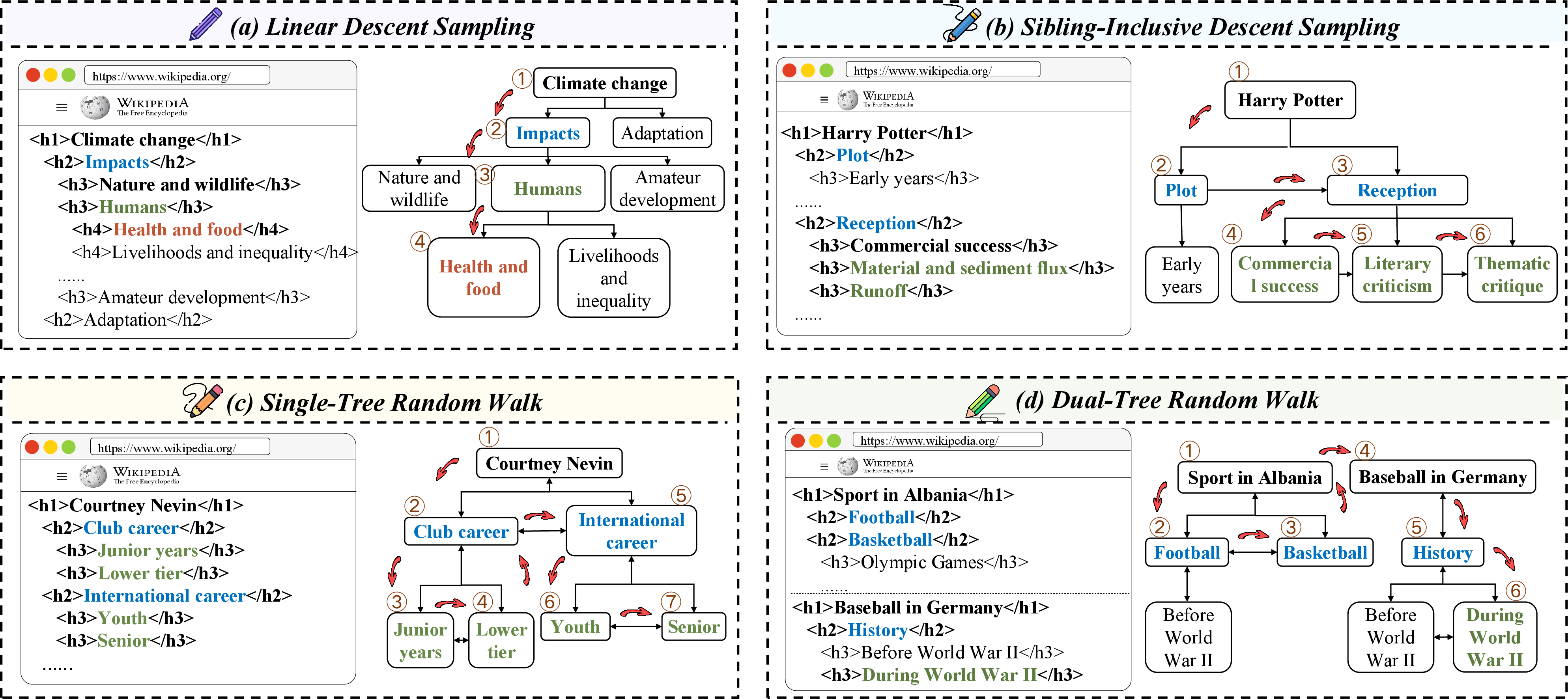
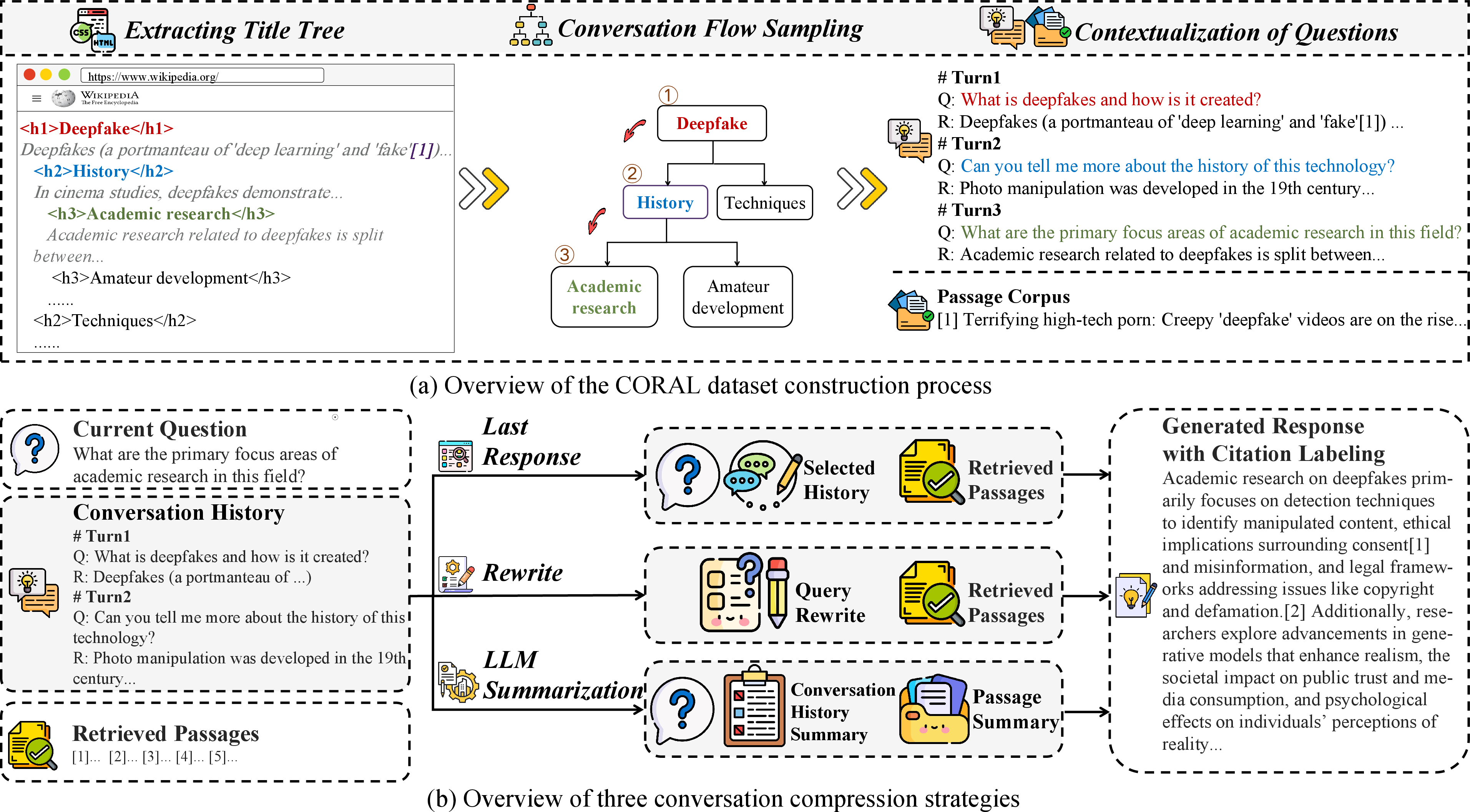
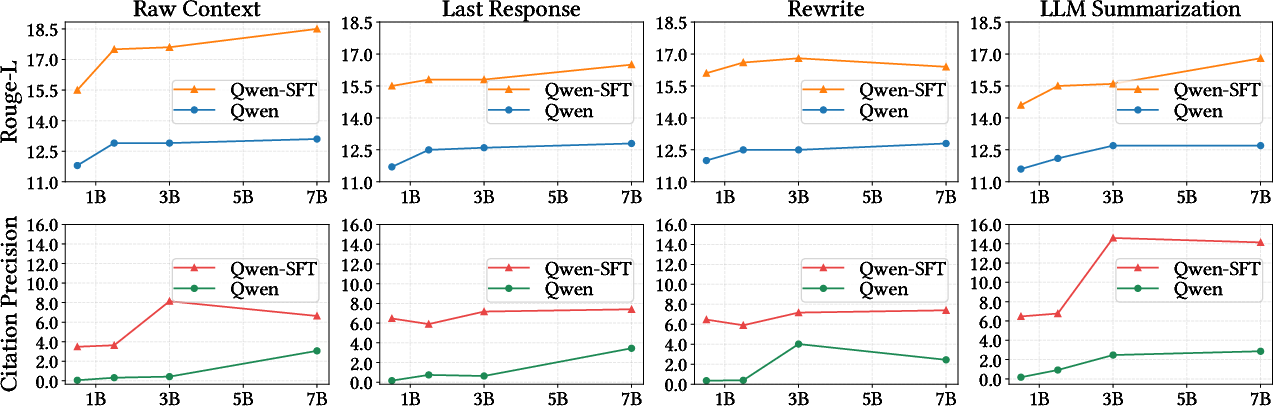
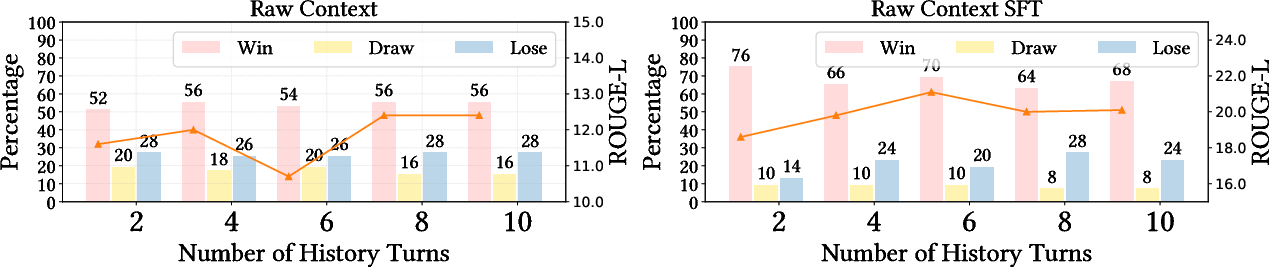
CORAL: Benchmarking Multi-turn Conversational Retrieval-Augmentation Generation
Abstract: Retrieval-Augmented Generation (RAG) has become a powerful paradigm for enhancing LLMs through external knowledge retrieval. Despite its widespread attention, existing academic research predominantly focuses on single-turn RAG, leaving a significant gap in addressing the complexities of multi-turn conversations found in real-world applications. To bridge this gap, we introduce CORAL, a large-scale benchmark designed to assess RAG systems in realistic multi-turn conversational settings. CORAL includes diverse information-seeking conversations automatically derived from Wikipedia and tackles key challenges such as open-domain coverage, knowledge intensity, free-form responses, and topic shifts. It supports three core tasks of conversational RAG: passage retrieval, response generation, and citation labeling. We propose a unified framework to standardize various conversational RAG methods and conduct a comprehensive evaluation of these methods on CORAL, demonstrating substantial opportunities for improving existing approaches.
- Topiocqa: Open-domain conversational question answering with topic switching. Transactions of the Association for Computational Linguistics, 10:468–483.
- Moonshot AI. 2023. Kimi chat.
- Open-domain question answering goes conversational via question rewriting. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, pages 520–534. Association for Computational Linguistics.
- Anthropic. 2023. Introducing claude.
- Crafting the path: Robust query rewriting for information retrieval. CoRR, abs/2407.12529.
- Generalizing conversational dense retrieval via llm-cognition data augmentation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 2700–2718. Association for Computational Linguistics.
- Dialog inpainting: Turning documents into dialogs. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pages 4558–4586. PMLR.
- Cast 2020: The conversational assistance track overview. In Proceedings of the Twenty-Ninth Text REtrieval Conference, TREC 2020, Virtual Event [Gaithersburg, Maryland, USA], November 16-20, 2020, volume 1266 of NIST Special Publication. National Institute of Standards and Technology (NIST).
- TREC cast 2019: The conversational assistance track overview. CoRR, abs/2003.13624.
- TREC cast 2021: The conversational assistance track overview. In Proceedings of the Thirtieth Text REtrieval Conference, TREC 2021, online, November 15-19, 2021, volume 500-335 of NIST Special Publication. National Institute of Standards and Technology (NIST).
- Wizard of wikipedia: Knowledge-powered conversational agents. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net.
- Longrope: Extending LLM context window beyond 2 million tokens. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net.
- Toward general instruction-following alignment for retrieval-augmented generation. arXiv preprint arXiv:2410.09584.
- Understand what LLM needs: Dual preference alignment for retrieval-augmented generation. CoRR, abs/2406.18676.
- The llama 3 herd of models. CoRR, abs/2407.21783.
- doc2dial: A goal-oriented document-grounded dialogue dataset. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 8118–8128. Association for Computational Linguistics.
- Enabling large language models to generate text with citations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 6465–6488. Association for Computational Linguistics.
- REALM: retrieval-augmented language model pre-training. CoRR, abs/2002.08909.
- Yizheng Huang and Jimmy Huang. 2024. A survey on retrieval-augmented text generation for large language models. CoRR, abs/2404.10981.
- Mistral 7b. CoRR, abs/2310.06825.
- Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 1658–1677. Association for Computational Linguistics.
- BIDER: bridging knowledge inconsistency for efficient retrieval-augmented llms via key supporting evidence. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 750–761. Association for Computational Linguistics.
- Instructor: Instructing unsupervised conversational dense retrieval with large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pages 6649–6675. Association for Computational Linguistics.
- Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535–547.
- Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 6769–6781. Association for Computational Linguistics.
- Vaibhav Kumar and Jamie Callan. 2020. Making information seeking easier: An improved pipeline for conversational search. In Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, volume EMNLP 2020 of Findings of ACL, pages 3971–3980. Association for Computational Linguistics.
- Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, Koblenz, Germany, October 23-26, 2023, pages 611–626. ACM.
- Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Can query expansion improve generalization of strong cross-encoder rankers? In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, pages 2321–2326. ACM.
- Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81.
- Contextualized query embeddings for conversational search. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 1004–1015. Association for Computational Linguistics.
- Multi-stage conversational passage retrieval: An approach to fusing term importance estimation and neural query rewriting. ACM Transactions on Information Systems (TOIS), 39(4):1–29.
- Conversational question reformulation via sequence-to-sequence architectures and pretrained language models. CoRR, abs/2004.01909.
- Large language model is not a good few-shot information extractor, but a good reranker for hard samples! In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pages 10572–10601. Association for Computational Linguistics.
- Chatretriever: Adapting large language models for generalized and robust conversational dense retrieval. CoRR, abs/2404.13556.
- Large language models know your contextual search intent: A prompting framework for conversational search. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pages 1211–1225. Association for Computational Linguistics.
- Curriculum contrastive context denoising for few-shot conversational dense retrieval. In SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, pages 176–186. ACM.
- Convtrans: Transforming web search sessions for conversational dense retrieval. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 2935–2946. Association for Computational Linguistics.
- Learning denoised and interpretable session representation for conversational search. In Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 - 4 May 2023, pages 3193–3202. ACM.
- A survey of conversational search. arXiv preprint arXiv:2410.15576.
- Learning to relate to previous turns in conversational search. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6-10, 2023, pages 1722–1732. ACM.
- History-aware conversational dense retrieval. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 13366–13378. Association for Computational Linguistics.
- Convsdg: Session data generation for conversational search. In Companion Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, Singapore, May 13-17, 2024, pages 1634–1642. ACM.
- OpenAI. 2022. Openai: Introducing chatgpt.
- TREC cast 2022: Going beyond user ask and system retrieve with initiative and response generation. In Proceedings of the Thirty-First Text REtrieval Conference, TREC 2022, online, November 15-19, 2022, volume 500-338 of NIST Special Publication. National Institute of Standards and Technology (NIST).
- Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, July 6-12, 2002, Philadelphia, PA, USA, pages 311–318. ACL.
- Webbrain: Learning to generate factually correct articles for queries by grounding on large web corpus. CoRR, abs/2304.04358.
- Open-retrieval conversational question answering. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, pages 539–548. ACM.
- Parallel context windows for large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 6383–6402. Association for Computational Linguistics.
- Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249–266.
- Small models, big insights: Leveraging slim proxy models to decide when and what to retrieve for llms. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 4420–4436. Association for Computational Linguistics.
- ByteDance Doubao Team. 2023. Doubao.
- Qwen Team. 2024. Qwen2.5: A party of foundation models.
- Question rewriting for conversational question answering. In WSDM ’21, The Fourteenth ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, March 8-12, 2021, pages 355–363. ACM.
- Query resolution for conversational search with limited supervision. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, pages 921–930. ACM.
- Query2doc: Query expansion with large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 9414–9423. Association for Computational Linguistics.
- Richrag: Crafting rich responses for multi-faceted queries in retrieval-augmented generation. CoRR, abs/2406.12566.
- Learning to filter context for retrieval-augmented generation. CoRR, abs/2311.08377.
- CONQRR: conversational query rewriting for retrieval with reinforcement learning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 10000–10014. Association for Computational Linguistics.
- RECOMP: improving retrieval-augmented lms with compression and selective augmentation. CoRR, abs/2310.04408.
- List-aware reranking-truncation joint model for search and retrieval-augmented generation. In Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024, pages 1330–1340. ACM.
- Qwen2 technical report. arXiv preprint arXiv:2407.10671.
- PRCA: fitting black-box large language models for retrieval question answering via pluggable reward-driven contextual adapter. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 5364–5375. Association for Computational Linguistics.
- Boosting conversational question answering with fine-grained retrieval-augmentation and self-check. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, pages 2301–2305. ACM.
- Few-shot generative conversational query rewriting. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, pages 1933–1936. ACM.
- Few-shot conversational dense retrieval. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, pages 829–838. ACM.
- Llamafactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand. Association for Computational Linguistics.
- One token can help! learning scalable and pluggable virtual tokens for retrieval-augmented large language models. CoRR, abs/2405.19670.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.