AI use in American newspapers is widespread, uneven, and rarely disclosed
Abstract: AI is rapidly transforming journalism, but the extent of its use in published newspaper articles remains unclear. We address this gap by auditing a large-scale dataset of 186K articles from online editions of 1.5K American newspapers published in the summer of 2025. Using Pangram, a state-of-the-art AI detector, we discover that approximately 9% of newly-published articles are either partially or fully AI-generated. This AI use is unevenly distributed, appearing more frequently in smaller, local outlets, in specific topics such as weather and technology, and within certain ownership groups. We also analyze 45K opinion pieces from Washington Post, New York Times, and Wall Street Journal, finding that they are 6.4 times more likely to contain AI-generated content than news articles from the same publications, with many AI-flagged op-eds authored by prominent public figures. Despite this prevalence, we find that AI use is rarely disclosed: a manual audit of 100 AI-flagged articles found only five disclosures of AI use. Overall, our audit highlights the immediate need for greater transparency and updated editorial standards regarding the use of AI in journalism to maintain public trust.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how often American newspapers use AI to help write the articles you read online, which kinds of stories use AI the most, and whether newspapers tell readers when AI is involved.
What questions did the researchers ask?
The researchers wanted to answer, in simple terms:
- How much of today’s news is written partly or fully by AI?
- Where and when is AI used most (by topic, by newspaper size, by owner, by state, by language)?
- Do top national papers use AI in opinion pieces, and is that changing over time?
- Do newspapers clearly tell readers when AI helps write a story?
- When AI is used, does it usually replace the writer, or does it just help edit?
How did they study it?
To keep things fair and big enough to trust, they built three large collections of real newspaper articles and analyzed them.
The three datasets
- “Recent”: 186,000+ articles from 1,500+ U.S. newspapers, published online between June and September 2025 (lots of local and national outlets).
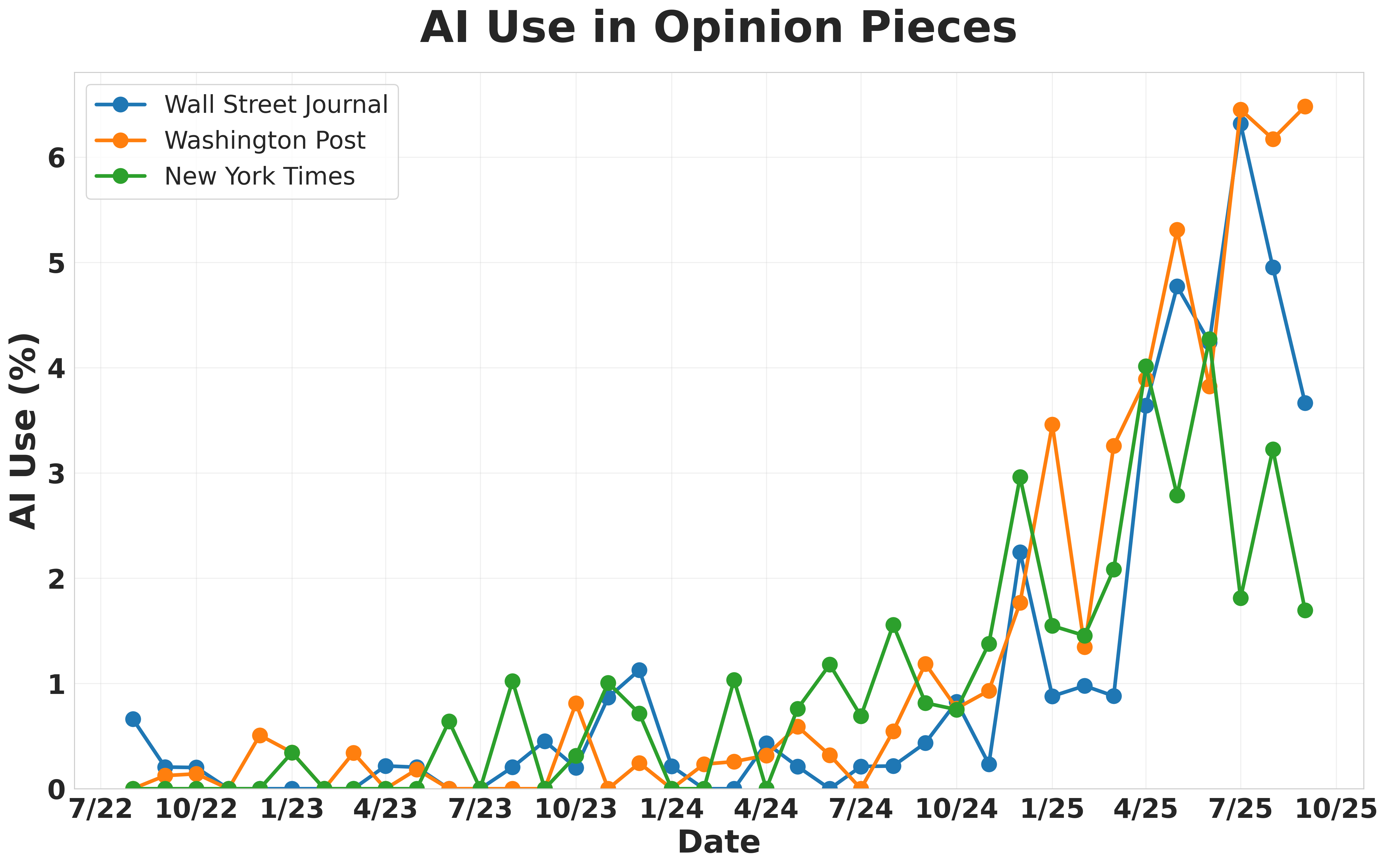
- “Opinions”: 45,000 opinion pieces from the New York Times, Washington Post, and Wall Street Journal (Aug 2022–Sept 2025).
- “AI (reporters)”: 20,000 articles by 10 long‑time reporters who wrote before and after ChatGPT came out, to see how their habits changed over time.
How they spotted AI writing
They used a tool called Pangram, which is like a metal detector—but for AI-written text. You feed in an article, and it predicts if the writing is:
- Human (mostly human-written)
- Mixed (some parts human, some parts AI)
- AI (mostly or fully AI-written)
Pangram also gives a score (0–100%) for “how likely this is AI.” The tool has been tested a lot and makes mistakes only rarely, but like any detector, it isn’t perfect.
They also:
- Checked topics (like weather, tech, sports) using a standard news-topic list, so they could compare AI use by subject.
- Matched newspapers to their size and owner (using public databases) to see if that mattered.
- Double-checked a sample with another detector (GPTZero) and did a manual read of 100 AI-flagged articles to look for disclosure.
- Looked at long quotes (over 50 words) to see if quotes were human-written inside AI-flagged stories.
What did they find?
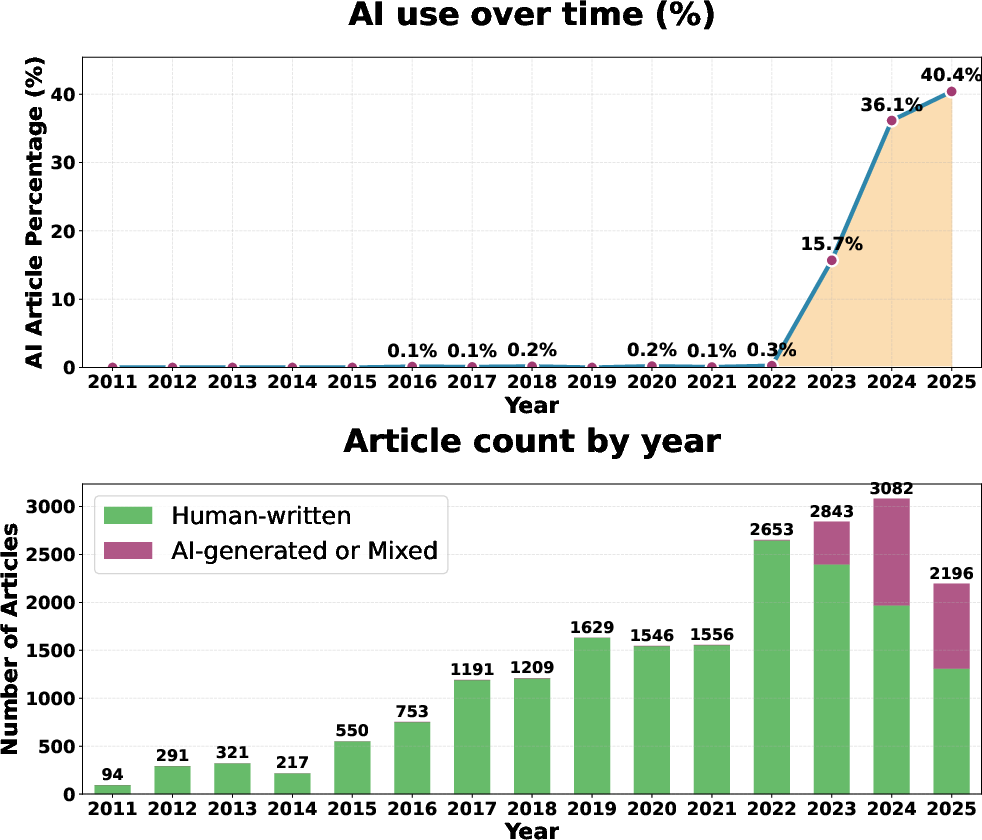
1) About 9% of new U.S. newspaper articles use AI in some way
Across 186,000 recent articles, roughly 1 in 11 were partly or mostly AI-written.
Why it matters: That’s a lot of news being shaped by AI—sometimes fine (like routine weather updates), sometimes risky (if errors slip in, or if readers aren’t told).
2) AI use is uneven—who uses it most?
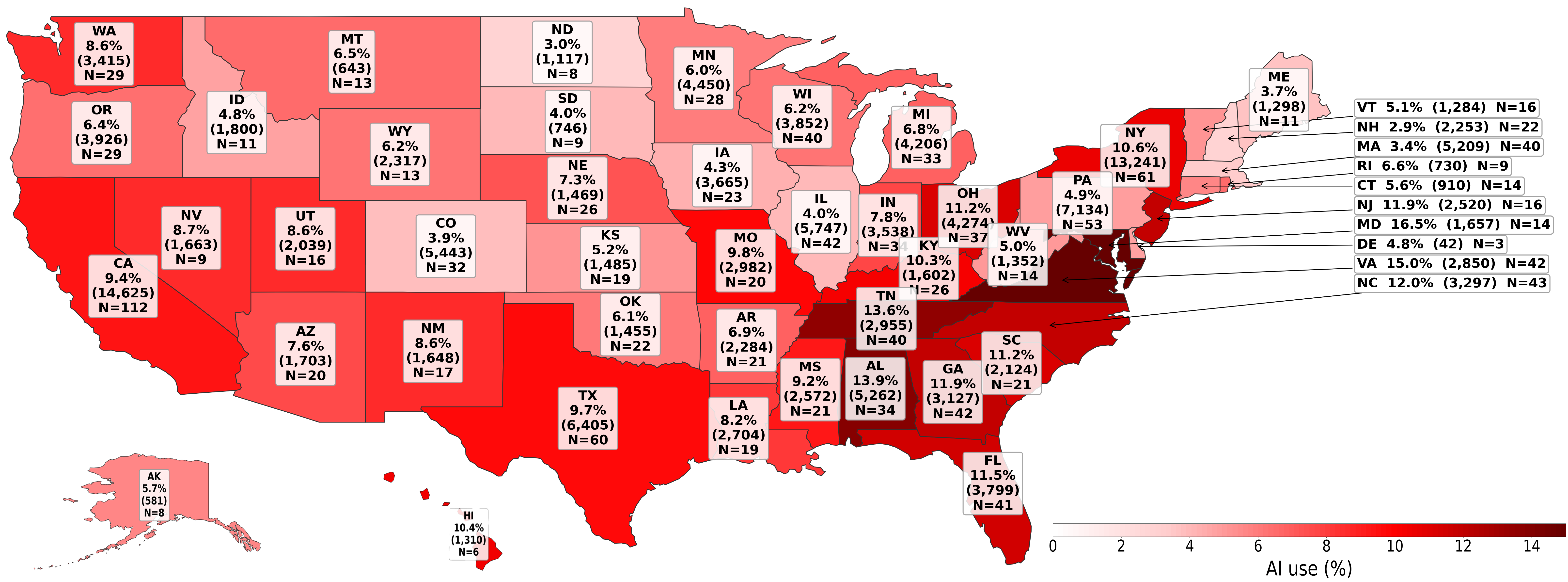
- Smaller local papers use AI more than big national ones. Local newsrooms often have fewer staff and smaller budgets, so automation can be tempting.
- Some states (especially in the Mid‑Atlantic and the South) had higher AI rates than others.
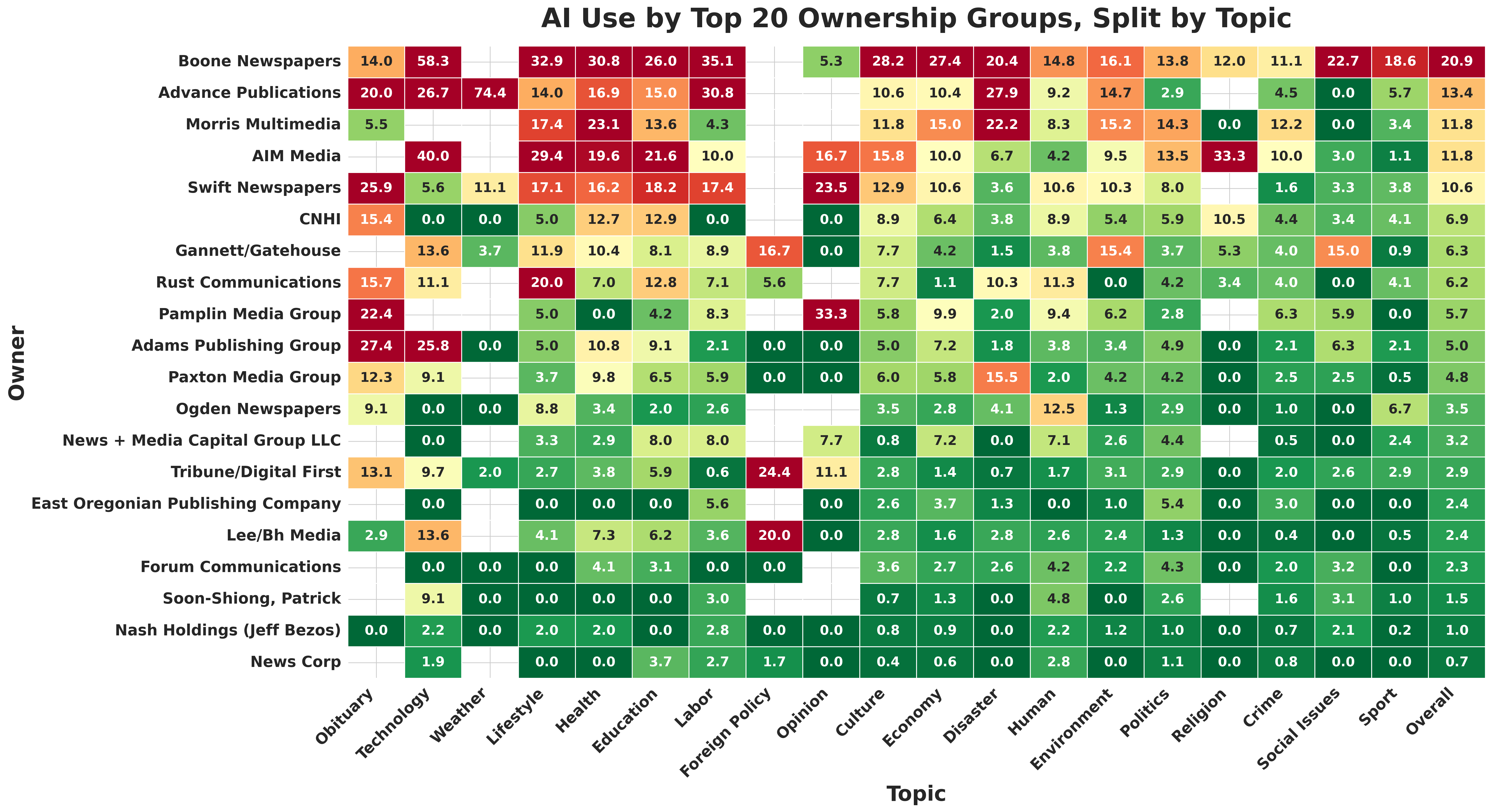
- AI use varies by owner. For example, two owners (Boone Newsmedia and Advance Publications) had especially high use, while several other big groups used it far less.
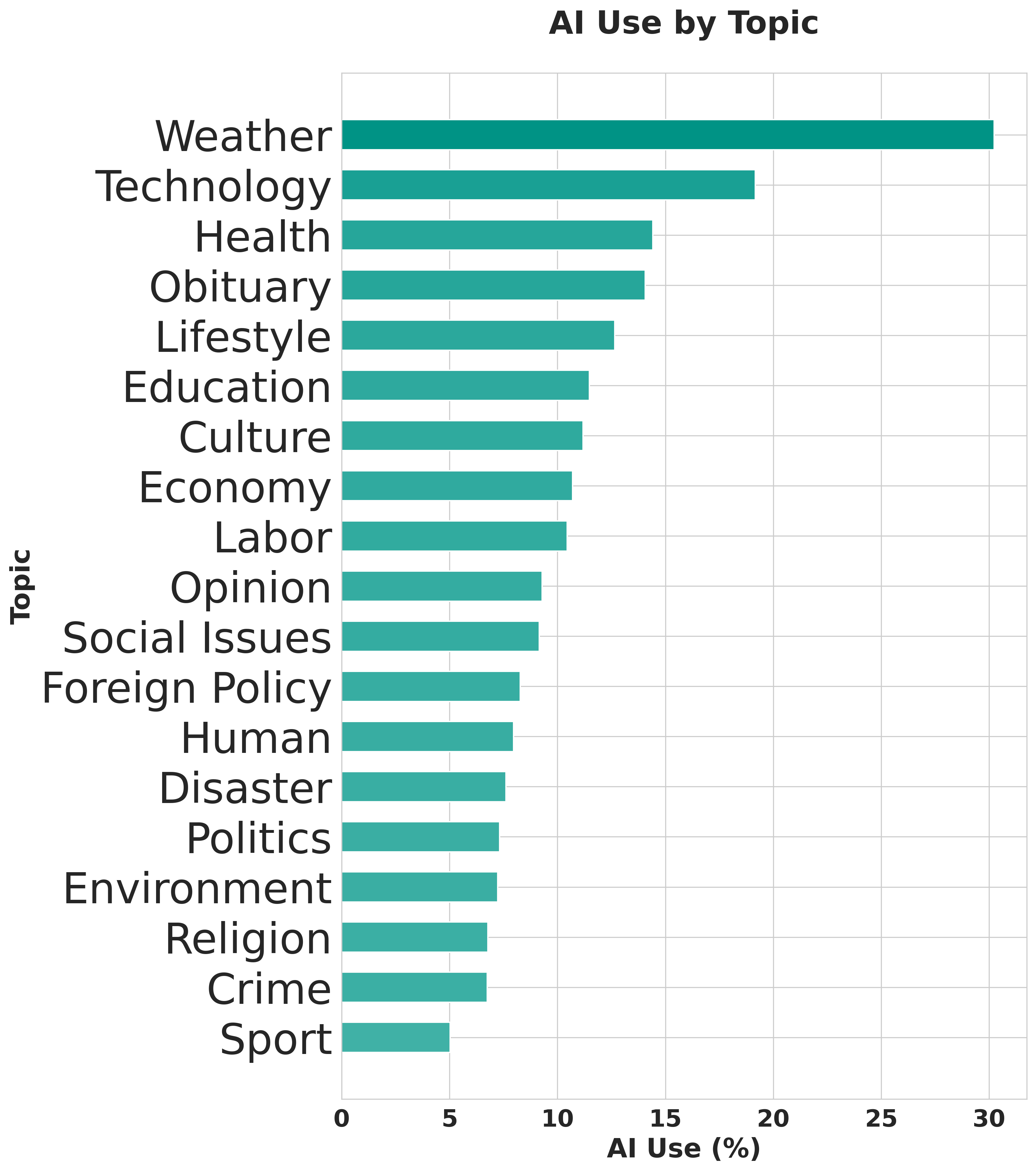
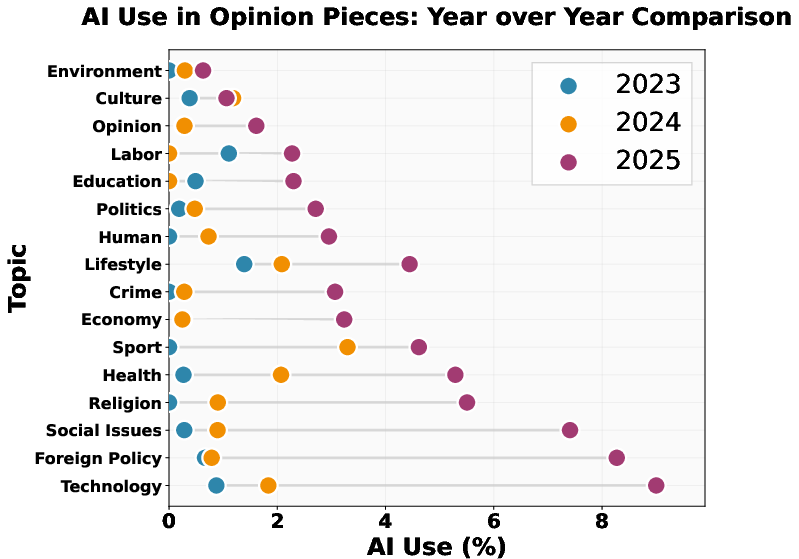
3) Certain topics use AI more
- Highest: Weather, science/technology, and health.
- Lower: Conflict/war, crime/justice, and religion.
Translation: Stories with routine data (like weather) are easier to auto-draft. Sensitive topics see less AI—probably because accuracy and tone matter more.
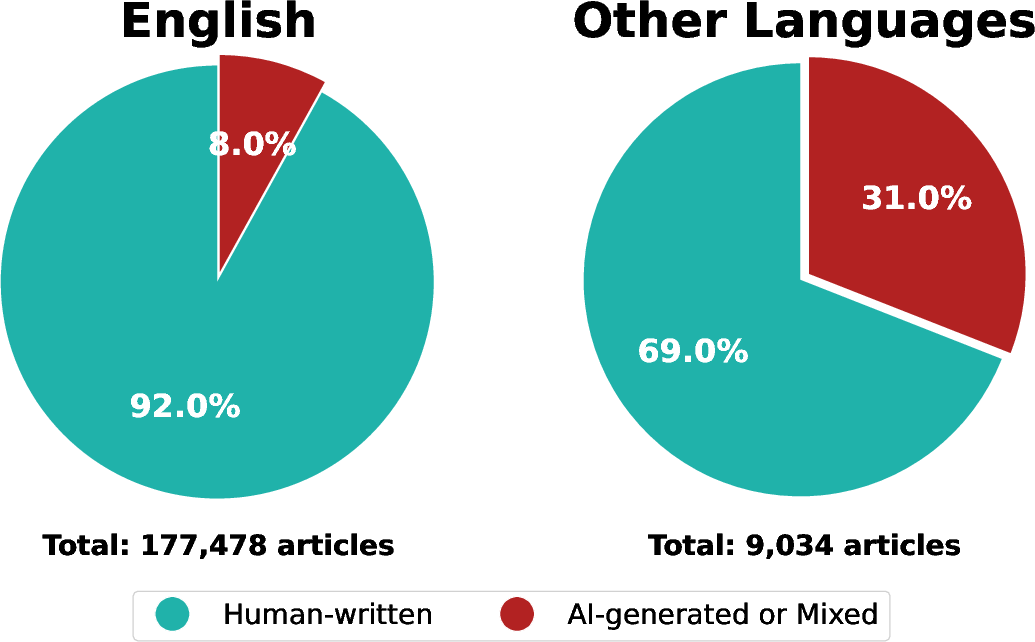
4) Non‑English articles used AI more often
- English articles: about 8% used AI.
- Other languages (often Spanish in U.S. outlets): about 31% used AI.
This suggests AI is often used for translation or fast drafting in bilingual coverage.
5) Opinion pieces at top newspapers are much more likely to use AI—and rising fast
- Opinion articles (NYT, WaPo, WSJ) were about 6.4× more likely to use AI than news articles from the same outlets in mid‑2025.
- From 2022 to 2025, AI use in these opinion sections jumped around 25×.
- Guest writers (politicians, CEOs, scientists) used AI far more than full‑time columnists.
Why it matters: Opinion pages can change minds. If AI helps write persuasive arguments, readers should know.
6) AI help is often “mixed,” not a full replacement
Many AI‑flagged pieces looked like teamwork: humans plus AI editing or drafting. The detector can’t always tell exactly how the AI was used (edit vs. draft), only that some parts look AI‑generated.
7) AI writing is rarely disclosed
In a manual check of 100 AI‑flagged articles from different newspapers, only 5 clearly told readers that AI helped. Most outlets didn’t have public AI policies, and even a few with bans still published AI‑flagged articles.
Why it matters: Readers can’t judge whether AI was used responsibly if they aren’t told it was used at all.
8) Many AI‑flagged articles still contain real human quotes
In stories with long quotes, most AI‑flagged articles had at least one human‑written quote. That suggests reporters may gather real quotes and facts, then use AI to draft or polish the story around them.
9) AI‑written stories also show up in print
Some AI‑flagged pieces appeared in printed newspapers (not just online), reaching older readers who may find it harder to check sources.
What does this mean?
- Trust and transparency: People tend to trust news more when they know how it was made. If AI is used, readers should be told where and how (for example, “AI drafted this weather report; an editor checked it”).
- Set better rules: Newsrooms need clear, public policies on when AI is allowed, how it’s checked for accuracy, and how to tell readers about it.
- Use AI wisely: AI can be useful for routine tasks (like weather summaries or grammar). But on sensitive topics—or persuasive opinion pieces—extra care and clear disclosure are crucial.
- Keep watching: AI use is growing and changing quickly. Public dashboards and follow‑up studies can help keep newsrooms accountable and readers informed.
Important limits to remember
- Detectors can’t always say exactly how AI was used—only that parts look AI‑written.
- Even good detectors can make rare mistakes.
- Circulation numbers are historical proxies (mainly from around 2019), not current total audience size.
- Machine‑translated articles might look “AI‑ish” to detectors, but small checks suggested real human writing still reads as human after translation.
- The study covered a specific time window; patterns can change over time.
The big takeaway
AI is already a significant behind‑the‑scenes helper in American journalism—especially in smaller outlets, certain topics like weather and tech, and opinion pages at top papers. But readers are almost never told when AI is involved. Using AI isn’t automatically bad, yet being open about it is essential. Clear labels, solid editorial rules, and careful human oversight can help newsrooms use AI’s benefits without losing the public’s trust.
Knowledge Gaps
Below is a single, concrete list of the key knowledge gaps, limitations, and open questions that remain unresolved by the paper. These items are framed to be actionable for future researchers.
- Ground-truth validation is limited: only 100 AI-flagged articles were manually checked (and only purplebg), with no systematic verification of tealbg articles for false negatives or stratified checks across topics, owners, states, or languages.
- The role of AI in mixed-authorship (orangebg) texts is indeterminate: there is no method to estimate the proportion of AI-generated vs. human-written content or to differentiate editing, drafting, translation, and templating; segment-level provenance remains unresolved.
- Detector reliance and validation gaps: the audit hinges primarily on Pangram; cross-detector comparison with GPTZero is limited (small, binary subset; excludes orangebg), and there’s no thorough evaluation of detector recall, multilingual performance, short-text reliability, or robustness against evasion (paraphrasing/human post-editing).
- Machine translation confound: the higher AI share in non-English pieces may reflect translation pipelines; controlled experiments to separate human-written, human-translated, machine-translated, and AI-generated content are missing.
- Sampling biases in recent: coverage is constrained to June–September 2025, RSS-dependent feeds, and “up to 50 articles” per outlet per crawl, potentially underrepresenting paywalled content, print-only articles, and seasonal/topic variation (e.g., weather-heavy months).
- Syndication and duplication are not de-duplicated: chain-wide replication or wire copy might inflate AI-use counts per owner/topic; provenance tracking to cluster identical/near-identical articles across outlets is absent.
- Ownership and circulation metadata are incomplete/outdated: owner mapping covers ~52% of outlets; circulation is a 2019 print proxy (self-reports; excludes digital audience), which may mischaracterize current scale and skew analyses of AI use by size.
- Topic classification reliability is moderate and uncalibrated by language: zero-shot Qwen3-8B labels align 77% with humans on a small English-only sample; cross-language accuracy, topic boundary errors, and IPTC taxonomy coverage (e.g., obituaries/Other) remain under-explored.
- Language identification method and accuracy are unspecified: there is no evaluation of language detection errors, which could misassign articles to “other languages” and affect AI-use estimates.
- No direct quality/factuality assessment: the paper does not quantify factual errors, hallucinations, bias, or corrections/retractions in AI vs. human articles; impact on reliability across topics and owners is unknown.
- Disclosure audit is narrow and non-representative: only 100 purplebg articles from unique outlets were reviewed; a systematic, large-scale, automated and manual audit of disclosures (including orangebg and tealbg) and outlet policy pages is missing.
- Opinions dataset coverage and author labeling are under-specified: ProQuest-based collection may under-sample online-only content; author occupational categorization lacks a reproducible protocol; AI-use claims in op-eds are not corroborated by author/editor workflows.
- Longitudinal panel (ai dataset) is selection-biased: reporters were chosen for having multiple AI-flagged articles; results are not representative of broader journalist populations; causal drivers of adoption (policy changes, tooling, staffing) are untested.
- Quote analysis is length-limited and lacks source verification: only quotes >50 words were analyzed; fabrication in shorter quotes is unexamined; there is no cross-source validation (e.g., checking quotes against transcripts/press releases).
- Drivers of geographic variation are not investigated: the observed state-level AI use differences are not linked to economic pressures, staff size, CMS/tooling, chain policy environments, or local news ecosystem health.
- Non-text and non-generative AI use is out of scope: the audit does not measure AI in images, video, audio, graphics, transcription, translation, summarization, or research workflows, likely understating total AI integration in newsrooms.
- Section-level placement of AI within articles is unknown: there is no segmentation analysis of where AI appears (headline, lede, nut graf, body, conclusion), limiting actionable editorial guidance.
- Print prevalence is anecdotal: AI use in print is not quantified; print-only outlets are not systematically audited; an OCR-based print pipeline to measure AI use is absent.
- Uncertainty quantification is limited: many reported rates (by topic, owner, language, state) lack confidence intervals and sensitivity analyses (e.g., to detector thresholds, article length, and sampling schemes).
- Outlet authenticity and “AI newspapers” detection lacks criteria: identifying and validating fake or fully AI-generated outlets (e.g., Argonaut) requires a protocol for outlet legitimacy (staff pages, registries, WHOIS, IP ownership).
- Policy–practice link is untested: relationships between public AI policies (including explicit bans) and observed AI use are anecdotal; a systematic compliance measurement over time is needed.
- Reader impact is inferred, not measured: beyond Pew surveys, there’s no experimental evidence on how disclosures (content-, section-, or extent-specific) affect trust, comprehension, persuasion, or engagement.
- Tooling, models, and workflow provenance are unknown: the paper cannot identify which LLMs or CMS integrations were used, prompt practices, or editorial review steps; newsroom interviews or telemetry could fill this gap.
- Equity implications in bilingual communities are unexplored: higher AI use in Spanish-language outlets raises fairness and quality questions for bilingual audiences; differential resource constraints and editorial oversight are not examined.
- Orangebg taxonomy and labeling protocol is absent: a standardized mixed-authorship rubric (edit vs. draft vs. translate vs. template) with human annotation at segment level would enable finer-grained analysis and guidance.
- Press-release and wire-copy confounds are not controlled: detectors may conflate formulaic PR/wire language with AI; source provenance tracing and PR/wire baselines are needed.
- Data sharing limits reproducibility: only links (not full texts) are released; article drift/paywalls can hinder replication; snapshots (e.g., text archives, hashes) under appropriate permissions would support durable auditing.
- Detector recall on known AI content isn’t estimated: using a ground-truth set of disclosed-AI articles to estimate Pangram’s recall for news text (by topic/language/length) is missing.
- Template-heavy domains (weather, obituaries, sports) may confound detection: controlled baselines to differentiate templating from AI generation are needed, especially within chains that standardize content.
Practical Applications
Overview
The following applications translate the paper’s findings, methods, and innovations into practical, real-world uses across industry, academia, policy, and daily life. They are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring further research, scaling, or development).
Immediate Applications
- Newsroom CMS-integrated AI detection and disclosure
- Sectors: media, software
- What: Embed Pangram API checks in content management systems to automatically flag orange/purple articles and inject standardized disclosure language (especially for templated content like weather).
- Tools/Products/Workflows: Pangram API, GPTZero for cross-checks, “Disclosure Banners” module; rule-based triggers by topic and outlet size.
- Assumptions/Dependencies: Detector reliability on news domains; CMS integration capacity; editorial buy-in; cross-detector consensus.
- Risk-based editorial triage for mixed authorship
- Sectors: media
- What: Route orangebg and purplebg content to human editors for extra verification (facts, quotes, sourcing), while allowing lighter checks for tealbg.
- Tools/Products/Workflows: “AI-risk queue” dashboard; per-article likelihood score thresholds; topic-aware prioritization (sensitive topics get stricter gates).
- Assumptions/Dependencies: Staff capacity; agreed thresholds; detector false positives/negatives.
- Topic-aware automation policies (allow, restrict, ban)
- Sectors: media, policy
- What: Permit AI assistance for high-structure topics (weather, sports), restrict for health/technology, and ban or heavily gate for conflict, crime/justice, religion.
- Tools/Products/Workflows: IPTC topic classification (Qwen3-8B zero-shot), policy rules mapped per topic; compliance logging.
- Assumptions/Dependencies: Topic classifier accuracy (77% model–human agreement); newsroom policy clarity; change management.
- Guest contributor onboarding and provenance checks
- Sectors: media
- What: Require guest writers (politicians, CEOs, academics) to disclose AI assistance and submit source materials; auto-scan drafts for AI signatures before publication in opinion sections.
- Tools/Products/Workflows: Opinion submission portal with AI scan; disclosure attestation; provenance checklist.
- Assumptions/Dependencies: Contributor compliance; legal terms; detector robustness on edited drafts.
- Ownership-level audits and governance
- Sectors: media management, finance
- What: Use owner-topic heatmaps to set chain-wide standards; identify high-risk properties (e.g., Boone Newsmedia, Advance Publications) and topics (weather, science/tech) for policy and resourcing.
- Tools/Products/Workflows: The released dashboard and datasets; monthly “AI use” KPI reports to execs.
- Assumptions/Dependencies: Coverage bias (RSS-accessible outlets); accurate ownership mappings.
- Multilingual translation and disclosure workflows
- Sectors: bilingual media, software
- What: Flag non-English pieces (especially Spanish) for higher scrutiny; disclose machine translation and AI drafting; add extra human review where AI likelihood is elevated.
- Tools/Products/Workflows: Language detection; multilingual Pangram; translation pipeline labels (e.g., “MT + human edit”).
- Assumptions/Dependencies: Detector performance across languages; risk of misclassifying machine-translated human text.
- Quote provenance checks for long quotes
- Sectors: media, software
- What: Identify quotes (>50 words) likely written by humans and flag suspect AI-sounding quotes for verification with sources.
- Tools/Products/Workflows: Quote extractor; per-quote Pangram scan; “quote verification” sub-workflow.
- Assumptions/Dependencies: Detector reliability degrades on short text; applies mainly to longer quotes.
- Advertiser brand safety and placement controls
- Sectors: advertising, finance, ad-tech
- What: Avoid placing ads adjacent to undisclosed AI-generated or sensitive-topic AI content; align brand safety standards with disclosure policies.
- Tools/Products/Workflows: Supply-side signal (“AI-generated” flag in ad inventory), programmatic filters.
- Assumptions/Dependencies: Ad-tech integration; publisher cooperation; clear thresholds.
- Reader-facing verification and media literacy
- Sectors: daily life, education
- What: Encourage readers to consult the public dashboard (ainewsaudit.github.io) or publisher-provided badges; libraries and schools teach how to interpret disclosures.
- Tools/Products/Workflows: Browser extensions linking to detection dashboards; classroom modules using the datasets.
- Assumptions/Dependencies: Public awareness; simple UX; responsible presentation of detection uncertainty.
- Legal/compliance self-audits for media groups
- Sectors: policy, legal, media
- What: Reconcile litigation positions against AI training with internal AI adoption; document policies and disclosures for regulatory or court scrutiny.
- Tools/Products/Workflows: Internal audits using the datasets/detectors; policy updates; compliance files.
- Assumptions/Dependencies: Counsel guidance; accurate internal logs; reputational risk management.
- Print edition disclosure badges
- Sectors: media/print
- What: Add “AI-assisted/reporting” badges in print for templated columns (e.g., weather), mirroring online disclosures; include brief provenance notes.
- Tools/Products/Workflows: Print layout templates; standard iconography; CMS flags carried to print production.
- Assumptions/Dependencies: Space constraints; reader comprehension; production workflow changes.
Long-Term Applications
- Standardized provenance metadata and content credentials
- Sectors: software, media, policy
- What: Adopt C2PA/Content Authenticity Initiative standards and schema.org extensions to encode segment-level provenance (human vs AI) in articles.
- Tools/Products/Workflows: CMS plugins for provenance logging; per-paragraph attribution; publisher signing workflows.
- Assumptions/Dependencies: Industry-wide adoption; standards evolution; consumer tooling that surfaces credentials.
- Mixed authorship measurement and auditability at scale
- Sectors: academia, software
- What: Integrate research on mixed authorship (e.g., EditLens) to quantify AI editing vs generation continuum; build robust per-segment detectors.
- Tools/Products/Workflows: New detector models; granular annotations; audit APIs.
- Assumptions/Dependencies: R&D; labeled corpora; benchmark standardization.
- Regulatory labeling mandates and enforcement
- Sectors: policy, government
- What: Enact rules requiring transparent AI-use labeling in news and opinion, with penalties for noncompliance; harmonize across states and languages.
- Tools/Products/Workflows: Compliance reporting; audit sampling; third-party certifiers.
- Assumptions/Dependencies: Legislative process; constitutional and press-freedom considerations; administrative capacity.
- Certification programs for “Human-Verified Journalism”
- Sectors: media, finance (subscription models)
- What: Third-party accreditation akin to “nutrition labels” for provenance; premium subscriptions promising human-first reporting with disclosed AI assistance.
- Tools/Products/Workflows: Audit criteria; certifier marketplace; consumer-facing seals.
- Assumptions/Dependencies: Trust in auditors; cost-benefit for publishers; market demand.
- Public trust impact studies and interventions
- Sectors: academia, policy
- What: Use released datasets plus Pew baselines to measure how disclosed vs undisclosed AI use affects trust, persuasion, and misinformation pathways; design evidence-based policies.
- Tools/Products/Workflows: Longitudinal experiments; IRB-approved studies; randomization by disclosure type.
- Assumptions/Dependencies: Access to participants; ethical approvals; causal identification.
- Multilingual, short-text, and domain-adaptive detection
- Sectors: software
- What: Improve detectors for short quotes, headlines, and non-English content; reduce misclassification of machine-translated human text.
- Tools/Products/Workflows: Cross-lingual models; stylometric and watermark fusion; active learning from newsroom feedback.
- Assumptions/Dependencies: Training data; model robustness; adversarial resistance.
- Syndication-aware provenance gating
- Sectors: media distribution, software
- What: Prevent undisclosed AI-generated pieces from propagating across chains; enforce disclosure and provenance validation upon syndication.
- Tools/Products/Workflows: Syndication APIs with provenance checks; automated stop/go gates.
- Assumptions/Dependencies: Platform cooperation; metadata interoperability; partner enforcement.
- Opinion section guardrails and provenance logs
- Sectors: media
- What: Define allowed AI roles (style-check vs generation) for op-eds; maintain auditable logs of AI assistance and edits.
- Tools/Products/Workflows: “Provenance ledger” per article; policy defaults per author type (guest vs staff).
- Assumptions/Dependencies: Cultural change; privacy considerations; storage and compliance.
- Transparent AI-augmented local news toolkits
- Sectors: civic tech, media (local)
- What: Provide small outlets with open-source modules for templated reporting (weather, municipal notices) with built-in disclosures and human-in-the-loop validation.
- Tools/Products/Workflows: Data pipelines (NWS feeds), templating engine, review queue; grant-funded deployment.
- Assumptions/Dependencies: Funding; training; reliable data sources.
- Ad-tech risk scoring tied to provenance
- Sectors: advertising, finance
- What: Programmatic buyers use provenance scores in brand-safety decisions and pricing; publishers monetize transparent, human-verified content at a premium.
- Tools/Products/Workflows: Supply-side metadata; DSP filters; risk-weighted CPMs.
- Assumptions/Dependencies: Ecosystem alignment; measurable lift in outcomes; prevention of gaming.
- AI literacy curricula and community outreach
- Sectors: education, libraries
- What: Build curricula that teach readers to interpret AI disclosures, mixed authorship, and detector limitations; host workshops in communities with high print readership.
- Tools/Products/Workflows: Course materials using the datasets; librarian toolkits; community dashboards.
- Assumptions/Dependencies: Institutional sponsorship; accessible materials; evaluation studies.
- Quote origin verification for short and composite quotes
- Sectors: software, academia
- What: Develop stylometric/forensic tools to assess AI involvement in short or paraphrased quotes; integrate with source verification workflows.
- Tools/Products/Workflows: Hybrid detectors; link analysis to source artifacts (emails, recordings).
- Assumptions/Dependencies: Privacy and consent; technical feasibility at short lengths; data availability.
- Cross-country media audits and comparative policy dashboards
- Sectors: academia, policy
- What: Replicate the audit in other countries; compare AI adoption by topic, language, and ownership; inform transnational standards.
- Tools/Products/Workflows: Global RSS/archives; multilingual detectors; public dashboards.
- Assumptions/Dependencies: Access to feeds/archives; localization; governance contexts.
- Labor contracts and ethical frameworks around AI use
- Sectors: labor, media policy
- What: Negotiate union contracts specifying permissible AI use, disclosure obligations, and protections for reporters; codify ethical standards.
- Tools/Products/Workflows: Contract templates; grievance procedures; compliance audits.
- Assumptions/Dependencies: Collective bargaining; management agreement; legal review.
Glossary
- AAM audits: Audits conducted by the Alliance for Audited Media to verify circulation figures used in media industry reporting. "The archive’s circulation series is assembled from AAM audits and self-reports"
- balanced binary held-out set: A test subset with equal class distribution set aside for evaluation without being used in training. "This experiment was conducted on a balanced binary held-out set of 1K news articles"
- chi-squared test (χ²): A statistical test for independence or goodness-of-fit used to determine whether observed differences are significant. "(, )"
- Cohen's kappa: A reliability coefficient that measures inter-rater agreement beyond chance. "a high cross-detector agreement of (Cohen's )."
- cross-detector agreement: The degree to which different detection systems produce consistent labels on the same data. "we also experiment with another commercial detector, GPTZero~\cite{tian2023gptzero}, and observe a high cross-detector agreement of "
- false positive rate (FPR): The proportion of human-written texts incorrectly flagged as AI-generated by a detector. "Pangram has a reported false positive rate (FPR) of 0.001\% on news text"
- GPTZero: A commercial AI-generated text detector used to cross-check results. "we also experiment with another commercial detector, GPTZero~\cite{tian2023gptzero}"
- inference API: A programmatic interface that returns model predictions (e.g., scores and labels) for input text. "Using Pangram's inference API\footnote{API documentation available \href{https://pangram.readthedocs.io/en/latest/api/rest.html}{here}.}, we collect (1) the likelihood (from 0-100\%) that a text is AI-generated and (2) a text label"
- International Press Telecommunications Council Media Topics taxonomy: A standardized hierarchical classification system for news topics. "we further augment our datasets with topic labels for each article using the International Press Telecommunications Council Media Topics taxonomy"
- inter-annotator agreement: A measure of consistency between human raters when labeling data. "Inter-annotator agreement between the two human raters was 87\% (Cohen’s~)."
- Longitudinal analysis: A study design that examines changes over time within the same subjects or entities. "making them good candidates for a longitudinal analysis to explore when and how they started using AI"
- mixed authorship: Texts that combine human-written and AI-generated segments within the same document. "Many articles have mixed authorship."
- multilingual AI detector: An AI detection system that can reliably operate across multiple languages. "A Pangram \href{https://www.pangram.com/blog/pangram-multilingual-v2}{study} shows that it is also a strong multilingual AI detector."
- Newspaper4K: A library for extracting article content from news webpages. "preprocessed using the Trafilatura~\citep{barbaresi-2021-trafilatura} and Newspaper4K\footnote{\url{https://github.com/AndyTheFactory/newspaper4k} libraries"
- orangebg: A Pangram label indicating mixed AI/human content within a document. "Pangram predicts orangebg\ when there is a high confidence of both AI and human writing present in the document"
- Pangram: A high-precision AI-generated text detector designed for reliability on news text. "Using Pangram, a state-of-the-art AI detector, we discover that approximately 9\% of newly-published articles are either partially or fully AI-generated."
- ProQuest Recent Newspapers: A database providing access to full-text and metadata of newspaper articles. "articles from some newspapers (e.g., Washington Post, Wall Street Journal) were accessed via ProQuest Recent Newspapers."
- purplebg: A Pangram label indicating text is highly likely to be AI-generated. "In our recent\ dataset, 9.1\% of articles are labeled by Pangram as either purplebg\ or orangebg"
- Qwen3-8B: A LLM used for topic classification in a zero-shot configuration. "We prompt Qwen3-8B~\cite{qwen3-2025} in a zero-shot setting to assign a topic"
- RSS feed: A standardized web feed that publishes updates from websites, commonly used for automatic article collection. "filter out those that are unreachable and/or do not have active RSS feeds"
- tiktoken tokenizer: A tokenization library (by OpenAI) used to count tokens in text according to a specific vocabulary. "The token counts are reported as per \href{https://github.com/openai/tiktoken}{tiktoken} tokenizer (o200k_base)."
- Trafilatura: A web scraping and text extraction tool used to clean article content. "preprocessed using the Trafilatura~\citep{barbaresi-2021-trafilatura}"
- Wayback Machine: An internet archive used to retrieve historical versions of web pages. "Earlier versions were retrieved via the Internet Archive’s Wayback Machine."
- Welch's t-test: A statistical test for comparing means between two groups without assuming equal variances. "a statistically significant gap (Welch's , , )"
- zero-shot setting: Using a model to perform a task without task-specific training examples. "We prompt Qwen3-8B~\cite{qwen3-2025} in a zero-shot setting to assign a topic"
- tealbg: A Pangram label indicating human-written or unlikely AI-generated text. "tealbg {Human, Unlikely AI}"
Collections
Sign up for free to add this paper to one or more collections.

