Train for Truth, Keep the Skills: Binary Retrieval-Augmented Reward Mitigates Hallucinations
Abstract: LLMs often generate factually incorrect information unsupported by their training data, a phenomenon known as extrinsic hallucination. Existing mitigation approaches often degrade performance on open-ended generation and downstream tasks, limiting their practical utility. We propose an online reinforcement learning method using a novel binary retrieval-augmented reward (RAR) to address this tradeoff. Unlike continuous reward schemes, our approach assigns a reward of one only when the model's output is entirely factually correct, and zero otherwise. We evaluate our method on Qwen3 reasoning models across diverse tasks. For open-ended generation, binary RAR achieves a 39.3% reduction in hallucination rates, substantially outperforming both supervised training and continuous-reward RL baselines. In short-form question answering, the model learns calibrated abstention, strategically outputting "I don't know" when faced with insufficient parametric knowledge. This yields 44.4% and 21.7% fewer incorrect answers on PopQA and GPQA, respectively. Crucially, these factuality gains come without performance degradation on instruction following, math, or code, whereas continuous-reward RL, despite improving factuality, induces quality regressions.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple explanation of “Train for Truth, Keep the Skills: Binary Retrieval‑Augmented Reward Mitigates Hallucinations”
What is this paper about?
This paper looks at a common problem with AI LLMs (like chatbots): sometimes they confidently say things that aren’t true. That’s called “hallucination.” The authors introduce a new training method that helps these models stop making up facts, without hurting their other skills (like following instructions, doing math, or writing code).
What questions are the researchers trying to answer?
They ask:
- Can we train a LLM to be more truthful while keeping its general abilities strong?
- Can we encourage the model to say “I don’t know” when it isn’t sure, instead of guessing wrong?
- Is there a simple, reliable way to reward truthful answers that avoids “gaming” the system?
How did they approach the problem?
Think of training like a game with points. The model tries an answer, and the training system gives points based on how good that answer is. Most past systems give partial points (like “7 out of 10”) for answers that look okay. But models can learn to “game” these scores—for example, by sounding fancy without being correct.
This paper uses a stricter, simpler rule: a binary reward (pass/fail).
- If the answer contains no factual mistakes: reward = 1 (pass).
- If the answer has any contradiction with trusted sources: reward = 0 (fail).
To check this, they use a retrieval-and-verification pipeline:
- Retrieval: Like going to a library, the system searches the web and gathers relevant documents related to the model’s response.
- Verification: Another AI “fact-checker” compares the model’s answer to the gathered documents and looks for contradictions (not just missing details). If there’s any conflict, the answer fails.
They train the model with reinforcement learning (RL), which is like teaching through trial and error: the model keeps trying answers and learns from the pass/fail signal. To keep the model from changing too much and losing its skills, they use a “leash” called KL regularization. You can think of it like keeping a trained dog close—letting it explore a bit, but not run off and forget what it already knows.
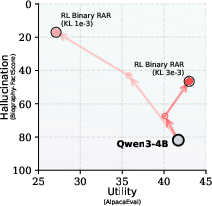
They use a stable RL method (GRPO) that’s efficient for LLMs and test this on Qwen3 reasoning models (sizes: 4B and 8B parameters).
What did they find, and why does it matter?
The results show big improvements in truthfulness without hurting other abilities. Here are the highlights:
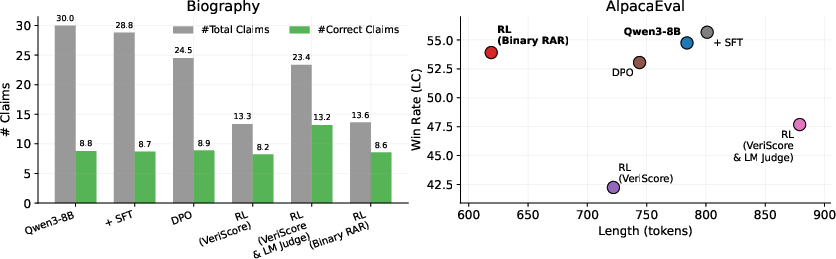
- Long answers (like explanations or essays): The model cut the rate of false claims by about 39% on the larger model (8B) and about 43% on the smaller model (4B), compared to the original. It beat other training methods that use partial scores.
- Short answers (like quiz questions): When allowed to say
I don't know, the model gave far fewer wrong answers—44% fewer on one dataset (PopQA) and 22% fewer on another (GPQA). - The model learned to abstain smartly: It didn’t randomly refuse to answer—mostly, it said
I don't knowon questions it would have gotten wrong, and kept or even improved accuracy on the ones it tried to answer. - No drop in general skills: Unlike other methods that improved truth but made the model worse at following instructions or writing helpful responses, this binary reward approach kept performance in areas like instruction following, math, and code essentially stable.
An important detail: the model didn’t just “get quieter.” It kept about the same number of correct facts but removed many incorrect ones. So it became more precise—still informative, but less likely to include wrong statements.
What does this mean going forward?
This research suggests a practical way to make AI models more trustworthy:
- A simple pass/fail reward tied to real evidence can reduce false statements.
- Encouraging honest uncertainty (
I don't know) is safer than forcing guesses. - We can train for truth without sacrificing the model’s other useful skills.
- Using binary rewards makes it harder for the model to “hack” the scoring system by sounding better without being more accurate.
In short, this method helps build AI systems that are both helpful and honest—more likely to admit when they don’t know, and less likely to confidently spread misinformation. This can make AI safer and more reliable for everyday users, students, and professionals alike.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research:
- External verifier reliability is unquantified
- Measure the accuracy, precision/recall, and failure modes of the Qwen3-32B verifier on contradiction detection, using human-labeled ground truth across diverse domains.
- Assess how often the LM verifier falsely flags contradictions (false positives) or misses errors (false negatives), and how this affects RL dynamics.
- Retrieval quality and evidence correctness are not rigorously validated
- Quantify the impact of retrieval errors (irrelevant, outdated, or incorrect documents) on reward noise and training outcomes.
- Evaluate robustness to conflicting evidence and source credibility; develop methods to handle contradictory or low-quality web sources.
- Pre-caching design may bias training and limit coverage
- Analyze how building the cache from “ground-truth responses” shapes what contradictions can be found, and whether it overfits to specific responses or topics.
- Compare pre-cached retrieval versus live retrieval during RL to understand coverage, latency, and factuality trade-offs.
- Binary “whole-response” reward may over-penalize minor errors
- Investigate graded or claim-weighted binary rewards that differentiate critical factual errors from minor inaccuracies, and quantify the utility–factuality trade-off.
- Abstention calibration is not measured quantitatively
- Report calibration metrics (e.g., Expected Calibration Error, selective risk curves) and threshold behaviors for abstention, including whether abstention aligns with true uncertainty.
- Examine miscalibration risks (e.g., abstaining despite knowing the answer, or answering despite uncertainty) and consequences for user experience.
- Generalization across model families, sizes, and languages is untested
- Extend experiments beyond Qwen3 4B/8B to larger scales and different architectures (e.g., Llama, Mixtral, GPT-like models).
- Evaluate cross-lingual and non-English factuality to test retrieval/verifier effectiveness in multilingual settings.
- Human evaluation is limited; reliance on LM judges may misalign with user preferences
- Conduct controlled human studies of long-form outputs to validate factuality, helpfulness, and perceived quality.
- Compare LM-judge outcomes with human preferences to detect and quantify judge-induced biases.
- Hyperparameter sensitivity and stability are insufficiently characterized
- Systematically ablate KL coefficients, group sizes, learning rates, and sampling strategies; produce stability and variance analyses across seeds and datasets.
- Explore alternative RL algorithms (e.g., PPO, P3O, implicit KL methods, actor–critic variants) and their stability–performance trade-offs.
- Reward design choices require deeper analysis
- Test hybrid reward formulations combining binary contradiction checks with claim-level precision, informativeness measures, or style constraints to prevent degenerate short outputs.
- Assess susceptibility to reward hacking under adversarial prompts and stylistic manipulations, and propose defenses.
- Coverage of task domains and input types is narrow
- Evaluate domains where “truth” is hard to define (e.g., opinions, legal interpretations, medical advice), and measure how Binary RAR behaves when definitive evidence is scarce.
- Assess multi-hop, temporal, and rapidly evolving knowledge tasks; quantify performance when facts change over time.
- Impact on harmfulness, safety, and ethical behavior is unknown
- Analyze whether Binary RAR affects safety (e.g., refusal to generate harmful content) or introduces new risks (e.g., over-abstention that blocks benign use cases).
- Long-form evaluation mismatch with training reward granularity
- The paper evaluates hallucination at claim-level (FactScore) but trains with whole-response binary rewards; quantify the mismatch and test claim-level binary rewards for training.
- Compute cost and efficiency are not benchmarked comprehensively
- Provide detailed throughput, latency, and cost-per-sample comparisons for Binary RAR vs. continuous rewards, across response lengths and retriever/verifier configurations.
- Verifier choice and ensembling are not explored
- Ablate different verifiers (sizes, families), or use verifier ensembles to reduce bias/noise; quantify benefits and overheads.
- Retrieval source dependence and reproducibility concerns
- Google Search API and dynamic web content introduce non-determinism; evaluate reproducibility across time and regions, and test curated, versioned corpora.
- Effects on intrinsic hallucinations and non-factual tasks are unmeasured
- Extend evaluation to intrinsic hallucinations (prompt consistency) and tasks requiring nuanced reasoning where truthfulness is not strictly binary.
- Integration with uncertainty-aware interfaces and user controls
- Study how calibrated abstention manifests in user-facing settings (e.g., confidence scores, citations, partial answers) and its impact on satisfaction and trust.
- Interactions with downstream tool use and RAG at inference
- Analyze whether post-training with Binary RAR improves or interferes with future retrieval-augmented generation pipelines at inference time, and develop combined training/inference strategies.
- Early stopping policy may bias reported results
- Investigate how the chosen early stopping criterion (>10% drop on any utility benchmark) affects outcomes; compare against fixed-step training or validation-based stopping to ensure fairness.
- Dataset selection pipeline introduces vendor and model biases
- The use of gpt-4.1 for prompt selection and claim extraction/verification may import proprietary-model biases; replicate with open-source alternatives and compare outcomes.
Practical Applications
Immediate Applications
Below are concrete, deployable uses of the paper’s binary retrieval-augmented reward (RAR) method that organizations and individuals can implement now, leveraging the released code and the demonstrated stability across tasks.
- Industry — Software and AI platforms: Evidence-aware “Truth Mode” for chatbots and copilots
- Application: Add a training stage that fine-tunes existing models with binary RAR to reduce extrinsic hallucinations while preserving general capabilities (instruction following, reasoning, code).
- Emergent tool/product: “Factual Mode” toggle in enterprise chat/coding assistants that returns answers only when fully supported; otherwise, it abstains (“I don’t know”).
- Assumptions/Dependencies: Access to a retriever and an LM verifier; curated evidence datastore (domain-relevant web pages, internal KB); sufficient compute for GRPO-based RL; careful KL tuning to avoid degenerate short responses.
- Industry — Customer support and enterprise search
- Application: Deploy calibrated, abstaining Q&A bots for internal knowledge bases and public FAQs, cutting wrong answers by replacing them with uncertainty statements when evidence is insufficient.
- Workflow: Pre-cache evidence for frequent questions; run binary RAR RL on the bot; monitor abstention vs. answer rates to tune KL and reward.
- Assumptions/Dependencies: High-quality document ingestion and chunking; evidence freshness; users accept occasional abstentions.
- Healthcare — Patient education and triage chat
- Application: Patient-facing assistants that abstain when not fully supported by clinical guidelines and cite verified sources for supported claims.
- Emergent tool: “Evidence-backed response” badge for health information.
- Assumptions/Dependencies: Regulated, vetted medical corpora; human-in-the-loop escalation for abstentions; institutional approval for retrieval sources.
- Finance — Research memos and market FAQs
- Application: Internal assistants that reduce unsupported market claims and switch to uncertainty language when evidence is missing, preserving accuracy when a best guess is required.
- Assumptions/Dependencies: Access-controlled financial research databases; compliance review of abstention thresholds; logging of evidence used.
- Legal and Compliance — Draft review assistants
- Application: Tools that flag contradictions against statutes, case law, or policy, and abstain from definitive statements without evidence, reducing risk in contract or policy drafting.
- Assumptions/Dependencies: Up-to-date legal corpora; verifier prompts adapted to domain language; human expert oversight.
- Education — Tutors and study helpers
- Application: Study assistants that avoid confidently wrong explanations, offering “I don’t know” plus reading suggestions when not fully supported; maintains math/code skills.
- Assumptions/Dependencies: Course-specific retrieval sets; UI that explains abstentions and suggests sources.
- News/Media — Fact-sensitive summarization and backgrounders
- Application: Editorial assistants that generate background paragraphs only when claims are fully supported by retrieved evidence; otherwise abstain and propose sources to consult.
- Assumptions/Dependencies: Curated, reliable news archives; transparent citation workflows.
- Safety/Quality Teams — Model governance and evaluation
- Application: Adopt the paper’s hallucination–utility evaluation suite to track factual precision vs. open-ended utility; gate releases if any utility metric drops >10%.
- Emergent product: Internal “Factuality CI” pipeline that runs long-form claim verification plus short-form abstention analysis on each checkpoint.
- Assumptions/Dependencies: Benchmarks integration; LM-as-judge configurations stable across versions.
- Academia — Research assistants and literature review
- Application: Fine-tune LLM research aides with binary RAR to reduce unsupported claims in related work sections and literature summaries; abstain when citations are missing.
- Assumptions/Dependencies: Field-specific repositories (PubMed, arXiv); consistent citation extraction; verifier prompts calibrated for academic claims.
- Daily Life — Personal assistants and writing helpers
- Application: Personal assistants configured with binary RAR to provide verified guidance on topics (travel rules, tax deadlines) and abstain when uncertain, reducing misleading advice.
- Assumptions/Dependencies: Reliable source lists per topic; acceptance that abstentions are preferable to plausible-but-wrong answers.
Long-Term Applications
The following use cases require further research, domain-specific scaling, productization, or standardization before broad deployment.
- Cross-domain “Factuality Certification” for LLMs
- Application: Industry-wide badges indicating a model meets abstention calibration and factuality targets across long-form and short-form tasks, audited with binary RAR-style evaluations.
- Sector: Policy, software, compliance.
- Assumptions/Dependencies: Shared benchmarks, third-party auditors, standardized retrieval corpora and verifier APIs.
- Regulated sectors — Evidence-grounded agents with selective autonomy
- Application: Multi-step agents that only act (file a claim, execute a trade, schedule a procedure) when all steps pass binary contradiction checks; otherwise escalate to humans.
- Sector: Healthcare, finance, public services.
- Assumptions/Dependencies: Robust, domain-verified retrievers; end-to-end provenance; liability frameworks for abstentions and escalations.
- Tooling ecosystem — Verifier microservices and “RAR-as-a-service”
- Application: Managed services offering retrieval, verification, and binary reward computation at scale, integrated into model training pipelines (GRPO/PPO).
- Sector: AI infrastructure.
- Assumptions/Dependencies: Cost-effective inference for verifiers; throughput guarantees; privacy-preserving retrieval for proprietary corpora.
- Education platforms — Curriculum-aligned factual tutors with adaptive abstention
- Application: Tutors that dynamically adjust abstention levels based on curricular scope and student progress, teaching uncertainty literacy alongside content mastery.
- Assumptions/Dependencies: Fine-grained learning objectives; calibrated reward shaping per grade level; classroom integration and teacher dashboards.
- Journalism and scientific publishing — End-to-end verified generation with citation scaffolding
- Application: Writing tools that couple binary RAR with structured citation extraction, ensuring every claim maps to a source and abstaining when sources are weak.
- Assumptions/Dependencies: Standardized citation formats, source reliability scoring, editorial acceptance of abstention-driven workflows.
- Government procurement and AI policy — Abstention and evidence requirements
- Application: Procurement rules mandating calibrated abstention and evidence-backed responses for public-facing AI systems, measured via binary RAR audits.
- Assumptions/Dependencies: Policy frameworks; conformance testing; exceptions-handling for emergency use.
- Multimodal expansion — Factuality across text, tables, images, and code
- Application: Binary RAR generalized to check contradictions in multimodal outputs (e.g., chart descriptions vs. underlying data, code vs. specification).
- Sector: Data analytics, robotics, software engineering.
- Assumptions/Dependencies: Multimodal retrievers/verifiers; domain-specific contradiction detection; benchmark coverage.
- On-device or edge deployments — Lightweight verifiers and offline corpora
- Application: Portable assistants with local, curated corpora and compact verifiers enabling offline factuality checks and abstention.
- Assumptions/Dependencies: Efficient retrieval indexes; small verifier models; periodic sync to refresh sources.
- Continuous knowledge operations — Automated evidence curation and cache management
- Application: Systems that ingest, de-duplicate, and rank sources for RAR training/inference, with drift detection triggering re-tuning of KL and reward thresholds.
- Sector: Enterprise knowledge management.
- Assumptions/Dependencies: Data pipelines for crawling and parsing; source reliability metrics; governance for updates.
- Safety research — Robustness to verifier/retriever noise and reward hacking
- Application: Formal analyses and tooling that quantify and mitigate residual failure modes (style bias, irrelevant correctness, degenerate brevity), improving binary RAR’s reliability.
- Assumptions/Dependencies: Adversarial testbeds; alternative verifiers; hybrid reward designs; human oversight loops.
- Certification-ready evaluation suites — Sector-specific hallucination–utility trade-off tests
- Application: Standardized tests that ensure factuality gains do not degrade instruction following, math, or code for models deployed in specific verticals.
- Assumptions/Dependencies: Sector-tailored benchmarks; reproducible pipelines; versioned evaluation artifacts.
Notes on Assumptions and Dependencies
- Evidence quality is pivotal: domain-specific, current, and reliable retrieval sources determine the verifier’s effectiveness.
- Verifier choice and prompts matter: biases in LM-as-verifier can affect reward accuracy; cross-verifier agreement and audits help.
- KL regularization is a critical control: overly low KL can cause degenerate short outputs; tuning preserves utility.
- Compute and engineering costs: RL with retrieval and verification requires infrastructure; throughput optimizations (pre-caching, chunking) reduce costs.
- User experience and trust: calibrated abstention must be communicated clearly (e.g., “I don’t know; here’s where to look”), or users may misinterpret refusal to answer.
Glossary
- Ablation studies: Systematic experiments that vary one component at a time to understand its effect on performance. "We conduct ablation studies to isolate the contributions of KL regularization and reward design to our core challenge: maintaining hallucination reduction while preserving model utility."
- Advantage (RL): A policy-gradient signal measuring how much better an action is compared to a baseline for the same state. "and the advantage and KL regularization $\mathbb{D}_{\mathrm{KL}$ are defined as:"
- AlpacaEval: An instruction-following benchmark with LM-judged win rates for long-form responses. "AlpacaEval~\citep{dubois2024lengthcontrolled} score remains largely stable (-1.4\%), whereas continuous reward baselines show significant degradation (-22.8\%)."
- ArenaHard: A challenging instruction-following benchmark comparing chat model responses. "AlpacaEval~\citep{dubois2024lengthcontrolled}, ArenaHard~\citep{li2025from}, and IFEval~\citep{zhou2023instructionfollowingevaluationlargelanguage} for instruction following;"
- Atomic claim: A minimal, verifiable factual assertion extracted from generated text. "Specifically, we decompose a response into atomic, verifiable claims and then check each claim against related documents."
- BBH: BIG-Bench Hard, a reasoning benchmark focusing on difficult tasks for LMs. "and BBH~\citep{suzgun-etal-2023-challenging}, GSM8K~\citep{cobbe2021trainingverifierssolvemath}, and Minerva~\citep{lewkowycz2022solving} for reasoning;"
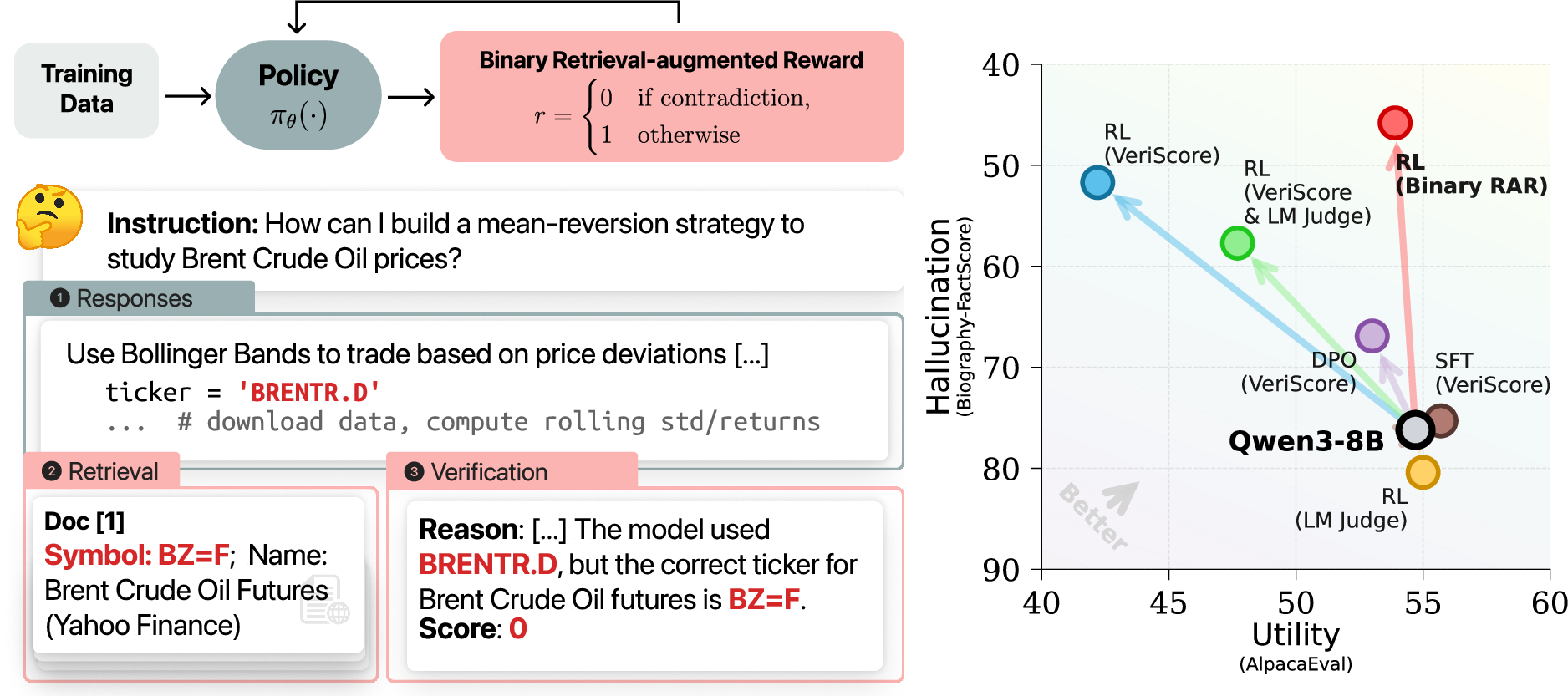
- Binary retrieval-augmented reward (RAR): A binary reward that assigns 1 only when an output is fully supported by retrieved evidence, and 0 otherwise. "We propose an online reinforcement learning method using a novel binary retrieval-augmented reward (RAR) to address this tradeoff."
- BM25: A classic term-weighting retrieval function used to rank text documents by relevance. "To compute binary RAR, we use BM25 retrieval with documents chunked into 512 tokens (using the Qwen3 tokenizer)."
- Calibrated abstention: Strategic refusal to answer (e.g., “I don’t know”) aligned with uncertainty, without harming accuracy. "the model learns calibrated abstention, strategically outputting ``I don't know'' when faced with insufficient parametric knowledge."
- Claim decomposition: Breaking generated text into individual factual claims for verification. "Verification Without Claim Decomposition."
- Continuous factuality rewards: Graded scoring functions that assign a scalar value to how factual a response is. "and reinforcement learning (RL) with continuous factuality rewards~\citep{liang2024learningtrustfeelingsleveraging,chen2025learningreasonfactuality}."
- Direct Preference Optimization (DPO): A post-training algorithm that makes models prefer higher-quality responses based on paired comparisons. "Direct Preference Optimization (DPO) trains the model to prefer more factual responses over less factual ones~\citep{tian2024finetuning,lin2024flame}."
- Extrinsic hallucination: Generation of information that is plausible but unsupported by training data or retrieved evidence. "LLMs often generate factually incorrect information unsupported by their training data, a phenomenon known as extrinsic hallucination."
- FactScore: An evaluation method measuring factual precision by verifying atomic claims against evidence. "which is equivalent to one minus the factual precision in FactScore~\citep{min-etal-2023-factscore}."
- GPQA: A graduate-level multiple-choice QA benchmark testing deep factual knowledge. "PopQA~\citep{mallen-etal-2023-trust} and GPQA~\citep{rein2024gpqa} for short-form question answering that requires substantial factual knowledge."
- GRPO (Group Relative Policy Optimization): A critic-free RL algorithm for LMs that estimates baselines from grouped rollouts. "Group Relative Policy Optimization (GRPO; \citealt{shao2024deepseekmathpushinglimitsmathematical}) has become a popular choice for LM post-training due to its stability and computational efficiency~\citep{deepseekai2025deepseekr1incentivizingreasoningcapability}."
- Hallucination rate: The proportion of incorrect outputs (claims or answers) among those produced. "We report the hallucination rate as the primary metric, following the definition used in \citet{openai2025gpt5systemcard}."
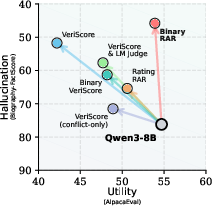
- Hallucination–utility tradeoff: The tension between reducing factual errors and preserving overall model usefulness. "Right: Binary RAR achieves the best hallucination–utility tradeoff among all post-training baselines."
- HumanEval: A code generation benchmark evaluating functional correctness of synthesized programs. "and HumanEval~\citep{chen2021evaluatinglargelanguagemodels} and MBPP~\citep{austin2021programsynthesislargelanguage} for code generation."
- IFEval: An instruction-following benchmark measuring adherence to complex directives. "AlpacaEval~\citep{dubois2024lengthcontrolled}, ArenaHard~\citep{li2025from}, and IFEval~\citep{zhou2023instructionfollowingevaluationlargelanguage} for instruction following;"
- KL coefficient: The hyperparameter controlling the strength of the KL penalty during RL fine-tuning. "The learning rate is set to , with KL coefficients of for Qwen3-8B and for Qwen3-4B."
- KL divergence (Kullback–Leibler divergence): A measure of how much the fine-tuned policy deviates from a reference policy. "the optimization is typically constrained by a Kullback–Leibler (KL) divergence term against a reference model $\pi_{\text{ref}$."
- KL regularization: Penalizing deviation from a base model during RL to prevent capability drift. "and introduce a novel binary retrieval-augmented reward (Binary RAR; Figure~\ref{fig:teaser}) that focuses on determining whether the entire response contains errors, with KL regularization to control drift."
- LM Judge: An automated evaluator that rates overall response quality on a numeric scale. "We first use {LM Judge}, which rates overall response quality on a 0–10 scale, following common practice~\citep{gunjal2025rubrics}."
- LM verifier: An LLM used to check generated responses against retrieved documents for contradictions. "To check correctness, an LM verifier takes as input and determines whether contradictions exist between the response and retrieved documents."
- LLM-as-a-Judge: Using a LLM to evaluate outputs in place of human judges. "and LLM-as-a-Judge~\citep{li2024toolaugmented}."
- Minerva: A math reasoning benchmark emphasizing quantitative problem solving. "and BBH~\citep{suzgun-etal-2023-challenging}, GSM8K~\citep{cobbe2021trainingverifierssolvemath}, and Minerva~\citep{lewkowycz2022solving} for reasoning;"
- Natural Language Inference (NLI): Techniques for determining entailment, contradiction, or neutrality between sentences. "including NLI-based methods~\citep{gao-etal-2023-rarr,min-etal-2023-factscore,song-etal-2024-veriscore}, QA-based methods~\citep{tian2024finetuning}, uncertainty estimation~\citep{farquhar2024detecting,orgad2025llms}, and LLM-as-a-Judge~\citep{li2024toolaugmented}."
- Next-token likelihood: The probability assigned by a LLM to the next token during pre-training. "pre-training optimizes next-token likelihood without enforcing factual correctness in generation~\citep{kalai2025languagemodelshallucinate,wen-etal-2025-know}."
- Online RL: Reinforcement learning that computes rewards on the current model’s rollouts during training. "We propose an online reinforcement learning method using a novel binary retrieval-augmented reward (RAR) to address this tradeoff."
- PopQA: A short-form open-domain QA benchmark testing factual recall. "PopQA~\citep{mallen-etal-2023-trust} and GPQA~\citep{rein2024gpqa} for short-form question answering that requires substantial factual knowledge."
- Pre-caching strategy: Precomputing and storing relevant documents per prompt to accelerate retrieval during RL. "To improve efficiency, we adopt a pre-caching strategy."
- Qwen3: A family of reasoning-focused LLMs used as base and verifier in experiments. "We train Qwen3~\citep{qwen3technicalreport} reasoning models (4B and 8B) with our Binary RAR method and evaluate them on four hallucination benchmarks and ten general capability benchmarks,"
- QA-based methods: Approaches that frame factuality checking as question answering over retrieved evidence. "including NLI-based methods~\citep{gao-etal-2023-rarr,min-etal-2023-factscore,song-etal-2024-veriscore}, QA-based methods~\citep{tian2024finetuning}, uncertainty estimation~\citep{farquhar2024detecting,orgad2025llms}, and LLM-as-a-Judge~\citep{li2024toolaugmented}."
- Retrieval-augmented generation: Enhancing LM outputs by incorporating information retrieved from external sources. "Many prior works explore mitigation methods at inference time, such as retrieval-augmented generation~\citep{asai2024selfrag}, prompting techniques~\citep{ji-etal-2023-towards}, and decoding algorithms~\citep{chuang-etal-2024-lookback}."
- Reward hacking: Exploiting imperfections in a reward function to increase scores without truly improving the intended behavior. "Unlike prior works using continuous factuality scores that can be vulnerable to reward hacking, we propose a simple binary signal:"
- Supervised fine-tuning (SFT): Post-training by learning from labeled or curated responses to improve specific behaviors. "Supervised fine-tuning (SFT) can improve factuality by avoiding training on knowledge that the model has not already assimilated during pre-training,"
- VeriScore: A continuous factuality metric that scores the proportion of supported claims in a response. "We also test {VeriScore}~\citep{song-etal-2024-veriscore} as an RL reward, following concurrent work~\citep{chen2025learningreasonfactuality}."
- WildChat: A dataset of natural human-LLM interactions used to source realistic prompts. "We build upon WildChat~\citep{zhao2024wildhallucinationsevaluatinglongformfactuality}, a large collection of natural instruction–response pairs from human interactions with OpenAI models."
- WildHallucination: A long-form generation benchmark for measuring hallucination in open-ended outputs. "Biography~\citep{min-etal-2023-factscore} and WildHallucination~\citep{zhao2024wildhallucinationsevaluatinglongformfactuality} for long-form generation,"
Collections
Sign up for free to add this paper to one or more collections.