Convomem Benchmark: Why Your First 150 Conversations Don't Need RAG
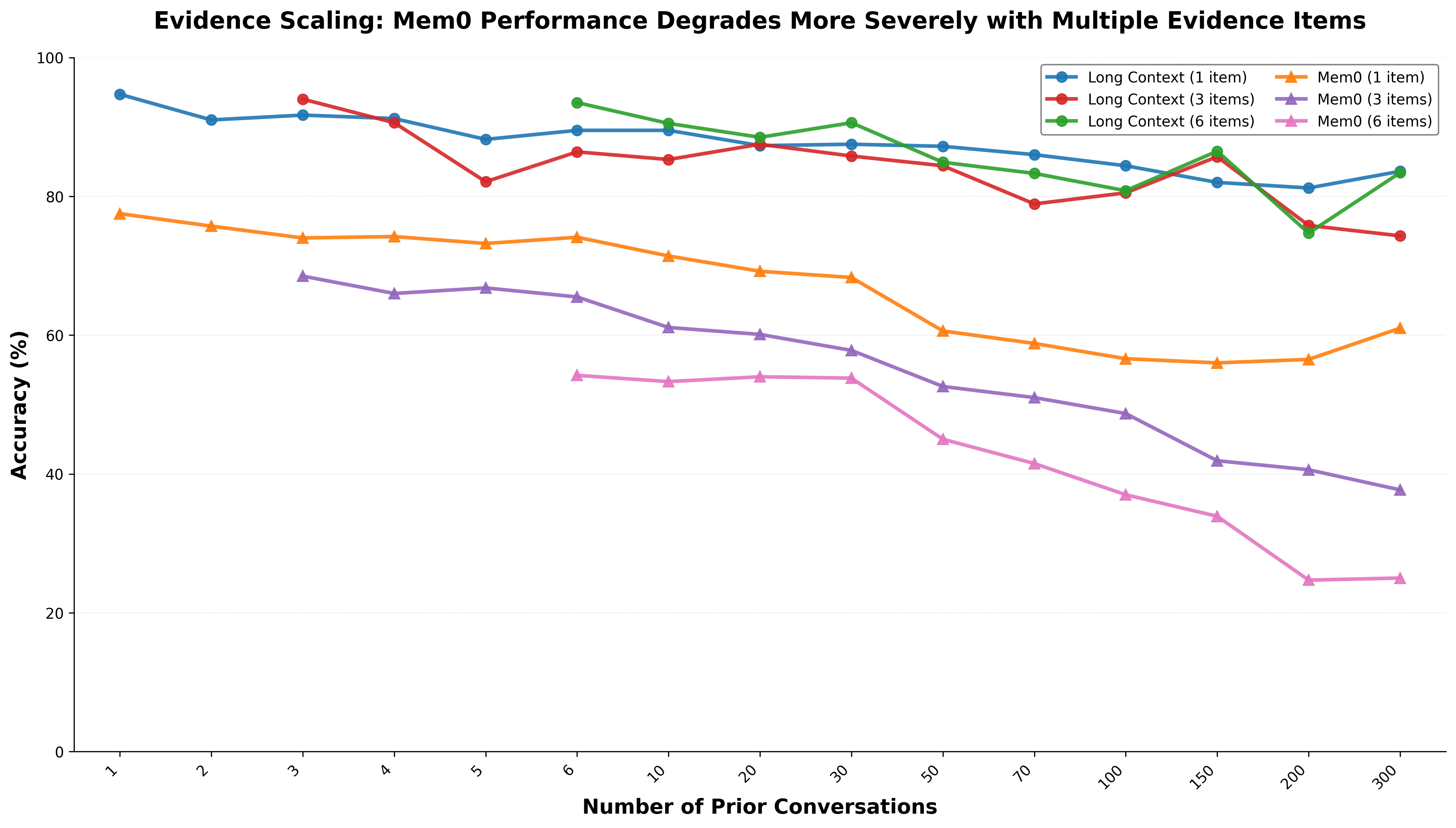
Abstract: We introduce a comprehensive benchmark for conversational memory evaluation containing 75,336 question-answer pairs across diverse categories including user facts, assistant recall, abstention, preferences, temporal changes, and implicit connections. While existing benchmarks have advanced the field, our work addresses fundamental challenges in statistical power, data generation consistency, and evaluation flexibility that limit current memory evaluation frameworks. We examine the relationship between conversational memory and retrieval-augmented generation (RAG). While these systems share fundamental architectural patterns--temporal reasoning, implicit extraction, knowledge updates, and graph representations--memory systems have a unique characteristic: they start from zero and grow progressively with each conversation. This characteristic enables naive approaches that would be impractical for traditional RAG. Consistent with recent findings on long context effectiveness, we observe that simple full-context approaches achieve 70-82% accuracy even on our most challenging multi-message evidence cases, while sophisticated RAG-based memory systems like Mem0 achieve only 30-45% when operating on conversation histories under 150 interactions. Our analysis reveals practical transition points: long context excels for the first 30 conversations, remains viable with manageable trade-offs up to 150 conversations, and typically requires hybrid or RAG approaches beyond that point as costs and latencies become prohibitive. These patterns indicate that the small-corpus advantage of conversational memory--where exhaustive search and complete reranking are feasible--deserves dedicated research attention rather than simply applying general RAG solutions to conversation histories.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is about teaching AI chat assistants to remember things you’ve told them across many chats, so they can help you better. The authors built a big test called ConvoMem to see how well different memory approaches work. They also ask a practical question: when you’re early in a relationship with an assistant (your first dozens or hundreds of chats), do you really need a fancy “search system” behind the scenes, or is it enough to just show the AI the whole chat history each time?
Their short answer: for your first 30 chats, the simplest approach works best. It stays pretty good up to around 150 chats. After that, you’ll probably want to switch to more advanced tools because costs and delays grow.
The main questions the paper asks
- How do we fairly and reliably test whether a chat assistant can remember important details over time?
- For small amounts of chat history, is a simple method (just giving the model the full conversation) better than complicated search-and-retrieve systems?
- When does it make sense to switch from “simple memory” to “fancy retrieval”?
- Do you need expensive, top-tier AI models to get good memory, or are mid-tier models good enough?
How they tested it (explained simply)
Think of two ways an AI can “remember”:
- Long context (the simple way): You hand the AI the entire past conversation every time it answers. It’s like giving a student your whole notebook before each question.
- RAG (retrieval-augmented generation, the fancy way): Instead of handing over the whole notebook, the AI keeps a searchable filing cabinet. It looks up only the pieces it thinks are relevant and uses those to answer. This is faster and cheaper on big libraries, but it can miss things.
The authors built a giant benchmark (a standardized test) called ConvoMem with 75,336 question–answer pairs. It checks six kinds of “memory” that matter in real life, especially at work:
- User facts: simple things you told the assistant (your job title, your time zone).
- Assistant facts: things the assistant said before (what it recommended last time).
- Abstention: admitting “I don’t know” when the info isn’t in the history (not guessing).
- Preferences: what you like and how you work (e.g., you prefer React for front-end).
- Changing facts: updates that replace old info (meeting moved from Tuesday to Friday).
- Implicit connections: reading between the lines (you broke your ankle, so don’t suggest hiking).
Real conversations spread info across multiple messages, not in one big chunk. So ConvoMem deliberately scatters “evidence” over 1–6 messages to test whether systems can gather pieces and connect dots.
To keep the test fair and robust:
- They generated all conversations in a consistent style (so models can’t cheat by spotting “odd” messages).
- They used multiple different AI models to both create and check the data, accepting only high-confidence cases.
- They evaluated memory systems at different history sizes (from just a couple of chats up to 300), and measured not only accuracy, but also cost and speed.
What they found and why it matters
Here are the big takeaways, explained with plain language and numbers where helpful:
- Long context is surprisingly strong early on.
- If you simply give the AI the full conversation history, it answers memory questions very well at the start and stays solid up to about 150 chats.
- On tough cases where evidence is scattered across several messages, long context still scores about 70–82% correct.
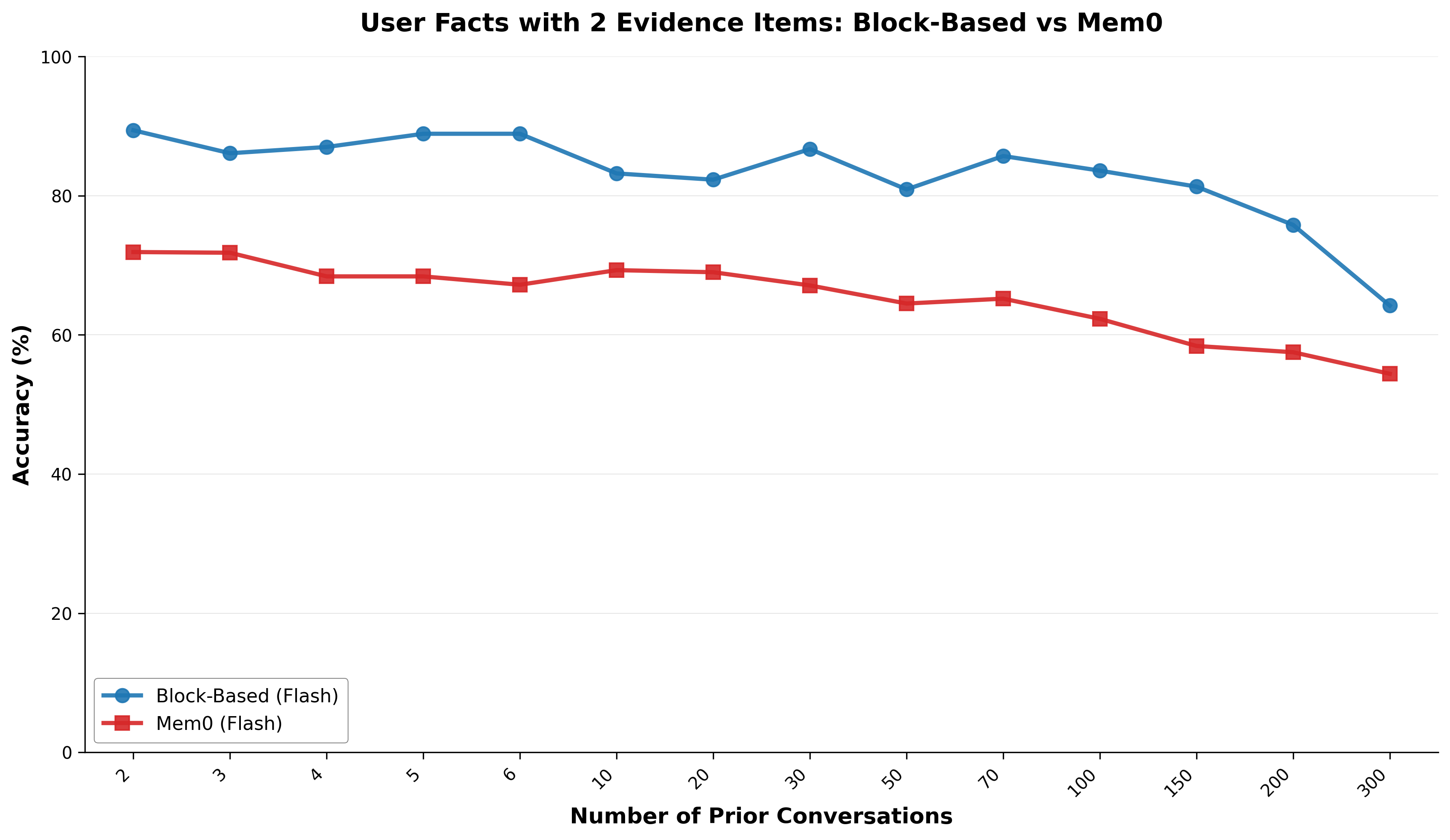
- Fancy RAG-style memory (like Mem0) is cheaper and faster at large scales, but it misses more.
- For many tasks with short histories, RAG-based systems only score around 30–45% on nuanced memory (like preferences or “read-between-the-lines” questions), while long context is much higher.
- As your history grows big (100–300 chats), RAG keeps responses cheap and reasonably fast. Long context gets slower and more expensive because you keep sending the whole notebook every time.
- There’s a clear “switch point.”
- Best accuracy and decent cost for the first 30 chats: use long context.
- Still viable with trade-offs up to ~150 chats.
- Beyond that, costs and delays for long context become a problem, so move to hybrid or RAG approaches.
- Medium-tier models often match premium models for memory tasks—at a fraction of the price.
- Mid-tier models delivered similar memory accuracy to top-tier ones in many cases, at around 8x lower cost.
- Very small models, though, lost a lot of accuracy on complex memory tasks.
- Small-corpus advantage: conversations are tiny compared to the whole web.
- Because your chat history is relatively small for a long time, “inefficient” tactics (like searching everything or re-ranking every item) actually work great early on. That’s not true when your “corpus” is a giant library of documents.
Why their benchmark (ConvoMem) is a big deal
Earlier tests were too small to be statistically solid or didn’t cover all the important memory skills. ConvoMem:
- Is large (75,336 Q/A), so differences between systems really mean something.
- Covers all six key memory abilities, including tricky ones like implicit connections and abstention.
- Spreads evidence across multiple messages on purpose, to mimic real conversations.
- Uses a consistent generation process, so systems can’t game the test by spotting stylistic differences.
This makes it a reliable way to measure progress and to guide engineering decisions.
What this means in practice
If you’re building or using a chat assistant:
- Start simple. For a new user with limited chat history, just pass the whole conversation to the model. You’ll get better accuracy early on with acceptable cost and speed.
- Watch your growth. As the user’s history approaches 100–150 chats, shift to a hybrid or RAG setup to keep costs and latency under control.
- Don’t overspend on the biggest model. Mid-tier models often get you nearly the same memory accuracy for much less money.
- Design for nuance. Retrieval systems struggle with scattered or subtle info (preferences, implicit connections). Hybrid strategies that first extract key bits and then answer can help bridge the gap.
In short, your first 150 conversations probably don’t need RAG. After that, they usually do. This paper gives you a solid test (ConvoMem) and a clear roadmap: start with long context for accuracy, move to hybrid/RAG as histories grow, and pick model sizes that balance cost and performance.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable items for future research.
- Ecological validity: Validate the benchmark and findings on real, human, multi-session conversations (with noise, typos, topic drift, code snippets, attachments) beyond synthetic enterprise personas to assess generalizability.
- Multilingual coverage: Extend the dataset and evaluation to non-English dialogues, mixed-language sessions, and code-switching to test memory across languages and cultural contexts.
- Multimodal memory: Incorporate and evaluate image, file, and spreadsheet attachments common in enterprise workflows to measure memory across modalities (a gap compared to LoCoMo).
- Reproducibility and release details: Specify and release generation prompts, seeds, full model versions, validation consensus criteria, code, and train/dev/test splits (with licenses) to enable exact replication.
- LLM-as-judge reliability: Quantify rubric-based and abstention evaluations’ inter-rater reliability, bias, and stability across judge models; publish calibration studies and adjudication protocols.
- Statistical rigor transparency: Report per-category confidence intervals, variance, hypothesis tests, and effect sizes; specify the statistical methodology used to claim ≤±2% CIs and significant differences.
- Category balance limitations: Address skewed evidence distributions (e.g., Preferences: 4,982 single-message vs only 97 two-message; Assistant Facts: heavily single-message; Implicit Connections capped at 3 messages) that may favor simpler retrieval and underrepresent hard multi-message synthesis for these categories.
- Multi-message complexity ceiling: Extend multi-message scenarios for Preferences and Implicit Connections beyond 3 messages, and for Changing Facts beyond 6, to stress-test synthesis and temporal reasoning at higher complexity.
- Ground-truth construction: Detail how multi-message “all pieces are essential” constraints were validated and how edge cases (partially sufficient evidence) are handled to prevent shortcuts.
- Abstention calibration: Measure and report calibration metrics (precision, recall of abstention, false-positive hallucination rates) and how varied phrasings of “I don’t know” are judged.
- Alternative scoring metrics: Include graded correctness, partial credit, F1, calibration, and confidence scoring (not just accuracy) for nuanced categories like Preferences and Implicit Connections.
- Confound between memory and reading comprehension: Design controls to disentangle long-context “reading all text” from true memory retrieval (e.g., shuffled contexts, adversarial distractors, controlled evidence saliency).
- Broader baseline coverage: Evaluate additional RAG/memory systems (GraphRAG, Zep, HippoRAG, summary-based memory, BM25 vs dense retrieval with reranking) to avoid overgeneralizing from Mem0 alone.
- Retrieval granularity and aggregation: Investigate indexing granularity, chunking policies, and multi-hop aggregation strategies that might reduce Mem0’s multi-fact degradation (e.g., 61% → 25% from 1 → 6 evidence items).
- Failure mode analysis: Provide systematic error taxonomy for each category (e.g., temporal ordering failures in Changing Facts, entity resolution errors in User/Assistant Facts, implicit inference misses) with targeted ablations.
- Transition thresholds methodology: Formalize the “30–50” and “~150 conversations” transition points (accuracy, latency, cost curves) with sensitivity analysis across models, pricing tiers, hardware, and workload distributions.
- Cost/latency generalization: Replicate cost and latency measurements across multiple providers (OpenAI, Anthropic, open-source LLMs) and contexts (streaming vs batch, concurrency, caching on/off) to validate economic conclusions.
- Mid-tier model sweet spot robustness: Test the Flash-class vs Pro vs Lite conclusions across diverse model families to confirm that mid-tier models consistently saturate memory performance at lower cost.
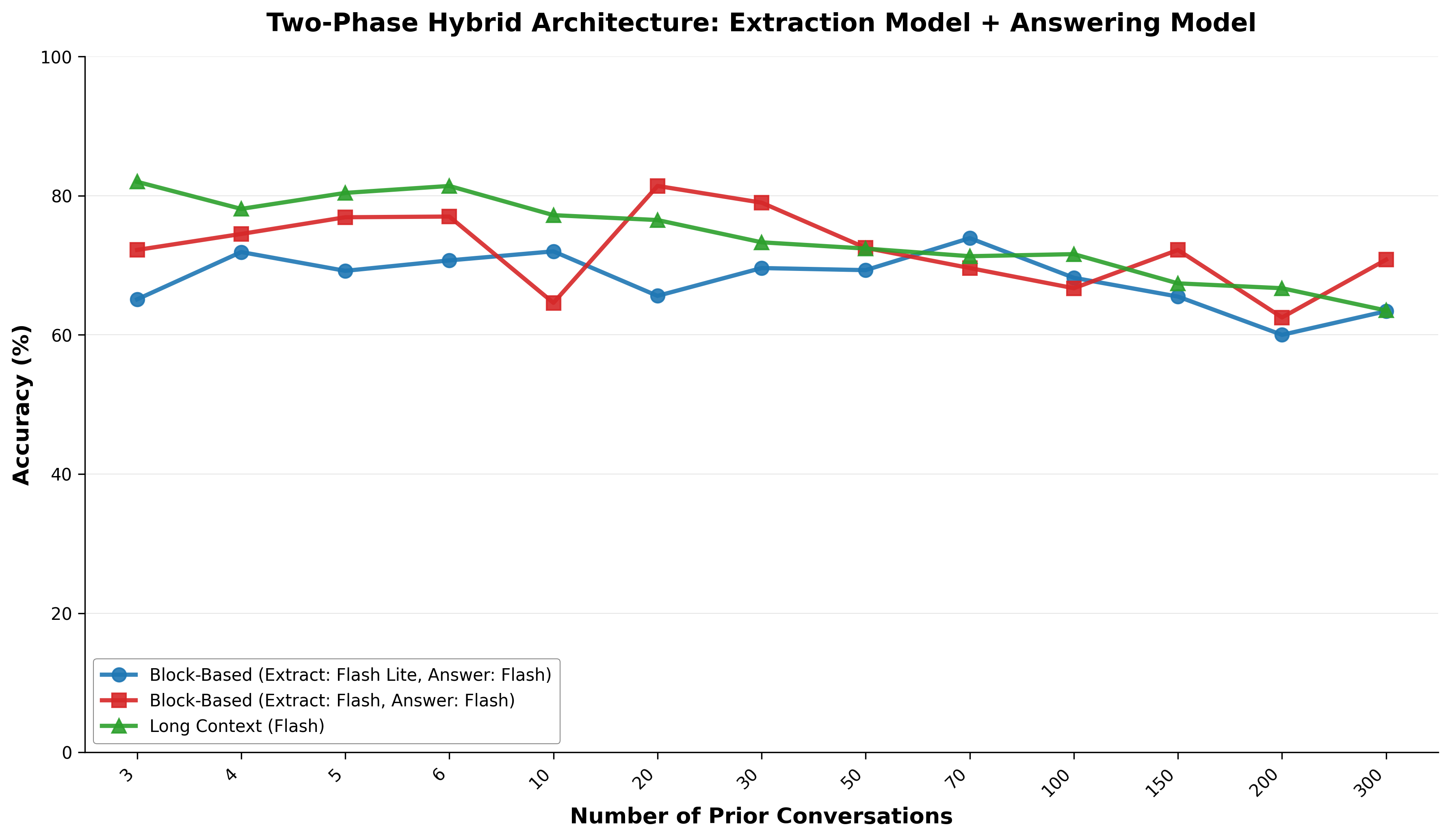
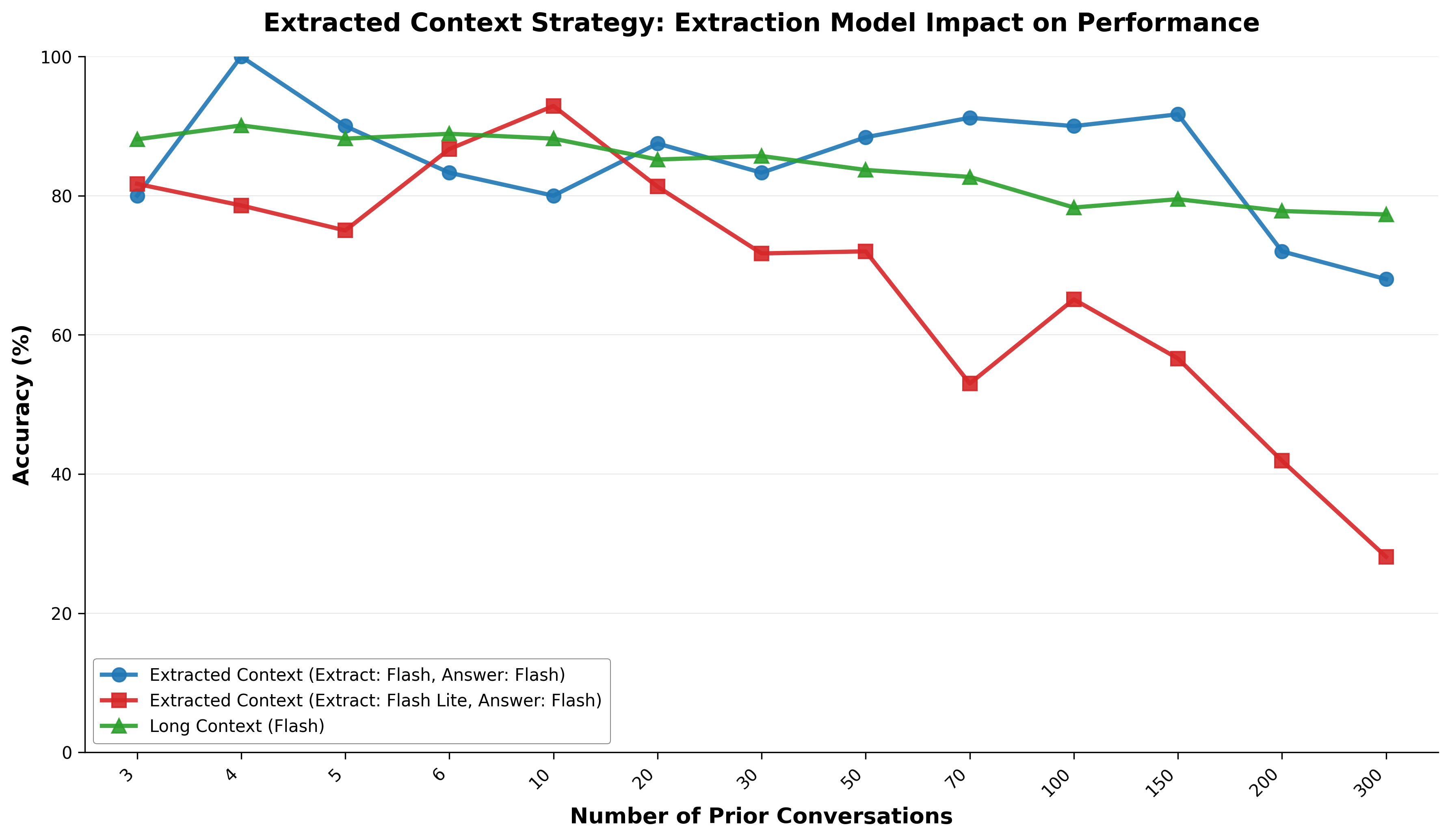
- Hybrid extraction completeness: Finish and expand the hybrid two-phase evaluation across all categories, report block-size tuning, model pairing strategies, adaptive segmentation, cost/latency overheads (30 API calls vs single request), and break-even analyses.
- Dynamic switching policies: Develop and evaluate algorithms that adaptively switch among long-context, hybrid, and RAG strategies per user and task, based on live signals (context size, evidence dispersion, latency budget).
- Temporal reasoning edge cases: Add tests for relative time references, timezone changes, rolling windows, and conflicting updates across sessions to probe more realistic temporal complexity.
- Assistant-side memory depth: Go beyond recalling prior recommendations to tracking commitments, actions taken, reversals, and contradictions; evaluate self-consistency and accountability over time.
- Privacy, compliance, and safety: Analyze memory retention, deletion (REPLACE/DELETE), consent, access control, and leakage across multi-user/team settings; include privacy-preserving retrieval evaluations.
- Memory interference and forgetting: Study how long histories introduce interference, contamination, or outdated context; quantify the benefits of selective forgetting, summarization, and recency weighting.
- Session and scope boundaries: Evaluate per-project or per-tenant memory isolation, cross-session scoping, and leakage detection—critical in enterprise deployments.
- Scalability beyond 300 conversations: Test performance on very long histories (e.g., 1M+ tokens) with modern ultra-long-context models, and compare with compressed memory and graph approaches.
- Style artifact resistance: Stress-test the unified generation pipeline against potential stylistic cues by introducing adversarial perturbations to ensure models cannot infer evidence placement from style alone.
- Evidence saliency and distraction: Add benchmarks with heavy distractor content and topic drift to quantify robustness of memory retrieval under realistic noise.
- Summarization-based memory: Benchmark hierarchical summarization and episodic condensation approaches as alternatives to full-context, hybrid, and RAG, including their accuracy/cost/latency trade-offs.
- Human-centered quality metrics: Measure user-perceived helpfulness, trust, and satisfaction for memory-dependent interactions, not just correctness, to assess practical value.
- Release governance: Clarify data privacy in synthetic personas and conversations, and provide guidelines for safe use and extension of the benchmark in regulated environments.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed today, drawing directly from the paper’s findings on long-context effectiveness, benchmark coverage, and operational patterns. Each item notes sector relevance, potential tools/workflows, and feasibility assumptions.
- Progressive memory strategy for chat assistants without early RAG
- Sectors: software, CRM/customer support, education, healthcare, finance
- What to deploy: Start with full-context memory for the first 30–50 conversations (extend up to ~150 with cost/latency monitoring), then plan a switch to hybrid/RAG as histories grow. Implement a policy gate that checks conversation length and automatically selects “long context” or “hybrid extraction.”
- Tools/workflows: Context-window packer; threshold-based routing; conversation-length monitor; cost/latency dashboard
- Assumptions/dependencies: Availability of mid-tier LLMs with ≥100K–1M token window; your user histories stay under ~150 interactions for most accounts; pricing is similar to reported ranges
- Cost-optimized model selection for memory tasks
- Sectors: software platforms, enterprise AI ops, finance, education
- What to deploy: Choose mid-tier models (Flash-class) for long context memory—near-premium accuracy at ~3–8x lower cost. Avoid ultra-light models (Flash Lite-class) for complex multi-message scenarios.
- Tools/workflows: Model policy manager; per-model cost tracking; AB testing using ConvoMem categories
- Assumptions/dependencies: Model pricing and context windows align with current market; tasks include multi-message recall and implicit reasoning where mid-tier models outperform small models
- Memory QA and regression testing using ConvoMem
- Sectors: software, academia, enterprise AI, MLOps
- What to deploy: Integrate the ConvoMem benchmark into CI to measure recall (user/assistant facts), abstention, changing facts, preferences, and implicit connections. Use category-level metrics to detect regressions.
- Tools/workflows: Test harness; category-based scorecards; CI gating on memory accuracy; synthetic conversation generation pipeline
- Assumptions/dependencies: Benchmark access; compute budget to run selected subsets; domain similarity (enterprise-focused personas)
- Guardrails for abstention (reducing hallucinations)
- Sectors: healthcare, finance, legal, customer support
- What to deploy: Explicit abstention handling when facts are missing (return “cannot answer” with helpful next steps). Evaluate with ConvoMem’s abstention category.
- Tools/workflows: Answer classification layer; “unknown” response template; escalation workflows
- Assumptions/dependencies: Clear policy/legal guidance on uncertainty; user experience design supports abstention and follow-up questions
- Change tracking and conflict resolution in conversation memory
- Sectors: project management, CRM, finance, healthcare
- What to deploy: Recency-aware memory with REPLACE/DELETE semantics to keep the final state accurate (e.g., meeting time changes, updated holdings, changed preferences).
- Tools/workflows: Update detectors; versioned memory entries; recency weighting
- Assumptions/dependencies: Conversation logs are timestamped; your system can parse and apply corrections consistently
- Multi-message synthesis for personal assistants and customer support
- Sectors: daily productivity, CRM, IT helpdesk
- What to deploy: Aggregate facts across multiple messages for tasks like calculating current stock holdings or compiling customer constraints (budget, timeline, requirements).
- Tools/workflows: Evidence aggregator; conversation slicing; consistency checks
- Assumptions/dependencies: Long-context models can handle multi-message patterns reliably; UX supports verification of synthesized results when high stakes
- Memory-aware recommendation tuning for preferences
- Sectors: education, software tooling, consumer apps
- What to deploy: Adapt recommendations (e.g., React-based tools for users expressing React preference) using preference signals mined from previous conversations.
- Tools/workflows: Preference extractor; policy rules; rubric-based evaluation (ConvoMem’s preference rubrics)
- Assumptions/dependencies: Enough preference signals exist in chats; preferences remain stable unless updated via “changing facts”
- Latency and cost SLOs with automatic mode switching
- Sectors: enterprise AI ops, customer support platforms
- What to deploy: Monitor latency/cost by conversation length; switch to hybrid extraction when long-context latency exceeds thresholds (often after 10–20 conversations) or costs rise beyond budget.
- Tools/workflows: SLO manager; telemetry; automatic routing; user-level budget controls
- Assumptions/dependencies: Accurate telemetry and per-request cost accounting; hybrid pipeline available as fallback
- Enterprise procurement and vendor evaluation with a memory benchmark
- Sectors: enterprise/IT, procurement, policy compliance
- What to deploy: Use ConvoMem to compare vendors/models on memory-specific competencies under realistic multi-message setups; weight abstention and implicit reasoning for high-risk use cases.
- Tools/workflows: Vendor test suite; scorecards; category-specific thresholds; procurement checklist
- Assumptions/dependencies: Vendors agree to standardized tests; coverage of enterprise scenarios fits your needs
- Conversation-caching and batch evaluation to reduce ops costs
- Sectors: enterprise AI ops, MLOps
- What to deploy: Reuse cached prefixes and batch balanced test cases; employ early termination when metrics converge to reduce evaluation spend by 40–60%.
- Tools/workflows: Prefix cache; batch scheduler; convergence monitor
- Assumptions/dependencies: Stable conversation structures; repeated prefixes across users; engineering capacity to implement caching
- Responsible memory governance (privacy, retention, deletion)
- Sectors: policy/compliance, healthcare, finance, consumer apps
- What to deploy: Memory retention windows matched to “small-corpus advantage,” with configurable deletion, redaction, and opt-out; implement explicit update/delete operations for user control.
- Tools/workflows: Consent management; audit logs; deletion APIs; privacy dashboards
- Assumptions/dependencies: Legal/regulatory requirements (GDPR/CCPA/HIPAA); internal data governance policies; auditability of memory operations
- Instructor and researcher toolkit for memory-RAG differentiation
- Sectors: academia, edtech
- What to deploy: Use the benchmark’s categories to teach and study memory vs RAG, highlighting the small-corpus advantage and multi-message evidence dimension.
- Tools/workflows: Course modules; lab assignments; comparative experiments (long context vs RAG vs hybrid)
- Assumptions/dependencies: Access to campus compute and LLM APIs; fairness controls across model families
Long-Term Applications
The following applications will benefit from more research, engineering scale-up, or broader ecosystem maturation (e.g., standardized frameworks, better hybrid strategies).
- Auto-progressive memory architecture “orchestrator”
- Sectors: software platforms, enterprise AI
- What to build: An engine that automatically transitions from full-context to block-based extraction to RAG, based on conversation length, latency, cost, and accuracy targets.
- Tools/workflows: Policy engine; multi-armed bandit for routing; performance predictors
- Assumptions/dependencies: Reliable breakpoints (~30–50, ~100–150 conversations) generalize across domains; robust hybrid components exist
- Two-phase, block-based extraction productization
- Sectors: CRM/support, developer tools, education
- What to build: A scalable pipeline that slices conversations into blocks (e.g., 10-message chunks), extracts salient facts/preferences, then answers using only extracted context to reduce token costs while maintaining accuracy.
- Tools/workflows: Block slicer; extraction model (possibly smaller); answer model (mid-tier); multi-call optimization
- Assumptions/dependencies: Economic benefit offsets overhead of multiple API calls; extraction quality remains high across domains
- Memory graphs with dynamic versioning and implicit reasoning
- Sectors: enterprise knowledge systems, healthcare, finance
- What to build: Graph-structured conversation memory with explicit REPLACE/DELETE, temporal ordering, and implicit connection edges that influence recommendations.
- Tools/workflows: Knowledge graph builder; graph retriever; temporal reasoner; implicit-link mining
- Assumptions/dependencies: Robust entity resolution; reliable change detection; governance for graph updates and privacy
- Standardized memory benchmarks for procurement and regulation
- Sectors: policy, enterprise procurement, compliance
- What to build: Sector-specific benchmark suites (e.g., healthcare consent/abstention, finance updates/accuracy thresholds), plus certification processes and reporting templates.
- Tools/workflows: Domain scenario libraries; auditing protocols; score normalization across models/vendors
- Assumptions/dependencies: Industry buy-in; legal alignment; stable evaluation APIs and datasets
- Memory-aware UX patterns (verification and correction loops)
- Sectors: consumer apps, education, healthcare
- What to build: Interfaces that help users verify memory-derived answers (especially multi-message synthesis) and easily correct outdated facts or preferences.
- Tools/workflows: Inline memory citations; “confirm or correct” prompts; memory diff views; edit histories
- Assumptions/dependencies: User acceptance of extra steps; low friction designs; secure storage of edit logs
- On-device early memory with cloud offload after threshold
- Sectors: mobile, IoT, edge AI
- What to build: Run long-context memory locally for the first conversations to reduce latency and enhance privacy; offload to hybrid/RAG in the cloud as histories exceed device capacity.
- Tools/workflows: Edge model deployment; encrypted sync; threshold offload orchestrator
- Assumptions/dependencies: Sufficient on-device context window and compute; secure handoff protocols
- Memory SLOs and cost-aware routing at enterprise scale
- Sectors: AI ops, multi-tenant platforms
- What to build: Global SLO policies for latency/cost/accuracy with automatic routing to long-context, hybrid, or RAG pipelines per tenant/account and time-of-day pricing.
- Tools/workflows: SLO manager; real-time telemetry; policy compiler; sandbox testing
- Assumptions/dependencies: Accurate forecasting; transparent, predictable LLM pricing; reliable observability
- Domain-adapted extraction models and distillation for memory tasks
- Sectors: healthcare, finance, legal, education
- What to build: Train small extraction models specialized in multi-message synthesis, change tracking, and abstention; distill from larger models using ConvoMem categories.
- Tools/workflows: Fine-tuning pipelines; distillation frameworks; continuous evaluation
- Assumptions/dependencies: Legal data access for training; label quality; transferability of benchmark signals to real-world conversations
- Privacy-preserving memory operations with granular controls
- Sectors: policy/compliance, consumer apps
- What to build: Differential privacy or federated approaches for memory extraction; granular retention and redaction aligned to user segments and regulatory regimes.
- Tools/workflows: DP/federated pipelines; user-level controls; compliance auditing
- Assumptions/dependencies: Mature privacy tech; regulatory clarity; cross-jurisdiction policy harmonization
- Cross-benchmark unification and reproducibility standards
- Sectors: academia, standards bodies
- What to build: A common framework that harmonizes LongMemEval, LoCoMo, ConvoMem, etc., with consistent generation/validation methods to avoid stylistic shortcuts and ensure statistical power.
- Tools/workflows: Shared data schemas; generation recipes; multi-model validation; open leaderboards
- Assumptions/dependencies: Community consensus; funding for maintenance; model providers supporting standardized evaluation APIs
- Sector-specific assistants that exploit the small-corpus advantage
- Sectors: vertical SaaS (sales, support, IT), clinics, classrooms
- What to build: Assistants designed to operate effectively within the first ~150 conversations—e.g., a clinic intake assistant tracking patient changes, a classroom tutor tracking student progress—before gradually adding RAG integrations.
- Tools/workflows: Domain ontologies; per-user memory policies; progressive feature unlocks
- Assumptions/dependencies: Conversation patterns fit small-corpus profiles; careful rollout of RAG to avoid sudden cost spikes or accuracy dips
- Memory performance scorecards for enterprise SLAs and billing
- Sectors: enterprise platforms, managed AI services
- What to build: Offer tiered SLAs for memory accuracy, abstention correctness, and latency; billing calibrated to conversation-length tiers and memory pipeline used.
- Tools/workflows: SLA contracts; reporting dashboards; usage-based billing integration
- Assumptions/dependencies: Reliable, reproducible measurement; customer acceptance of tiered memory guarantees; integration with finance systems
These applications lean on the paper’s core insights: the small-corpus advantage for conversational memory, the practical breakpoints for switching strategies, the strength of long-context on nuanced tasks within early histories, and the need for robust, statistically powered evaluation across categories (including multi-message evidence, change tracking, and abstention).
Glossary
- Abstention: The deliberate choice to not answer when required information is missing to avoid hallucination. "Abstention tests whether systems avoid hallucination when information is absent."
- Block-based extraction: A hybrid strategy that processes conversations in fixed-size blocks to extract relevant information before answering. "Block-based extraction divides conversations into blocks of 10, extracts relevant information from each block independently, then aggregates the extracted information for final answer generation."
- Confidence intervals: A statistical range that expresses uncertainty around an estimate at a given confidence level. "This scale enables statistically significant results with confidence intervals under 2\% for major categories while providing sufficient data for training memory-aware systems through supervised learning."
- Conversational memory: An assistant’s capability to use prior conversations to produce more helpful, context-aware responses. "For the purposes of this paper, we use ``conversational memory'' as a convenient umbrella term for a chat assistant's ability to leverage prior conversations to provide more helpful and contextually aware responses."
- Dynamic indexing: Frequently rebuilding indices as data evolves to keep retrieval accurate and up to date. "Dynamic indexing: Indices can be rebuilt frequently as conversations evolve"
- Exhaustive search: Brute-force scanning of the entire corpus rather than relying on approximate retrieval. "Exhaustive search: With only hundreds rather than billions of text chunks, brute-force search becomes feasible"
- Forensic capabilities: Instrumentation and analyses used to diagnose and understand system behavior and failures during evaluation. "The framework's forensic capabilities proved invaluable---revealing, for instance, that changing facts questions fail not because systems can't find updates but because they struggle with temporal ordering when multiple changes occur."
- Full attention mechanisms: Using attention over the entire available context window instead of truncated subsets. "Full attention mechanisms: Entire conversation histories can fit within transformer attention windows"
- Graph-augmented memory: A memory approach that encodes entities and relations in a graph to improve retrieval and reasoning. "Mem0's graph-augmented memory achieving 26\% accuracy improvements \citep{arxiv:(Chhikara et al., 28 Apr 2025)}"
- Graph-structured representations: Data models that encode entities and their relationships as a graph for retrieval and reasoning. "Graph-structured representations have emerged independently in both domains---Zep and Mem0 for conversations, GraphRAG for documents---as the optimal architecture for capturing entity relationships \citep{arxiv:(Rasmussen et al., 20 Jan 2025), arxiv:(Chhikara et al., 28 Apr 2025), url:https://microsoft.github.io/graphrag/}."
- Hybrid extraction approaches: Two-stage pipelines that combine extraction and answer generation to balance accuracy and cost. "To address the scalability limitations of long context while maintaining higher accuracy than pure RAG systems, we developed hybrid extraction approaches that combine the benefits of both paradigms."
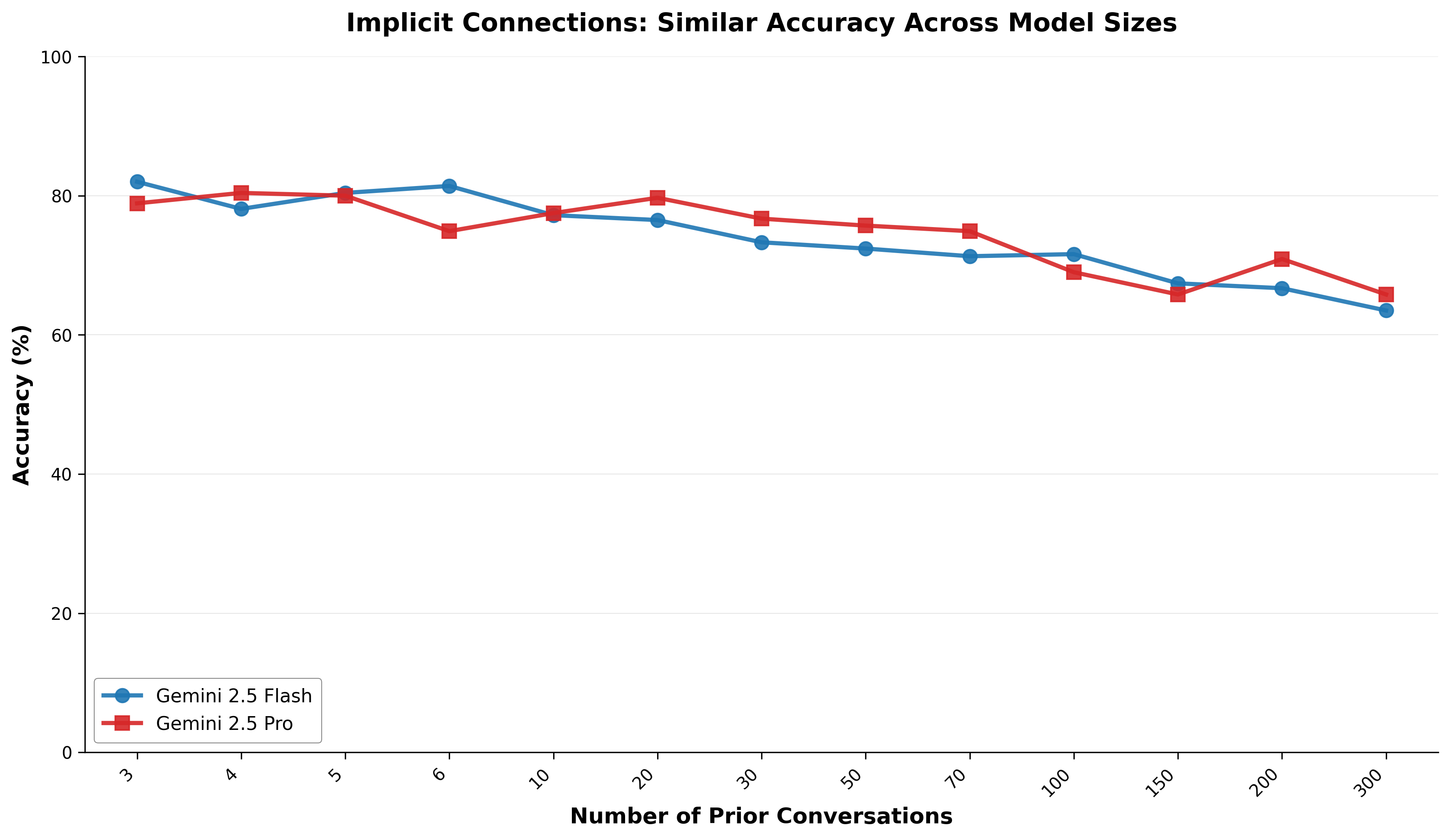
- Implicit connections: Unstated contextual links that should inform answers and recommendations. "Implicit connections test the invisible threads of context---the unspoken considerations that should shape every recommendation."
- Implicit information extraction: Inferring and connecting incomplete or indirectly stated information during retrieval. "Implicit information extraction challenges both to resolve semantically incomplete inputs, driving evolution from simple slot-filling to sophisticated reasoning frameworks that extract and relate information fragments \citep{arxiv:(Guan et al., 28 Mar 2025), arxiv:(Kim et al., 13 Sep 2025), arxiv:(Ji et al., 29 Mar 2025)}."
- Knowledge update mechanisms: Methods for handling corrections and contradictions by updating stored knowledge. "Knowledge update mechanisms force both to handle contradictions and corrections, evolving from recency heuristics to explicit versioning systems with REPLACE and DELETE operations \citep{arxiv:(Bae et al., 2022)}."
- Long context: Supplying the model with the full conversation history within its context window. "Consistent with recent findings on long context effectiveness, we observe that simple full-context approaches achieve 70-82\% accuracy even on our most challenging multi-message evidence cases, while sophisticated RAG-based memory systems like Mem0 achieve only 30-45\% when operating on conversation histories under 150 interactions."
- Long context memory: An approach that answers by placing all prior conversations directly in the model’s context. "Long context memory---placing all prior conversations directly in the model's context---represents the simplest implementation yet consistently achieves the highest accuracy."
- Model-agnostic evaluation: An evaluation methodology that remains fair and applicable across different model families and architectures. "We ensure model-agnostic evaluation by employing systematic diversity in both generation and validation."
- Multi-message evidence: Relevant information distributed across several messages that must be combined to answer correctly. "Different evidence categories use tailored validation approaches---multi-message evidence requires all pieces to be essential, abstention accepts ``I don't know'' as correct, and preference categories use rubric-based evaluation (see Appendix A for complete validation protocols)."
- Needle in the haystack: A stress-test paradigm for finding small pieces of information in very large contexts. "aligns with findings from ``needle in the haystack'' literature on long context performance \citep{arxiv:(Moon et al., 30 Jul 2025)}."
- Progressive growth: A property where the memory corpus starts empty and expands incrementally with user interactions. "The most distinctive characteristic of conversational memory systems is their progressive growth from an empty state."
- RAG-based memory systems: Memory architectures that index and retrieve from conversation histories using RAG-like pipelines. "RAG-based memory systems like Mem0 achieve only 30-45\% when operating on conversation histories under 150 interactions."
- Retrieval-augmented generation (RAG): Systems that improve responses by retrieving relevant external information and conditioning generation on it. "When we examine conversational memory as a research area, we find it has substantial overlap with retrieval-augmented generation (RAG)."
- Rubric-based evaluation: Assessing answers against a predefined rubric of criteria rather than a single gold answer. "and preference categories use rubric-based evaluation (see Appendix A for complete validation protocols)."
- Small-corpus advantage: Performance benefits enabled by small search spaces that allow naive yet accurate strategies. "These patterns indicate that the small-corpus advantage of conversational memory---where exhaustive search and complete reranking are feasible---deserves dedicated research attention rather than simply applying general RAG solutions to conversation histories."
- Statistical power: The ability of a study to detect true effects given sample size, variance, and effect size. "This comparison reveals several critical gaps in existing benchmarks: (1) statistical power---our 75,336 questions provide 150x more data than LongMemEval's 500, enabling meaningful statistical analysis;"
- Temporal knowledge graphs: Graphs that encode entities and relations with temporal information to track changes over time. "Zep's temporal knowledge graphs reducing latency by 90\% \citep{arxiv:(Rasmussen et al., 20 Jan 2025)}"
- Temporal ordering: Reasoning about the correct sequence of events or updates over time. "The framework's forensic capabilities proved invaluable---revealing, for instance, that changing facts questions fail not because systems can't find updates but because they struggle with temporal ordering when multiple changes occur."
- Temporal reasoning: Understanding and resolving time references and validity in context. "Temporal reasoning requires both to resolve ambiguous time references (
yesterday'' in conversations,recently'' in documents) and manage information validity over time, leading both fields to develop explicit timeline construction mechanisms \citep{arxiv:(Kenneweg et al., 2 May 2025), arxiv:(Bae et al., 2022), arxiv:(Piryani et al., 26 May 2025)}." - Two-phase architecture: A pipeline that separates information extraction from final answer generation. "These approaches employ a two-phase architecture that separates information extraction from answer generation"
- Versioning systems: Mechanisms that maintain explicit versions of facts (with operations like replace/delete) to handle updates. "evolving from recency heuristics to explicit versioning systems with REPLACE and DELETE operations \citep{arxiv:(Bae et al., 2022)}."
Collections
Sign up for free to add this paper to one or more collections.