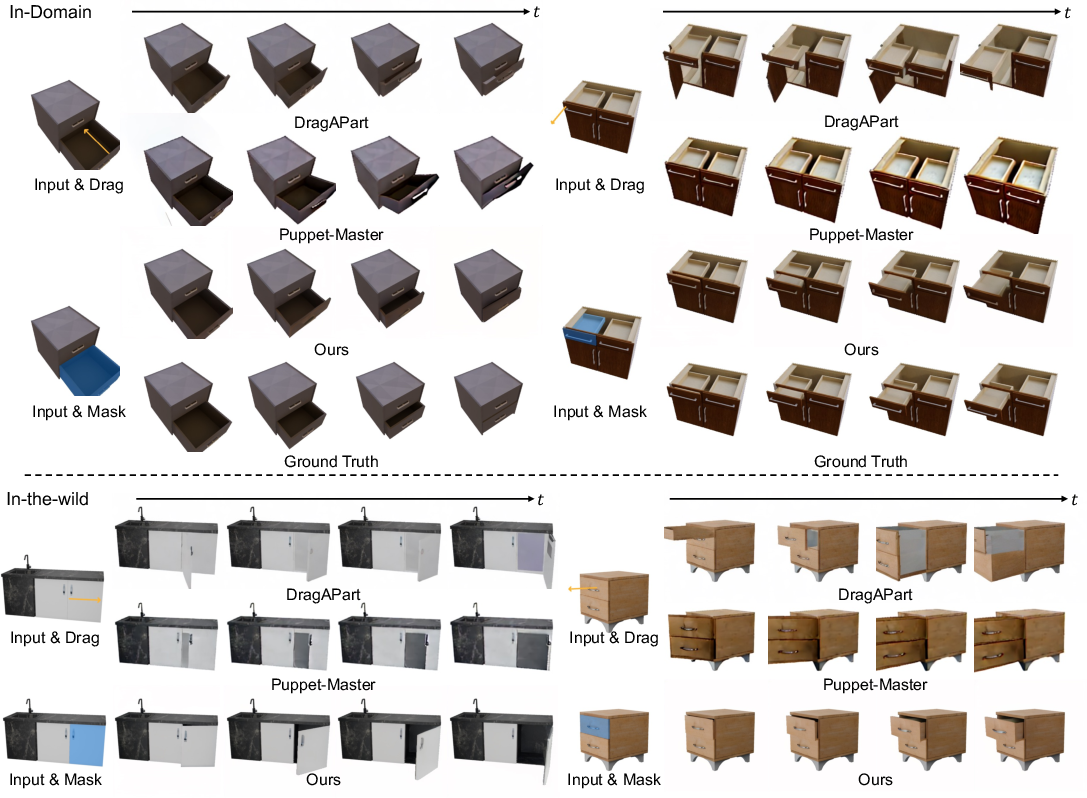
Figure 2: Qualitative comparison of synthesized articulation videos. We present qualitative results on both in-domain and in-the-wild data. Our method consistently outperforms the baselines by producing clearer and more plausible articulation, particularly in multi-part object scenarios.
Joint Parameter Optimization and Texture Refinement
Following video synthesis, joint parameters are optimized using a dual quaternion representation for articulated movements. The model estimates joint types and motions, applying differentiable rendering techniques to ensure precise and plausible articulation. Texture refinement ensures that the appearance is coherent and realistic across parts.
Experimental Evaluation
The method's performance was evaluated through various benchmarks and user studies, showcasing superior quality in articulated asset generation. DreamArt's ability to generalize across object categories and produce physically plausible, articulated assets highlighted its efficacy compared to baseline methods.

Figure 3: Visualizations on asset synthesis. shows clearer images with more plausible articulations than baselines, especially under novel views.
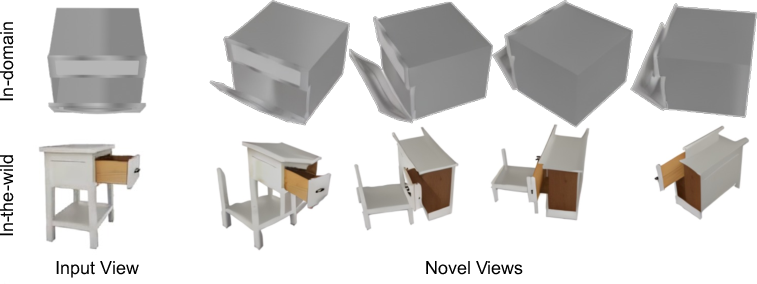
Figure 4: PartRM performs well on in-domain data but generalizes poorly to in-the-wild data.

Figure 5: Multi-view renderings of articulations.
Conclusion
DreamArt presents a scalable solution for generating high-quality articulated objects from single images, addressing both part-level segmentation and articulation modeling. While leveraging existing image-to-3D models presents challenges such as occasionally producing implausible results, DreamArt's multi-view adaptability and physically coherent model setups mark significant progress in articulated asset generation. Future research could focus on improving viewpoint ambiguity resolutions and extending articulation optimization to multi-view contexts.

